
结合词性、位置和单词情感的内存网络的方面情感分析
2019-02-15 09:21王行甫苗付友邵晨曦
小型微型计算机系统 2019年2期
王行甫,王 磊,苗付友,邵晨曦
(中国科学技术大学 计算机科学与技术学院,合肥 230027)
1 引 言
随着互联网的快速的发展,网络上出现了大量包括评论信息的网站,比如在电商中用户对商品和商家的评论,外卖网站中对于食品、价格等方面的评论.这些信息是用户对商家服务、商品的反馈,这些反馈包含了用户对商品和服务的满意程度,如果利用好这些反馈能够帮助商家及时进行改善,这个也促使了网络评语情感分析的发展.
情感分析主要包括基于文档的情感分析,基于句子的情感分析,还有基于方面的情感分析.由于一个网络评论中往往中包含多个方面的评论,所以基于方面的情感分析是比较适合网络评语的情感分析的,比如“Great food but the service was dreadful!”这句话包含了对food和service两个方面的评论,但是情感却是相反的.
目前主流的情感分析算法包括基于特征工程的算法和基于深度学习的算法.文献[1]首先获取ngram特征、解析特征和基于情感词典的特征,然后将这些特征送入到SVM中进行分类,最终将算法应用到客户评论中并获得了很好的效果.文献[2]利用单词的正向情感值、负向情感值生成情感特征向量,然后在通过MNB、SVM等机器学习方法训练后应用到Twitter推文中进行情感分析取得了非常好的效果.文献[3]提出使用递归神经网络(RNN)对影评进行情感分析,取得了当时最好的效果.文献[4]在文献[3]的基础上扩展了RNN,并利用句子的依赖树和构成树来解决基于方面的情感分析.文献[5]首先利用CNN(Convolutional Neural Network)或LSTM(Long Short-Term Memory)去编码文档中的句子,然后在用GRU(Gated Recurrent Unit Recurrent Neural Networks)去编码所有句子作为文档的代表进行情感分析.文献[6]在LSTM中融入了方面的信息去编码句子进行情感分析,并且通过实验表明没有融入方面信息的LSTM在情感分析中的效果并不好.文献[7]在LSTM的基础上加入了关注机制,该关注机制能够在输入不同方面的情况结合句中不同的部分作为输入.文献[8]在LSTM的基础上,提出了一种具有层次结构的双向LSTM去解决基于方面情感分析的问题.文献[9]中采用了CNN去解决文本分类问题,并获得了令人满意的效果.文献[10]首次利用深度学习的方法去自动提取句子中方面,然后结合情感分析的算法获得了相当不错的效果.文献[11]中首先利用带有条件随机场的双向LSTM将不同的句子划分成不同类别,然后利用CNN对不同类别的句子进行情感分析.文献[12]提出了一种叠加神经网络,该网络首先利用RNN和CNN的混合网络来提取句中方面和评语,然后利用RNN分析评语的情感,最后利用一个RNN来匹配方面和评语,通过实验表明了算法的有效性.
尽管上面提到的基于深度学习的方法在情感分析问题上都取得了不错的效果,但是这些方法都存在一个潜在的不足,没有能够利用句子(上下文)中单词情感信息(积极的、消极的还是中性的),但是单词情感在情感分析中却非常重要,这也是基特征工程的算法[1,2]能获取成功的原因之一.比如在句子“Great food but the service was dreadful!”中,由于对food这个方面的评论是Great,并且Great的情感极性是积极的,所以句子对food的评论是积极的;对service这个方面的评论是dreadful,而dreadful的情感极性是消极的,所以对service的评论是消极的.如果在句子中不知道一个单词的情感,可能就无法判断了,比如“这道菜很XXX”这句话中对菜的评论是XXX,如果不知道单词XXX的情感信息是没法判断句子对菜的情感.其实不管XXX是什么单词,只要它的单词情感是积极的,那么这句话对菜的评价就是积极的,比如XXX是“美味”;只要它的单词情感是消极的,那么对这句话对菜的评价就是消极的,比如XXX是“难吃”.
