
人机协作中人的动作终点预测
2019-01-30 01:31:52陈友东刘嘉蕾胡澜晓
北京航空航天大学学报 2019年1期
陈友东, 刘嘉蕾, 胡澜晓
(北京航空航天大学 机械工程及自动化学院, 北京 100083)
在制造业中,机器人越来越多地与人共存于同一工作空间[1]。机器人具有速度、精度的优势,人具有感知和灵活适应的优势,人机协作(Human-Robot Collaboration,HRC)很好地结合了机器人和人的优势[2-3]。机器人和人协同合作,共同完成工作任务。这种新的工作模式对生产装配而言尤其有益,比如,可以通过使机器人为装配人员定位工具或传递零件等方式,减少完成任务的时间。而HRC装配的成功实践,离不开机器人对人类运动的可靠预测[4-5]。
在HRC领域中,一些研究旨在通过对人和机器人执行任务的离散动作进行分析,利用动作之间的转移关系来预测后续动作。Hawkins等[6]则通过贝叶斯网络推理预测之后的行为。Nikolaidis和Shah[7]通过马尔可夫决策过程对人和机器人的角色信息进行编码从而推断下一步的动作。文献[8]将一个任务定义为不同动作的集合,使用有限状态机对HRC过程进行建模。这些研究均聚焦于对后续动作的预测,而未强调对当前动作的预测。高效的HRC,应该实现机器人对人的动作的实时预测。同时,这些研究仅利用了动作的先后次序信息,而没有利用动作本身的几何或运动学信息。
对动作本身的研究隶属于动作识别、行为理解领域。而在大多数动作识别[9-10]或行为理解[11-12]的研究中,多通过对完整的人体动作或行为进行分析,提取时空特征,然后进行分类或识别。这些研究中区分的对象(动作或行为)是粗粒度的(如走、跑、跳),并且没有提前预测。本文根据动作的初始部分提前对人的动作终点做出预测。
在运动预测的相关研究中,Mainprice等[13]认为单臂的伸及动作(reaching motion)对于一个未知的成本函数而言是最优的。通过学习该成本函数,用随机轨迹优化算法[14]来迭代地规划人的运动轨迹,从而实现预测人类运动的目的。在Mainprice和Berenson的另一篇文章中[15],基于高斯混合模型(Gaussian Mixture Model,GMM)构建了人类的运动库,进而利用回归方法对人的运动提前做出预测。然而模型未考虑时间特征等因素,导致在运动的早期阶段,预测结果的准确率非常低。Pérez-D’Arpino和Shah[5]通过时间序列分析的方法,对人的伸及动作的终点进行预测,盖因模型强调实时性,而忽视了预测的准确率。
人的动作不是瞬时性的行为,而是一个连续的过程,因此常用时间序列数据对其进行分析。隐马尔可夫模型(HMM)被认为是对动作序列进行建模和分类的有效工具[16-17]。但HMM仅考虑各状态的转移概率,难以表示动作的上下文意义。
