
基于Paxos的强一致性复制在天文数据存储中的应用研究*
2019-01-24 03:48:46刘应波
天文研究与技术 2019年1期
童 彬, 王 锋, 刘应波,2, 张 帆
(1.昆明理工大学云南省计算机技术应用重点实验室,云南昆明 650500;2.云南省科学技术情报研究院,云南昆明 650051)
近几年来,我国天文观测设备的研制取得了较大的进展。以太阳观测为例,1 m新真空太阳望远镜(New Vacuum Solar Telescope,NVST)和光学/近红外太阳爆发探测仪(Optical and Near-Infrared Solar Eruption Tracer,ONSET)望远镜已经相继投入观测。其中,1 m太阳望远镜主要是通过焦面设备采集获取太阳光球和色球的高分辨率图像。图像用天文普适图像传输系统(Flexible Image Transport System,FITS)格式保存。以其中一个焦面设备的CCD(分辨率2 048×2 048)为例,每个像素存储时使用16位编码,则编码后文件大小为8 MB。若要求设备每秒采集10帧,则采集速率为80 MB/s。当4个焦面设备同时采集时,采集数据的峰值可达320 MB/s。按平均日观测时间7.5小时计算,每天观测数据量达到8.24 TB。
为确保这些海量科学观测资源的存储,传统方法采用直接附加存储、网络附加存储或存储区域网络技术,通过廉价磁盘冗余阵列提高数据的安全性,但在实际应用中会受到诸如无法实时扩充空间、存储速度受限于总线、多机共享困难等问题的困扰。近几年,分布式存储系统领域出现了基于廉价硬件分布式存储的系统构架方法,在有效控制成本的前提下可靠地保存超过PB级总量的数据且具有良好的访问性能,为海量天文数据的存储带来了新的思路[1-2]。
在天文观测系统中,采集工作站负责将焦面探测设备(如CCD)生成的数据提交至存储系统。原始观测图像一般先缓存在工作站有限的内存中,编码后再尽快提交至存储系统,以免造成内存的溢出。外挂式存储通常由硬件机制保证数据的安全性,可靠性较高;而组成分布式存储系统的廉价存储节点平均失效率为0.034%[3],数据安全性能和数据恢复手段均比外挂式存储设备复杂。为了弥补存储节点数据安全性的不足,只能通过复制手段把数据拷贝至多个节点中以确保存储数据的安全性,而组成分布式存储系统的硬件并不具有保证所有复制过程无差错的数据复制,因此每当复制操作执行之后还需确认所有拷贝的存储状态。只有当所有参与复制的节点均完成数据持久化存储后才能确保最低的数据丢失概率,进而使得工作站达到确认存储完成并安全释放内存的条件。为满足释放条件,复制操作必须具有确定数据达成一致性的能力。
复制操作过程中数据的多份冗余存储在有效提高数据安全性的同时,不可避免地增加了“确定存储状态”的复杂度。基于以太网构建的分布式存储系统存在消息丢失和复制两种异常,在此条件下容忍分布式存储中的所有错误并达成一致性结果至少需要三轮信息交换。如何在分布式天文数据的存储过程中,在保障观测数据复制成功的同时,能够让复制的数据副本一致是需要重点研究的问题。
1 相关工作
软件复制过程中的一致性相关算法一直以来都是该领域研究的热点和难点。复制算法可分为事务复制、虚同步复制以及状态机复制3种,事务复制方法的普适步骤是先复制,后同步,其同步(一致性达成)的方式选择灵活,可以获得最强的容错能力。
在高容错一致性达成算法方面,文[4-5]的Paxos算法被认为是解决一致性最有效的算法,但实现也有一定困难,因此产生了其他一致性算法,例如Zap,Raft等。这些算法中最核心的Quorum商议理论被认为是当前高容错前提下解决一致问题最通用的方法[6]。围绕Quorum商议方法产生了很多各具特色的改进,例如文[7]在消息延迟数量上减少了一个轮次,文[8]将FastPaxos与ClassicalPaxos用于分布式提交方面,比经典的2PC方法具有更强的容错能力。
常规的复制场景通常追求最小的复制完成时间,例如Isis协议可以实现至少一轮至多三轮消息交换即可完成复制;用于MySQL数据库中日志复制的主从协议则更加简单高效,完全利用传输控制协议的有序特性实现有序单播,保证复制结果的一致。在这些研究中,复制延迟的减少都是以容错性为代价的,上述两种算法对通讯及进程产生异常的种类都有苛刻限制。在实践过程中,天文观测数据存储时对复制完成时间并不敏感,更加重视算法的容错能力与数据安全性。过分注重存储完成时间,弱化提交完成时一致性结果的复制算法并不适用于天文场景。
