
大规模MIMO系统基于小区分类-交叉熵的导频调度算法
2019-01-31 02:34:20于银辉周恒杨莹潘昊任嘉鹏
通信学报 2018年12期
于银辉,周恒,杨莹,潘昊,任嘉鹏
(吉林大学通信工程学院,吉林 长春 130012)
1 引言
大规模多输入多输出(MIMO,multiple-in multiple-out)系统是一种基站配备大规模天线阵列的多用户MIMO系统[1]。该系统能在同一时频资源上支持更多的用户,从而大大提高系统吞吐量和能量效率。大规模MIMO是一种依赖空间复用的技术,需要获得精确的上下行信道状态信息(CSI,channel state information)。在时分双工(TDD,time division duplex)模式下,上下行信道具有互异性,上行导频训练阶段产生的干扰会直接对下行数据产生影响,即导频污染[2]。随机矩阵理论分析表明随着基站天线数的不断增加,小区内的干扰和不相关噪声会逐渐消失,但小区间的导频污染并不会随着天线数增加而消失。因此,导频污染的存在限制了大规模MIMO系统性能。
文献[3-6]从不同角度对导频污染问题进行深入研究。文献[3]提出了自适应导频聚类方法来减轻导频污染,可以在任意不对称几何图形的蜂窝网络中进行分散式导频分配优化,但是不同用户的导频序列必须相同或者正交。文献[4]提出了一种导频序列分配策略,该方案的思路是为小区中心的用户分配相同的导频,而为小区边缘的用户分配正交的导频,从而减轻导频污染,提升系统的容量,但当小区边缘的用户数量相对较大时,如何获得所需数量的正交导频序列是一个必须解决的问题。文献[5]提出了基于交替最小化不同小区之间导频相关性的导频设计方案,该方案的导频可以是任意长度以便减轻导频污染的影响来最大化频谱效率。随着更多的信道被分配用于训练,导频序列之间的相关性变小,但是可用于数据传输的资源也随之减少。文献[6]考虑到不同用户与基站之间的信道质量可能不同的情况,提出了一种智能导频分配方案来减轻导频污染,并证明该方案能够有效地提升系统的上行信号与干扰加噪声比(SINR,signal to interference plus noise ratio),但是不同小区间使用的还是相同的正交导频。