在机器学习领域,对动态序列数据的建模一直是研究的热点之一。静态模型,如卷积神经网络(Convolutional Neural Networks,CNN)和深度置信网络(Deep Belief Network,DBN),只专注于数据特征而不考虑时间依赖性。动态模型试图寻找时序数据之间的联系,其中循环神经网络(Recurrent Neural Network,RNN)[18]是一种对动态序列建模的有效方法[19],已经被证明在人体动作建模方面表现优异[20-21]。但是,传统的RNN由于存在梯度消失等问题[22],难以对较长的序列进行建模。
为解决这一问题,Hochreiter和Schmidhuber[23]提出了长短时记忆(LSTM)网络。LSTM网络的神经元使用多个功能不同的门来控制神经元并存储信息,具有保存更长时间的重要信息的能力。这种信息保存特性使得LSTM网络在处理、分类或预测复杂动态序列方面表现优异。研究表明,LSTM网络在处理一些实际问题时,如在语言建模、语音识别[24]、机器翻译、行为识别[25]、视频分析[26]、交通流速预测[27]等研究领域,取得了很好的效果[28-30]。
本文提出一种基于LSTM网络的动作终点预测方法。通过采集少量人的动作数据,对数据做增强处理,训练LSTM网络,构建动作序列与动作终点之间的映射。应用时,根据人的动作的初始部分,通过模型对动作终点提前做出预测。本文方法在一定程度上避免了大量数据采集的困难,避免了直接处理或分析图像或视频等多媒体数据的对硬件和时间的要求,利用少量的数据,对动作终点做出了提前预测,并取得了较好的预测效果。
1 问题阐述
1.1 应用场景
本文首先通过一个实例来阐述将要研究的人的动作终点预测问题。
考虑如下场景:在装配工位上,一名装配工人与一台机器人,二者相互配合,完成某个装配体的组装。整个装配任务由一系列操作组成,在装配过程中,装配工人从零件区或工具箱中陆续捡取零件或工具执行各种操作。在这种模式下,机器人基本处于闲置状态。而事实上,机器人配备了摄像头和机械手,能够观测装配空间内的活动,可以帮助人固定装配的部件,也可以向人提供工具或零部件。
为了提高装配效率,可以使机器人在观察人类操作的基础上,提前预测出装配工人要捡取哪件工具或零部件,从而迅速规划自身运动,快速反应,配合装配工人工作。
1.2 问题分析
通常情况下,装配线上的装配工位由零件区、工具区以及装配区3部分构成,其中可能的布局如图1所示。待组装的零部件从流水线上传来,装配所需的连接件放置在零件区,装配所用的工具放置在工具区。零件区和工具区又分别由若干个不同的区域组成,不同的区域摆放着不同的联结件(如螺栓、螺母等)或工具(如扳手、钳子等)。
一项装配任务往往由一系列具体的操作组成,每项操作又常与一定的对象(零件和工具)相关联。而在上述的装配工位中,各个对象又与特定的区域(或位置)相关联。因此,可以通过预测人的抓取动作的终点位置,再依据位置与对象的对应关系,获知人要抓取的对象。即需要研究如何通过(部分)动作序列,提前预测动作的终点位置。
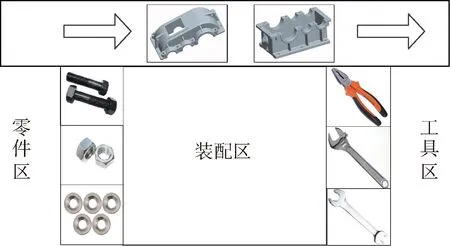
