
神经网络声码器的话者无关与自适应训练方法研究
2019-02-15 09:21伍宏传凌震华
小型微型计算机系统 2019年2期
伍宏传,凌震华
(中国科学技术大学 语音及语言信息处理国家工程实验室,合肥 230027)
1 引 言
语音合成是人机语音交互中不可或缺的重要技术.近年来,语音合成技术广泛应用于智能手机助手、智能音箱、机器翻译机等大众产品中,同时人们对于合成语音质量提出越来越高的要求.统计参数语音合成方法[1]在最近二十年来发展迅速,该方法相对于基于大语料库的单元挑选与波形拼接合成方法具有系统尺寸小、鲁棒性高、体现不同发音人和发音风格的灵活性强等优点[2].但是现阶段统计参数方法合成语音的质量与自然语音相比还存在一定差距.统计参数语音合成系统通常由文本分析、声学建模、声码器三个模块组成;声码器重构语音音质损失、声学模型建模精度不足与参数生成中的过平滑效应是造成该方法合成语音质量受损的三个主要因素[3].其中声学模型将由文本分析得到的文本特征映射到声学特征,传统方法用隐马尔可夫模型(Hidden Markov Model,HMM)对声学模型建模.近年来,研究者用深度神经网络(Deep Neural Network, DNN)等深度学习模型替代传统的HMM模型构建声学模型,声学模型精度与合成语音自然度均得到了有效改善[4].但是在声码器特征提取与波形重构过程中的音质损失仍然制约着统计参数合成语音质量的进一步提升.
声码器实现从基频、频谱等声学特征中重构语音波形,传统声码器[5-12]基于源-滤波器思想[13,14]设计,STRAIGHT[10]是现阶段统计参数语音合成系统中最常用的声码器之一.在特征提取阶段,STRAIGHT提取每一帧语音信号的基频以及去除基音影响的平滑谱包络.由于谱包络维数较高,谱包络通常被转换成维数较低的倒谱、线谱对等参数作为声学建模中使用的滤波器表征.在波形重构阶段,首先将倒谱、线谱对等频谱特征转换为谱包络,然后依据基频特征产生激励信号,最终通过线性滤波重构语音波形.现阶段以STRAIGHT为代表的基于源-滤波器模型的声码器在以下方面存在不足.首先,由于谱包络维数较高,谱包络通常被转换成维数较低的倒谱、线谱对等参数作为声学建模中使用的滤波器表征,这样造成频谱细节的丢失;其次,传统声码器提取的频谱特征往往丢失了相位信息,波形重构中使用的语音相位往往依赖最小相位假设和人工设计;最后,传统声码器使用时变的线性滤波器来模拟声道滤波过程,而自然语音的采样点之间存在非线性相关性,这种线性滤波框架不足以精确描述语音波形点的生成过程.
2016年Deep Mind研究者提出了用于直接对语音波形建模与生成的深度卷积神经网络WaveNet[15],并将其用于从文本特征预测语音波形,取得了优于传统统计参数方法的合成语音自然度.已有研究工作[16-18]将WaveNet引入参数语音合成的声码器构建,使用STRAIGHT提取的语音基频、频谱等声学特征作为WaveNet的条件输入,利用特定目标发音人的语音数据进行模型的训练.对比传统源-滤波器声码器,基于WaveNet的神经网络声码器具有以下优势.首先,传统声码器采用线性滤波器重构语音,而神经网络声码器采用多层带有非线性激活函数的卷积层来生成波形,具有灵活的非线性处理能力;其次,神经网络声码器模型利用自然语音数据通过机器学习方法构建,能够较好的弥补输入声学特征相位和频谱细节缺失的问题.现阶段实验结果表明在输入自然声学参数以及由统计参数语音合成系统预测的声学参数情况下均取得了优于STRAIGHT声码器的重构语音质量[18].
现有的WaveNet声码器[18]采用话者相关方法训练,为了取得较好的模型精度和重构语音质量,对于目标发音人的语音数据量有较高要求,这限制了WaveNet声码器在目标发音人数据量受限的语音转换、个性化语音合成等任务中的应用.因此,本文面向目标发音人语音数据量受限情况,设计实现了神经网络声码器的话者无关与自适应训练方法.首先利用多发音人数据训练话者无关的WaveNet声码器模型,进一步利用少量目标发音人数据对话者无关模型进行自适应更新,以得到目标发音人的神经网络声码器模型.本文实验分析对比了自适应训练中局部更新与全局更新两种策略,以及相同训练数据下自适应与话者相关两种训练方法.实验结果表明,利用本文提出方法构建的神经网络声码器不仅可以取得优于传统STRAIGH声码器的重构语音质量,在目标发音人语音数据量较少的情况下,该方法相对话者相关训练也可以取得更好的客观和主观性能表现.