另外在基于方面的情感分析中,句子(上下文)中不同单词对于推测方面情感的重要性是不同的,其实这可以看作是提取方面和句中单词相关性的问题.最近几年,关注机制(attention mechanism)在提取上下文中不同部分和目标相关性上受到了非常大的关注.文献[13]认为只利用编码器产生的固定大小的向量作为解码器的输入是机器翻译的瓶颈,因为当输入链很长的话,用固定大小的向量会损失很多信息,所以在解码器中加入对输入句子的局部关注机制,从整个上下文中获得信息,通过实验结果表明效果很好.文献[14]在深度卷积神经网络编码器中加入了局部关注机制后,将其应用到句子摘要生成当中也获得了很好的效果.文献[15]利用端到端内存网路(End To End Memory Network,ETEMN)中局部关注机制分析上下文中不同部分和问题的相关性,并应用到问答系统中同样获得了非常好的效果.
虽然上面各个算法中的局部关注机制都取得了非常好的效果,但是在基于方面的情感分析中,单词的词性(Part of Speech,POS)、方面和单词间的位置信息其实是可以帮助分析句子中不同单词和方面之间的相关性的.比如句子“Great food but the service was dreadful!”中和food相关性最高的Great是形容词,和service的相关性最高的dreadful也是形容词,根据经验在句子中最频繁用于表达情感的也是形容词.另外由于句中Great和dreadful都是形容词,那么如何判断food和Great相关,service和dreadful相关呢?单词和方面之间的位置信息可以在一定程度上帮助决定.Great和food的距离为1,Great和service的距离为4,所以Great和food相关性可能更高;dreadful和service的距离为2,dreadful和food的距离为5,所以dreadful和service相关性可能更高.
基于上面的分析,本文在结合ETEMN、单词情感信息、词性和位置信息后提出了一种结合词性、位置和单词情感的内存网络(memory network with POS,position and polarity of word,MNPOSPP),该网络首先在词向量的基础上加入单词情感信息,然后利用一种结合词性、位置信息的CNN关注机制(CNN attention mechanism with POS and position,POSP-CNNAM)来分析句中单词和方面之间的相关性并生成上下文向量(句子)用于基于方面的情感分析.
2 基本理论
2.1 端到端内存网络
端到端内存网络是一个递归关注模型(recurrent attention model,RAM),带有一个额外的内存用来保存上下文,在文献[15]中该模型被用于问答系统.该模型首先接受一系列输入X={x1,x2,…,xn}作为问题的上下文,在通过转化成词向量XV={xv1,xv2,…,xvn}后保存在内存当中,xvi的维度为d.然后接受一个提问Q={q1,q2,…,qm},通过词向量转换获得QV={qv1,qv2,…,qvm}后进行一定方式转换获取Q的内部状qh,比如通过乘以一个矩阵,qvi和qh的维度都是d.之后利用qh对XV进行局部关注,判断qh和XV中各个部分的相关性,具体的方式如下:
pi=softmax(qhT*xvi)
(1)
(2)
(3)
公式(1)中pi表示qh和xvi的相关程度,*表示矩阵乘法.公式(3)中o表示上下文经过局部关注后的输出,代表X,其中ci∈C={c1,c2,…,cn}是X的另外一种词向量表示,⊙表示点乘.因为ETEMN是一个递归的关注模型,所以o可以用来下一次递归的输入,具体方式如下:
qhk+1=qhk+ok
(4)
公式(4)中qhk、qhk+1分别表示第k、k+1次关注的qh,ok表示第k次局部关注后的上下文的输出.如果o不作为下一次递归的输入,它就和qh一起作为分类器的输入,如公式(5)所示,其中W是一个待学习的权重参数:
Y=softmax(W(o+qh))
(5)
2.2 卷积神经网络
CNN是一个前馈神经网络,在图像处理和自然语言处理中都取得了非常大的成功.CNN的结构主要包括输入层,卷积层、池化层、全连接层和输出层,其中卷积层和池化层可以交替重复设置.卷积层和池化层在CNN是最重要的,卷积层用一个或多个大小为n*n的卷积核对上层的输入进行特征提取,然后将提取出的特征交给池化层进行组合形成更抽象的特征,如此反复最终获得输入的特征描述.CNN的具体结构如图1所示,其中C1、C2分别是卷积层,P1和P2分别是池化层.