图1 装配工位示意图Fig.1 Schematic of assembly station
1.3 数学模型
通过上述分析可知,需要让机器人对人当前的动作进行分析,预测人的动作终点位置,从而预测人要抓取的对象(工具或零件)。当然,无条件的预测是不存在的,科学的预测建立在充分的依据之上。为此,本文选择机器学习的方法来赋予机器人预测人动作终点位置的能力。
如果将动作序列与动作终点位置的组合看作一个动作样本,将到达同一终点位置的所有动作样本视为一个类别,那么动作终点的预测问题就可以抽象为机器学习中的分类问题。问题的输入是一个动作序列,问题的输出是人的动作终点。要实现的目标,即根据动作的起始部分,从固定而有限的终点位置的集合中,选取后验概率最大的终点位置。
动作终点位置的预测问题可以通过以下2步来解决:
(1)
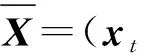
(2)
2 预测方法
2.1 模型框架
让机器人通过自主学习的方式,从人的多次演示中获取知识,从而逐渐具备预测装配工人动作终点位置的能力。整个过程分为2个阶段:①训练(学习)阶段;②预测(应用)阶段。在训练阶段,通过采集人的动作序列,从中提取动作特征,然后将动作特征与真实的终点位置关联起来,以此作为训练样本,训练LSTM网络,获得最优的模型参数。在应用阶段,当仅观测到部分动作序列时(动作未完成,序列不完整),提取动作特征,作为模型的输入,对动作的终点位置进行预测。这2个阶段的内容分别对应1.3节中的2个步骤。
为了充分利用已有数据中的信息,使模型能够展现出更好的预测效果,本文将对训练数据进行增强处理,一方面是要对样本的数量进行扩充,另一方面则是要尽量使训练数据与测试数据具有相近的分布(详见第3节实验部分)。
2.2 LSTM网络
LSTM网络是一种特殊的RNN。其对传统RNN的神经元做了改进,使得网络对序列中较长时间之前的输入也有了记忆的能力,从而更有利于对时间序列数据的处理和分析。改进后的神经元称为一个LSTM单元,由记忆单元、输入门、遗忘门、输出门组成。记忆单元用于存储状态信息,门则用于控制何时及如何更新记忆单元的状态。输入门用于控制该单元接受输入信息;遗忘门用于控制将上一时刻的输出保留到该单元;输出门则决定输出存储在记忆单元中的信息。网络的前向计算过程,即根据输入和模型参数计算输出,由式(3)~式(7)共同完成:
ft=σ(Wf·[ht-1,xt]+bf)
(3)
it=σ(Wi·[ht-1,xt]+bi)
(4)
ct=ft⊙ct-1+it⊙ tanh(Wc·[ht-1,xt]+bc)
(5)
ot=σ(Wo·[ht-1,xt]+bo)
(6)
ht=ot⊙ tanh(ct)
(7)
式中:xt为LSTM的输入向量;ft为遗忘门的激活向量;it为输入门的激活向量;ct为单元状态向量;ot为输出门的激活向量;ht为LSTM单元的输出向量;W和b分别为需要训练的权重矩阵和偏置值;σ为sigmoid函数;tanh为双曲函数;⊙表示逐点相乘;[·,·] 表示向量拼接。