鉴于导频污染是相邻小区间复用同一组导频造成的[7],所以本文采用基于小区分类-交叉熵(CC-CE,cell classification-cross entropy)导频调度算法降低导频污染影响。首先采用分类机制将蜂窝小区分成 2类,然后采用交叉熵算法通过最小化K-L(kullback-leibler)距离对导频分布概率进行更新,最终得到导频分布最优解和系统下行和速率最大值,仿真结果验证了该算法的有效性。
2 系统模型
图1给出了多小区多用户的大规模MIMO系统模型,其中包括L个六边形小区,每个小区内配有M根天线的基站和K个单天线的用户[8]。第l小区内所有用户与第j小区基站之间的信道可以表示为

其中,Gjl中所有元素满足独立同分布(IID,independently and identically distributed),其元素gjmlk表示第l小区内第k个用户到第j小区基站天线m之间的小尺度衰落系数;Djl为一个对角矩阵,其对角元素其中βjlk表示第l小区内用户k到第j小区基站之间大尺度衰落系数。本文基于TDD模式对大规模MIMO系统的上下行链路进行讨论。

图1 多小区多用户大规模MIMO系统模型
2.1 上行链路
假设第j小区内所有用户向基站端发送长度为τ的正交导频序列,可表示其中则第j个小区基站接收到的导频序列可以表示为
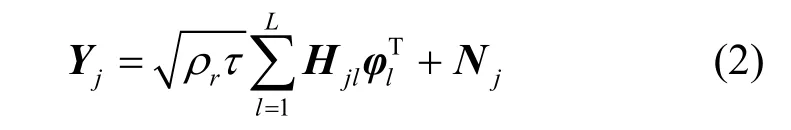
其中,ρ表示导频发射功率,N∈CM×τ表示加性rj高斯白噪声矩阵,其元素是满足均值为 0,方差为的独立同分布高斯随机变量。
基站端利用接收到的导频序列Yj对信道进行估计,从文献[9]中可以得到第j小区期望信道的最小均方误差(MMSE,minimum mean square error)估计为
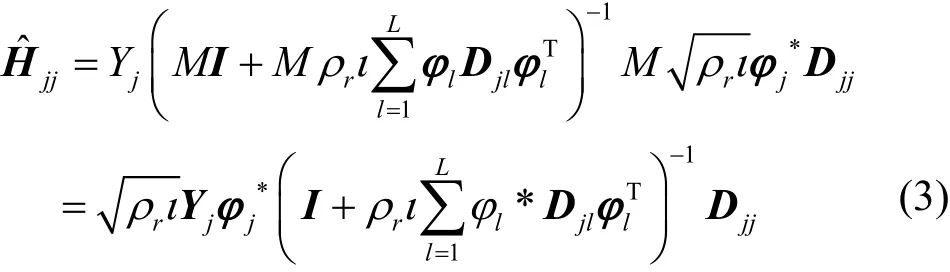
2.2 下行链路
假设第j小区基站向用户发送的数据为的线性预编码矩阵,f(·)表示基站端特定的线性预编码技术[10]。本文采用匹配滤波(MF,matched filter)预编码方案,定义为:Bj=。经过预编码后基站发送的信号矩阵可以表示为Bj Sj,则第j小区K个用户接收到的数据矢量可以表示为
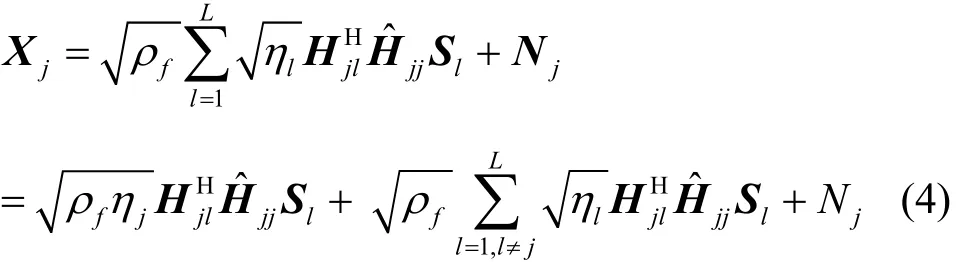
其中,fρ为下行发射功率,为预编码矩阵Bl归一化因子,即