图1 CNN结构Fig.1 Structure of CNN
3 结合词性、位置和单词情感的内存网络
通过上面ETEMN的介绍,可以判断ETEMN是非常适合做基于方面的情感分析的,因为基于方面的情感分析可以看作是提取句中单词和方面相关性的问题,给出一个句子和方面,然后通过ETEMN的局部关注机制获取句子中各个单词和方面的相关性,并在获取句子一个最好的内部表示后进行分类.比如给出句子“Great food but the service was dreadful!”和方面food,如果ETEMN能够算出food和Great的相关性为1,和其他单词相关性为0的话,那么ETEMN就能够很好分析出句子对food的情感了.但是ETEMN有两个缺点:
1)ETEMN只是简单的通过softmax词向量和方面的乘积来获取方面和句中单词相关性.这种做法过于简单并且没有利用好句子的内部信息,比如句中每个单词的词性、单词和方面之间的相对位置,这些信息其实是可以帮助计算单词和方面的相关性的;
2)即使ETEMN能够很好的分析出方面和句中单词的相关性,但是在ETEMN中也只能获取单词的词向量,并没有能够获取单词的情感信息,单词的情感信息对推测方面的情感是非常重要的;
针对这两个问题,本文提出了一种结合词性、位置和单词情感的内存网络(memory network with POS,position and polarity of word,MNPOSPP),相较于ETEMN,该网络有两个优点:
1)为了弥补ETEMN只能获取单词词向量,没法利用单词情感的问题,MNPOSPP在结合情感词典SentiWordNet的情况下,在词向量中融入了单词情感信息.
2)为了能够更好的利用句中单词词性、方面和单词间位置信息,本文提出了一种结合词性、位置信息的CNN关注机制(CNN attention mechanism with POS and position,POSP-CNNAM)来分析句中单词和方面之间的相关性.
接下来本文将首先介绍MNPOSPP的整体架构,然后介绍POSP-CNNAM,之后介绍如何获取给定句子的词向量、单词词性、单词情感信息以及单词和方面之间的距离,最后介绍如何训练MNPOSPP.
3.1 整体架构
假设在给定一个包含n个单词的句子s={w1,w2,…,wn}和包含m个单词的方面aspect={wi,wi+1,…,wi+m-1}后就已经知道了s的词向量sv={wv1,wv2,…,wvn}(wvi维度是dwv)、aspect的词向量aspectv={wvi,wvi+1,…,wvi+m-1}、s中每个单词的词性pos={pos1,pos2,…,posn}(posi是一个向量,维度是dpos)、情感信息ss={ss1,ss2,…,ssn}(ssi是一个向量,维度是dss)以及单词和方面的距离dis={dis1,dis2,…,disn}(disi是一个向量,维度是ddis).
图2描述了一个具有3层关注机制的MNPOSPP,左上角的memory={memory1,memory2,…,memoryn}是句子词向量sv和单词情感信息ss的结合,具体结合方式如下:
memoryi=wvi⊕ssi
(6)
式中⊕是连接的意思,所以memoryi的维度是dwv+dss.左下角的aspect1是aspect的词向量和对应的情感信息的结合,结合方式和memory一致.这里需要注意的是句子不同方面包含的单词数量可能不一样,为了能够统一处理,首先获取包含最多单词的方面中单词数M,然后对于单词数不够M的方面,在aspect1后面补充0向量.所以aspect1的维度为M*(dwv+dss).aspect1在进入第一层关注机制之前进行一次线性转换获得input,具体转换如下:
input=WInput*aspect1
(7)
式中WInput维度为1*M,是一个待训练的权重参数.