LSTM网络的训练方法采用的是基于时间的反向传播 (Back Propagation Trough Time,BPTT)算法[28],该算法主要包括4个步骤:①按照前向计算方法(式(3)~式(7))计算LSTM网络的输出值;②反向计算每个LSTM单元的误差项,包括按时间和网络层级2个反向传播的方向;③根据相应的误差项,计算各个权重的梯度;④使用基于梯度下降的优化算法更新权重。
基于梯度下降的优化算法多种多样,如随机梯度下降(Stochastic Gradient Descent,SGD)[31]、AdaGrad[32]、RMSProp[33]。本文选用文献[34]提出的Adam算法。Adam算法是一种基于梯度下降的有效随机优化方法,该算法结合了AdaGrad和RMSProp的优势,能够对不同的参数分别计算相适应的学习率并且占用的存储资源较少。相比于其他的随机优化方法,Adam算法在实际应用中的整体表现更加优越。
2.3 基于LSTM网络的动作终点预测
本文将人的动作表示为一个形如X={x1,x2,…,xt,…,xT}的多元时间序列。
将可能的终点位置yj(j=1,2,…,K)用数字按从小到大的顺序编号,并编码为独热码(one-hot coding)向量。网络结构示意图如图2所示。
网络输入层的神经元个数与动作序列的长度(T)相等,网络最终输出层的神经元个数与可能的终点位置总数(K)相等。将动作序列按时序赋给网络的输入神经元,即将动作第t帧的数据xt作为网络输入层第t个神经元的输入。输入层的输出经过网络的2个隐藏层(隐藏层的神经元是LSTM单元)进行非线性变换。网络第2个隐藏层的最后一个单元的输出是LSTM网络的原始输出。首先,在原始输出层之后增加一个全连接层,对原始输出做线性变换,使其输出与网络的最终输出维度相等。然后,通过一个softmax层,将全连接层的输出归一化,转化为各个可能的终点位置对应的概率。最后,选择后验概率最大的终点位置作为预测结果。
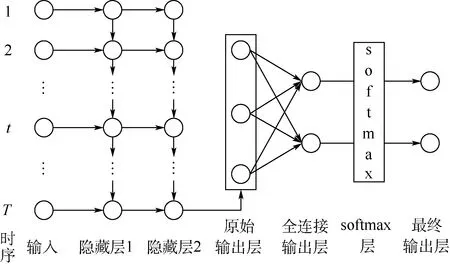
图2 网络结构示意图Fig.2 Schematic of network structure
3 实 验
3.1 实验设置
为研究人的动作终点预测问题,邀请被试人员站在实验台前,伸手去抓实验台上的某件工具,采集人抓取不同工具的动作数据。
实验场景如图3所示,图中左下角黄色矩形框中的是微软Kinect传感器,摄像头正对着实验台,用于采集动作数据;红色矩形框中的是实验台上摆放的工具,也就是被试人员要抓取的对象。
实验台的桌面则被划分为9个小区域,每个区域内放置着一种工具,如图4所示。

图3 实验场景Fig.3 Experimental scene

图4 实验台的布置Fig.4 Layout of experiment table
3.2 实验数据
3.2.1 数据选择
