
图像搜索环境下用户满意度预测方法研究
2019-02-15 11:20陈雪松张帆刘奕群罗成张敏马少平
山西大学学报(自然科学版) 2019年1期
陈雪松,张帆,刘奕群*,罗成,张敏,马少平
(1.青海大学 计算机技术与应用系,青海 西宁 810016;2.清华大学 计算机科学与技术系,北京信息科学与技术国家研究中心,北京 100084)
0 引言
这是一个数据的时代,人们每天都被大量的数据包围着,网络上的数据资源更是不可胜数,如何从海量的数据中尽快地且高质量地寻找出所需数据的需求,催生了信息检索学科[1-2]的发展。信息检索的一个重要载体是搜索引擎,当人们遇到问题的时候,便会通过搜索引擎寻找答案。
目前,广泛应用的信息检索方式是网页搜索,随着日益增长的物质文化需求,用户对网页搜索形式的文本检索有了更高的要求,同时,也希望能搜索到更多类型的信息,比如图像、音乐、视频等等。图像搜索便是一个应运而生的信息检索场景。在图像搜索环境下,用户有着多样的搜索意图[3-4]。演讲者作汇报展示时,会寻找恰当的图片辅助表达自己的主题;行人走在路边遇到不认识的植物,希望图像搜索能够满足自己的知识需求;办公人员在烦躁的时刻也希望能通过搞笑图片调节自己的情绪。获取用户在不同搜索意图下的满意度是提高搜索引擎性能和竞争力的重要方式。实际搜索环境下,收集每次查询会话后的用户满意度将会是一种花费很大并且难以实施的方法,也会对用户的搜索体验产生负面影响。最近的研究表明,网页搜索场景下,用户在浏览过程中与搜索引擎的交互行为如鼠标的移动、点击,滑轮的滚动等,都是预测满意度的强信号[5-8]。借助于用户和搜索引擎的交互行为对用户满意度进行预测的方法可大致总结为两种:一是从交互行为信息中设计特征来预测满意度[3,9],二是对用户的动作序列进行建模来预测用户满意度[10-11]。

Fig.1 Difference between web search and image search图1 网页搜索和图片搜索区别示意图
从网页搜索到图像搜索,如图1所示,整体搜索结果(Search Engine Result Pages,SERPs)的展示形式由一维变成了二维;每个搜索结果的展示内容由标题加摘要变成了缩略图加关键字;同时,翻页的控制方式也由点击按钮变成了滚动滑轮。图像搜索和网页搜索在搜索结果的展示方式,用户与搜索引擎的交互方式等方面的改变,势必影响了用户与搜索引擎的交互行为。在图像搜索环境中,用户与搜索引擎的交互行为的变化决定了用户满意度的预测方法需要重新考量。
本文收集了图像搜索环境下,1 500多个用户查询会话中的交互行为和用户满意度的反馈,分析了衡量搜索引擎性能的评价指标在图像搜索环境下的表现情况,根据指标表现来设计用户在浏览过程中的动作特征,将其作为梯度提升决策树算法(GBDT)的特征来训练模型从而预测用户满意度,同时将用户在浏览过程中,存在的动作作为马尔可夫模型(Markov Model)的状态,根据动作序列,生成用户在满意和不满意查询下的状态转移概率图,对用户满意度进行预测。最后,本文设计了GBDT和马尔可夫模型的组合模型来预测用户满意度,准确率达到了78%。