2 WaveNet简介
WaveNet[15]是一种自回归的深度生成模型.它直接在语音波形层面建模,将波形序列的联合概率分解为条件概率连乘:
(1)
其中xn是n时刻采样点,每一个因子项表示用n时刻以前的历史信息作为输入预测当前采样点的概率分布.WaveNet采用因果卷积神经网络来对条件概率建模,由于语音波形序列的长时相关性,WaveNet使用了扩张因果卷积网络结构(带孔的因果卷积)来获得足够大的接受野,即使用较长的波形历史作为输入来预测当前波形点,(1)式中条件概率项近似为:
p(xn|xn-R,xn-R+1,…,xn-1)
(2)
其中R是接受野长度.
WaveNet网络结构如图1所示, 它采用了类似PixelCNN[19,20]的加门控激活函数:
z=tanh(Wf,k*x)⊙σ(Wg,k*x)
(3)

图1 WaveNet结构.“因果”、“1×1”、“2×1扩张”分别代表因果、1×1和扩张因果卷积,“ReLu”、“加门控”和“Softmax”分别代表修正线性单元、加Sigmoid门控和Softmax激活函数.Fig.1 WaveNetarchitecture.“Causal”,“1×1” and “dilated” represent causal,1×1,and dilated causal convolution respectively.“ReLu” ,“Gated” and “Softmax” represent rectifier linear unit,gated and softmax activation function,respectively.
其中*是卷积运算,⊙是点乘运算,σ(·)是Sigmoid函数,Wf,k,Wg,k分别代表第k层的滤波卷积权重与门控卷积权重.WaveNet还采用残差网络[21]结构以及参数化的跳跃链接(skip connection)来构建深层次的网络,同时这种网络结构也有助于加快模型收敛.网络输出层采用了softmax激活函数输出当前采样点波形幅度量化值的概率分布,WaveNet使用μ-law压扩对音频信号进行8比特量化,这样softmax层只需要预测256个概率值,保证了建模预测的可行性.
3 WaveNet声码器及其话者无关与自适应训练
本节将先介绍话者相关的WaveNet声码器的实现,由于话者相关训练方法对目标发音人的语音数据量有较高要求.因此,本文面向目标发音人语音数据量较少情况,设计实现了神经网络声码器的话者无关与自适应训练方法,具体内容将在本节进行介绍.
3.1 WaveNet声码器
在第2节介绍的WaveNet结构基础上,增加声学特征作为模型的条件输入,即可构造基于WaveNet的神经网络声码器.在输入外部条件情况下的WaveNet模型可以表示为:
(4)
其中h为条件序列,其时域分辨率通常低于语音时域采样率.为了使两者的时域分辨率匹配,需要构造一个上采样变换y=f(h),然后把变换后的条件信息序列y加入到WaveNet各节点的激活函数中以控制生成预期的语音序列.加入条件信息后的激活函数可以表示为:
z=tanh(Wf,k*x+Vf,k*y)⊙σ(Wg,k*x+Vg,k*y)
(5)
其中Vf,k,Vg,k是第k层卷积条件输入的权重,Vf,k*y,Vg,k*y都是1×1的卷积运算.
在之前WaveNet声码器研究[16-18]中,条件信息h通常表示用STRAIGHT从自然语音中提取的声学特征.为了使加入的条件信息的时域分辨率匹配语音序列,构造了一个如图2左边所示的条件网络.输入的声学特征先经过1×1卷积,然后经过ReLU激活,最后通过最近邻上采样加入到激活函数中.最终图2所示的整个WaveNet声码器模型利用特定目标发音人的数据进行话者相关的模型训练.在生成阶段,给定输入的声学特征与生成的历史波形信息,构建每个采样点的条件概率分布,并通过采样方法实现波形的逐点生成.

图2 基于WaveNet的声码器模型结构Fig.2 WaveNet-based neural vocoder
3.2 话者无关及自适应训练
WaveNet声码器的话者无关与自适应训练流程如图3所示,首先用混合的语音数据训练得到话者无关模型;然后将话者无关模型作为初始化模型,用目标说话人语音数据作进一步自适应训练.