文[8]提出的一系列基于Quorum商议方法都可以实现高容错,但用于实现强一致性复制或者事务语义有一定前提。要实现分布式环境下的事务,不但需要达成一致性的方法,而且为了保证并发事务执行,必须要对读写操作串行化。而基于Quorum商议的算法需要三轮消息交换与两轮日志持久化才可以通过决议选出一个操作,用于实现串行化将过多地增加事务完成的时间,很难在延迟上达到常规的复制场景的需求,因此不可行。但天文观测数据的特殊性在于存储系统中的FITS文件不允许更改和删除,且任意FITS文件之间两两独立无任何相关性,因此可以避免发生并发写。无须考虑并发串行化的事务仅需对FITS文件持久化的结果达成一致即可,避免了引入有序多播机制的巨大开销。在此种特殊的场景下,事务复制方法变得具有可用性。
2 改进的细粒度数据复制算法
定义1:数据复制原子性,如果整个FITS文件的复制结果只能是“提交”或“回滚(复制失败)”,那么算法就满足原子性。
在观测数据存储的场合下,回滚失败的处理方法不适合FITS文件的实时存储。在传统关系型数据库中,较多写操作在事务提交前仅执行日志操作并改变内存中对应数据,因此可以不考虑事务中已影响的记录数目,一旦事务失败执行回滚即可。但在高速观测数据流复制中执行回滚操作,必将放弃大量已经成功复制的数据块,浪费过多的输入输出资源,严重制约应用,尤其是采用分布式存储的场合。除此之外,回滚操作还将在一个短时间内增加采集工作站内存中缓存的观测数据的总量,一旦数据来不及存储,数据丢失,将影响数据存储的安全性。因此,在保证一致性的前提下恰当减弱事务回滚发生的条件有利于FITS文件的存储,这是能够保障天文数据观测过程中数据存储的有效方案,既保障了一定的存储性能,又提高了数据存储的安全性。
要减少事务回滚的发生概率,需要对原子性的要求作改进,使得异常发生情况下采集服务器(下称客户端)有机会对提交进行补偿。为了处理这种问题,论文改进了数据复制方法,主要思路是借助减少数据提交粒度的方法。
定义2:一个FITS文件被切割成P个数据块:[P1,...,Pn],对应存储状态为[S1,...,Sn],每个状态 S ∈ { ″replicated″, ″unreplicated″}, ″replicated″: 表示数据块i为已复制, 反之为未复制, 当且仅当∀Pi∈[P1,...,Pn],Si=″replicated″,即所有块都达成 “提交”决议时,FITS文件提交成功。
为了说明复制操作的过程,设P值为2,即需要复制2份。参考Paxos算法(文中涉及的投票、编号等术语均来自该算法)[4-5],将复制操作(下称算法)中执行的过程依逻辑划分成5部分,每部分均接收并发送特定消息,这5部分为Client,Proposer,Acceptor,Learner与StorageNode。采集工作站中包含Client与Proposer两个角色,二者只是逻辑上的划分。算法实例的运行最先由这两个角色同时发起。Client发起实际的数据复制操作,向负责数据持久化的StorageNode传输FITS文件;Proposer与3个Acceptor配合发起对存储结果的裁决,之后Acceptor,StorageNode与Learner这3部分之间发生一系列消息传递用于完成FITS数据的复制。图1描述了整个消息传递与日志记录的流程,复制算法详细步骤如下:
步骤0:Client选定复制组[SN0,SN1,SN2],并决定主要拷贝所在的组[SN0,SN1],执行主从复制; 同时向 Leader Proposer提交 BeginCommit([SN0,SN1],[SN0,SN1,SN2])消息;
步骤1a:Leader Proposer收到BeginCommit消息后,按照自己的日志选择一个比所有已发起的投票号都要大的编号,然后向所有的Acceptor发送Prepare(N,[SN0,SN1,SN2])消息,尝试开始编号为N的决议投票;
步骤1b:Acceptor1收到Prepare(N)消息后,如果没有向别的进程承诺过不表决小于N的投票,则向Leader Proposers回复Promise(N,V1)消息,V1表示Acceptor1承诺过的最大投票编号。同时Acceptor0与Acceptor2也执行相同的逻辑;
步骤2a1:Leader Proposer收到半数以上Promise(N,Vx),x∈{0,1,2}的消息后,根据Promise消息中的(V0,V1,V2)值计算Max(V0,V1,V2),如果Leader Proposer处于正常流程,则应满足条件N=Max(V0,V1,V2),此时依据BeginCommit消息中指示的复制组,向所有组内成员发送Prepare(N)消息;