在20世纪90年代,用户满意度首先被Su引入到信息检索领域[12],用来表示当用户拥有一个查询需求或者目标的时候,他对于搜索引擎返回结果的满意程度。Jones等人[13]强调了用户满意度的重要性并且将其作为信息检索评估的基础。用户满意度在信息检索评估中占有了极其重要的地位,因此有了很多相关的工作。Al-Maskari[14]调研了在信息检索中,影响用户满意度的一些因素。Wang等人[15]论证了用户的满意程度在搜索结果相关性评估和查询建议条目中的重要作用。Hassan的工作表明[16],用户满意度在衡量搜索引擎性能时的价值比查询和结果的相关性更重要。用户满意度的重要性引导着预测用户满意度工作的开展。他们通过三种不同的方式来衡量点击到访页面(Landing Page)停留时间,进而对单次点击的用户满意度进行预测。也有学者[8]创新性地建立起鼠标的移动轨迹中存在的模式来预测用户满意度。同时,Mehrotra等人[17]通过用户在查询过程中点击、滚动等动作的次序对用户满意度进行预测。随着移动端搜索流量的增加,很多学者也开始关注移动搜索场景下,用户满意度的预测方法。
本文在选择GBDT模型特征时,参考了搜索引擎性能的评价指标[18-20]。搜索引擎性能评价的方式主要包括离线评价方式和在线评价方式。其中离线评价方式考虑了查询文档对的相关性、结果的位置、用户的执着程度等因素,该评价方法需要外部评估人员进行标注,成本较高,因此本文不采用离线指标作为特征对用户满意度进行预测。对于网页搜索中被广泛使用的在线指标,如点击率、点击结果排名、UCTR、PLC等,本文通过基于Concordance的区分度等指数来衡量这些指标在预测用户满意度中的效用,将效用高的指标选为特征,用来训练模型,预测满意度。同时,本文针对图像搜索场景,提出了一些新的特征。
本文所使用的马尔可夫模型主要考虑了在查询过程中,连续的动作所存在的潜在的关系对用户满意度的影响。Hassan[6]比较了成功的查询和不成功的查询中动作的状态转移概率问题,并通过马尔可夫模型预测用户的查询是否是一次成功的查询。Wu等人[21]提出了一些预测用户满意度时,可以作为马尔可夫状态的用户动作。本文考虑了用户在查询过程中,不同的动作转移应占有不同权重的问题,并且总结了满意和不满意查询中存在的典型的动作转移模式。
1 实验数据收集
实验采用在校内有偿招募被试者的方式收集数据,被试者依次来到实验室,在指定的机器上进行指定任务的图像搜索,在每次查询会话完成后,被试者需进行满意度打分。
1.1 实验环境
在该实验数据收集过程中,被试者通过Google Chrome浏览器,在17英寸,分辨率为1 366×768像素的LCD显示器上进行图像搜索任务。用户在搜索过程中所有的查询内容、鼠标移动、点击、划入(划出)元素、滑轮的滚动、标签的切换等信息都会被记录下来。
1.2 实验过程
本实验在高校招募了36名本科生(13名女生和22名男生),年龄分布在18到25周岁,来自于工科、人文、社会科学和艺术院系等。所有的被试者在实验之前均有图像搜索的经历。
实验开始前,被试者首先要完成一个热身性质的图像搜索任务,从而熟悉整个用户实验。然后被试者按照网页提示的信息依次进行12个图像搜索任务。对于每一个任务,被试者会首先看到任务的描述信息,该描述信息用来模拟真实搜索中的用户需求,比如说通过图像搜索引擎找到一张哈利波特的海报用来做PPT。实验的具体流程如下:
被试者先读任务描述,然后用通俗的语言把任务重述一遍,保证彻底理解了模拟的用户需求。然后,被试者点击“开始任务”按钮进行图像搜索。当被试者认为任务完成或者找不到满意的结果时,便可以点击“结束任务”按钮来结束。任务结束后,被试者在该任务下的每次查询内容将再次展示出来,实验会要求被试者对每次查询进行5个等级的用户满意度打分。
2 GBDT模型
本文通过评测在线指标与用户满意度(5级标注)的Pearson相关系数和Concordance一致性指数及基于Concordance的区分度指数进行GDBT模型特征的选择,利用sklearn中GradientBoostingClassifier分类器进行训练,采用十折交叉验证的方式进行模型评价。
2.1 特征显著性评测方法
Pearson相关系数和Concordance一致性指数为常用的相关性评价指标,本文不再具体介绍。基于Concordance的区分度指数算法设计如下:
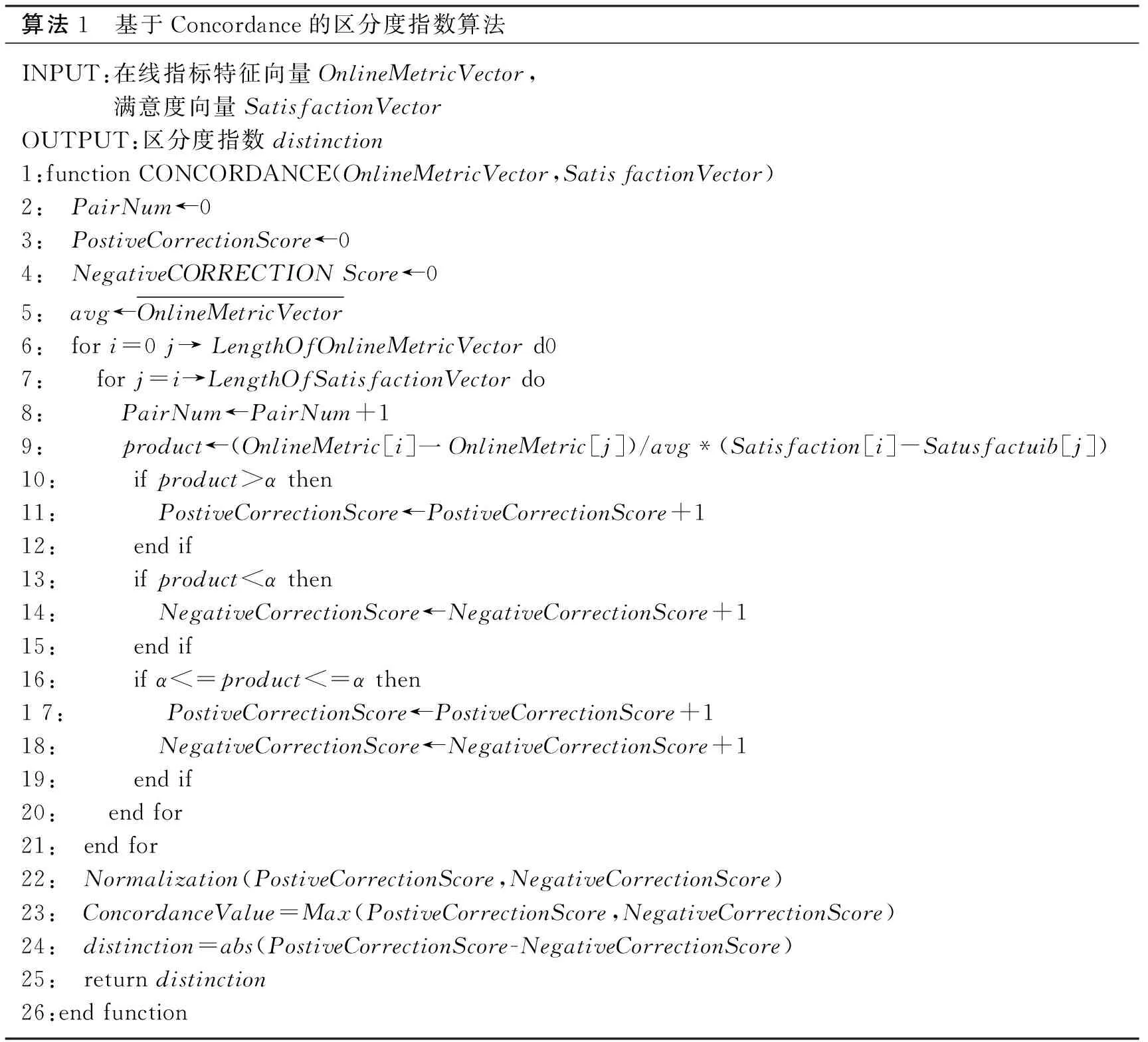
算法1 基于Concordance的区分度指数算法INPUT:在线指标特征向量OnlineMetricVector,满意度向量SatisfactionVectorOUTPUT:区分度指数distinction1:function CONCORDANCE(OnlineMetricVector,Satis factionVector)2: PairNum←03: PostiveCorrectionScore←04: NegativeCORRECTION Score←05: avg←OnlineMetricVector6: for i=0 j→ LengthOfOnlineMetricVector d07: for j=i→LengthOfSatisfactionVector do8: PairNum←PairNum+19: product←(OnlineMetric[i]一OnlineMetric[j])/avg*(Satisfaction[i]-Satusfactuib[j])10: if product>α then11: PostiveCorrectionScore←PostiveCorrectionScore+112: end if13: if product<α then14: NegativeCorrectionScore←NegativeCorrectionScore+115: end if16: if α<=product<=α then1 7: PostiveCorrectionScore←PostiveCorrectionScore+118: NegativeCorrectionScore←NegativeCorrectionScore+119: end if20: end for21: end for22: Normalization(PostiveCorrectionScore,NegativeCorrectionScore)23: ConcordanceValue=Max(PostiveCorrectionScore,NegativeCorrectionScore)24: distinction=abs(PostiveCorrectionScore-NegativeCorrectionScore)25: return distinction26:end function