图3 WaveNet声码器的话者无关与自适应训练Fig.3 Speaker-independent and adaptive training of WaveNet vocoder
与话者相关模型训练只使用目标发音人语音不同,话者无关模型采用混合多说话人的语音数据来进行训练,希望所得到的模型能够具有对不同说话人声学特征与语音波形之间映射关系的泛化表示能力.在话者无关模型训练阶段,先利用STRAIGHT从混合多说话人语音数据库中提取每一帧语音对应的声学特征;然后将声学特征序列作为条件输入,将对应的语音波形作为输出,训练图2所示的WaveNet声码器中的模型参数.
自适应训练指的是在已经获得的话者无关WaveNet声码器模型基础上,利用目标发音人的语音数据对话者无关模型进行进一步的优化更新.对比随机初始化的话者相关训练,自适应训练使用话者无关模型作为初始值,更适合目标发音人数据量受限的应用场景.考虑到WaveNet声码器模型参数较多而目标发音人的语音数据较少,在自适应训练过程中我们也设计了两种自适应策略:
1)全局更新:利用目标发音人数据,基于WaveNet声码器训练准则,对所有模型参数进行更新;
2)局部更新:在利用目标发音人数据更新话者无关模型参数时,只更新与条件输入相关的部分模型参数,即公式(5)中的权重矩阵Vf,k,Vg,k.
4 实 验
4.1 实验条件
本实验采用公开的多说话人语音库VCTK[22]以及CMU Arctic[23]语音库进行实验.VCTK库包含109位不同口音的英语母语发音人的语音数据,每个发音人大约400句话,总计时长约44小时.本文选取了其中100个说话人的90%数据作为训练集(时长约37小时)来做话者无关训练.实验中为了对比目标发音人不同数据量情况下的自适应与话者相关模型训练效果,选取Arctic数据库中女发音人slt数据(共1132句,约1小时)作为自适应训练数据以及测试集,后面实验中测试集统一使用女发音人slt的100句话.实验中使用的声学特征包括STRAIGHT分析提取的能量、40维梅尔倒谱、基频与清浊判决标志;WaveNet声码器模型参数配置如表1所示,本文利用Xeon(R)E5-2650和Nvidia 1080Ti GPU来训练WaveNet声码器.
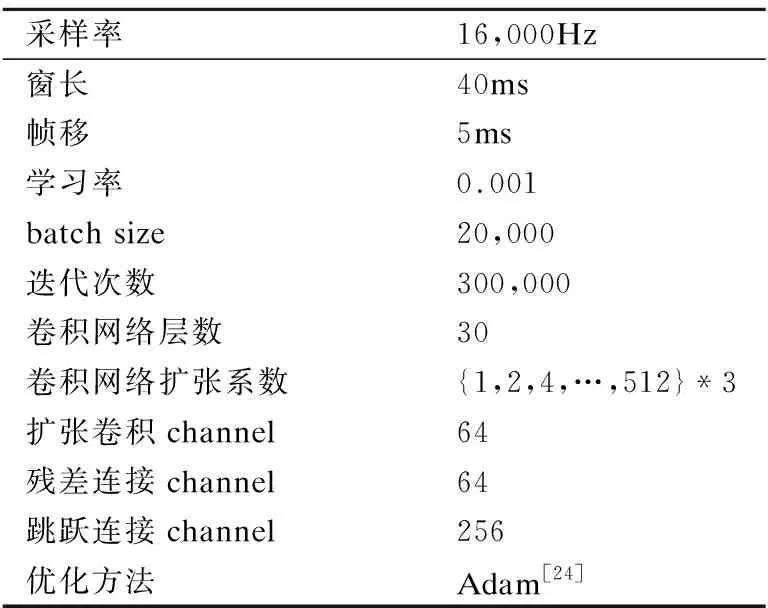
表1 WaveNet声码器参数配置Table 1 Configurations of WaveNet vocoder
4.2 自适应训练更新策略的对比
在3.2小节中提到了自适应训练的两种参数更新策略,为了探究不同训练数据下更新策略优劣,本文计算了不同模型在测试集上的预测正确率,如图4所示.下面简要说明预测正确率的计算过程,WaveNet声码器将自然历史采样点作为输入,输出当前波形采样点幅度量化值对应的概率分布,将概率最大对应的量化值作为预测结果与真实波形幅度量化值对比,从而计算采样点的预测正确率.从图中可以看到在训练数据较少时,局部更新策略优于全局更新.特别的在100句时全局更新自适应模型正确率低于话者无关模型,这说明数据量较少时全局更新存在过拟合问题,采用局部更新策略性能更好.在训练数据较多时,全局更新模型性能更优,而且可以发现全局更新策略高度依赖数据量,其模型预测正确率随数据量的提升率高于局部更新.因此在后续实验中,我们对于少于等于200句目标发音人数据量情况使用局部更新进行模型自适应训练,对于多于200句的数据量情况使用全局更新训练.