然后将input,dis,pos和memory输入到基于CNN的关注模块中去,获得一个output,维度为dwv+dss,对于CNN的关注机制将会在下一节中进行详细的解释.最后将output和input相加得到新的input,如果当前的关注机制是最后一层的话则将新得到的input输入到全连接的网络中进行分类,如果不是最后一层的话,则将其作为新一层CNN关注机制的输入.
3.2 结合词性、位置信息的CNN关注机制
ETEMN中局部关注机制是用来计算方面和句中每个单词相关性的,但是其计算方式过于简单,并没有利用到单词词性、单词和方面之间的位置信息.因为CNN具有很好的局部特征提取的能力,并且句中单词词性和位置信息有助于计算句中单词和方面的相关性,所以本文提出了一种结合词性、位置信息的CNN关注机制(CNN attention mechanism with POS and position,POSP-CNNAM).
POSP-CNNAM是CNN的一个变体,只有卷积层,没有池化层.卷积层是用来计算方面和句中单词相关性的,包含两个卷积核,每个卷机核的宽度为2(dwv+dss),高度为h,分别是通过pos和dis计算得来的,计算方法如下:
posFilter=Wpos1*pos*Wpos2
(8)
disFilter=Wdis1*dis*Wdis2
(9)
公式中的Wpos1,Wpos2,Wdis1和Wdis2都是待训练的权重参数,维度分别为h*N,dpos*2(dwv+dss),h*N和ddis*2(dwv+dss).这里需要注意不同句子中包含的单词数量可能不一样,为了能够使得Wpos1和Wdis1的维度在网络中保持不变,需要保证pos和dis的维度保证不变.所以在将pos和dis带入了公式计算之前,需要先获取包含最多单词的句子中单词数N,然后对单词数不够N的句子的pos和dis后面填充0向量,使它们的维度为N*dpos和N*ddis.

图2 MNPOSPP整体架构Fig.2 Structure of MNPOSPP
另外在计算句中单词和方面相关性之前,首先将memory和input连接得到context={context1,context2,…,contextn},contexti的维度为2(dwv+dss),具体方式如下:
contexti=memoryi⊕input
(10)
接下来利用posFilter和disFilter对context进行卷积获得cPos={cPos1,…,cPosn}和cDis={cDis1,…,cDisn},步长为1,具体方式如下:

(11)
(12)
pi=(1-a)*softmax(cPosi)+a*softmax(cDisi)
(13)
(14)
图3表示了句子“Great food but the service was dreadful!”和方面food的卷积过程,其中h为3.
3.3 获取词向量,pos,dis和ss
在上面我们假设在给定句子s和aspect后就已经知道了对应词向量,单词词性pos,单词和方面之间的距离dis以及单词情感信息ss,接下来将分别介绍如何获取这些信息.
3.3.1 词向量
利用word2vec工具对维基百科上学到的词向量获取句子和方面中每个单词的词向量,每个词向量的维度为300.
3.3.2 单词词性pos
首先利用斯坦福大学的POS Tagger(Part of Speech Tagger)对句子进行词性标注,从而获得每个单词的词性,然后在对每个单词的词性进行one hot编码.由于斯坦福大学的POS Tagger采用了Penn Treebank tag set,这个标签集将单词划分为36种词性,所以每个单词的词性的维度是36.如果给定的单词没有对应的词性的话,直接设置为0向量,比如逗号的词性.

图3 POSP-CNNAM的卷积过程Fig.3 Convolutional process of POSP-CNNAM
3.3.3 单词和方面之间距离dis
句子单词每和方面相差一个位置距离加1,并且单词和方面每存在一个逗号距离加100,之所以这么做是因为在网络评语中一般逗号是用来分割句子对不同方面评论的,比如句子“While the food was good,the service was horrendous”中的逗号就是用来分割句子对food和service两个方面评论的.另外单词和方面之间的距离虽然只是一个值,但是为了后面计算方便,这里表示成包含一个元素的向量.