机器学习中最重要的一步是特征提取。很多情况下,特征选择的好坏决定了模型的效果。在传统机器学习方法中,特征提取往往是根据人类专家的经验开发相应的算法来完成的。而在深度学习中,特征提取是由网络通过多层非线性变换完成的。
不同于动作识别领域研究的走、跑、跳等粗粒度的动作,其特征比较明显,相对易于区分。在HRC装配场景中的常见动作有人伸手去工位上捡起某件零件或工具,伸手去接收机器人递来的工具,亦或是伸手将零件递给机器人等。这些动作,于人而言,执行的都是一个伸及动作,即将手伸到某一位置。对于这样的动作,区分起来是困难的,因为抓取(或捡起、接收、传递)不同对象时,动作本质上并无明显的差别,难以根据动作的固有特征来区分,达到预测动作终点位置的目的。
通过1.2节的分析可知,被抓取的对象是与特定的位置关联的。在HRC装配案例中,主要的运动对象是手,手的运动能够更加直接地表征人的抓取动作。在抓取某一对象的过程中,手的轨迹在空间的分布是不同的。而且,不同于行为分析研究中直接处理大量的图像或视频数据,手的轨迹数据结构简单,便于处理和分析。因此,可以通过手的轨迹来区分抓取不同对象的动作。进而,可以根据动作起始部分的轨迹对抓取动作进行区分,从而对动作的终点位置提前做出预测。
3.2.2 数据采集
实验使用微软的Kinect传感器,以30帧/s的传输速率记录人的动作。Kinect采集的数据包含颜色、深度和点云信息,以RGB-D图像序列的形式传输。Kinect采集的原始RGB-D图像序列如图5所示。
为从图像序列中获取人手的轨迹,基于OpenCV库,使用C++语言开发了图像获取与处理程序,从Kinect传感器传回的RGB-D图像流中,实时地获取手的空间坐标,构成人手的空间轨迹。程序的流程如图6所示。
实验邀请了5名被试人员,每次抓取前,被试人员站在实验台前,待“开始”指令发出,马上伸手去抓取实验台上的一件工具。为保证样本的代表性,抓取动作的起点不完全一致;由于人的运动的灵活性,抓取动作的速度也不尽相同;而且,不同的人的抓取动作的特点也不尽相同。
次执行抓取操作的过程中,采集100帧数据,从而获得代表人手位置的100个点的坐标,构成一条空间轨迹。

图5 Kinect采集的原始RGB-D图像Fig.5 Original RGB-D images captured by Kinect
以下将抓取同种工具的若干条轨迹视为一组。绘制这9(组)×5(人)×8(次)抓取动作的轨迹,如图7所示。图中,轨迹的起点位置在右侧,终点位置在左侧。轨迹的起点由人站立的位置确定,在实验中的差异并不是很大。轨迹的终点位置则由物体在实验台上的摆放位置决定(见图4)。
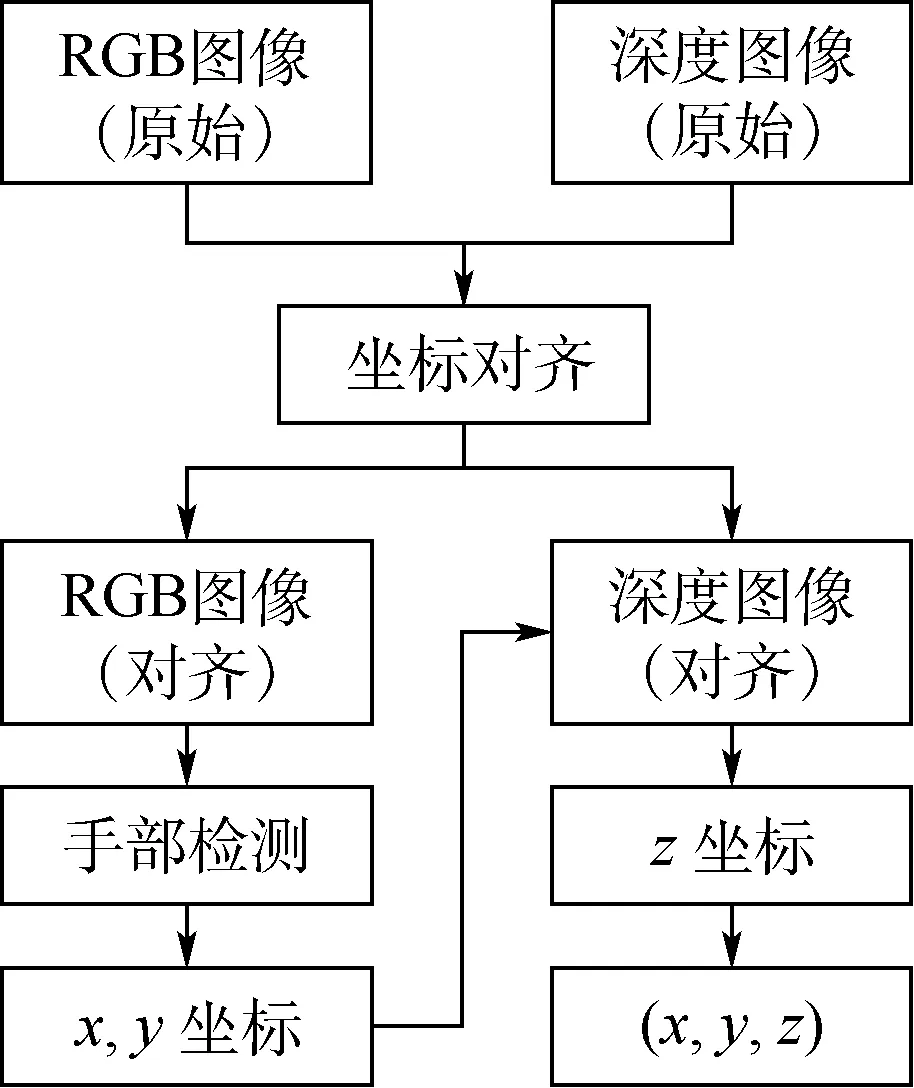
图6 从RGB-D图像中获取手的坐标Fig.6 Hand coordinates obtained from RGB-D images
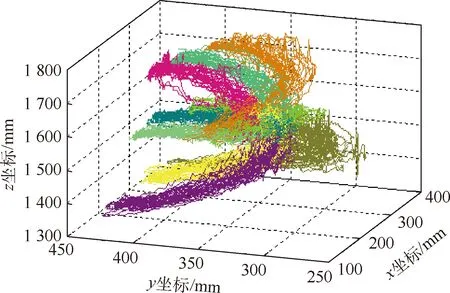
图7 轨迹的空间分布Fig.7 Spatial distribution of trajectories
