
自然场景下基于四级级联全卷积神经网络的人脸检测算法
2019-02-22 09:13:22石学超周亚同韩卫雪
铁道学报 2019年1期
石学超, 周亚同, 韩卫雪
(河北工业大学电子信息工程学院, 天津 300401)
人脸检测是人脸分析的关键步骤,在人脸建模、人脸矫正、人脸识别、头部姿态跟踪、性别和年龄识别中均具有重要意义[1-3]。如今比较流行的人脸检测方法大致有特征脸、支持向量机(SVM)、AdaBoost法、和卷积神经网络(CNN)等几种。特征脸方法[4]是利用主成分分析重构原理,将任意输入图像通过特征脸空间重构进行人脸检测。文献[5]提出用SVM检测人脸,但SVM有限的建模能力使其在处理自然场景下的检测问题时显得不足。文献[6-8]提出的AdaBoost法第1次实现了人脸实时检测,并且能够保证较高的检测率和较小的误检率。
卷积神经网络CNN是深度学习领域里一种常见的网络结构,文献[9]提出基于CNN的多角度人脸检测方法,此方法没有对输入图像进行预处理,利用未经过处理图像的灰度值保留图像的原始信息进行分类,实现了特征的自动提取,但此网络仅是端到端的单级5层网络,复杂自然场景下的人脸检测效果较差。文献[10]提出了1种紧凑级联卷积神经网络的人脸检测算法,但此算法为追求速度而在设计网络结构时使用了较少的网络参数,导致检测精度大幅降低。文献[11]提出基于多视点卷积神经网络的人脸检测算法,通过对人脸进行多角度划分的方法提高检测效果,但此算法的网络简单,对于很小的人脸图像需进行尺寸放大操作,极大增加了计算负担。文献[12]提出使用Faster R-CNN实现人脸检测,此算法利用区域建议网络RPN来实现人脸边框的预测,但由于候选窗口的尺寸和长宽比是预先随机设定的,因此很难处理大形态变化的图像。
基于上述工作,本文提出1种自然场景下基于4级级联全卷积神经网络的人脸检测算法。所提算法是对传统AdaBoost的深度卷积网络的实现,充分结合了传统级联结构和深度卷积网络的优势。和AdaBoost方法一样,本文算法包含了多个分类器,这些分类器采用级联结构相结合,不同的是本文算法采用全卷积神经网络FCNN[13]作为每级的分类器,而不是像AdaBoost通过多个弱分类器组合成强分类器,不存在单独的特征提取过程,特征提取与分类由每级FCNN完成。另外加入了边框校准和非极大值抑制NMS等环节,确保了复杂自然场景下人脸检测的速度与精度,增强了检测的鲁棒性。
本文的研究意义在于:利用卷积神经网络特性,尝试构建4级级联网络结构,并获得有区分性功能的深度网络,可提高人脸检测精度;每级网络采用全卷积网络结构,能接受任意尺寸图像的输入,可提高人脸检测效率;采用自举法进行每级全卷积网络模型的优化训练,可提高训练样本的利用率。
1 4级级联全卷积神经网络模型构建
1.1 整体网络结构概述
为了提高复杂自然场景下人脸检测的速度和准确性,本文提出4级级联全卷积神经网络的人脸检测算法:前3级全卷积网络为15步长滑窗分类网络(15c-net)、30步长滑窗分类网络(30c-net)、60步长滑窗分类网络(60c-net),用于人脸与非人脸的分类,最后1级60步长滑窗矫正网络(60c-calibration-net)用于人脸区域边框的回归校准。每级网络均采用了全卷积神经网络结构进行检测,可以接受任意尺寸图像的输入,同时在每级网络后面接非极大值抑制NMS,消除高度重叠输出冗余窗口。
1.2 全卷积网络结构
1.2.1 第1级全卷积网络15c-net
15c-net的网络结构示意见图1。15c-net网络只包含3个卷积层,无全连接层,为全卷积网络FCNN,此网络结构可以接受任意尺寸图像的输入,尝试用不同尺寸的输入进行训练,如12×12、18×18 px等,经多组测试得出15×15 px输入效果最佳,所以此级网络的输入控制为15×15 px的大小,相当于15×15 px的检测窗口,同时对应的滑动窗口的步长设置为5个像素,对于输入大小为W×H的图像上进行滑窗,可以等效地看作此15c-net利用15×15 px的滑动窗口遍历W×H整张图像得到[(W-15)/5+1]×[(H-15)/5+1]个置信度等分点,此15c-net可以密集扫描整张图像,拒绝80%以上的非人脸窗口,从而大幅减小下级网络的负担。

