
面向云制造资源调度预测的学习模型
2019-02-15 09:27简琤峰张美玉
小型微型计算机系统 2019年2期
简琤峰,姜 晨,张美玉
(浙江工业大学 计算机学院 数字媒体技术研究所,杭州 310023)
1 引 言
云制造的任务调度和资源分配一直是当前云制造研究的热点[1-3].与侧重计算能力的云计算资源调度不同,云制造资源调度是根据云平台中虚拟制造资源的状态信息和制造任务的实时信息来产生最优的任务执行方案.云制造的调度是面向服务和以客户为中心的,是以满足消费者需求为前提的,云制造调度的优化大多为多目标模糊优化,除了基础的最大完工时间和成本之外,还需考虑例如物流时间、产品质量、QoS、系统可持续性等更多的优化目标,而其中很多目标都是模糊的和不定量的属性.现有的智能调度算法虽然能较好的解决云制造资源调度问题,但是均存在由于算法在寻优时的多次迭代导致时间复杂度较高的缺陷.面对客户越来越迫切的需求,从任务被顾客提交到最后完成所花费的时间长短至关重要,随着大数据和物联网的发展,如何在最短时间内寻找最优结果是云制造资源调度分配的核心问题.当前各种改进算法仍然是在算法复杂度和性能之间寻找平衡,并不能从根本上解决该矛盾.针对上述问题,利用深度学习模型训练优化调度后的数据来实现对调度结果的直接预测是一条可行的路径.但是由于深度学习复杂的层次结构和数量众多的神经元节点,导致其训练时间比传统的机器学习更长,如何提高训练优化适合云制造资源调度的深度学习模型是必须解决的问题.
本文主要从以下两个方面展开,第一是研究优化调度算法,首先针对云制造任务调度的问题建立基于任务最短执行时间的调度模型,并提出基于动态因子、二阶震荡以及差分进化算法改进的新蝙蝠算法(ONBA),使用ONBA算法求解本文的多目标问题.另一方面,提出改进的深度学习模型(IDBN),IDBN在传统的DBN网络前向训练的RBM阶段和反响微调阶段对学习率进行优化并在此基础上对模型的训练次数进行控制从而达到加快训练速度的目的.最后,使用ONBA调度算法得到的数据集对IDBN模型进行训练,预测并和传统的调度方法进行对比.
2 模型的建立和求解
2.1 模型的建立
云制造的调度问题其本质是以一定的性能指标为前提,把任务按照设定的调度策略进行排序,将任务按顺序的分配到资源点上.云制造平台上的各个企业或者车间作为云制造平台的制造资源.由于云制造任务大多都为复合型的任务,所以我们需要先将任务分解为一个个可以由企业或者车间单独加工的子任务,然后根据调度策略进行排序使其达到最优.因此,云制造资源调度问题基本上可以描述为n个计算节点对应着m个任务,每个计算节点都是一个独立的企业或者车间提供的制造资源,而任务则是可以分解到最小单位的子任务.其中,P= ﹛p1,p2,p3,…,pm﹜,pi表示第i个子任务,r= ﹛r1,r2,r3…rn﹜其中rj表示 第j个资源点.任务ti在rj上的执行时间定义如下:
timeij=Leni/MIPSj
(1)
各个子任务执行的总时间为
(2)
cij为任务pi在rj上的执行情况,如果任务pi在rj上执行则cij=1,否则cij=0.所有的任务执行完成所需时间为:
Tmax=Max(Tj)
(3)
要求解任务的最短执行时间就是要找到如何使调度任务Tmax最小.即我们要求解的目标函数为:
Cost=min(Tmax)
(4)
当目标函数Cost得到最小值的目标,此时cij=1就是任务pi对应分配制造资源rj.
2.2 ONBA算法
NBA算法[4]是于2015年提出的基于蝙蝠算法上的改进算法,该算法着重进一步模拟蝙蝠的行为,并基于生物基础改进蝙蝠算法.该算法将蝙蝠的栖息地选择及其对应回波多普勒效应的自适应补偿引入到基本蝙蝠算法中,设计了一种新的局部搜索策略.虽然NBA算法在于之前传统的粒子群算法、遗传算法和蚁群算法对比有着收敛性精度高、局部搜索能力强和鲁棒性较好等优点,但是NBA算法仍在容易陷入早熟.本文通过将二阶振荡机制[5,6]结合差分进化算法引入NBA算法对其进行改进,在保证NBA算法优点的同时提高算法的全局搜索能力和避免粒子早熟的现象.算法如下:
(5)
fij=fmin+(fmax-fmin)r
(6)
(7)
(8)
(9)
(10)
(11)
(12)
(13)

二阶震荡机制针对公式(8)改进,公式如下:

(14)
其中β1=c1r1以及β2=c2r2.ω与ci分别代表了惯性权重和学习因子,ri是取值在[0,1]范围内的随机数.