在算法1中,在线指标特征向量OnlineMetricVector的定义为
(1)
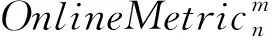
(2)
其中Satisfactionn表示第n次查询中,用户的满意度情况。
在Concordance算法中,由于在线指标特征数值较多,并且存在一定的计算误差(鼠标移动距离,滑轮滚动等都不是绝对精确的数值)对于任意两个对应位置上归一化后的在线指标特征和用户满意度数值相差不大时(即绝对值小于α),则认为该对位置上的值既支持两个向量呈正相关,又支持两个向量呈负相关。如果该种位置对数量较多,就会导致两个向量的正相关和负相关Concordance一致性指数都比较大,但是该在线指标特征并不能很好地体现出用户的满意度,为了解决此类问题,本文提出了基于Concordance的区分度指数,其数值大小体现了支持两个向量正相关和负相关的差值。该区分度指数与Concordance一致性指数在衡量在线指标是否可以作为GBDT模型特征时各有所长,本文在选取作为模型特征的在线指标时综合考虑了Pearson相关系数和上述两个指数。
2.2 模型特征
在传统的网页搜索中,常用的在线指标汇总如表1所示。

表1 在线指标及其描述
本文充分考虑了图像搜索场景下的应用环境,提出了如下特征:
Query id:query id中的id表示在同一查询任务下,当前查询属于该任务中的第几次查询。该特征与用户满意度呈一般负相关,也就是说,在同一任务下,用户的查询次数越多,越容易出现不满意的查询。
LastClickToEnd:用户在当前查询下,最后一次点击的时间点与查询结束的时间点之间的时间长度。该指标与用户满意度呈现较强的负相关性。也就是说,用户在点击图片后,与结束查询的时间越短,满意程度越高。如果用户在查询结束和最后一次点击之间存在较多的动作,比如说hover(鼠标悬浮),scroll(滑轮滚动)等,就意味着用户还在寻找着更合适的图片,容易感到不满意。现有的结论表示用户的最后一次点击一般是得到了满意的结果来结束查询,用户满意后就会停止查询,用户最后一次点击发生后,结束查询的时间越短,用户满意的可能性就越大,该指标能体现用户的这种行为。
QueryTermNum:用户使用图像搜索引擎时,输入的查询内容不同,对图像搜索引擎返回的结果的期望不同。比如说用户输入“衬衫”和“宽松款女士白色衬衫”时,前者表示用户对搜索引擎有一个宽泛的要求,只要是衬衫即可,后者表示用户对图像搜索引擎返回的属性有了“宽松款”、“女士”、“白色”的要求,期待搜索引擎的返回的结果能够满足所有属性,因此,需要有一个对查询内容复杂度衡量的指标。借助自然语言处理(NLP)中的jieba分词工具,对用户提交的所有query进行分词处理。去掉了查询内容中的停用词、连词等,对查询内容中剩下的以形容词、名词为主的单词进行加权、计数得到一个简单的用于估计查询内容复杂度的数值。结果表明,该数值与用户满意度存在较弱的负相关,即查询内容中包含单词越多,数值越大,用户满意度越低。也就是说用户提交的查询内容中包含的查询词越多,搜索引擎越难以让用户满意。