图1 15c-net的网络结构示意
1.2.2 第2级全卷积网络30c-net
30c-net为第2级的二分类卷积网络,目的是进一步减少传入到下级网络的检测窗口。经15c-net输出的检测窗口,由于通过的人脸与非人脸窗口之间更加难以区分,因此第2级30c-net将输入的图像尺寸增大到30×30 px,以利用图像更多的信息,另外,考虑检测的时间效率,15c-net同样设计成比较浅的网络,但相比于第1级网络增大了网络的复杂程度,进而增加网络对图像的判别性,30c-net的网络结构示意见图2。

图2 30c-net的网络结构示意
1.2.3 第3级全卷积网络60c-net
60c-net是最后一级二分类全卷积网络FCNN,60c-net设计了相对于前两层网络更深的网络结构,包含5层卷积层,最后输出只含有1个边框的人脸窗口,另外60c-net和30c-net相同,进一步增大输入图像的大小到60×60 px获得更多的图像信息,增加网络结构的判决性,60c-net的网络结构示意见图3。

图3 60c-net的网络结构示意图
1.2.4 第4级全卷积网络
60c-calibration-net网络在60c-net网络之后,用于对输出人脸检测窗口的矫正,可以将最后输出偏移的人脸框校准到正确人脸的位置。矫正方式使用3个偏移量:水平方向偏移量xn,竖直方向偏移量yn,边框宽高缩放比值系数值kn,其中(x,y)表示检测边框的左上点坐标位置,(w,h)分别为输出边框的宽度与高度,60c-net输出的人脸检测窗口经过60c-calibration-net矫正网络校准调整为
( 1 )
此级网络结构中设计有N=3×3×3=27种模式,用于输出窗口的矫正,通过设定3个变量参数矫正。其中,水平偏移量xn对应(-0.1,0,0.1)3种变量值;竖直方向偏移量yn对应(-0.1,0,0.1)3种偏移变量值;边框宽高缩放比值系数值kn对应(0.8,1.0,1.2)3种偏移变量值。60c-calibration-net的网络结构见图4。

图4 60c-calibration-net的网络结构示意
此外,利用60c-calibration-net网络输出的置信度向量分数[c1c2c3…cn]对3个偏移量参数取平均值,进一步精确矫正输出,方式为
( 2 )
( 3 )
1.2.5 非极大值抑制NMS
为了消除冗余的检测窗口,本文算法在每一级网络的输出都加入了非极大值抑制NMS操作,选定 1个窗口重叠面积的比例(IOU)阈值ϖ,将每级全卷积网络输出的人脸检测窗口按照得分由高到低进行排序。选中得分最高的窗口,再进行遍历计算,若IOU大于开始设置的阈值ϖ,则将窗口删除。再从剩余的窗口中选中1个得分最高的,重复上面的过程,直至所有窗口都被处理完成,得到单一没有冗余的人脸检测窗口。
2 人脸样本准备及网络训练
2.1 样本准备
本文制作了6万多张正样本(人脸图像)和20万张负样本(非人脸图像)训练网络。另外为了有效地解决复杂自然场景的遮挡、不同角度等影响,采用随机平移、翻转、旋转及人工加入遮挡物等操作,扩充正负样本的多样性。
2.1.1 训练正样本制作
正样本来自AFLW、FERET等人脸数据库和网上下载的图片。在生成人脸正样本时,主要是将原有的矩形框进行随机比对操作,若得到的矩形框和原来矩形框的相交面积比值大于设定好的阈值0.65,则采样得到1个正样本;如果存在遮挡或夸张姿态的情况,则增加“采样”次数,防止遗漏这些样本,最终得到2万多张人脸正样本。另外,对网上下载的图片用手工裁剪方式生成单张人脸正样本图像,此操作共生成4万多张人脸正样本。最终制作了训练所需的不同肤色、遮挡、姿态等正样本图像6万多张。部分正样本图像见图5。

图5 部分正样本图像
2.1.2 训练负样本制作
负样本是从1万张不包含人脸的图像生成,这些图像涵盖了餐厅、建筑、卧室、衣服和动物等复杂场景。在利用收集的图像进行制作负样本时,首先对开始准备的1万张图像进行随机滑窗操作,窗口大小和滑动步长根据图片的大小确定,平均每张图像滑动产生150个窗口,经过阈值设定每张图像,最终得到20个左右负样本,此时1万张图像总共产生20万张负样本。部分负样本图像见图6。