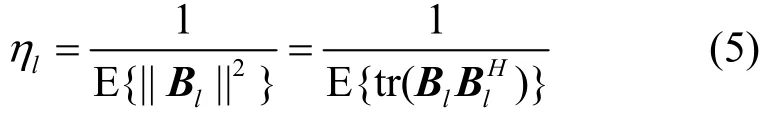
其中,E表示期望。
2.3 系统性能
根据文献[11]可得大规模MIMO系统下行链路第j小区第k个用户的速率可表示为
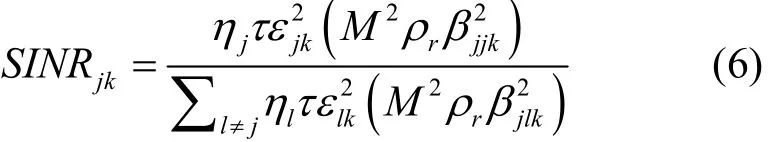
第j小区第k用户的速率可表示为
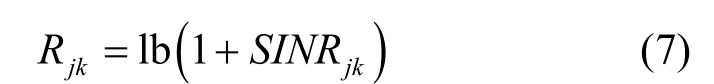
3 提出方案
本文的目的是通过循环找到使系统下行和速率达到最大的导频分布方案A∗。由于同一个导频不能在小区内复用,所以本文遵循式(8)所示导频调度方案来进行问题的优化。
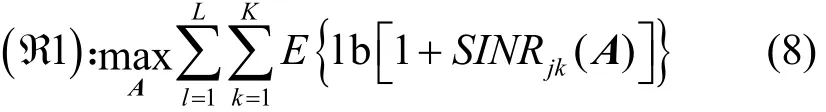
当系统存在导频污染的情况下,并不能准确获得信道状态信息,所以不能直接解决问题ℜ1。当基站端天线数目无限多时,小尺度衰落系数gjj保持不变,因此可以忽略小尺度衰落系数对系统的影响。由于在相干时间内大尺度衰落系数βjjk变化很慢,所以问题ℜ1可以变换成解决式(9)所示问题ℜ2进行导频调度的优化。
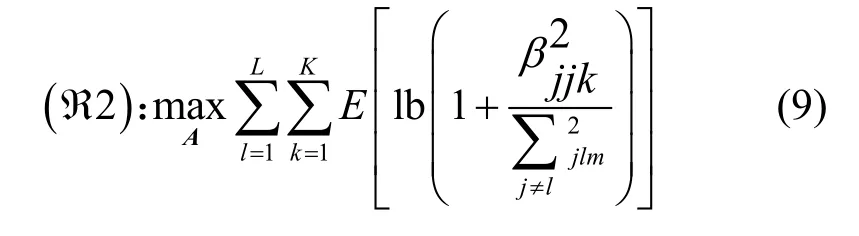
根据式(9)可以看出问题ℜ2是基于排列优化问题,最优解可以通过贪婪搜索算法获得。然而该算法求得最优解A∗的计算复杂度为(K! )L-1,其计算量将会很大。
3.1 交叉熵方法优化问题原理
交叉熵方法(CE,cross-entropy)的主要思想是将组合优化问题转化为关联随机优化问题[12],通过适当的采样来随机逼近最优解,通俗地讲就是构造随机序列使其以一定概率收敛到最优或次优解。在求解目标问题时,目标问题最优解出现的概率非常小,于是将组合优化问题转化为小概率事件进行模拟解决处理。然而和小概率事件模拟不同的是交叉熵方法在得到参数的估计值之后,会把该值带入到原始问题中进行重新求解,而不是对小概率事件进行估计。
假设需要解决以下优化问题

其中,S(x)为小概率事件,χ为一组随机变量状态集合。假设{f(x,v),v∈V}为定义变量x∈X集合中,以v为参数的概率密度函数。下面对式(10)得到的组合优化问题针对确定变量v时转换成小概率事件估计问题进行求解
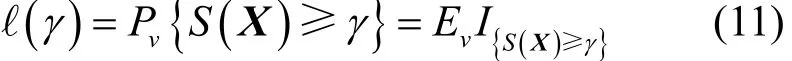
