
基于MEA_SVM 空气质量指数预测
2019-02-06 10:56俆乔王胡红萍白艳萍王建中
重庆理工大学学报(自然科学) 2019年12期
俆乔王,胡红萍,白艳萍,王建中
(中北大学 理学院,太原 030051)
当前,营造良好的生态环境作为民生的优先领域,其中最重要的一项便是打赢蓝天防御战,并立足于空气质量的明显改善。因此,空气质量预测对生态环境治理和环保工作具有极其重要的意义。
空气质量数据具有高度复杂的非线性时间序列,是衡量空气质量指数(AQI)的重要依据。目前的AQI预测方法有多元线性回归[1]、BP神经网络[2-3]、支持向量机[4-7]、遗传算法对支持向量机进行改进[8]等。
思维进化算法(MEA)是1999年由孙承意等[9]提出的一种新型群体智能优化算法,继承了遗传算法中的优点且避免了交叉与变异因子产生基因的双重性。王芳等[10]对思维进化算法进行设计,增加了子群体迁徙策略和拥挤度控制策略,使得在搜索新解和利用好的解方面达到最佳平衡;俞俊等[11]运用思维进化算法对风电功率进行预测,有效降低了电力系统的运行成本;高帅等[12]对思维进化算法进行改进用来预测空气质量,取得了良好的效果。
本文针对思维进化算法(MEA)整体搜素的高效率性,结构固有的并行性,良好的泛化性能以及支持向量机(SVM)惩罚函数c和核函数参数g难以寻优的问题,利用思维进化算法(MEA)的模型,将其与支持向量机(SVM)进行结合,得到MEA_SVM评估模型。通过与MEA_SVM、GA_SVM 和PSO_SVM相比,发现其具有较高的空气质量预测精度,误差小,评价优良,说明了该优化算法具有良好预测效果。
通过MEA_SVM算法对空气质量预测准确率以及速度的提高,不仅可以指导人们的生活、工作,为出行提供有效及时的监测手段,还可为医学领域提供不可或缺的防控机制,在一定程度上对老年人心血管疾病、呼吸系统疾病、妊娠期妇女、儿童发育期等方面起到突出的防控作用,减少病发率,提高治愈率,降低因空气污染导致发病的占比。此外,在城市环境规划、大气污染造成的突发事件预警方面,本研究能全方位、多角度提供相关理论支撑。
1 思维进化算法(MEA)
MEA算法是通过分析遗传算法(GA)中存在的问题和人类思维的进化提出的。MEA算法将单层种群进化转化为多层种群进化,继承了达尔文进化论中种群和进化的概念,模拟了人类社会行为的某些方面,每个人都是在一群人中运作的智能代理。为了在团队中取得较高的地位,一个人必须向团队中最成功的人学习。而群体本身也应该遵循同样的原则,在群体间的竞争中生存下去,大大提高了搜索效率。
MEA算法是一种采用迭代法进行连续进化研究的方法。在学习开始时,将个体随机分散在求解空间中,分别计算其得分。得分较高的被保留为优势子种群的原赢家,得分较低的被保留为临时子种群的原赢家,种群被分成优势子种群和临时子种群,其中优势子种群在整个解空间上记录了子群之间竞争中优胜者的信息。临时子种群记录了整个解空间上子种群之间竞争的中间过程。
MEA有趋同和异化两个重要的操作。①趋同:在子种群中,个体竞争成为赢家的过程称为趋同,即判断子群体中的第一个个体是否为该子群体中的最优个体。趋同算子在子空间上完成子种群内部的竞争,实现局部优化。②异化:在整个解决方案空间中,每个子种群竞相成为全局解决方案的赢家并寻找最佳点的过程称为异化。异化算子在整体解空间上完成了子种群之间的竞争,保持了种群的全局搜索能力,因此避免了早熟,种群进化为全局解决方案。③公告栏:公告栏为个体和各子群体之间的交流提供了机会。子种群中的个体将他们的信息张贴在当地的公告栏上。全球公告栏用于发布子种群信息。趋同与异化在进化过程中交替实现信息交换。
2 MEA_SVM 算法
惩罚参数c和核函数参数g的选择对支持向量机(SVM)预测结果的评价十分重要,但通常的c、g寻优主要是Cross-Validation(CV)交叉验证方法下的网格划分,当参数搜索范围变大时,优化过程变慢。群体智能的优化方法随机搜索,全局搜索能力强,因此本文将c和g两个参数作为MEA算法的优化参数,将训练集在CV交叉验证方法下的准确率作为MEA的适应度函数,提出了MEA_SVM算法,分别对AQI的实际值和变化范围进行预测,算法流程如图1所示,具体步骤如下:
步骤1原始数据处理。把基础数据复制1份,1份用于预测AQI的真实值,另1份数据进行粒化,用于预测AQI的变化范围。
步骤2确定适应度函数。将训练集CV交叉验证方法下的准确率作为MEA中的适应度函数。
步骤3参数设置及初始化。按思维进化算法默认参数进行设置,创建初始种群,并且分别以得分最高的前a个个体和前a-2a个体为中心,生产优胜子种群ax和临时子种群by。
步骤4子种群趋同操作。优胜子种群和临时子种群利用趋同算子进行更新,判别个种群中第1个个体是否为最优个体,如果是则种群成熟;若优胜子群体尚未成熟,则将最高分数作为新中心,并且该中心产生新的种群。继续步骤4操作,直到所有子种群都成熟。
步骤5子种群异化操作。找到临时子种群得分高于优胜子种群的种群并记录编号,优胜子种群得分低于临时子种群的种群并记录编号。分别使高得分的临时子种群被得分低的优胜子种群取代,取代完成后补充临时子种群,以保证临时子种群的个数不变。继续步骤4操作,直到没有临时子种群得分高于优胜子种群,异化操作结束。
步骤6解码最佳个体。异化操作完成后,MEA算法迭代寻优完成。依据编码规则,找到最佳的个体进行解码,从而得到对应的SVM 的c和g。
步骤7训练SVM及预测。优化后的c和g用作SVM的训练参数,并利用训练样本对SVM进行训练、学习。训练结束后,分别对实际值和范围进行仿真预测并用平方相关系数(R2)和相对误差(MAPE)进行评估。
3 实验
3.1 数据来源
本文所采用的污染物浓度数据来源于中华人民共和国环境保护部http://datacenter.mep.gov.cn/发布的山西省太原市实时空气质量数据,采样时间为2015-06-10—2017-08-17,采样频率为每天1次,数据各计800组。