(15)

(16)
r3,r4为(0,1)范围内的随机数.
c1=β1′+β1cos(ρ2×t/Gmax)
(17)
(18)
c2=β2′+β2cos(ρ2×t/Gmax)
(19)
(20)
c1′与c2′是一个定值,Gmax代表最大的迭代次数.
差分进化算法(DE)由于其寻优的过程中存在变异,交叉,选择等机制能够提高个体的多样性在提高粒子的局部搜索能力和防止粒子早熟等方面具有很好的优点.因此在二阶振荡改进的基础上再引入差分进化算法对NBA进行改进.公式如下:
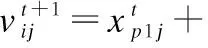
(21)
(22)
(23)
其中i≠p1≠p2≠p3,p1,p2,p3分别表示种群中的个体,ϖ为缩放因子取值在[0,2]之间,jr为粒子维度内的一个随机整数,函数f为目标函数,cr为交叉概率.
2.3 算法描述
本文的算法在NBA算法的基础上加入了二阶振荡机制和引入了差分算法对NBA算法进行了优化,具体的算法步骤如下:
1)初始化参数:设置种群数量以及其他相关参数.
2)若t小于迭代数,通过调整频率产生新解,并更新速度与位置信息.
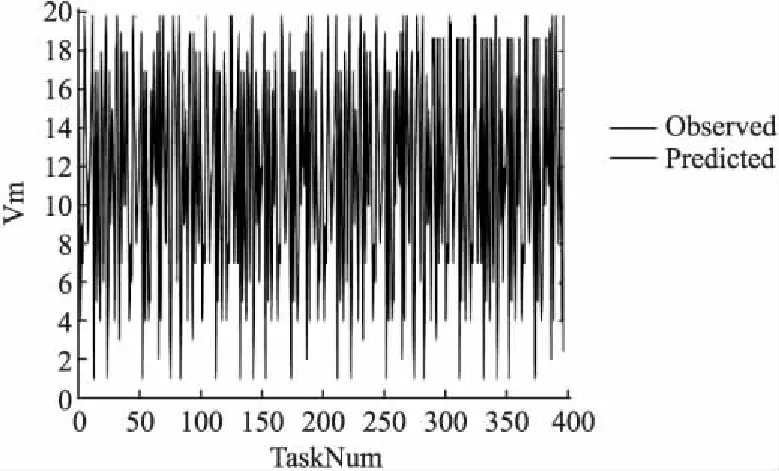
3)若rand(0,1) 4)若rand(0,1)>r,从最佳解中选择一个,并通过围绕选择的解产生一个局部解. 5)通过随机飞行来产生新的解. 6)若rand(0,1) 7)随机选择三个个体并根据公式(21)、(22)和公式(23)产生新解与之前的解作对比,找到当前的最佳解. 学习率是深度学习中的一个重要参数,它控制着基于损失梯度调正神经网络权值的速度.学习率如果较小,网络可能会陷入局部最优;但是如果过大,会导致其在某一位置反复震荡.因此,选择一个合适的学习率,可以节省大量的资源和时间.不少学习算法在训练过程中,随着误差的减少,迭代次数的增加,步长变化越来越小,训练误差越来越小直到变为零,局部探索到一个驻点,如果这个点是误差曲面的鞍点,即不是最大值也不是最小值的平滑曲面,那么一般结果表现为性能比较差;如果这个驻点是局部极小值,那么表现为性能较好,但不是全局最优值.目前大多数训练算法在碰到无论是鞍点还是局部极值点的时候,因为此刻学习率已经变得非常小,所以会陷入非全局最优值不能自拔.对于这个问题,一个可行的办法是在训练过程中使用动态学习率,使其随时间不断下降,这样可以显著减少训练时间[7,8].如果在学习率的调整上更贴近模型的训练过程,在误差的控制上也可以更好[9-11]. 深度信念网络(Deep Belief Nets),神经网络的一种,DBN是一个概率生成模型,由多个限制玻尔兹曼机层组成. RBM是一种神经感知器,这些网络被限制为一个可视层和一个隐层,层间存在连接,但层内的单元件不存在连接.隐层单元被训练去捕捉在可视层表现出来的高阶数据的相关性. RBM的训练有多种方法[12-14],其中CD[15]算法是最经典和最有代表性的算法.训练前需要对RBM进行初始化,对训练周期、学习率等进行赋值.当学习率η较大时,收敛速度更快,但可能会引起算法的不稳定,而当η较小时,虽然可以避免不稳定的情况的出现,但是收敛速度较慢.