3.2.3 数据预处理
由于传感器的误差等原因,采集到的轨迹数据中包含异常数据与大量噪声。为此,先通过设置固定阈值的方式,去除轨迹中存在的明显异常坐标;再采用滑动平均法,去除轨迹中的噪声。因为轨迹数据在时间上是有先后顺序的,为此给轨迹加入时间维度,每一帧轨迹数据变为xt=(t,x,y,z)。由于人体动作的灵活性,抓取动作的速度不同,运动轨迹在时间轴上不对等。为方便后续处理,这里采用动态时间归整(Dynamic Time Warping,DTW)算法[35]将轨迹进行时序对齐。图8为DTW算法的示意图,其中,ti和si(i=1,2,…,7) 分别为轨迹模板和轨迹样本在第i时刻的数据。
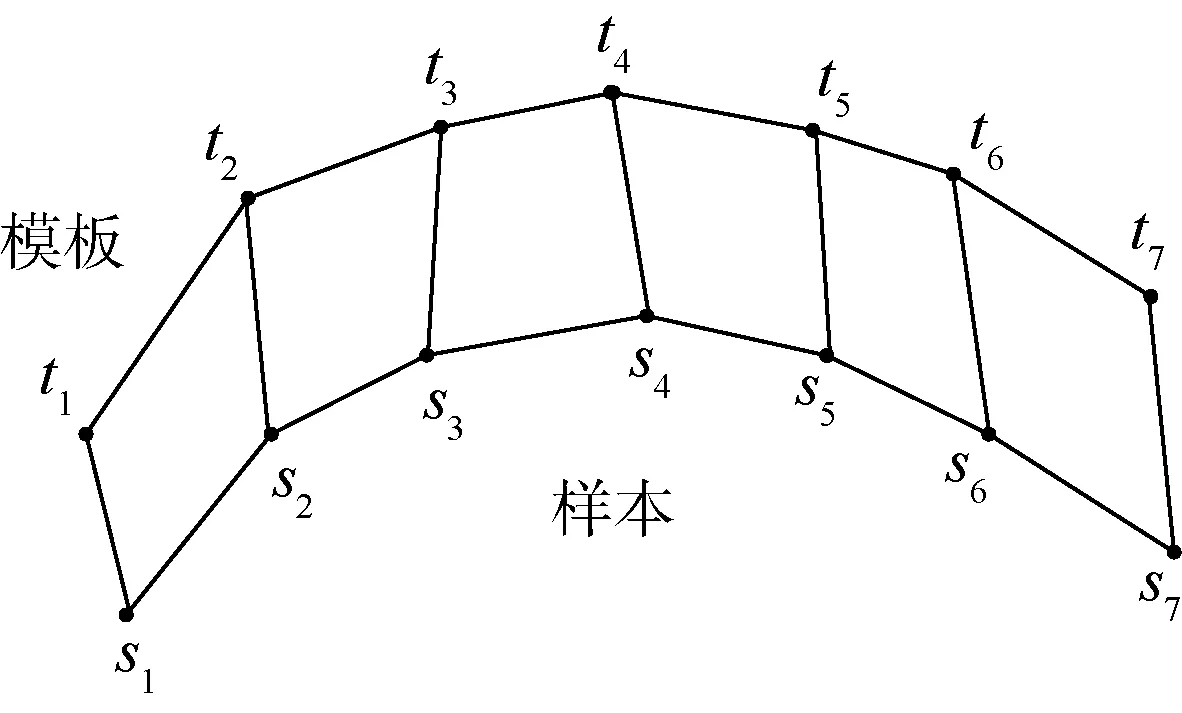
图8 DTW算法示意图Fig.8 Schematic of DTW algorithm
3.2.4 数据增强
LSTM网络作为一种数据驱动的深度学习模型,需要大量的数据进行训练。而对于本文中所研究的问题,无论是在实验中,还是在实际应用中,采集如此大量的数据过于耗时费力,实不可取。为此,本文对预处理后的数据进行数据增强(data augmentation),获得更多的训练数据。
图像处理领域为了增强数据[36],通常会采用给原始图像添加噪声、旋转等方式。在本文中,需要尽量保证动作轨迹的特征,不宜采用给轨迹加噪声的方式。考虑到动作轨迹的时序特性以及LSTM网络的输入特点,通过对原轨迹进行再采样的方式,生成新的轨迹。
现有轨迹数据共9组,每组包括40个轨迹序列,每个序列包含100个时刻,每一时刻的数据有4个维度,即xt=(t,x,y,z)。为适应LSTM模型的输入特点,将处理后的序列长度统一设定为30个时刻,即T=30。以此作为(原始)训练集,并采用如下2种方式来增强训练集的数据。
1) 等距采样:从原轨迹序列的100个时刻中“隔三取一”(下标为小数时圆整),抽取30个时刻的数据,按时间先后顺序排列,组成新的轨迹序列。具体过程如下:
①从序列的下标 (1~97)中等间隔抽30个数并圆整,按抽到的下标,将完整的原轨迹序列分割,得到新的轨迹序列X={x1,x4,x8,…,x97}。
②参照过程①中的操作,对原轨迹序列按下标值(2~98),(3~99),(4~100)做类似处理。
对训练集中的每个轨迹序列都重复上述过程①和②操作。这样,通过等距采样将原训练集的数据增加了4倍。
2) 截断采样:将原轨迹序列按百分比截断,然后等距采样,从中随机不重复地抽取30个时刻,按时间顺序排列,组成新的轨迹。具体过程如下:
①将原轨迹序列按下标值(1~30)截断,得到新的轨迹序列X={x1,x2,x3,…,x30}。
②从序列的下标值(1~40)中等间隔抽30个数并圆整,按抽到的下标,将完整的原轨迹序列分割,得到新的轨迹序列X={x1,x2,x4,…,x40}。
③参照过程②的操作,对原轨迹序列按下标值(1~50),(1~60),…,(1~90)做类似处理。