3.3.4 单词情感极性ss
单词的情感极性通过SentiWordNet中单词的情感分数计算而来.因为SentiWordNet中每个单词在不同词性下的情感分数不同,所以在计算情感分数时需要利用pos,比如good作为形容词和作为名词时的情感分数不同.另外SentiWordNet中单词在不同语境下的情感分数也不同.所以在计算单词情感极性时,首先通过单词词性获取不同场景的情感分数,然后取平均值.因为SentiWordNet中每个单词包含两个分数,积极的分数和消极的分数,所以在表示单词情感极性的时候用一个包含两个元素的数组表示,第一个元素是积极的情感分数,第二个元素是消极的情感分数,另外消极的情感分数用负值表示.比如作为形容词的good的情感分数为[0.62,0],作为形容词horrendous的情感分数为[0,-0.625].如果单词或对应的词性在SentiWordNet中不存在直接表示为[0,0].
3.4 模型训练方法
由于对网络评论进行基于方面的情感分析是一个多分类问题,所以本文选用多分类的交叉墒函数作为损失函数,同时为了防止过拟合,在损失函数中加了L2正则化项,最终目标是使得损失函数最小.

(15)
(16)
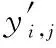
本文使用带有mini-batch的自适应梯度下降法(Adagrad)[17]来训练MNPOSPP中的每个参数,下面给出在t时刻,第i个参数θi,t的更新公式:
(17)
式中η表示初始学习率,gi,t表示在t时刻参数θi的梯度,是一个很小的值,防止分母为0.
4 实验与分析
为了验证MNPOSPP在基于方面情感分类问题上的性能,本文设计了多个算法在2个数据集上的性能对比实验.
4.1 数据集
为了验证MNPOSPP的性能,本文选择了来自于SemEval 2014任务4中的laptop和restaurant数据集,数据集中包括积极的(positive)、消极的(negative)、中性的(neutral)和冲突的(conflict)四种情感类别.但是conflict类别的数据特别少,所以在实验的过程中本文只选取了前三个类别的数据.表1展示了两个数据集在训练集和测试集中每个类别的分布.
4.2 参数设置
在所有实验中,本文用word2vec在维基百科上学到的词向量来初始化所有单词,维度为300;然后利用3.4节的方法获取pos,dis和ss,MNPOSPP中全连接网络中隐含层节点个数为20,输出层节点个数为3;参照文献[7],本文对于MNPOSPP中所有的权重参数用正态分布进行初始化,U(-0.1,0.1),并将所有的偏差初始化为0;结合词性、位置信息的CNN关注机制中卷积核的高度h设置为3,a初始化为0.5;迭代次数为20,每次mini-batch的大小为200,由于最后一次mini-batch的样本不够200,所以以样本数量为准;L2正则化系数λ设置为0.001;Adagrad中初始学习率η为0.01,设为0.00000001;网络中每个节点的激活函数为ReLu.
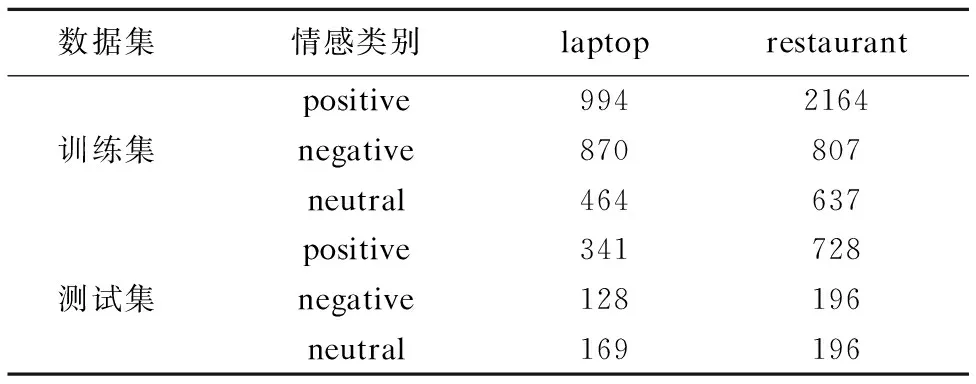
表1 laptop和restaurant数据集Table 1 Datasets of laptop and restaurant
4.3 对比算法
为了验证MNPOSPP在基于方面的情感分类问题上的性能,本文利用下面列出来的算法进行了对比实验:
1)Feature-based SVM:文献[1]中SVM利用ngram特征、解析特征和情感词典特征进行情感分析获得了非常好的结果;
2)LSTM:长短期记忆网络,文献[18]中利用LSTM获取句子中每个单词的隐藏状态,然后利用LSTM中最后一个隐藏状态进行情感分类;
3)TD-LSTM:文献[6]采用两个LSTM分别对方面在句中左右两边的内容(都加上了方面)进行建模,然后将两个LSTM最后的隐藏状态连接后作为句子和方面的代表进行情感分类;
4)ETEMN:利用ETEMN进行基于方面的情感分类,表2中ETEMN(i)表示含有i层关注层的ETEMN;
5)MNPOSPP:利用本文提出的MNPOSPP进行基于方面情感分析,表2中MNPOSPP(i)表示含有i层关注层的MNPOSPP.