其中,γ表示一个未知或者已知值参数,X表示根据概率密度函数f(x,v)得到的一个随机向量。这样将组合优化问题转化成对应的统计问题。根据交叉熵方法的K-L距离最短原理可知,可将参数v∗的估计表示为
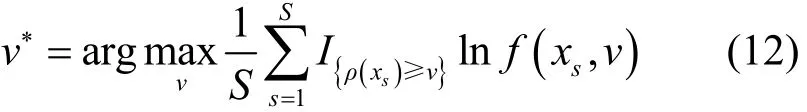
其中,定义ρ(·)表示χ集合中的实值函数,通过交叉熵方法找到最优解集合X使实值函数ρ(·)最大化。
小概率事件模拟的交叉熵方法可以分为以下3步。
步骤 1根据随机变量的概率函数f(· ,v)从全部解集合χ中随机选取一样本,记为然后该样本中所有元素通过计算实值函数得到一组性能值记为
步骤2按照样本的实值函数值的大小,将样本提取前得到的子样本成为精英解,其中ρ∈ ( 0 , 1)表示分位系数也称为精英比例, ■·■表示向上取整操作;同时精英解中实值函数最小值记为η。
步骤3利用精英解迭代更新概率分布参数v,以便于在下一次更新迭代时产生更优的随机样本。确切地说参数v是通过在精英解集合和概率密度函数f(· ,v)间通过最小化K-L距离进行更新而得到的,这个进程等价于解决式(13)。
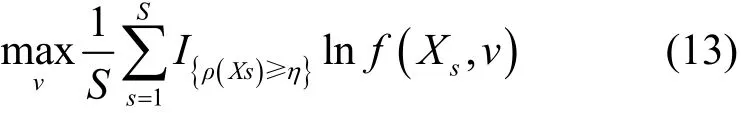
其中,函数I{ρ(Xs)≥η}表示当条件满足时为1,否则为0。
根据交叉熵K-L最短距离可知,利用该方法得到的某次迭代带参数概率密度f(· ,v)是与最优概率密度的模拟估计最短距离,并不能证明其结果是否为最优。这也说明CE方法是通过逐次尝试更新,最终达到结果合理的启发式算法。
3.2 基于小区分类-交叉熵的导频调度算法
-在大规模MIMO系统中基站利用用户发送的导频信息进行上行信道估计时,其他小区用户发送相同导频会对本小区发送的导频产生干扰从而影响基站端信道估计的准确性。王海荣等[13]分析了蜂窝网络中导频功率控制方法,蜂窝网络小区分类方案如图2所示,将蜂窝网络分为2类,同一类的小区使用相同导频,不同类间的小区使用相互正交的导频,以消除相邻不同类间用户间的导频污染。
由于大尺度衰落系数随距离的增加而急速下降,当用户与基站距离较大时,大尺度衰落系数就可以忽略不计。这是基于大尺度衰落系数与距离紧密相关。大尺度衰落系数βjlk可以表示为
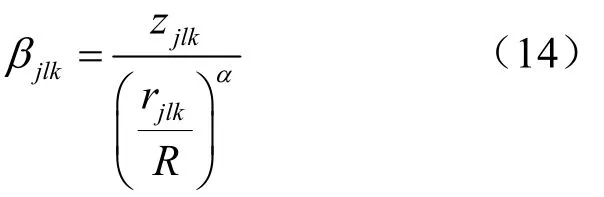