图1 MEA_SVM流程
依据我国生态环境部发布的《环境空气质量标准》(GB3095—2012),本文将空气质量指数(AQI)、细 颗 粒 物(PM2.5)、可 吸 入 颗 粒 物(PM10)、二氧化硫(SO2)、一氧化碳(CO)、二氧化氮(NO2)、臭氧(O3)共7项指标作为SVM的输入变量,把次日的AQI作为SVM的输出,并把预测水平分为一级(优)、二级(良)、三级(轻度污染)、四级(中等污染)、五级(重度污染)、六级(严重污染)6个等级。AQI浓度划分表如表1所示。
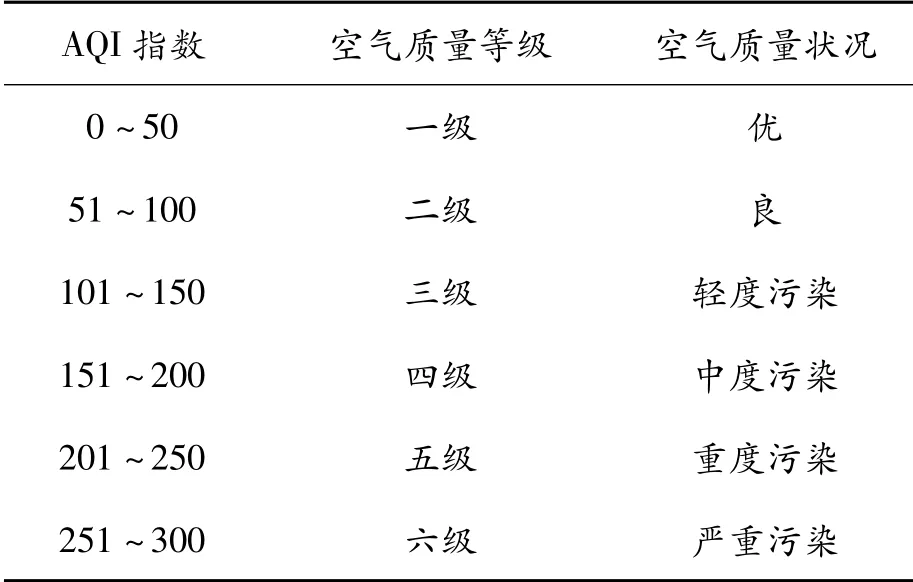
表1 AQI浓度划分表
3.2 实验结果
本文AQI预测的实验环境是在Windows 64位、12核CPU,24G 内存的PC计算机,Matlab 2014a下进行的,分别运行MEA_SVM算法、GA_SVM算法、PSO_SVM算法进行预测。
采用粒化数据对变化范围进行预测。数据粒化时采用三角模糊粒子作为隶属度函数,每4天作为一个粒化窗口,找到每个窗口的Low、R和Up。
隶属度函数为:

式中:a是最小值Low;m是平均值R;b是最大值Up。
对2015-06-10—2017-08-17共800组数据进行粒化,其中每4天作为一个粒化窗口,共200个粒化窗口,用2015-06-10—2017-08-17 200个粒化窗口的空气质量的7个指标预测第201个粒化窗口,即2017-08-18—2017-08-21的AQI最小值Low、平均值R和最大值Up。表2为各预测模型对太原市这4天的AQI指数范围的预测。然后,对用2015-06-10—2017-08-17的800组数据预测2017-08-18—2017-08-21的真实值。表3为2017-08-18—2018-08-21的AQI实测值。
通过运行上述4种预测模型,分别得到MEA_SVM、GA_SVM、PSO_SVM、SVM在AQI预测的最低与最高值及其误差,预测结果如图2所示。4种算法的误差分析如图3所示。
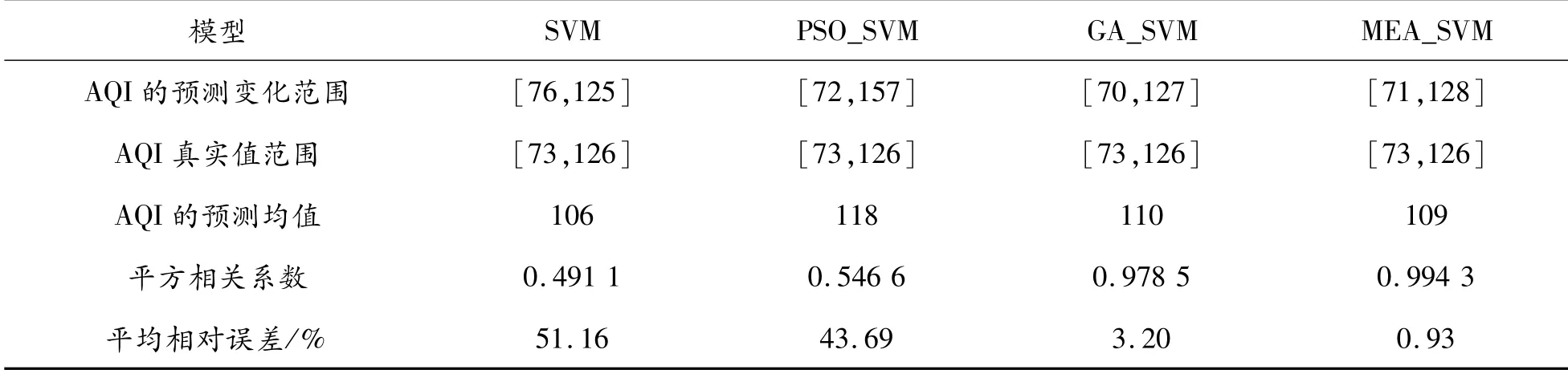
表2 各预测模型预测范围的结果比较

表3 各预测模型预测值与实测值结果比较

表4 各预测模型预测值预测速度比较

图2 4种模型的预测结果

图3 4种模型的误差比较
从表2、3中可以看出:MEA_SVM算法预测的AQI变化范围与实际情况完全符合,平方相关系数接近100%,误差很小,并且MEA_SVM算法在模型平方相关系数和平均相对误差方面都优于其他3种模型,从而该算法更优。从表4中可以看出:MEA_SVM算法的优化速度远高于其他3种模型,耗时最短,显著提高了预测速度。
由图2可以看出:MEA_SVM算法与实际数据点更加接近,与实际情况更加吻合,精度高、预测效果更好。由图3看出:MEA_SVM算法的相对误差在零附近徘徊且接近于零,误差分布比较密集,相比另外3种算法相对误差明显较小。
通过对MEA_SVM、GA_SVM、PSO_SVM、SVM几种预测模型的分析比较,在预测范围方面,MEA_SVM和GA_SVM模型的预测效果远好于PSO_SVM和SVM模型,MEA_SVM和GA_SVM模型都做到了较好的预测范围,但MEA_SVM模型相关系数高于GA_SVM模型且平均相对误差低于GA_SVM模型;在预测每日的AQI值方面,MEA_SVM模型比其他3种模型更接近于实际值,其误差最小。因此,MEA_SVM 模型更适合于空气质量的预测。
4 结束语
本文将SVM 与MEA相结合提出了MEA_SVM算法,对山西省太原市2015—2017年间800组污染物数据进行分析和AQI预测。通过实验发现,预测结果较为可靠、优越、理想。结合AQI预测结果和相对误差对比,MEA_SVM算法与实际情况较为符合,在预测精度、误差率和可靠性方面更优。因此,利用MEA_SVM算法对空气质量预测可以在保证准确率的同时显著提高预测速度,更适用于预测AQI的变化趋势及未来几天的精确值,能更好地指导人们提前做好防范措施,同时为政府相关职能部门制定计划提供及时、准确的预测数据。
猜你喜欢
农机科技推广(2022年7期)2022-08-16
青岛农业大学学报(社会科学版)(2021年3期)2021-12-06
马克思主义哲学研究(2021年1期)2021-11-22
中国现代中药(2021年7期)2021-09-06
河南农业科学(2020年7期)2020-07-22
马克思主义哲学研究(2020年2期)2020-07-21
广西农学报(2019年4期)2019-11-26
中央社会主义学院学报(2017年1期)2017-04-16
汽车与安全(2016年5期)2016-12-01
汽车与安全(2016年5期)2016-12-01