图6 部分负样本图像
2.2 网络训练
考虑到每级网络人脸检测的召回率和准确率,还有对负样本复杂程度的利用和填充,本文采用自举法Bootstrap[14]增加训练过程中负样本的多样性来训练分类器。
2.2.1 第1级全卷积网络15c-net训练
15c-net采用非监督学习进行训练,所用的正负样本的比例为1∶3,采用6万张正样本和18万张负样本进行优化训练15c-net。此外,设定的目标函数为均方差MSE(Mean Square Error)函数[15],表示为
( 4 )
式中:w,b分别为对应的权值、偏置项;m为训练有m个样例。激活函数采用ReLU激活函数[16],为
f(z)=max(0,z)
( 5 )
ReLU可由f(x)=In(1+ez)逼近,另外惩罚系数取值λ=10-6,动量项系数设置为β=0.9,学习率从0.01开始下降,每训练100 000次降低10倍。由于训练数据较大,训练的迭代次数设为300 000次。最后训练测试的准确率曲线和损失曲线见图7。

(a)准确率曲线 (b)损失曲线图7 15c-net的训练结果曲线
由图7可见,在训练15c-net分类网络的训练次数在达到20 000次时,训练测试的准确率曲线达到饱和,训练测试准确率达到最大值;损失曲线在20 000次左右就基本不变,损失不再下降。
2.2.2 第2级全卷积网络30c-net训练
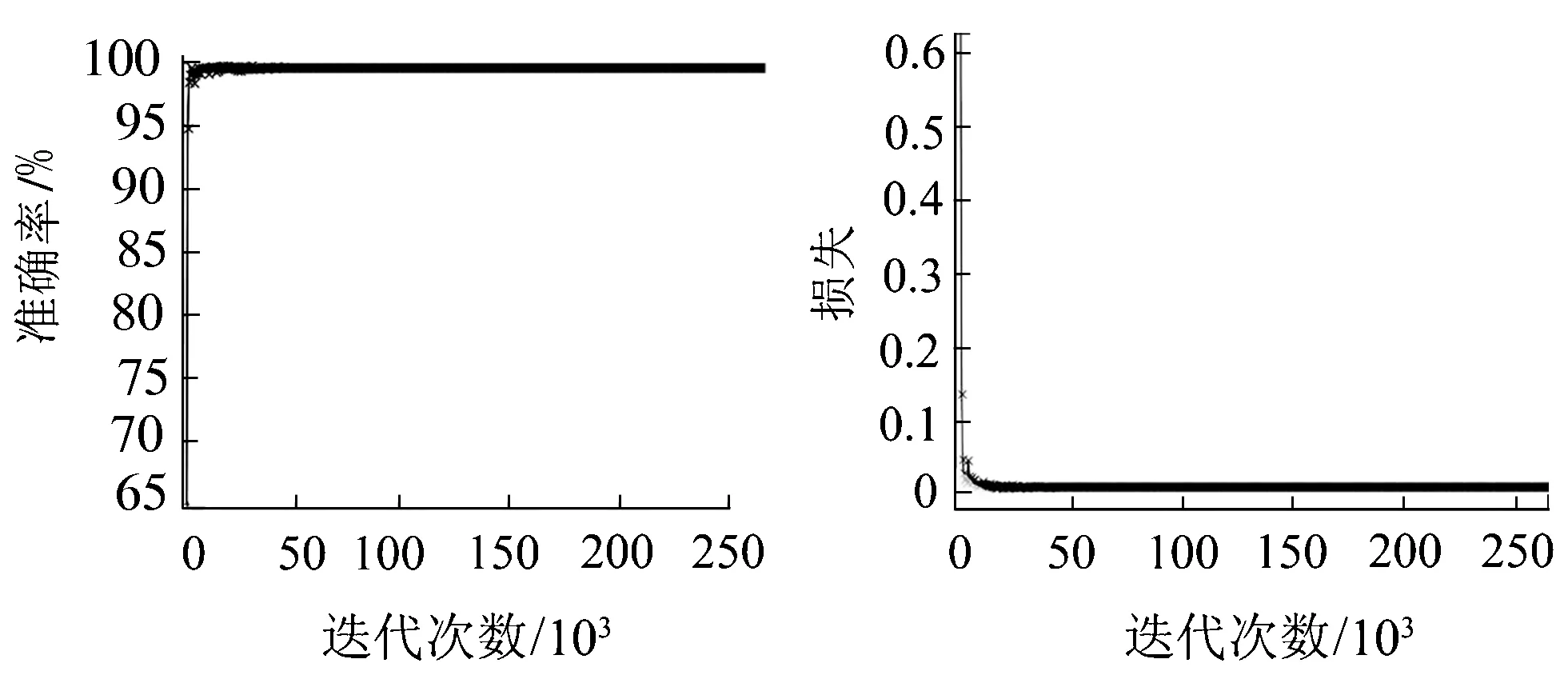
30c-net的训练方式和对应各参变量与第1级15c-net一样。此级网络利用自举法Bootstrap增加非人脸负样本的多样性:利用已经训练好的15c-net在原始准备的1万张负样本上进行滑窗检测,得到误检为人脸的艰难样本6万张。取原来的20万张负样本中的12万张与用Bootstrap生成的新的6万张样本合在一起,用正负样本1∶3的比例训练30c-net,训练的迭代次数为300 000次。训练测试的准确率曲线和损失曲线见图8。
(a)准确率曲线 (b)损失曲线图8 30c-net的训练结果曲线
由图8可知,训练次数在达到10 000次时,30c-net训练测试的准确率曲线达到饱和,训练测试准确率达到最大值;损失曲线在10 000次左右基本不变,不再下降。
2.2.3 第3级全卷积网络60c-net训练
第3级分类网络60c-net,训练方式和对应各参变量与前两级网络设置相同。60c-net也利用了自举法Bootstrap进一步增加训练非人脸负样本的多样性,利用已经训练好的15c-net与30c-net在原始准备的1万张负样本上进行滑窗检测,得到误检为人脸的艰难样本4万张。取原来的20万张负样本中的14万张与用Bootstrap生成的新的4万张样本合在一起,用正负样本1∶3的比例训练60c-net,训练的迭代次数为300 000次。训练测试的准确率曲线和损失曲线见图9。