因此,对RBM学习率的改进时尤为重要的.RBM学习率的改进算法中参数的更新公式如下: Δωi,j=Δωi,j+η[c1-c2] (24) (25) (26) (27) (28) 其中学习率η为定值,在训练过程中无法调整学习率导致参数的更新能力较弱.结合神经网络学习率改进算法[16-18]可以达到改进RBM训练的目的.如下所示: (29) α为(1,2)之间的定值,β为(0,1)之间的定值,t为当前迭代次数,e为训练重构误差.当e(t) (30) 其中e(t)为当前误差,e(t-1)为上一次训练误差,学习率的调整过如下: 1)当e(t) 2)当e(t)>e(t-1)则说明误差很有可能越过了极小值此时减小η以使得误差继续减小直至收敛.在训练过程中为了防止过拟合使用权重衰减: Δωi,j=Δωi,j+η[c1-c2-δΔωi,j] (31) 其中δ为权重衰减系数位(0,1)之间的值.传统方法中δ为一个定值,导致模型的泛化能力不强.采用自适应的方法对δ进行改进,如公式(32)所示. (32) 随着训练次数的增加δ不断的减小以使得对模型精准微调的同时保证收敛. 实验证明本文提出的RBM改进算法能在确保模型训练精度的情况下加快模型的训练速度从而加快整个深度学习模型的训练速度. 当DBN模型中的RBM训练完成之后使用标签数据集对模型进行整体的微调以达到模型的整体最优,在这一阶段主要使用梯度下降算法对模型的权重进行更新: (33) 为克服传统算法中学习率手动调整的缺陷,Adagrad[19]和AdaDec[20]算法被大多数采用.这两种方法中学习率η都呈非线性下降的趋势,虽然其涉及到梯度下降的速率和学习率之间的关系,但是没有考虑误差减小时的因素.因此如果为了达到收敛的目的而减小η可能会导致训练误差靠近收敛误差的速度减慢,从而需要增加训练次数才能收敛.从模型训练过程分析可知当模型误差不断减小时η可以适当的增加以加快模型的收敛速度,但是η的增加速率应该不断的减小.因为随着迭代次数的增加误差越来越小,距离极小值越来越近所以η也要减小以免越过极小值.结合上面的学习率改进公式和分析,提出的改进算法IRBM公式如下: (34) G(t)=ζE(g(t-1)2)+g(t)2 (35) 其中e(t)为误差值,ζ为一个(0,1)之间的定值,g(t-1)为上一次迭代的梯度,E(g(t-1)2)为上一次迭代的梯度平方和的均值.g(t)为当前的梯度.学习率调整过程如下: 1)当e(t) 2)当e(t)>e(t-1)时说明当前的学习率太大导致梯度下降太快,因此应当减小学习率. 在误差下降的阶段适当的增加学习率能够增加梯度下降的速度从而快速减小误差到一个合理的范围内,当误差越过最小值时适当的减小学习率能够保证在合理的范围内对误差进行精调.学习率下降阶段中在上一回合的学习率的基础上利用当前的梯度去自适应调节学习率的大小,这样设计的学习率更能准确描述模型的运行状态,调节得到的学习率也更合理,因此能加快模型的收敛速度,同时也能减小历史梯度参与计算从而减小计算量. 传统的训练次数通常根据经验进行设置,为了保证模型在训练时能够收敛,需要反复的调整.根据提出的学习率调整方法,在实际训练中结合误差和学习率来控制模型的训练次数.