步骤2a2:SN0收到Prepare消息后,在自身的存储中查询主从复制的执行情况,如果已经完成FITS文件的复制,则向所有的Acceptor广播Accept(N,[P0,P1])消息,其中P0=P1=″replicated″。同时SN1与SN2也执行相同的逻辑;
步骤2b:Acceptor1需要依据步骤1a中Prepare消息获得的复制服务器列表,等待每份复制的完成向量SN x.[P0,P1],x∈{0,1,2}。从所有SN节点返回的复制完成向量可以判断复制是否完全完成,但此处不必做判断,只需将生成决议的结果向量r=[SN0.[P0,P1],SN1.[P0,P1],SN2.[P0,P1]],并通过消息Accepted(N,r)发送给Leader Proposer;
步骤3:Leader Proposer接收到半数以上的Acceptor发来的Accepted消息即可认为已经对提交结果达成一致,广播一致结果至所有的SN和Client节点。
至此已达成对提交结果的一致性决策结果[P1,P2]。如果i∈{1,2},Pi=″unsuccessful″,则Client应对复制失败的数据块进行重试。重试的操作等价于重新执行一次复制算法的实例。很多情况下该操作可以代替回滚,但要完全避免回滚发生是不可能的,例如,采集服务器硬件异常发生在FITS文件未完全提交的情况下,必须执行回滚操作代替重试操作。如果不执行回滚则永远不能达成含义为提交成功的一致结果,而且有可能导致存储复制操作陷入循环。
由图1可以看出,算法以Quorum商议①Quorum商议,即大多数协商决策,一般认为在对某个决议的过程中,某决议得到了超过半数的投票,即认为通过。文中因算法上下文需要因此沿用该词。为核心,结合主备复制的优点,保证了高效并发与强一致性。文件复制路径由多主节点的主备复制算法决定,主节点故障时系统的性能损失较小。在一致性达成算法上,步骤1a与步骤1b沿用了Classic Paxos协议的第1轮过程,主要用于保证Quorum商议中的B3约束[5];步骤2a1与步骤2a2之间,设有一个上限时间,用于限制复制完成的时间。这两步加入了复制过程与一致性算法之间的必要交互流程,在保证不破坏Quorum商议中可进展条件的情况下计算FITS分片的持久化状态向量。当然由于Quorum商议方法可以支持完全异步的网络模型,此处用于失效判定的算法选择很多,例如累积失效检测器[9],定长失效检验等方法都是可行的。

图1 无异常情况下复制算法执行路径与一致性达成的过程Fig.1 Replication algorithm execution path and the consistency-reaching produce under no fault condition
3 算法性能分析
研究[10-11]表明,同时加强容错与一致性存在矛盾,更强的一致性约束与复制延迟也存在必然矛盾,复制延迟对访问性能有一定的影响。鉴于上述矛盾,算法设计时最重要的工作是根据具体的应用场景,在容错性、一致性与延迟之间给出最优的平衡[12-13]。
假设将FITS文件切分成两部分,有N个StorageNode进程,并且系统为容忍F个进程失败设立了2F+1个acceptor,在只将Prepare类型的消息发送给F+1(acceptor中的大多)个acceptor的情况下,其日志延迟和消息延迟情况如表1。如果数据的持久化时间、日志持久化的耗时、消息的发送时间均相同,由表1可知消息延迟与日志延迟的总量为7,由于数据持久化过程与一致性达成过程可能并发执行,最终由复制算法造成的延迟倍数在7~8之间(简称为放大系数),即1次复制操作比不使用复制操作带来7~8倍的延迟,但从保障一致性的角度来看,即使不采用基于Quorum商议算法,使用传统经典的2PC方式,虽然能够节省1次日志写入时间,但同样有5~6倍的延迟,因此采用Quorum商议达到一致性的方式具有可行性。
算法在复制数据块时,仅要求采集工作站将数据提交至单台存储节点,并称该节点为主节点,再由主节点执行后续的复制。此种方法称为主备复制,是被动复制方式的一种。相比与其对应的主动复制,被动复制算法在容错性上略弱[14]。
主动复制中,由采集服务器直接传输数据至所有存储节点,就可以避免主备复制中由主节点失败导致的后续问题。假设复制份数为3,每台机器失效的概率均为p,被动复制异常的概率为p3+2p2+p,而主动复制为p3。
为便于讨论,假设发生异常后即回滚。设执行复制所需的一致性开销为C,复制粒度为M,FITS文件的大小为S,回滚产生的IO代价为M/2。