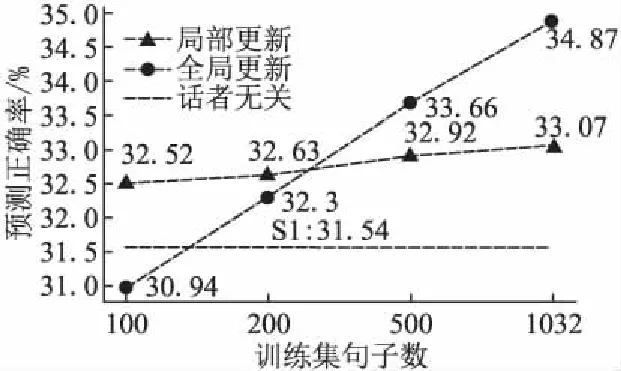
图4 不同训练数据量两种更新策略预测正确率Fig.4 Prediction accuracy of two updating strategies on different training data
4.3 自适应训练与话者相关训练的对比
我们首先对比了不同数据量情况下,自适应训练与话者相关训练模型在测试集上的预测正确率,结果如图5所示.从图中可以看到在100、200、500句训练数据下,自适应方法预测正确率高于话者相关训练方法,而话者相关模型高度依赖数据量,只有在足够大的数据量(如1032句)下才能得到优于自适应方法的预测正确率.

图5 不同训练数据量自适应方法与话者相关训练方法预测正确率对比Fig.5 Prediction accuracy of adaption and speaker-dependent methods on different training data
由于在计算预测正确率时采用真实历史采样点信息预测当前采样点,因此测试集预测正确率不能直接衡量重构语音的质量,本文还计算了重构语音和自然语音的时域与频域误差,尝试从多角度客观衡量不同模型的语音重构能力.本文参照已有的WaveNet声码器研究[16]中的客观指标,计算了波形信噪比(SNR)、短时幅度谱的均方误差(RMSE)、基频误差以及清浊误判率,计算公式如下:
(6)
(7)
RMSE(f0)=|Fr-Fs|
(8)
(9)
其中xs(n)是合成语音序列,yr(n)是自然语音序列,特别的在计算SNR时会给合成语音序列线性相位补偿和自然语音序列对齐;X(f),Y(f)分别是合成语音的短时幅度谱和自然语音的短时幅度谱;Fs,Fr分别是合成语音和自然语音的基频值;FFU,FFV分别是分别是合成语音中浊音误判为清音,清音误判为浊音的帧数,F是总帧数.
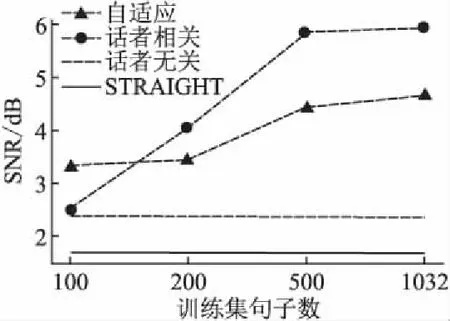
图6 自适应与话者相关模型的SNRFig.6 SNR of adaption and speaker-dependent models
从图6可知在100句时,自适应方法SNR高于话者相关方法,随着训练集增大话者相关方法SNR快速提高并且超过了自适应方法,而且基于WaveNet声码器重构语音SNR均高于STRAIGHT.从图7可知在100句时,自适应方法RMSE低于话者相关方法,随着训练集增大话者相关方法RMSE下降而自适应方法变化较小,STRAIGHT重构语音的RMSE明显低于WaveNet声码器.从图8可知在100句时,自适应方法基频误差低于话者相关方法,但随着训练集增大话者相关方法基频误差快速下降,并且最终低于STRAIGHT.从图9可知在100句时,自适应方法清浊误判率低于话者相关方法,随着训练集增大话者相关方法清浊误判率下降较快而自适应方法较慢,STRAIGHT重构语音的清浊误判率一直低于WaveNet声码器.总的看来,在100句时自适应方法所有客观指标都好于话者相关方法,话者相关训练方法的性能随着训练集规模增加而提升,但是高度依赖于数据量.