4.4 实验结果和分析
表2展示了不同算法在laptop和restaurant两个数据集上的分类效果,其中黑色加粗并加下划线的数据是最好结果.从表中可以看出:
1)Feature-based SVM在两个数据集上准确度都非常高,这也说明情感词典的单词情感信息对于情感分类是有帮助的;
2)TD-LSTM在两个数据集上的准确度都比LSTM要好,可以说明在进行情感分类的时候加入方面的信息也是有帮助的;
3)虽然ETEMN(1)~(8)在两个数据集上的表现不理想,但是从准确度的总体变化趋势来看,多层关注机制比单层关注机制的效果要好.同时MNPOSPP也表现出了这样的特点;
4)在两个数据集上本文提出的MNPOSPP和具有相同关注层的ETEMN相比,MNPOSPP的准确度要明显高于ETEMN.和其他算法相比,在laptop数据集上MNPOSPP(1)的准确度就比LSTM要高,MNPOSPP(2)的准确度比TD-LSTM要高,MNPOSPP(7)和MNPOSPP(8)的准确度分别要比Feature-based SVM高0.05%和0.37%;在restaurant数据集上,MNPOSPP(1)的准确度就比LSTM和TD-LSTM要高了,MNPOSPP(8)的准确度比Feature-based SVM要高0.44%.由此可见,本文提出的MNPOSPP在基于方面情感分类问题上具有很好的优势.

表2 不同模型的准确度Table 2 Accuracies of different models
表3、表4分别给出了ETEMN在5-8层关注机制中food、service两方面和句子“Great food but the service was dreadful!”中每个单词的相关性.表5、表6分别给出了MNPOSPP在5-8层结合词性、位置信息的CNN关注机制中food、service两方面和句子“Great food but the service was dreadful!”中每个单词的相关性.从4张表中可以看出ETEMN和MNPOSPP都判断出了 food 和Great的相关性最高,service和dreadful相关性最高.但是从表3、表4中可以看出,ETEMN在确定方面和单词相关性时效果并不明显,对于food和Great的相关性最高为0.31,service和dreadful的相关性最高为0.33.对于MNPOSPP,从表5、表6中可以看出POSP-CNNAM能够较好的判断出food和Great的相关性最高,service和dreadful的相关性最高,最高分别为0.48和0.52,比ETEMN要高0.17和0.19,这说明了POSP-CNNAM利用词性和位置信息来判断方面和句中单词相关性是有效的.另外令人没有想到的是,表5中food和but之间的相关性相较于其他单词还是蛮高的,这里说明对于but这样的反转POSP-CNNAM在一定程度上也是能够检测到.