Distribution:在查询中,将鼠标悬停时间、鼠标的移动距离和鼠标的移动速度划分为不同的区间,统计不同区间中特征在特征总数的占比,用来作为在线指标。其中鼠标移动速度特征表现较好。对于鼠标移动速度来说,鼠标移动速度非常快([0,0.5]px/ms)的比重越大用户在查询中越容易不满意,鼠标移动速度在[0.5,∞px/ms]的比重越大,用户越容易满意。换句话说,用户鼠标移动速度快的比例大,代表着用户没有在搜索结果页面中检查到满意的结果,是一种不耐烦的表现。
NonMoveTimeRatio:已有研究表明[22],在以文字为主的网页中,鼠标移动和人的注意力有很高的相关性,因此,用户在鼠标移动和鼠标不移动的两个状态下,对搜索结果页面的检查方式不一样。在鼠标不移动的状态下,搜索结果中很有可能有用户感兴趣的内容,用户的注意力集中,注意力切换较慢;在鼠标移动的状态下,用户在查找内容,注意力切换快。在一次查询会话中,用户注意力集中的时间的比例可通过如下公式计算(T[start,end]表示该次查询会话的总时间,Tmouse_movei表示第i次鼠标移动的时间),将该比例作为指标,表现较好。
(3)
2.3 特征筛选
指标TTFC,TTLC,LCTE的应用场景是在查询会话中存在至少一次点击的情况,但在用户的实际搜索中,有些查询会话并不存在点击行为,对于该类会话,假定点击行为发生的时间距离标记时刻(TTFC和TTLC的标记时刻是查询会话开始的时刻,LCTE的标记时刻是查询会话结束的时刻)无穷远。根据2.1节中所提出的特征显著性评测方法,对2.2节中所有特征进行筛选,筛选后的特征及其在3种评测方法下的表现如表2所示。

表2 GBDT特征显著性评测结果

Fig.2 Performance to predict user satisfaction by our designed features图2 本文所设计特征在预测用户满意度时的表现
2.4 模型效果
本文首先把用户满意度分成两类,用户满意度为4,5的查询看作是用户满意的查询,用户满意度为1,2,3的查询看作是用户不满意的查询。除本文提出的5个特征外,剩余的所有在线指标为特征训练的模型作为baseline。图2展示了本文所设计的特征在预测用户满意度时的表现,所有特征对预测用户满意度均有不同程度的贡献。
将上述所有的在线指标作为特征用于常见分类器的训练,如k-近邻(KNN)、支持向量机(SVM)、朴素贝叶斯(Naive Bayesian)、GBDT等模型,同时把Wu等人[17]工作中所设计的特征训练生成GBDT模型的表现作为Baseline,所有模型的性能对比如表3所示。

表3 模型性能对比图
通过上表可以看出,在所有的分类器中,GBDT模型表现最好。两个GBDT模型作为对比,本文所采用的特征训练所得的模型表现较好,精度提高了3.77%,同时在Wu的工作中,用到的特征数量是33个,在本文的模型中,用于GBDT模型的特征数量有23个。
3 马尔可夫模型
3.1 马尔可夫基准模型
