
科技大数据背景下的中英双语语料库的构建及其特点研究
2019-02-12 06:24苏晓娟张英杰
中国科技资源导刊 2019年6期
苏晓娟 张英杰 白 晨 吴 思
(1.北京石油化工学院,北京 102617; 2.中国科学技术信息研究所,北京 100038)
1 概述
语料库特指能够被计算机存储的数字化语料库,广泛应用于编撰字典、语言教学、自然语言处理、人工智能等方面。随着各学科、各领域科学研究的融合发展,语料既能够记录各类科技活动,反映特定时期的科技发展特征,也能够支撑科技大数据的丰富应用场景。
国外的语料库比较著名的有欧盟的术语数据库(IATE)、美国当代语料库(COCA)等。欧盟术语数据库(IATE)开始于1999年,收录有1017288 条实体,7961980 个术语,旨在为所有欧盟术语资源提供基于网络的基础设施,提高信息的可用性和标准化[1]。美国当代语料库(COCA)是美国唯一一个大型的、类型均衡的语料库,也是最广泛使用的英语语料库,包含超过5.6 亿字的文本,涉及口语、小说、流行杂志、报纸和学术文本等内容[2]。在商业领域,图灵机器人目前拥有1300 多亿条对话语料库。
国内的语料库比较知名的有国家语委现代汉语通用平衡语料库[3]和中国科学技术信息研究所编制的《汉语主题词表》。国家语委现代汉语通用平衡语料库立项于1991年,全库约有1 亿字符,语料选材类别广泛,时间跨度大。标注语料库为国家语委现代汉语通用平衡语料库全库的子集,约5000 万字符,准确率大于98%[4]。中国科学技术信息研究所编制的《汉语主题词表》,多年来持续建设和维护的中文基础词库收录词汇总量达到500 万条,包括中文叙词表、全国科学技术名词审订委员会审定公布的规范名词、文献关键词、专业词典、术语标准、百科等多种来源的词汇,词汇信息丰富,包括词间关系、词汇分类、英文、注释等属性。此外,部分有特色的语料库包括中国传媒大学的新词语研究资源库[5]、哈尔滨工业大学信息检索研究室开发的对齐双语句对的语料库[6]、清华大学的汉语均衡语料库TH-ACorpus[7]、中国科学院计算技术研究所的跨语言语料库[8]。国内商业领域的搜狗、网易围绕中文新闻语料库也积极进行了探索实践。
从科技语料库的构建研究来看,MatildeTrevisani依托科技文献语料,探讨了通过词生命周期聚类的方式从科学语料库中进行知识动态发现[9]。英国曼彻斯特大学的Nhung T.H.利用生物多样性文献,建立了一个COPIOUS语料库,提出了服务于生物命名实体的金标准[10]。国内语料库的研究主题主要涉及语言文学、教育学、计算机科学、临床医学、图书馆和情报学。