当η减小到一定的范围后,模型的误差下降幅度极小此时误差已经很接近极小值,整个模型的误差范围在可接受范围内所以此时再增加t已经没有意义则停止训练.另外考虑到t可能还没有下降到设置的范围时模型已经收敛,所以训练误差也是控制模型训练次数的因素之一.当IGD训练模型满足公式(36)的两个条件时就不断的进行迭代: (36) 其中∂为一个设置的阈值,β为模型的训练误差,n为连续统计误差的次数.α为一个误差波动范围.由上面的公式可知当η>∂,连续e>α时,模型进行迭代训练,当η<∂时误差下降幅度小此时停止训练,当连续几次的e<α时基本认为模型收敛也停止迭代. DBN的训练采用的是逐层无监督贪婪的预训练方法,由低层到高层及使用前向传播来训练每一层的参数,前向训练就是分层对RBM进行训练以后去对应的权重等参数,预训练完成后再使用标签数据集由高层到低层的反向传播算法来微调各层的参数.本文提出的改进算法IRBM具体过程如下: 1)初始化参数:输入数据集,初始化学习率、重建误差、隐层数等. 2)初始化ω,a,b. 3)当η(t)>∂&& n 4)计算重构误差e(t). 5)首先根据公式(30)更新参数η(t),再通过公式(25)-(28)和公式(31)、公式(32)更新ω,a,b. 6)若|e(t)-err|≤μ,n++;否则n=0. 当RBM训练完成后在使用带标签的数据集对模型进行反向训练,反向训练的目的就是对损失函数求偏导以调整权重和偏置使得误差最小.IGD训练具体过程如下: 1)初始化参数. 2)while ε>θ&&n 3)根据公式(33)更新参数ω,a和b. 4)根据公式(34),(35)更新参数ε. 5)若|e(t)-err|≤μ,n++,否则n=0. 为了测试ONBA的性能,我们将其与二阶振荡粒子群算法(MPSO),差分进化算法(DE),新蝙蝠算法(NBA)相对比.实验通过模拟多种情况下的云制造批量生产情况,展示了ONBA算法较好的优化效果以及快速收敛性. 实验过程中权重因子分别取值为0.3,0.3,0.2,0.2每个任务在各个工序上加工时间是随机生成的数值,取值区间为[0,60],单位分钟,由矩阵Timem×n进行存储.实验重复进行多次并取平均值作为实验数据,以避免偶然因素对实验的影响.实验中三种算法的迭代数统一设置为100,种群规模设置为50.算法的惯性因子的值设置为0.8. 表1 算法对比情况Table 1 Algorithm comparison 为了测试算法在不同云制造任务数和不同工序的搭配下的表现情况,同时也为了体现考虑物流情况下算法调度所得到的总的生产时间的对比,我们将实验分为生产工序分别是10,20,30和40这四种情况,并分别展示了四种算法在这四种情况下的对比情况.(n代表任务数,m代表工序数)单位为:103分钟. 从表1和表2中可以看出,ONBA对于不同任务数和不同工序数的云制造批量生产所产生的时间开销绝大多数情况下均小于MPSO和DE,NBA算法.在本文的模型中,还加入了物流因素,所以ONBA算法所要求解的问题的复杂度更高.