在马尔可夫模型中,本文考虑了用户在整个查询会话中,动作转移概率的问题。比如说从查询开始到点击动作,从点击动作到滑轮滚动动作等动作间的转移概率。本文将所有的动作划分为了六类,具体动作及其描述如表4所示。

表4 马尔可夫模型中动作状态及其描述
本文首先将数据集划分为训练集和测试集,在训练集中,将其划分为用户满意的数据集部分和用户不满意的数据集部分,为两部分数据集生成两个状态转移矩阵,也就意味着生成了用户满意情况下的状态转移图和用户不满意情况下的状态转移图。用户满意情况下的状态转移图如图3所示,用户不满意情况下的状态转移图如图4所示。
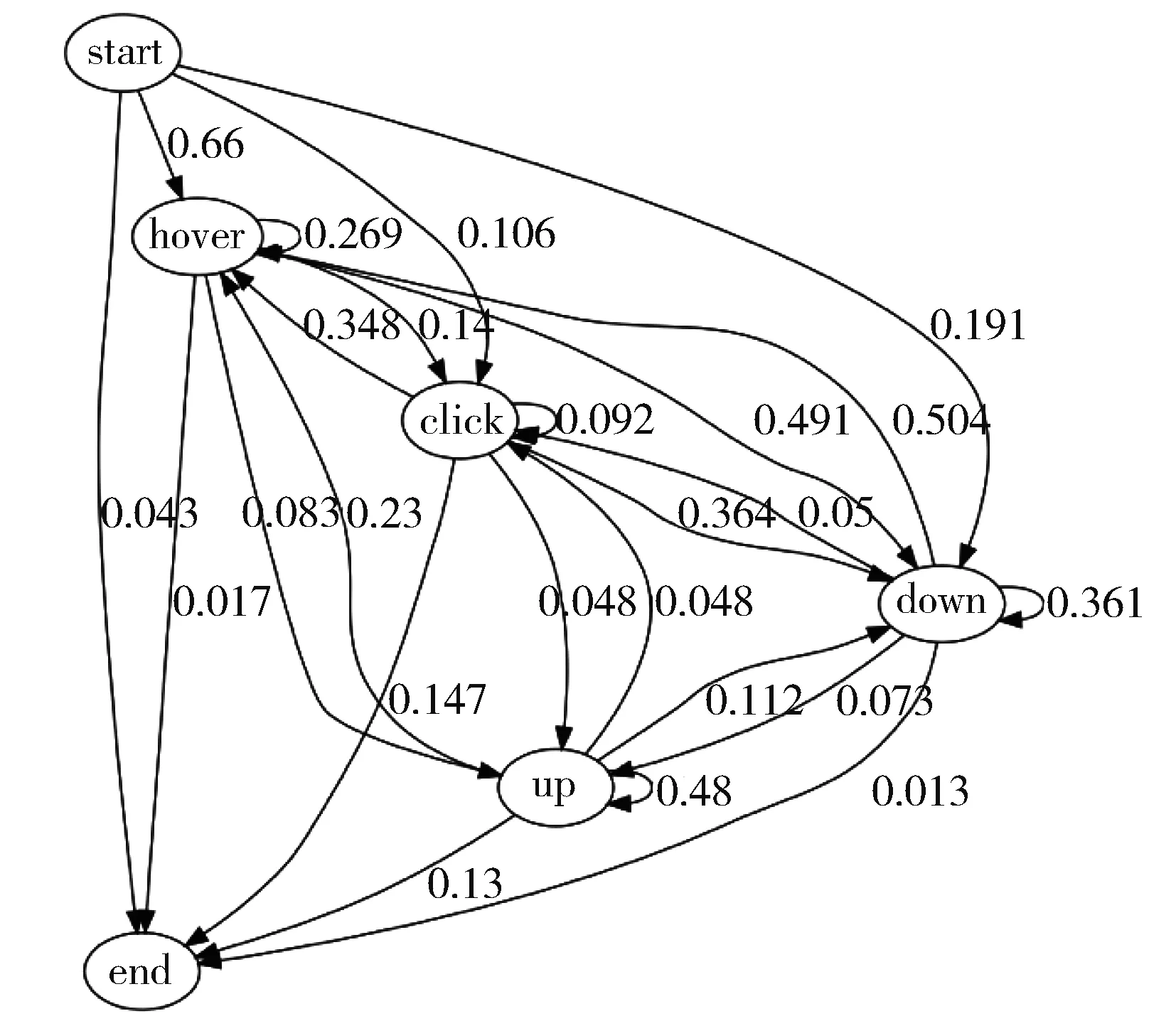
Fig.3 Transition diagram under satisfaction图3 用户满意情况下的状态转移图

Fig.4 Transition diagram under dissatisfaction图4 用户不满意情况下的状态转移图
根据测试集中一次查询会话中的动作序列来预测用户满意度时,两个状态转移图均可计算当前查询所包含的动作序列的得分。该查询在哪个状态转移图的得分越高,就可以说明该查询中的动作序列更符合其状态转移图的预测结果。将此马尔可夫模型作为baseline。
3.2 典型动作模式
对于马尔可夫模型中存在的任意两个动作转移,它支持所在查询是满意或者不满意的程度不同,通过比较用户满意和不满意情况下,状态转移概率的比值,可以将两种情况下的典型动作模式筛选出来。典型动作模式生成算法如下。

算法2 用户在满意和不满意查询中典型动作模式得分算法INPUT:用户在满意查询中的状态转移矩阵SatTransitionMatrix,用户在不满意查询中的状态转移矩阵DSatTransition-MtrixOUTPUT:满意查询中的动作模式SatActionPattern,不满意查询中的动作模式DSatActionPattern1:function GETACTIONPATTERN(SatTM = SatTransitionMatrix.DSatTM = D SatTransitionMtrixl2: states←[start,hover,click,down,up,end]3: for OriginaIState=start→end do4: for DestinationState=start→end do5: SatOvetDSatValue← SatTM[OriginalState][DestinationState]/DSatTM[OriginaIState][DestinationState]6: DSatOverSatValue← DSatTM[OriginaIState][DestinationState]/SatTM[OriginalState][DestinationState]7: if Sat0verDSatValue>1+α then8: SatActionPattern[OriginalStatel][DestinationState]←SatOverDSatValue9: end if10: if DSatOvetSatValue>1+α then11: DSatActionPattern[OriginalState][DestinationState]←DSatOverDSatValue12: end if13: end for14: end for15:end function