对训练集中的每个轨迹序列,重复上述过程①~③。这样,通过截断采样的方式将原训练集的数据又扩增了7倍。
采用方式1)和方式2)进行数据增强之后,(新的)训练集共包含9组数据,每组有440个轨迹序列。
3.3 模型训练
实验使用配有Pentium E5800 3.2 GHz CPU的台式机,在Win 7 64位操作系统上,使用Python 3.5.4,基于Google的开源深度学习框架tensorflow 1.4.0,参照2.3节中的网络结构搭建LSTM网络。
如1.3节所述,训练样本是动作轨迹序列与对应终点的组合,其形式为(X,y)。
通过设定学习率、迭代步数等超参数,随机初始化网络的权重和偏置参数,应用Adam优化算法不断更新网络的权重。实验中所设定的相关参数如表1所示。
整个训练过程耗时约9 200 s(约2.5 h),在迭代5 000轮之后,训练损失不再降低,模型收敛。此时,将网络的参数保存下来,用于预测。
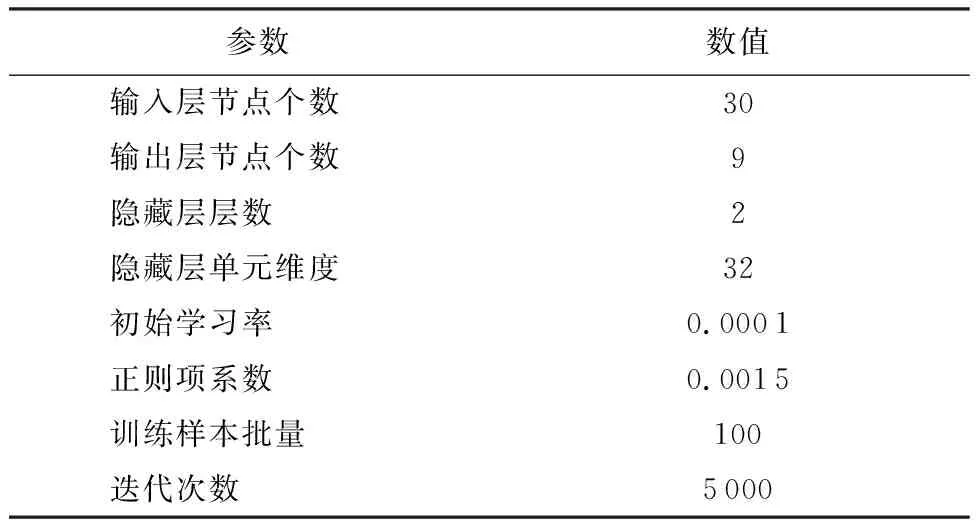
表1 LSTM网络的相关参数Table 1 Related parameters for LSTM network
3.4 实验结果
3.4.1 预测效果
在测试阶段,同样邀请了5名被试人员,站立在实验台前,随机抓取实验台上的9种工具,每人抓取同种工具5次。采集的数据用来做测试。即测试集包含9组轨迹数据,每组包括25个完整的(100个时刻)轨迹序列。
为了模拟在线预测的情形,将测试集的完整轨迹序列按比例(30%,40%,…,90%)截断,以模拟观测到部分动作片段的情形。
然后,从截断后的轨迹序列中等间隔抽30个时刻的数据,按时间的先后顺序组成新的轨迹序列,作为测试数据,输入LSTM网络,预测动作的终点位置。
实验结果表明,在观测到30%的动作片段时,对动作终点位置预测的准确率可以达到67.7%;当观测到60%的动作片段时,预测准确率可以达到87.5%。详情如图9所示。
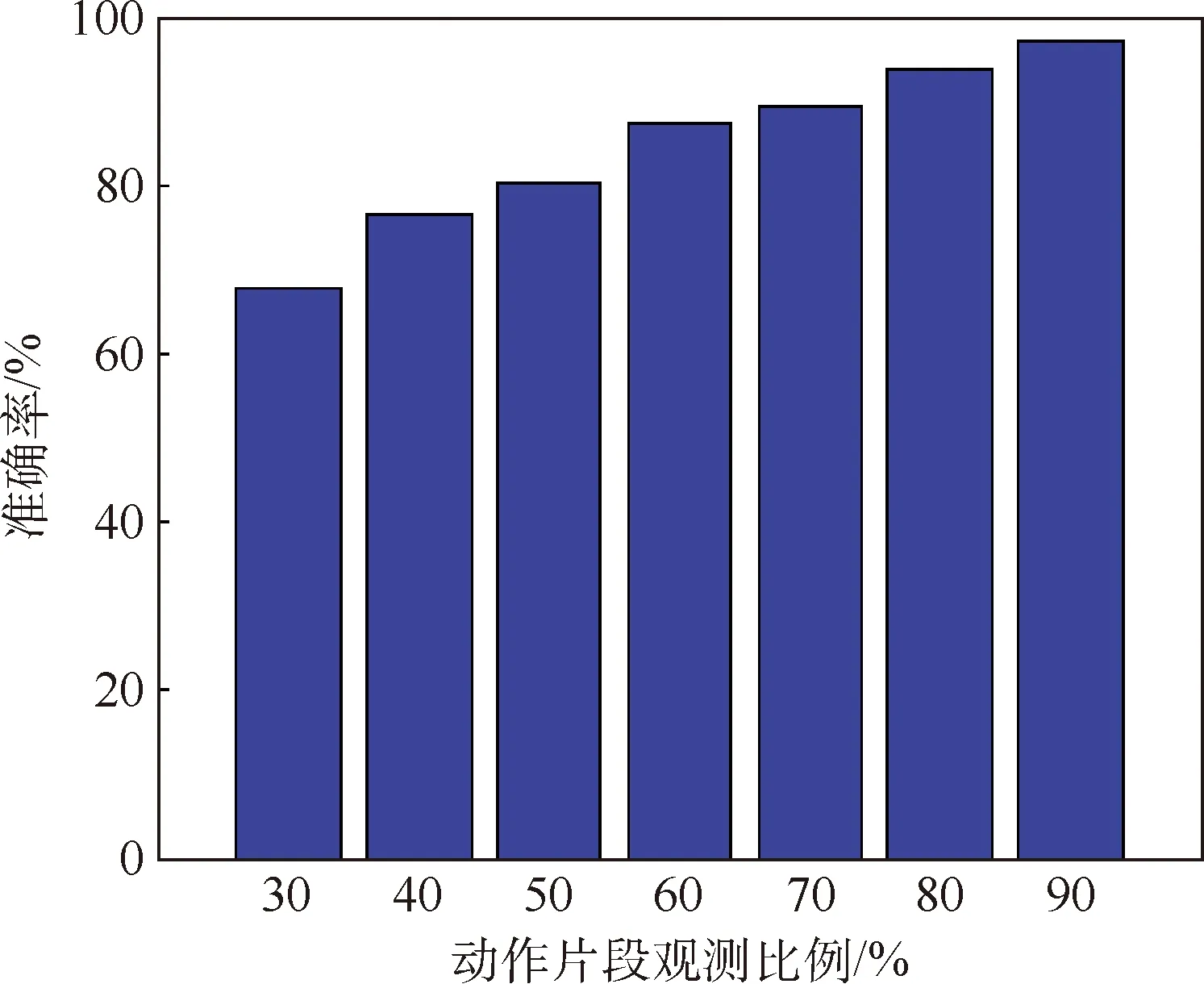
图9 预测效果Fig.9 Prediction results
3.4.2 对比分析
基于实验采集的数据,分别训练GMM和传统的RNN模型并进行测试,预测结果如表2和图10所示。
随机预测(Random),即不进行学习而直接“盲目”预测。根据古典概率模型,共有9种情况,每种情况等可能发生,因此预测结果的准确率即为1/9(11.1%)。该结果明显低于通过各种模型建模后的预测结果,难以为机器人的提前响应提供参考,这说明机器人的学习是有效而且必要的。
在实验中GMM模型使用的是未进行增强的原始数据。原因在于,使用GMM模型时要计算协方差矩阵的逆,而增强后的轨迹与原始轨迹有内在关联,数据间存在线性相关,导致矩阵不可逆,模型无法求解。RNN模型使用的是通过2种增强方式处理后的数据。在较短的观测时间内(动作刚开始),GMM效果比RNN好,但是随着动作的继续进行,GMM因不能捕获动作的时序信息,其预测效果逐渐被赶超,并最终落于下风。