其中,语言文学的研究主题主要聚焦于平行语料库、语料库语言学等内容,如谢家成[11]自建了60 万对的平行语料库;王克飞[12]开展了中国英汉平行语料库的设计实践;教育学主要涉及翻译教学、英语写作、外语教学、自主学习等主题,如秦洪武等[13]、方秀才[14]、张宇[15]围绕语料库与教学实践,就翻译教学中的理论依据和实施原则,中国英语教学与语料库结合的成就与不足等问题开展研究;计算机科学涉及语料库的自然语言处理、词性标注、语音合成等研究主题,尤其是在大规模语料库的词性标注方面,张虎等[16]提出了基于主题聚类和分类的语料库词性标注一致性检查新方法,保证大规模语料库标注的正确性;图书馆、情报学主要利用大型科技文献数据库、搜索引擎,抽取其中的关键词构建知识元词库,进行基于语料库的对比研究以及围绕主题词语料库的研究,如李淑平[17]提出了基于语料库的主题图式构建,李佳[18]以科技论文中英文关键词、主题词作为语料库开展了跨语言检索平台研究。
在新时期科技大数据蓬勃发展的背景下,科技资源建设的重点已经不限于单一来源、单一维度数据的开发、应用,更多的是通过整合不同的数据,揭示新规律,发现新关系,支撑新决策,形成新的情报服务模式。本文试图探讨在科技大数据日益复杂、多样的情况下,以现有科技大数据中已有的自标注中英文语料为基础,通过机器学习的方式,形成双语语料库的构建流程,并对最终的双语语料库进行忠实度、流畅度和可接受度评测基础上,总结上述构建方法的优势与特点。
2 机器学习双语语料库构建
2.1 双语语料库的构建
以“分布式能源”为主题,进行机器学习双语语料库的构建实验。对数据的获取及处理方法是以“分布式能源”为检索词,首先在中国科学技术信息研究所科技大数据仓储1.2 亿条的数据中检索相关期刊论文,随后提取其中有中英文摘要和关键词的论文,最终形成中英文关键词词对的对齐、匹配,累积形成20834 个双语词对初试语料集。同时,以“分布式能源”和“Distributed Energy”为检索词,在中国科学技术信息研究所专利数据库、德温特专利数据库中进行检索,下载、查重后形成6428 条专利数据,然后分别按照语种提取其中的专利形成中文专利数据集和英文专利数据集,供后续实验应用。
在实验中,利用了新译科技公司的机器翻译引擎进行训练,基本过程是将20834 个双语词对初试语料集导入机器翻译引擎,经过机器翻译引擎自我学习、深度学习后,生成一个机器翻译模型,使用“神经网络机器翻译+统计机器翻译”,图1 为机器翻译引擎训练示意图。
相比于传统的统计机器翻译(Statistical Machine Translation,SMT),神经网络机器翻译(Neural Machine Translation,NMT)已经在翻译、对话和文本概要总结方面获得非常好的成绩。领域术语语料库在整个过程中保证专业词汇在翻译过程中的专业性和一致性。在训练模块,系统挂载自有术语库,以确保翻译结果精确度更高,翻译结果更加符合业务场景。
译文评估主要从忠实度、流畅度和可接受度3 个方面开展。忠实度是评测译文是否忠实地表达了原文的内容,按 0-5 分打分,打分可含一位小数,最后的得分是所有打分的算术平均值。流畅度是评测译文是否流畅和正宗,按0-5 分打分,打分可含一位小数,最后的得分是所有打分的算术平均值。可理解度则是从用户的角度对最终的翻译结果进行评测,如表1 所示。