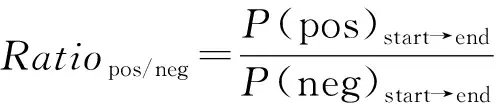
用户在满意或者不满意情况下,存在的典型动作模式如图5和图6所示。

Fig.5 Typical action pattern under satisfaction search图5 用户在满意查询中的典型动作模式

Fig.6 Typical action pattern under dissatisfaction search图6 用户在不满意查询中的典型动作模式
如果用户在一次查询会话中的动作序列为{start, click, end},该序列是用户在满意查询下典型动作模式中所存在的序列,在该典型动作模式中得分较高,故而用户该次查询满意的概率较大。
3.3 加权马尔可夫模型(weighted Markov Model)
通过对查询结束前一个动作内容(包括start,scroll,hover,jump in, jump out)进行统计分析,得到不同满意度下的查询结束前动作分布图(见图7),由动作分布图可以看出,用户满意度较低(用户满意度为1,2,3)的查询中,用户一般以scroll结束查询,用户满意度高的查询中,用户会以jump in(鼠标点击图片链接后返回搜索结果页面)结束查询。用户以scroll作为查询结束的最后一个动作,意味着用户在结束当前查询前,仍然用鼠标滚动滑轮,试图寻找着满意的答案,该行为是用户不满意的一个强信号;用户以jump in作为查询结束的最后一个动作,意味着用户在搜索结果页面中点击了一个图片链接,用户在检查landing page(图片详情页面)后,对整个查询是满意的,回到搜索结果页面(jump in)后,就直接结束了当前查询。因此,加权马尔可夫模型提高了这两个动作预测用户满意度时的权重。

Fig.7 Distribution of last action before query session under different user satisfaction图7 不同满意度下的查询结束前动作分布图
4 混合模型
最后,本文将GBDT模型和马尔可夫模型结合对用户满意度进行预测。首先,在马尔可夫模型中抽取出了两类特征,一类是马尔可夫模型的预测输出值,一类是马尔可夫模型中所存在的典型动作模式的得分情况。
(1) 马尔可夫模型预测结果作为特征:马尔可夫模型的输出值可以为GBDT模型提供2维的特征,一维是用户是否满意(0或者1,离散值),一维是用户满意或者不满意的可能性(1左右的值,比1越大,代表模型认为用户满意的可能性越大,比1越小,代表模型认为用户不满意的可能性越大,连续值)。
(2) 马尔可夫典型动作模式作为特征:分别计算要预测查询会话中存在的动作转移在用户满意和不满意情况下典型动作模式图的总得分作为GBDT模型的特征,对用户满意度进行预测。