表3 ETEMN中food和”Great food but the service was dreadful!”中单词相关性Table 3 Relevance between food and each word in ”Great food but the service was dreadful!” on ETEMN

表4 ETEMN中service和”Great food but the service was dreadful!”中单词相关性Table 4 Relevance between service and each word in ”Great food but the service was dreadful!” on ETEMN
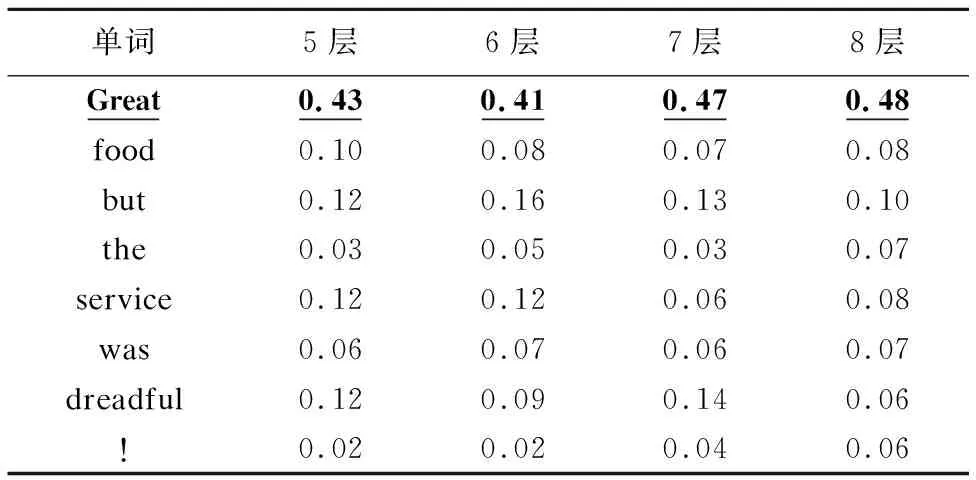
表5 MNPOSPP中food和”Great food but the service was dreadful!”中单词相关性Table 5 Relevance between food and each word in ”Great food but the service was dreadful!” on MNPOSPP

表6 MNPOSPP中service和”Great food but the service was dreadful!”中单词相关性Table 6 Relevance between service and each word in ”Great food but the service was dreadful!” on MNPOSPP
4.5 错误分析
虽然本文提出的MNPOSPP能够正确的判断大部分句子对不同方面的情感,但是仍存在一些错误的案例,这里给出错误分析,给出后续工作一些启示.
首先通过实验发现给定句子“We didn't know if we should order a drink or leave?”和方面“drink”,MNPOSPP判断情感是中性的,可是这里应该是消极的.这里之所以出现错误是因为这里情感需要根据整个上下文来推理得到,然而MNPOSPP并不具备这样的能力.
另外通过实验还发现给定句子“Dessert was also to die for”和方面“Dessert”,MNPOSPP判断句子对方面的情感是消极的,然而这里应该是积极的才对.之所以出现了错误是因为MNPOSPP在分析句子时没有将“die for”作为一个整体来处理,而是当作 “die”和“for”两个单词来处理,由于die的情感极性是消极的,所以导致判断错误.
5 总结和展望
本文在研究基于方面的网络评论情感分析任务的背景下,考虑到单词情感信息对于判断句子对方面的情感是有帮助的,并且考虑到单词词性、单词和方面间的位置信息能够帮助确定句中单词和方面之间的相关性的情况下提出了一种结合词性、位置和单词情感信息内存网络,该网络在词向量的基础上融入了单词的情感信息,并利用一种结合词性、位置信息的CNN关注机制判断方面和单词之间的相关性.通过和其他几个算法在两个来自于SemEval 2014任务4的两个数据集上进行对比实验,结果表明本文提出的内存网络在基于方面的情感分析问题上具有一定的优势.
由于本文提出的内存网络没有对像“die for”这样的词组进行处理,而这样的单词组应该是一个整体,所以在下一步工作中将考虑如何自动的识别这些词组,并给出相关的处理.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
当代陕西(2022年4期)2022-04-19
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
当代陕西(2020年22期)2021-01-18
中华诗词(2019年7期)2019-11-25
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
高中生学习·高三版(2016年9期)2016-05-14