以下是一个轮次的实验步骤。
第一步:利用没有经过训练的机器翻译引擎,对中外文专利进行互译;
第二步:各选取100 条数据,对机器翻译结果进行人工校对,按照表1 的标准对忠实度和流畅度进行打分;
第三步:根据检索词(略),抽取相关期刊论文,将其中的中英文词对进行抽取,梳理成对应的词对;
第四步:将期刊的中英词对用于机器学习,学习后的语料对先前提供的数据集进行二次翻译;
第五步:选取第二步已经校对过的数据,进行二次人工校对判别,按照表1 的标准分别对忠实度和流畅度进行打分;

图1 机器翻译引擎训练示意图
第六步:选取中英文同族的专利,将机器翻译的结果和原始提供的译文进行比对,按照表2的标准对可理解度进行打分。
第七步:总结语料构建的流程和效果。
2.2 双语语料库的评测及结果分析
2.2.1 实验结果分析
在整个实验过程中,邀请了10 名北京石油化工学院外语系英语专业2015 级学生参与评测,共进行两轮打分,第一轮对机器翻译前的数据打分,第二轮对机器翻译后的数据打分。
从表3 可以看到,在“神经网络机器翻译 + 统计机器翻译”的机器翻译模型中,虽然模型自身有一定的迭代优化,但双语专业领域词库在机器翻译中扮演着重要的角色,故在双语语料库的构建中要加大双语专业语料的建设工作,同时,也需要根据多主题科技领域的复杂性、时效性特色,进行神经网络模型参数的优化。
此外,从用户接受的角度,最终语料的可理解性依赖于通用语料和专业语料的结合,通过机器学习迭代后,从统计结果来看,“分布式能源”最终的双语语料基本能达到80%的级别。
为了检验译文在专业双语词库介入前后翻译效果,对介入前后忠诚度和流畅度的人工评价结果进行检验,来分析专业双语词库的效果,结果如表4 所示。首先检验数据是否服从正态性,当正态性检验的W值对应的概率小于0.05,则认为数据不服从正态分布,四组数据的Pr<W均小于0.05,说明这四组数据都不服从正态分布;其次,选择检验统计量,对于不服从正态分布的数据可以采用非参数的Wilcoxon秩和检验,主要看Pr>|Z|对应的概率,若小于0.05,那么就有95%的把握认为两组数据存在差异。从结果来看,忠诚度和流畅度均存在显著性差异,同时结合均值,可以认为通过搭配专业双语词库进行的翻译与原来的方法相比,在忠诚度和流畅度方面都有非常杰出的表现。

表1 忠实度、流畅度打分标准

表2 可理解度打分标准

表3 双语翻译结果打分统计表
2.2.2 案例实证分析
表5 分别选择一条中文专利原文和英文专利原文,比较应用“领域双语词库”后的译文效果,以对最终的中英双语语料进行评估。
从第一条的中译英情况来看,第二次的译文与第一次的译文相比,在忠实度和流畅度方面都有所提高,特别是第二次译文中,热电联产系统(CHP)这样的专业词得以体现,专业领域方面表现良好,且在译文样式方面跟原文相比,具有较好的吻合度。