每次复制时,异常可能带来的IO代价为
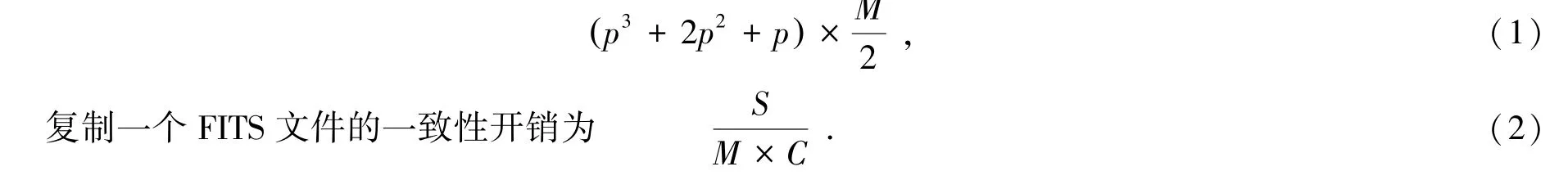
其中,p,C,S均为常数,M与异常可能带来的IO代价成正比,与复制一个FITS文件的一致性开销成反比。通过实验测定失效概率p与一致性开销为C可确定复制粒度M的最优值。
p和C与硬件有直接关系,需要在实际生产环境中测得,因此只能给出测定M的方法,无法给出一个表征M普适的常数。

表1 日志延迟和消息延迟Table 1 Delay caused by Log and Message-Passing
4 实验及讨论
实验服务器集群拓扑结构如图2,该集群由16台搭载单块SATA硬盘和一块千兆网卡的存储服务器充当StorageNode角色,3台同样配置的服务器充当Acceptor角色;1台搭载6块千兆网卡的采集工作站充当Client和Proposer角色,向集群提交随机生成的FITS文件并生成2份拷贝。分块大小取4 MB,并发复制实例为节点数的两倍共32个,复制时间如图3,上方曲线为达成一致性复制的时间,下方曲线为仅传输FITS文件所用的时间,二者比值时延均值在1.67左右,不到1 s,表明在存储FITS文件的时候,可以同时通过引入一致性保障机制,保证分布式实时存储的可行性,即在高速存储和一致性要求之间进行了有效的平衡。
复制算法使得分布式存储系统在获得一致性的同时让访问延迟成为需要关注的性能参数,减少同步延迟可以减少数据在采集工作站中缓存的时间,有利于在采集工作站发生单点故障的时候减少数据丢失的数量。另外,在一致性与延迟的矛盾中,文中算法倾向容错性较强的一致性达成方法,不可避免地增加了复制数据之间的一致性达成时间,也就决定了算法不适合KB级的小数据复制。但针对天文图像数据的普遍大小MB级的情况,综合考虑复制算法能够对错误异常的处理,采用Quorum商议适合天文高速观测数据存储的场景。

图2 实验环境设计Fig.2 Experimental environment

图3 数据复制耗时与数据提交耗时的对比Fig.3 Time elapse comparison of replication operation and the commit operation
理论认为,在不存在欺骗的异步网络模型中能够容忍所有异常的一致性算法最低需要交换3轮消息[10],本文描述的算法也使用了3轮,但是对于复制数据的大小不同,其影响程度不同。在外挂式存储中延迟主要由机械硬盘的硬件性能决定,磁盘调度等算法因素造成的影响较小;但在分布存储过程中,复制算法中的商议过程不但发生了3轮通讯还执行4次(最少可减少到2次)记录日志操作。系统在写入KB为单元的小数据时,同样的数据量需要更多的信息交换,对复制结果的商议过程耗时远远高于机械硬盘存储数据的延迟,从而造成整体访问延迟成倍增加。而FITS文件的典型值处在4 MB以上时,由于复制算法引入的通讯和传输延迟在整体延迟中所占比例减少,硬盘访问速度依旧为延迟的主要因素,通过分析和实验来看,两倍的延迟在可容忍的范围,可以采用访问延迟较低的固态硬盘作为数据复制暂存盘,这样能极大提高性能。
5 结束语
在上述对比实验和理论分析中,本文提出的算法具有如下特点:(1)与主动复制方法相比,降低了采集工作站的IO开销,增加了复制阶段发生错误的概率,即减弱了可用性。(2)与经典的2PC方法相比,增加了一定的延迟,获得了容忍半数节点宕机的能力,即加强了可用性;(3)与直接写入外挂式存储器相比,延迟较高,但放大系数在可接受的范围内。虽然相应的改进增加了延迟,但这些改进更利于安全存储FITS文件,在性能上完全可以满足高速观测数据可靠存储的需要,具有实际应用价值。
猜你喜欢
公民与法治(2022年5期)2022-07-29 00:47:28
华人时刊(2021年13期)2021-11-27 09:19:02
教学考试(高考物理)(2021年5期)2021-11-08 10:31:22
中医眼耳鼻喉杂志(2021年1期)2021-07-22 07:38:14
心声歌刊(2020年4期)2020-09-07 06:37:14
通信产业报(2020年43期)2020-01-15 06:38:43
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
燕山大学学报(2015年4期)2015-12-25 02:19:49
中国卫生(2014年12期)2014-11-12 13:12:26
中国卫生(2014年8期)2014-11-12 13:00:50