从表1和表2可以看出,除了ONBA算法之外其他的三种算法中当模型迭代完成后它们的最优解相差不大,这是由于这些单一的算法虽然有着各自的优点但在问题复杂度较高时,很难发挥出各自的优点,不能完全展示出其在大规模劣质解包围下搜索最优解的能力.ONBA算法则是结合上面的算法的优点使得搜索能力强于上述的三种算法的搜索能力. 表2 算法对比情况Table 2 Algorithm comparison MPSO算法在保证收敛速度的具有较强的避免局部优化的能力.图1和图2是云制造任务数分别为50,130的情况下MPSO,DE,ONBA,NBA对应求得的总的生产时间随迭代次数增加的趋势图. 图1任务数为50时Fig.1 Number of tasks is 50 从图1和图2中可以看出,三种算法中,ONBA展现了较强的跳出前期局部优化的能力以及快速收敛能力.ONBA算法在保持了各自种群的优良性的情况下,不断和其他种群进行信息互换,不仅扩展了种群的多样性,且提高了最优解的质量.ONBA算法在NBA算法的基础上引入振荡环节不仅能增强全局搜索能力,并且结合DE算法中父代粒子杂交产生子代粒子的过程还进一步丰富了种群的多样性.当与MPSO和NBA,DE这三种算法相比较时,随着解空间范围的增大,在继续保持解的优势情况下,ONBA的收敛速度逐渐提高.在迭代过程中出现停滞时,ONBA可以及时扩展种群的多样性和优良性,跳出局部最优,同时这些改变也是在保持解质量前提下迭代速度进一步提高的原因所在.并且ONBA由于在局部搜索的过程中,不断扩展了最优候选值集合的范围,所以选取的最优值也比其他三种算法选取的最优值质量更好.这是因为ONBA算法结合NBA算法的局部搜索能力强,MPSO的全局搜索能力强,DE算法中变异和粒子的杂交等优点使得ONBA算法在搜索能力和防止粒子早熟上表现的更优. 训练集来源于通过4.1实验仿真ONBA算法云制造调度后获取的数据.使用改进的DBN(IDBN)进行训练数据特征的提取,使用RBF进行预测. 为了评估模型的预测效果,使用的误差为:平均绝对误差(MAE),平均相对误差(MRE)和均方根误差(RMSE)来衡量本文的模型的预测值和真是之间的差距,使用重构误差来评估RBM的训练情况,这些误差的定义如下: (37) (38) (39) RBM的训练改进对比,训练次数和重构误差关系如图3所示,改进的IRBM训练不仅在模型的训练收敛速度上比传统的RBM方法快,而且在训练精度上也比传统的RBM训练更高. 图3 模型训练Fig.3 Model training 4.1节实验确定调度算法模型数据,4.2节实验确定改进的学习模型,本节将改进的学习模型对上述调度算法模型进行预测.预测的准确度主要和传统的预测模型神经网络进行对比. 图4 改进的学习模型预测IDBNFig.4 Improved learning model for predicting IDBN 当节点为45,任务为400时对比结果如图4,图5所示. 图5 神经网络预测BPFig.5 Neural network prediction BP 从预测图可以看出本文提出的预测模型在MAE,MRE,RMSE等方面表现都十分不错. 