其中,zjlk是服从对数正态分布的随机阴影衰落变量;10lgzjlk服从均值为零,标准差为 σshadow的高斯分布;rjlk表示第l小区中第k个移动用户到第j小区基站的距离;R表示小区半径。
所以本文只考虑相邻小区之间的导频污染而忽略距离目标小区较远的小区中用户产生的干扰。本文采用文献[13]小区分类方法将蜂窝网络分为两类后,同类蜂窝网络系统模型如图3所示。每个小区有K个用户和一个M根天线的基站。所有小区排成一字型,每个用户向基站发送导频和相关的数据信息。在每个小区内,每个用户所分配的导频是相互正交的,同类小区复用同一组导频。为了保证同一小区内用户之间没有干扰,导频长度必须满足τ≥K。
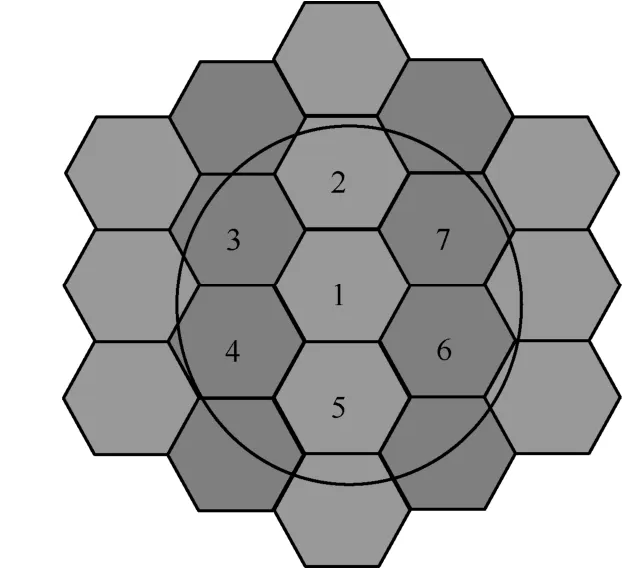
图2 大规模MIMO系统下蜂窝网络小区分类方案
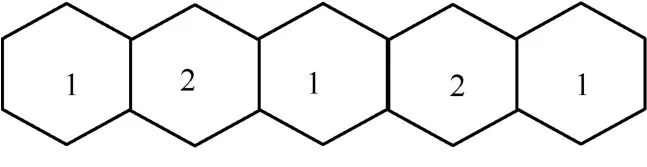
图3 同类蜂窝网络系统模型
为了将CE方法应用于导频调度问题,首先构建随机理论产生导频分配给用户的参数矩阵A,大规模MIMO系统模型下具有Q个小区,并且K个导频能够在不同小区间进行复用,所以定义了Q个K×K概率矩阵表示将第l导频序列分配给第q个小区第k个用户的概率。因此通过概率矩阵π得到参数矩阵A的概率分布f(· ,π),并定义如下。
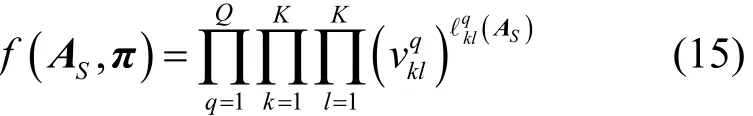
其中, ℓq(A)表示一个指数变量,当A中的第
klSS
(q,k)个元素值为l时,变量 ℓq(A)为1,否则为0。
klS A是概率密度函数为f(· ,π)的一个随机矩阵,并且AS是从概率密度函数f(· ,π)中得到的一组随机样本又称随机候选解。
当相关参数分布确定之后,接下来根据交叉熵方法的K-L距离最小式(13)对概率矩阵的更新规则进行制定。首先根据式(15)从概率分布函数f(· ,π)中可得到一组共S个相关导频分配给对应用户的参数矩阵。然后通过式(6)计算每个候选解的性能指标得到一组性能值为同时考虑到一个小区内每个导频只能分配给一个用户,所以要求Vq的每一列元素值的总数为1。所以优化更新问题式(13)可表示如下。
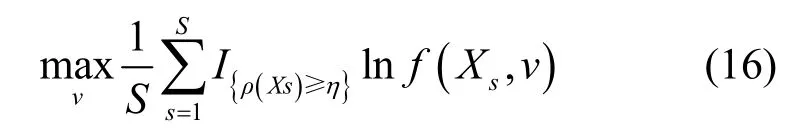
其中条件

因此在条件Vq的每一列元素值的总数为1,即式(17)下,为了最大化式(16)的问题,需要通过拉格朗日乘子的每一列进行处理,计算式如下。