本文将抽取的马尔可夫模型的特征添加至GBDT模型已有的特征中,生成GBDT+马尔可夫特征模型(GBDT+Markov’s features Model),对用户满意度进行预测。同时,对于同一查询会话的用户满意度预测,GBDT模型和马尔可夫模型都会有一个预测结果,本文提出的GBDT与马尔可夫置信度选择模型(Confidence Selection Model)是将两个模型中置信度高的结果作为对用户的满意度预测的最终结果。
5 模型表现
将GBDT模型和马尔可夫基准模型作为baseline,本文提出的所有拓展模型的表现如表5所示(其中,括号中第一个值代表相对于马尔可夫基准模型的表现,第二个值代表相对于作为baseline的GBDT模型的表现)。

表5 模型性能表
在所有模型中,GBDT与马尔可夫置信度选择模型的预测结果的效果最好,预测的精度达到了78.1%。整体上来看,GBDT相关的模型比单纯基于马尔可夫模型的相关模型(马尔可夫基准模型和加权马尔可夫模型)表现要好一些。
6 结论
用户满意度是衡量搜索引擎性能的关键因素。准确地预测用户满意度可以辅助搜索引擎不断改良,从而具有更高的行业竞争力。在传统的网页搜索中,根据用户与搜索引擎交互过程中存在的特征和用户使用搜索引擎时的动作序列能够准确地预测用户的满意度。相较于网页搜索,图像搜索引擎提供了不同的结果展示方式,改变了用户与搜索引擎的交互行为。本文围绕着图像搜索环境下的用户满意度预测方法进行设计、研究。
本文首先提出了基于Concordance的区分度指数,用来衡量用户与搜索引擎之间的交互信息中存在的一些特征在预测用户满意度时的效用。其次,针对图像搜索环境下,提出了的新的特征来描述用户与图像搜索引擎间的交互行为,进而预测用户满意度。并设计算法总结出了用户在满意查询和不满意查询中存在的典型动作模式。最后,本文整合了用户的行为特征,动作模式,动作状态转移情况等,设计出的模型在预测用户满意度时的准确率达到了78%左右。本工作对在线指标的设计,用户满意度的预测等相关领域的研究都有着一定的参考价值。
本文中所使用的数据集包含了约1 500次本科生进行图像搜索的信息,是一个较小的数据集,该数据集在被试者的职业、年龄上存在局限性,因此所提出用户满意度预测模型的泛化能力有待评价。由于数据集较小,对于用户在搜索过程中的动作类型区分较少,用户的行为特征提取较为宽泛,也是导致用户满意度的预测精度不是很高的原因之一。在实际的图像搜索环境中,用户可以同时看到多个搜索结果,在对比图像结果后才进行点击查看,图像本身的吸引性等内容特征也对用户的满意度影响较大,因此用户与图像搜索引擎存在着更多、更复杂的交互行为有待研究。同时,如何更好地解释用于预测用户满意度的特征的含义也是今后的研究方向之一。
猜你喜欢
疯狂英语·新阅版(2020年11期)2020-12-21
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
西南民族大学学报(自然科学版)(2018年1期)2018-03-22
中国卫生(2015年12期)2015-11-10
中国民航大学学报(2015年3期)2015-03-01
郑州大学学报(理学版)(2014年4期)2014-03-01
发明与创新·中学生(2014年1期)2014-01-24
科学导报·学术论坛(2013年5期)2013-06-26
微型计算机·Geek(2009年1期)2009-12-15