(a)准确率曲线 (b)损失曲线图9 60c-net的训练结果曲线
由图9可知,训练次数在达到10 000次时,60c-net训练测试的准确率曲线达到饱和,训练测试准确率达到最大值;损失曲线在30 000次左右就基本不变,不再下降。
2.2.4第4级全卷积矫正网络60c-calibration-net训练
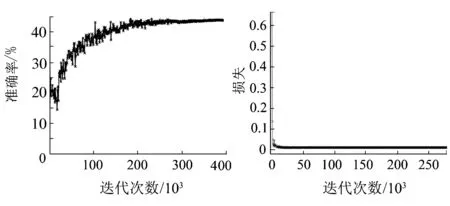
第4级矫正网络60c-calibration-net的训练同样采用非监督学习的训练方式。60c-calibration-net在矫正输出检测边框时使用的是分类而不是回归,即通过预先训练好的神经网络得到对于检测边框位置的预测,输出27维位置的预测向量。在正样本准备方面,对开始准备的6万张正样本中的1万张样本进行对应27维位置的手工制作裁剪,得到含有27维位置信息的样本约20万张。60c-calibration-net取得的20万张正样本和最开始的20万张负样本按照1∶1的比例进行训练,训练测试的准确率曲线和损失曲线见图10。
(a)准确率曲线 (b)损失曲线图10 60c-calibration-net的训练结果曲线
由图10可知,在训练60c-calibration-net矫正网络时,由于要训练27分类的网络,训练样本比较复杂,因此在训练过程中准确率曲线和损失曲线波动都比较大,最终训练次数在达到350 000次时,训练测试的准确率曲线达到饱和,训练测试准确率达到最大值;损失曲线在20 000次左右就基本不变,不再下降。
3 实验结果与分析
为验证本文算法的性能,设置两组实验进行测试分析。第1组实验基于国际权威的FDDB公开测试集进行本文算法的性能测试,并通过ROC曲线展示本文算法的性能;第2组为与传统Adaboost算法的对比实验。实验在GPU 1.2 GHz显存12 G的WinFast gs4800服务器上进行训练,在CPU 3.6 GHz内存8 G的预装Windows 10旗舰版64位操作系统的个人计算机上进行测试,深度学习框架为Caffe,软件编程环境为Python2.7.5。
3.1 实验1 基于FDDB公开测试集的性能测试
本实验的目的是测试和展现本文的人脸检测算法的性能。FDDB测试集是由美国马萨诸塞大学计算机系维护的全世界权威的人脸检测测试集,可用于研究各种非控条件下的人脸检测问题。FDDB测试集内容丰富,包含了5 171张人脸的2 845张图片,涵盖各种复杂自然场景下的正面人脸图像、遮挡人脸图像和多姿态人脸图像等。本文算法在FDDB测试集的部分检测结果见图11。