表3 对应图4图5的误差分析Table 3 Error analysis of Figure 4 and Figure 5 表4 ONBA和IDBN调度耗时Table 4 Scheduling time consuming 无论从预测图还是误差对比表都可以看出本文提出的预测模型在MAE,MRE,RMSE等方面都比传统的预测模型表现的更优秀.如表3所示,分别比较IDBN和BP结果显示,随着集群节点的增加和任务数量的增加模型在测试时误差也会增加,因为随着节点和任务数的增加数据间特征组合可能性也在呈几何倍数的增加,从而导致预测的难度也会增加.但是IDBN的误差值增加幅度和最终误差值在一个可允许的范围内,而BP误差增加的幅度远远大于IDBN,原因在于调度数据的特征难以提取导致预测结果不够精准和稳定. 为了验证改进的学习模型比传统调度模型在调度任务时更加节约时间,随机取6组调度数据进行统计,结果表4所示. 从表4中可以看出当模型训练完成后,如果有新的任务到达,使用IDBN模型对调度进行预测所用的时间和传统的ONBA方法进行求解时所使用的时间缩短了10倍以上,从前面的预测结果和误差图可以看出预测的结果和使用ONBA进行求解的结果差别不大,可见使用改进学习模型替代传统的调度模型进行云制造调度不仅可行而且高效. 本文针对云制造平台调度策略和调度速度主要进行了以下两点工作,首先提出了一个基于NBA算法改进的智能调度算法,然后提出改进的深度学习模型和智能调度算法相结合,更好的解决的一些传统调度算法无法解决的问题. 传统的智能算法调度模型,不仅对任务的求解所花的耗时较长,而且各个群组优化的模型算法复杂度和调度效果都存在矛盾.将深度学习算法引入其中不仅可以很好的协调各个算法之间的矛盾,还可以快速有效的获得想要的调度结果.通过效果比较好的智能调度算法先得出一些调度数据,然后通过深度学习对之后的调度数据直接进行预测可以大大减少调度所需的时间、提升云制造平台客户的满意度.实验证明,深度学习对云制造调度的结果进行直接预测是一条可行的路径.3 学习模型及改进
3.1 RBM模型
3.2 DBN模型的改进
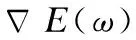
3.3 训练次数的控制
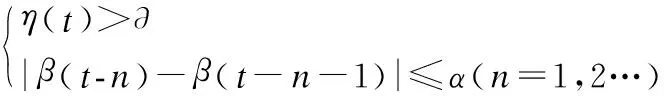
3.4 算法描述
4 实验仿真
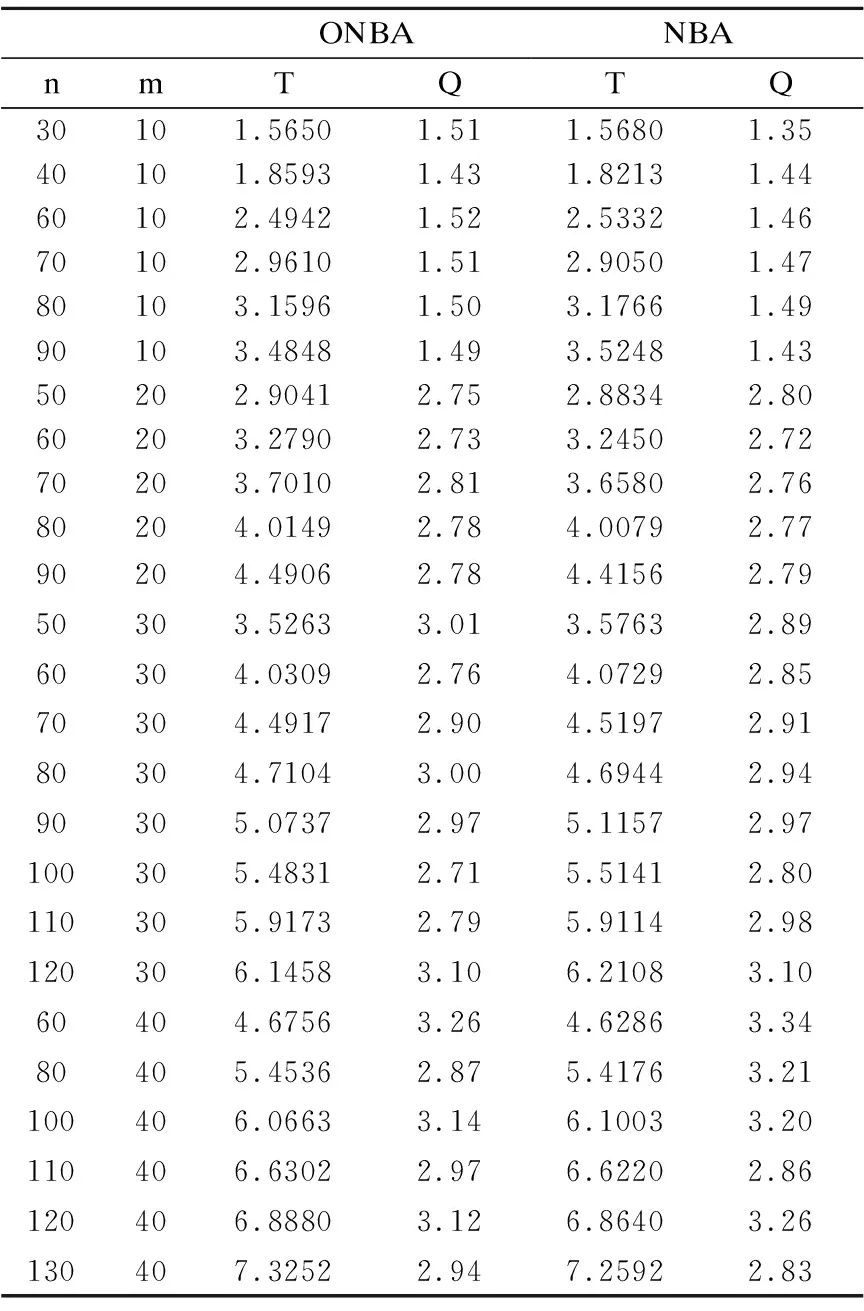
4.1 ONBA算法性能对比


4.2 深度学习模型的效果对比


4.3 基于深度学习的调度预测实验



5 总结展望
猜你喜欢
新高考·高二数学(2022年3期)2022-04-29新高考·高二数学(2022年3期)2022-04-29北京航空航天大学学报(2021年6期)2021-07-20中学生数理化(高中版.高二数学)(2020年11期)2020-12-14铁道通信信号(2020年10期)2020-02-07北京航空航天大学学报(2019年9期)2019-10-26计算机测量与控制(2019年6期)2019-06-27智富时代(2018年5期)2018-07-18智富时代(2018年5期)2018-07-18中学生数理化(高中版.高一使用)(2018年6期)2018-07-09