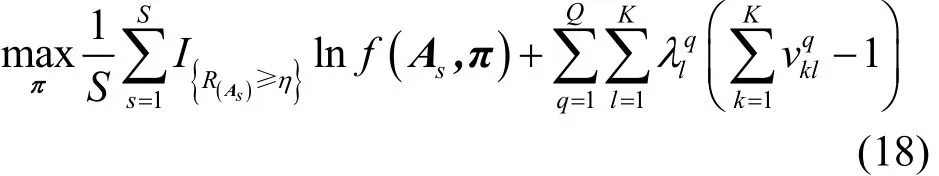
将式(18)对进行求偏导,同时令求得的偏导为0,可得
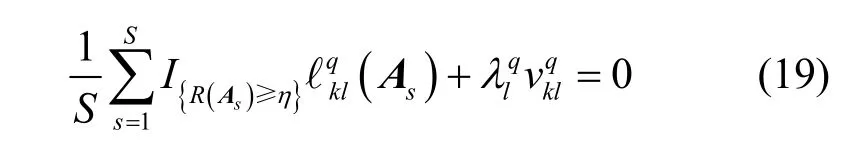
对式(19)k= 1 ,2,… ,K进行求和,可得
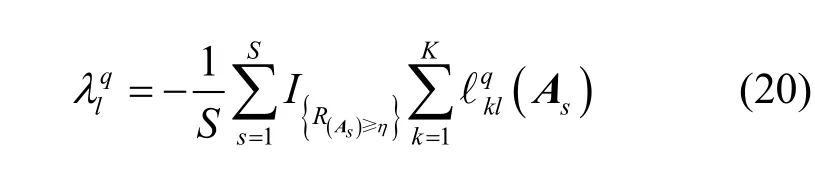
把式(20)代入式(19)得到
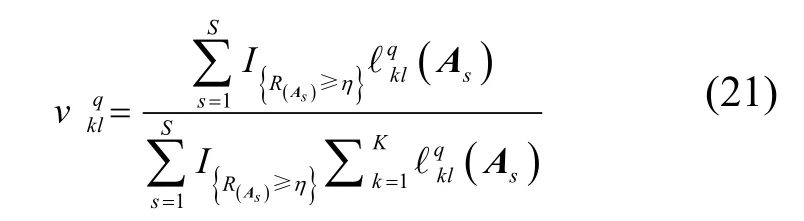
参数更新式(21)仅用于单次迭代更新,为了不失一般性,本文设置了一种平滑更新机制,通过计算当前数据和上次迭代更新数据最终得到期望数据,其计算式如下
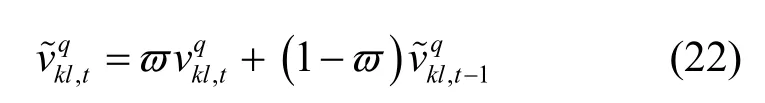
4 仿真结果及分析
本节将用数值仿真的方法评估 CC-CE算法给大规模 MIMO系统带来的性能提升。在仿真场景中,本文考虑L个正六边形小区网络,其中每个小区内包含一个具有M根天线的基站和K个单天线小区用户,目标小区是被6个小区环绕的中心小区。系统仿真参数如表1所示。

表1 系统仿真参数
图4表示基于小区分类的交叉熵算法和贪婪算法实现导频调度时,每次迭代更新通过500次蒙特卡洛仿真得到的小区每个用户平均速率,通过图 4可以看出 CC-CE算法在第tconv=16次迭代更新后可达到与贪婪算法相似值接近于99.9%。
表2为CC-CE算法与贪婪算法复杂度对比,其算法内候选解数量S=400,当小区内用户数K=8时,CC-CE算法计算Stconv= 4 00 × 7 = 2 800次就可获得最优的导频分配方案,而贪婪算法的计算复杂度表示为(K! )L-1= 5 18 400,CC-CE算法的复杂度约为贪婪算法复杂度的 0.54%。当小区内用户数K= 2 5时,其算法候选解数量S= 1 000,贪婪算法需要计算 1 .39× 10151次才能获得最优解,这么高的计算复杂度在实际环境中很难实现,而 CC-CE算法计算复杂为Stconv= 1 000× 1 6 = 1 6 000,所以CC-CE算法能够大幅度降低计算复杂度。
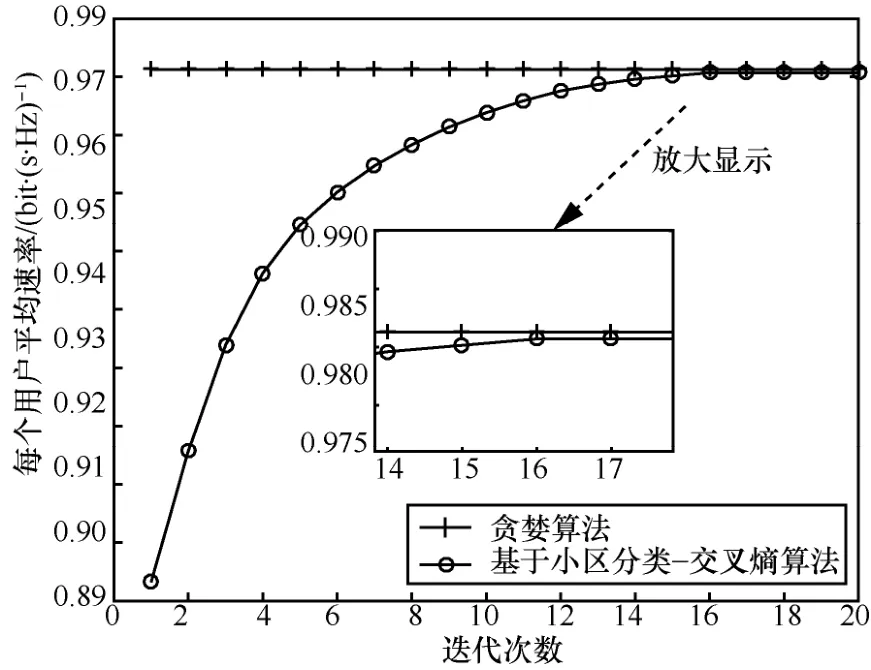
图4 CC-CE算法和贪婪算法对比