从第二条的英译中情况来看,第二次的译文相较于第一次的译文,在用词方面更为紧凑、准确,对用户表现出较好的可理解度,但在整体的流畅、完整性方面还有待进一步优化。
2.3 双语语料库构建方法的优势分析
经测评和实证分析表明,本文构建的中—英双语语料库通过结合神经网络机器翻译和基于统计的机器翻译方法,对于后续双语语料库的构建具有以下优势。
(1)提高语料库选择与处理效率。采用神经网络机器翻译和基于统计的机器翻译方法,可大幅度地减少语料选择和处理的人工工作量,并在专业主题数据库基础上,快速形成专业领域的双语语料库,相应构建语料库的时间可从按年规划缩短到按月响应,同时由于大量训练样本和算法的介入,处理所耗费的人工也大幅度得以减少。
(2)快速发现基础语料多属性。基于神经网络的自学习机制,可从期刊、专利等规范化文本中,快速发现多属性的基础语料,从而丰富基础语料的多属性值,完成语料的标注,支撑科技大数据知识检索、知识图谱方面的应用。

表4 忠诚度和流畅度的假设检验结果
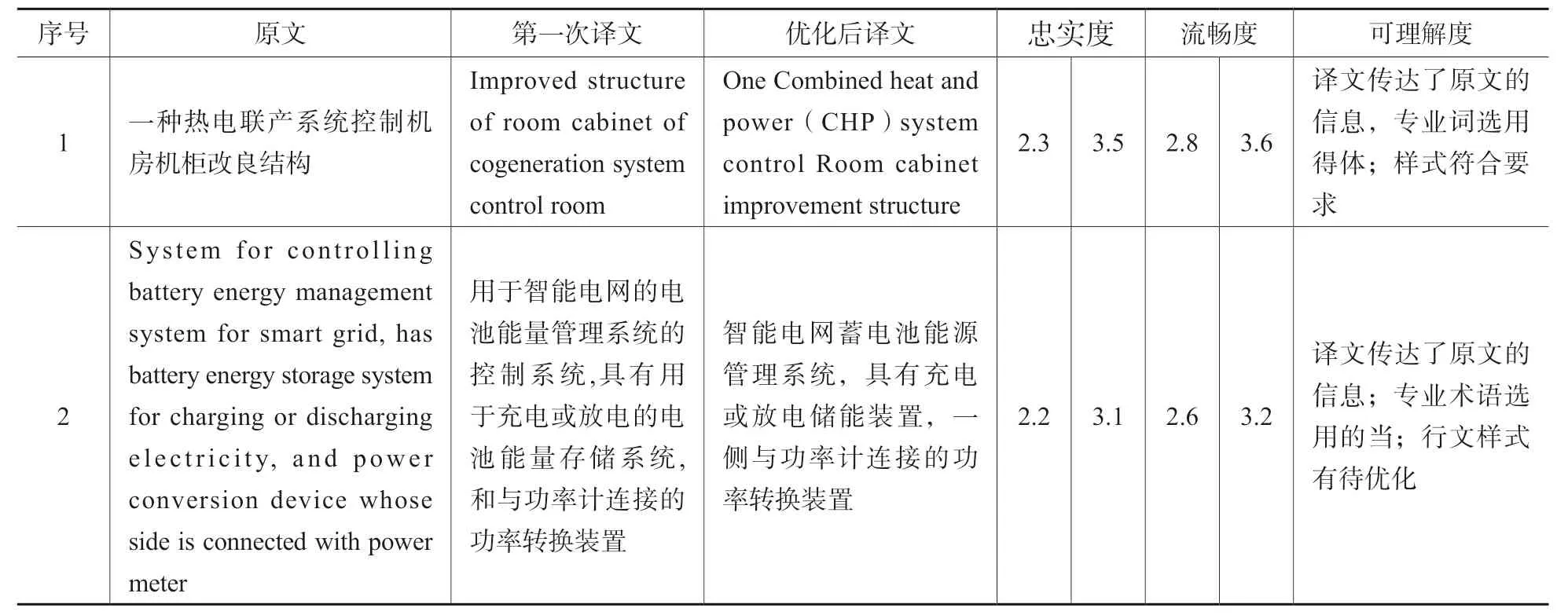
表5 双语语料效果案例
(3)提升双语语料库的工程化构建水平。语料库是人工智能时代的基础工程,已经从传统的文本语料向图片、声音、视频等全媒体语料库转变,其服务模式也从传统的纸质语料向Web接口、API等多种方式提供对外共享应用服务,本文验证的快速语料库构建方法,可以促进各专业领域语料库的工程化水平。
3 启示与结论
本文通过分析新时期科技大数据对语料库构建的要求,从期刊、专利中选择“分布式能源”主题数据集,结合“神经网络机器翻译+统计机器翻译”的机器翻译技术,最后通过人工评测的方式,描述了进行中英双语语料库构建的全过程。我们发现,在人工智能技术发展的大背景下,通过综合利用人工智能技术、大数据技术,新型的语料库构建模式不仅满足了语言学自身的发展,而且通过工程化的语料库构建开发专业领域语料库和服务标杆语料库,在诸如生命科学、人种语音等新兴前沿领域,都处于专业领域语料库的建设期,这为本文构建的双语语料库的实施方法提供了丰富的应用场景。
猜你喜欢
通信技术(2021年12期)2022-01-25
文化创新比较研究(2020年13期)2021-01-14
动漫界·幼教365(大班)(2020年7期)2020-06-26
天津外国语大学学报(2020年1期)2020-03-25
现代计算机(2019年30期)2019-12-11
计算机应用与软件(2018年9期)2018-09-26
电脑爱好者(2017年5期)2017-05-04
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
外语教学理论与实践(2014年2期)2014-06-21
外语教学理论与实践(2014年4期)2014-06-13