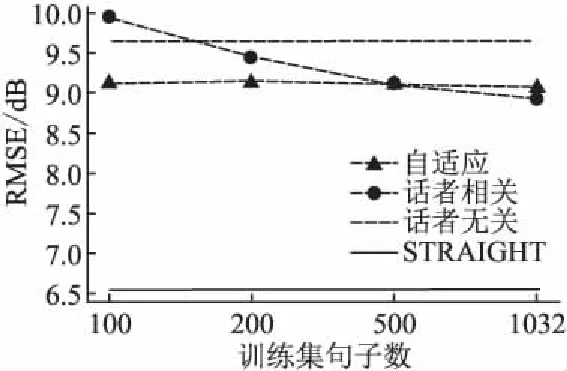
图7 自适应与话者相关模型的短时幅度谱均方误差RMSEFig.7 Short-time spectral amplitude RMSE of adaption and speaker-dependent models
综合以上客观实验结果可以发现WaveNet声码器的波形SNR明显高于STRAIGHT声码器,但是STRAIGHT声码器短时傅里叶谱RMSE、基频误差以及清浊误判率却都低于WaveNet声码器.由于波形SNR同时受到重构语音的幅度谱和相位谱影响,这说明WaveNet声码器相对传统STRAIGHT声码器更好的重构了原始语音中的相位信息,这也验证了WaveNet声码器通过波形建模在保留相位信息方面的优势.

图8 自适应与话者相关模型的基频误差Fig.8 Fundamental frequency distortion of adaption and speaker-dependent

图9 自适应与话者相关模型的清浊误判率Fig.9 Voiced and unvoiced error of adaption and speaker-dependent models
4.4 自适应模型与话者无关模型性能对比
为了验证自适应训练的有效性,我们用100句话自适应训练的模型(AD100)、话者无关模型(SI)以及STRAIGH(ST)声码器分别重构了Arctic slt测试集上的20句语音[注]http://home.ustc.edu.cn/~whc/xwjxt/demo.htm.利用Amazon Mechanical Turk众包平台[25]进行以上三个系统两两之间合成语音质量的倾向性测听.测听由20位英语母语测听者进行,倾向性测听实验结果如表2所示.

表2 100句自适应WaveNet声码器(AD100)、话者无关WaveNet声码器(SI)与STRAIGHT声码器(ST)重构语音质量倾向性测听结果(%),其中N/P表示无倾向,p值为系统间差异的t-test结果Table 2 Preference test scores among different vocoder AD100,SI and ST
主观测听结果表明在不进行自适应训练情况下的话者无关模型性能不够理想,其重构语音质量低于STRAIGHT声码器.而在采用100句目标发音人数据进行自适应训练后,WaveNet声码器质量显著提升,且优于STRAIGHT声码器,这也表明了利用少量目标发音人数据进行自适应训练的有效性.
最后我们对四组训练数据量情况下自适应和话者相关两种方法所得WaveNet声码器分别进行了重构语音质量的倾向性测听实验,测试方法同上,测听结果如表3所示.由表中可知,在100句训练数据下自适应训练方法所得WaveNet声码器重构语音质量显著高于话者相关训练方法;200句时两种方法差异不明显;500、1032句训练集时,话者相关方法重构语音质量更高.该主观测试结果与客观结果一致,均表明本文所提出的话者无关与自适应训练方法在较少数据时可以取得优于话者相关训练的性能表现.

表3 自适应模型(AD)和话者相关(SD)模型倾向性测听结果(%),其中N/P表示无倾向,p值为系统间差异的t-test结果Table 3 Preference test scores among AD model and SD model
5 总 结
本文提出了WaveNet声码器的话者无关与自适应训练方法,以改善话者相关训练方法对于目标发音人数据量的依赖.实验结果表明在目标发音人训练数据量较少情况下,自适应训练方法构建的WaveNet声码器可以取得优于话者相关方法的客观与主观性能,其重构语音质量也优于传统STRAIGHT声码器.该方法在话者转换、个性化语音合成等目标发音人数据量受限的场景中具有应用潜力.如何通过扩充训练数据规模改善话者无关模型的性能以及在小数据量自适应训练中避免过训练现象,是今后需要进一步探讨研究的问题.
猜你喜欢
电子技术与软件工程(2022年6期)2022-07-07
煤气与热力(2021年5期)2021-07-22
北京大学学报(自然科学版)(2021年3期)2021-07-16
家庭影院技术(2020年11期)2020-12-28
防爆电机(2020年4期)2020-12-14
电脑爱好者(2020年19期)2020-10-20
家庭影院技术(2020年5期)2020-08-24
家庭影院技术(2020年6期)2020-07-27
雷达学报(2018年5期)2018-12-05
汽车维护与修理(2018年9期)2018-10-31