表2 CC-CE算法与贪婪算法计算复杂度对比
从图5中可以看出本文所提出的CC-CE算法能有效提高系统和速率,并随着基站天线数目的增加而增加。并且CC-CE算法得到的系统和速率相较于小区分类算法会有所提升,提升约0.6 bit/(s·Hz)。但是当基站天线数目继续增加时系统和速率仍然趋于一定值,主要是因为本算法通过导频调度只减轻导频污染的影响,并没有完全消除导频污染。
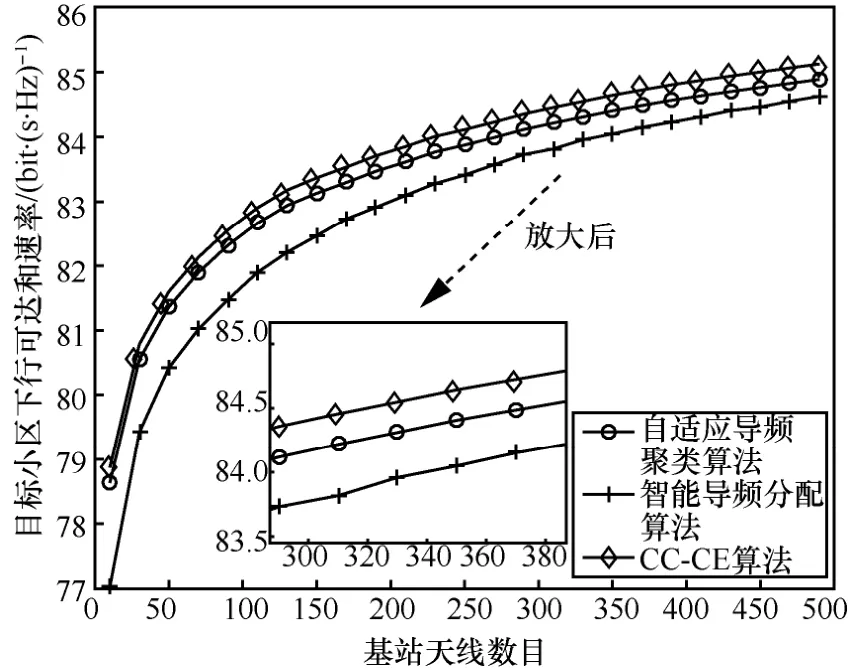
图5 不同导频调度方法系统下行和速率与基站天线之间的对比
图6表示多小区多用户大规模MIMO系统下,CC-CE算法与Mochao-urab等[3]提出的自适应聚类算法和Zhu等[6]提出的智能导频分配算法的系统性能对比图。从图6中可以看出,CC-CE算法得到的系统性能要优于其他2种算法,并随着基站天线数目的增加而增加。
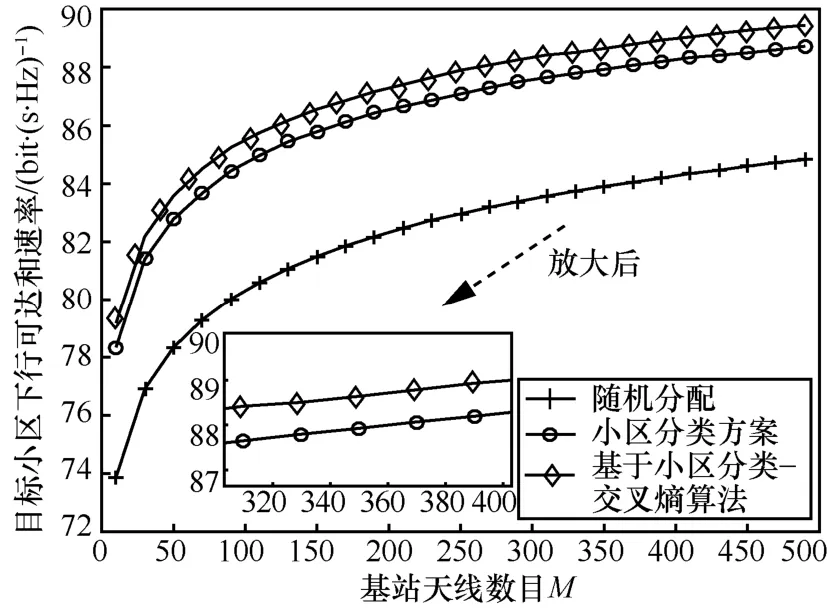
图6 CC-CE算法与其他算法系统性能对比
5 结论
导频污染问题可以通过将相邻小区中具有很高干扰的用户分配不同的导频来消除,但是这种基于排列的组合优化问题属于非凸问题。所以本文采用小区分类和交叉熵机制,通过迭代运算解决导频调度问题以减轻大规模MIMO系统中的导频污染。仿真结果表明,本文所提出的算法不仅能够有效提高系统性能,还降低算法计算复杂度。
猜你喜欢
初中生世界·八年级(2019年6期)2019-08-13 18:41:18
探索科学(2017年4期)2017-05-04 04:09:47
小学生导刊(低年级)(2016年6期)2016-07-02 22:17:33
电信科学(2016年9期)2016-06-15 20:27:26
中国交通信息化(2016年8期)2016-06-06 03:56:25
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:42
移动通信(2015年17期)2015-08-24 08:13:10
计算机工程(2015年8期)2015-07-03 12:19:54
电子设计工程(2015年8期)2015-02-27 12:05:34
发明与创新(2015年29期)2015-02-27 10:39:43