图11 FDDB测试集的部分检测结果
在实验中本文算法检测出5 171个人脸目标中的4 291个,真正率为82.98%,其中漏检880个,检测过程中有756个误检,误检率为14.62%。将本文算法与目前常见的深度学习卷积网络人脸检测算法Cascade CNN[17]、Joint Cascade[18]、Head Hunter[19]等进行比较。在对比实验中,所有的测试均使用FDDB测试集。实验对比结果的受试者特征曲线(ROC曲线)见图12。图12中本文算法用红色曲线表示,其他算法曲线来自于FDDB官网公开结果数据。由图12可见,本文算法在假正率较低时真正率可达到82.98%。相比于传统算法如Viola-Jones、Pico、Zhu et al有较高的检测精度优势;且其精度与目前流行的深度学习卷积网络Cascade CNN、Joint Cascade差别不大。

图12 FDDB测试集实验对比ROC曲线
另外,将本文算法与传统的Viola-Jones[20]、性能较好的深度学习Cascade CNN、Join Cascade进行时间效率的对比实验。在本地CPU下,取FDDB的2 845张图像测试每张图像的检测时间,检测结果如表1所示,相比于Cascade CNN,本文所提算法的检测效率略低,因为本文算法前3级分类网络的卷积层个数均比Cascade CNN方法多,网络相应较深,因此比Cascade CNN方法的卷积计算过程多,但本文算法在CPU上每张图片的检测速度可达到96 ms,每秒中可达到10 fps以上,基本可以满足一些视频监控中人脸检测实时性的要求。

表1 检测时间效率对比实验
3.2 实验2 与传统的Adaboost算法对比实验
为进一步验证本文所提算法的性能,进行各种复杂自然场景下人脸图像的检测,并将本文算法和传统Adaboost检测算法进行对比。测试数据来自部分网上下载的图片与自己拍摄采集的图片。实验分别给出了复杂姿态、部分遮挡和光照变化等情形下的检测结果,实验中Adaboost设置检测人脸的最小尺寸为24×24像素;尺度变化值设置在1.1~1.4倍之间。部分检测结果对比见图13,其中a1和a3为本算法的检测结果,a2和a4为Adaboost的检测结果;b1和b3为本算法的检测结果,b2和b4为Adaboost的检测结果;c1和c3为本算法的检测结果,c2和c4为Adaboost的检测结果。

(a)复杂姿态

(b)部分遮挡

(c)光照变化图13 本文算法与传统Adaboost算法的部分检测结果对比
由图13中a1,a3,b1,b3的检测效果图可见,在复杂姿态与部分遮挡这两种复杂场景下,本文算法均准确地检测出人脸的位置,而由图13中a2,a4,b2,b4的检测效果图可知,Adaboost算法在这两种场景下未能检测到人脸,本文算法有着较好的检测效果,原因在于:尽管人脸目标整体有较大变化,但对深度学习卷积网络,人脸的局部区域特征仍然是存在的,因而人脸检测受到的干扰较小;反之,Adaboost是利用全局特征来检测人脸,当人脸整体变化较大时,比较容易漏检。对于光照较差的情形,本文算法检测结果不如Adaboost算法,因为Adaboost算法具有比较好的光照不变性,可以较好地去除光照的干扰。
为了更好地突显本文算法的优越性,对多人脸图像进行了检测。图像取自本人生活的照片,能有效地反映实际复杂的自然场景。图像涵盖了正面、侧脸、夸张表情等情况,检测结果见图14。

(a) 本文算法 (b) Adaboost算法图14 本文算法与传统Adaboost算法多人脸检测对比
由图14可见,所检测的图中共含有28个人脸,Adaboost算法的检测结果为:正检人脸数20个,漏检人脸数8个,误检人脸数0个;本文算法的检测结果为:正检人脸数28个,漏检人脸数0个,误检人脸数0个。此外,从检测效果可以看出,本文算法人脸框定的位置比Adaboost算法准确。Adaboost算法的框定位置有明显的偏移不准现象,因此从实验结果可以看出,本文算法在复杂姿态和部分遮挡等情形下的检测准确性和鲁棒性更好。
5 结束语
针对于自然场景下人脸检测存在的多种表情姿态、遮挡和光照等问题,提出1种基于4级级联全卷积神经网络的人脸检测算法。该算法将深度学习卷积网络与级联思想相结合,同时采用全卷积的网络结构,建立了高效深度卷积模型来实现复杂自然场景下的人脸检测。实验表明,本文算法对于自然场景下的人脸检测具有较强的鲁棒性,在复杂姿态部分遮挡场景下具有较高的检测准确率。下一步的工作将对光照不变性进行研究,以增强算法在光照变化情况下人脸检测的鲁棒性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
电子制作(2019年11期)2019-07-04 00:34:38
动漫星空(2018年9期)2018-10-26 01:17:14
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
发明与创新(2015年33期)2015-02-27 10:40:09