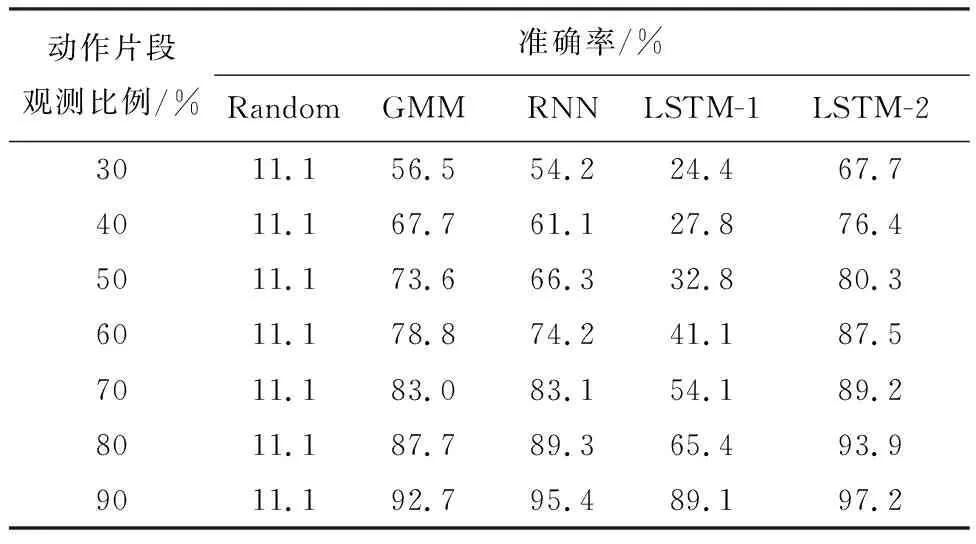
表2 不同模型预测效果统计Table 2 Prediction results statistics among different models
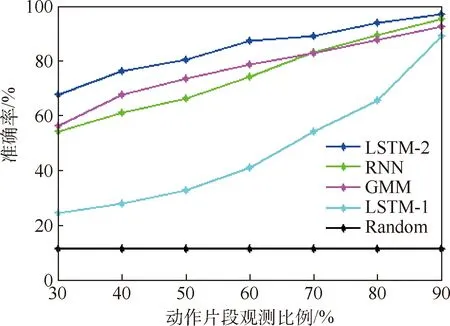
图10 不同模型预测效果对比Fig.10 Comparison of prediction results among different models
LSTM-1代表仅通过“等距采样”(方式1))增强训练数据后,训练LSTM网络并进行预测的结果;LSTM-2代表通过2种方式进行数据增强后,训练LSTM网络并进行预测的结果。在仅采用方式1)进行数据增强后,每组数据有160个序列,模型的预测效果较差;通过2种方式进行数据增强后,每组数据有440个序列,预测结果的准确率得到了很大的提升,说明LSTM网络对数据的依赖性较强。
在整个观测过程中,LSTM模型的预测效果始终优于GMM模型和RNN模型,原因在于,传统RNN模型比LSTM模型的神经元结构简单,而LSTM由于加入了门结构,能够更好地对序列数据进行建模。
4 结 论
1) 研究了在HRC装配的特定场景下,机器人对人的动作终点位置的预测问题。实验结果表明,机器人在学习的基础上,能够根据人体动作的初始部分对动作的终点做出预测。并且,随着观测时间的持续,预测结果的准确率在不断提高。这既证明了本文方法的有效性,也符合人们的直观认知。
2) LSTM网络与GMM及传统RNN等模型相比,在处理序列问题方面确实具有独到的优势。同时,深度学习作为一种数据驱动方法,对训练数据的需求量非常大,而数据采集又常常耗时且费力。本文所使用的数据增强方法,可供在使用深度学习方法解决时间序列等相关问题时借鉴。
3) 通过实验验证了本文方法预测抓取动作的终点位置的有效性。事实上,在HRC装配过程中,人的很多动作都具有与抓取动作相似的性质,如接收、传递、放置动作。通过预测这种伸及动作的终点,能够使机器人更好地配合人的操作,或者是提供辅助,或者是避免妨碍。
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
现代装饰(2018年5期)2018-05-26 09:09:39
小学生作文(低年级适用)(2018年3期)2018-04-17 00:58:35
少年博览·小学低年级(2017年4期)2017-06-09 16:22:28
中国三峡(2017年2期)2017-06-09 08:15:29
作文评点报·低幼版(2017年7期)2017-03-11 20:49:41
少儿科学周刊·少年版(2015年4期)2015-07-07 21:13:44
少儿科学周刊·少年版(2015年4期)2015-07-07 21:09:31
少儿科学周刊·少年版(2015年4期)2015-07-07 21:08:08
