
大数据集群管理系统设计与实现*
2019-01-23 11:49邹大均
通信技术 2019年1期
黄 沾,邹大均
(中国电子科技网络信息安全有限公司,四川 成都 610041)
0 引 言
随着计算机应用的推广和智能设备的广泛普及,人类的日常生活特别是互联网服务所产生的数据量正在快速飙升。全球著名科技咨询机构和IT服务公司EMC在2014年3月份发布的《2020年的数字宇宙》报告称,到2020年,数字宇宙将会膨胀到40 000 EB,也就是说2020年人均数据量将达到5 200 GB以上[1]。由于数据规模的庞大,传统的数据分析与处理工具已经不能满足当前的数据分析需求。如何处理分析这些数据,逐渐成为了一个新领域,“大数据”的概念也应运而生[2]。
目前,越来越多的公司正在运用大数据手段来分析用户的行为、公司的购买力以及增值信息、市场动向等。大数据能力逐渐成为一个企业生存能力的重要组成部分。社会各行各业对大数据技术的需求在不断增长,大数据技术正在快速前进[3]。
当前,Hadoop已经成为大数据技术的代名词。这项受Google GFS和MapReduce启发的项目,已经快速发展成一个完整的大数据软件生态系统。但是,对于整个大数据生态系统来说,将它很好地运用融合到自己的研究领域并非易事。首先,大数据组件很多都是开源系统,相对专业,非技术人员部署和配置无从下手。其次,在部署大数据组件前需要搭建基本的操作系统环境和一些基础运行环境,如网络配置、ssh、jdk等。仅仅把整个集群部署启动要花费大量成本和精力。而除了部署之外,集群中主机以及组件的管理也是繁琐而又常见的工作,如新增主机、下线主机、组件参数调整等。为了解决这些问题,Ambari项目诞生,以便解决大数据组件的管理问题。Ambari项目作为Hadoop官方认可的生态系统的一部分,随着其越来越完善,可以认为Ambari已经解决了组件管理问题。但是,Ambari并非该问题的完美答案,主要缺乏如下的主机管理功能。
(1)电源管理:电源管理可以随时对主机执行开机和关机操作,是集群管理中的一个基本功能。
(2)操作系统部署:Ambari需要已经部署操作系统,所以管理系统必须提供便捷的部署操作系统的方法。
(3)网络管理:hadoop组件要求集群之间都通过域名访问,所以管理系统必须有网络管理的功能。
(4)SSH访问:Ambari要求所有主机都能通过公钥访问,管理系统需要自动部署好。
(5)Ambari安装源:Ambari组件安装源非常庞大(超过8 GB),管理系统需要准备好离线安装环境,同时要为每台主机导入Ambari安装源的签名公钥,以便正确安装Ambari及其组件。
因此,笔者设计并实现了一个融合主机管理与组件管理的大数据集群管理系统。下面将从设计目标、方案、实现三个方面分别进行描述。
1 大数据集群管理系统设计目标
本系统的设计目标是一个覆盖大数据集群全生命周期管理的系统,具有自动化部署,使用便捷,可以兼容大多数主机类型等特性。
(1)自动化:除了必要的信息输入流程外,所有部署流程全部自动化。
(2)一致性:保证集群内系统配置和大数据组件配置一致,同时可以保证同样的集群配置数据可以重复部署。
(3)兼容性:可以部署在满足电源管理需求的各类主机或机架式设备、vmware虚拟主机以及各种云上的主机。
(4)全生命周期管理:不仅负责初始化安装部署,而且集群建立后所有主机和大数据组件都可以进行管理,如增加或删除主机、主机下线上线等操作。
(5)离线部署:所有需要的组件都已包含在安装介质中,在不能连接互联网的特殊网络环境中也可以使用。
(6)便捷管理:提供WEB/CLI客户端供管理员使用。
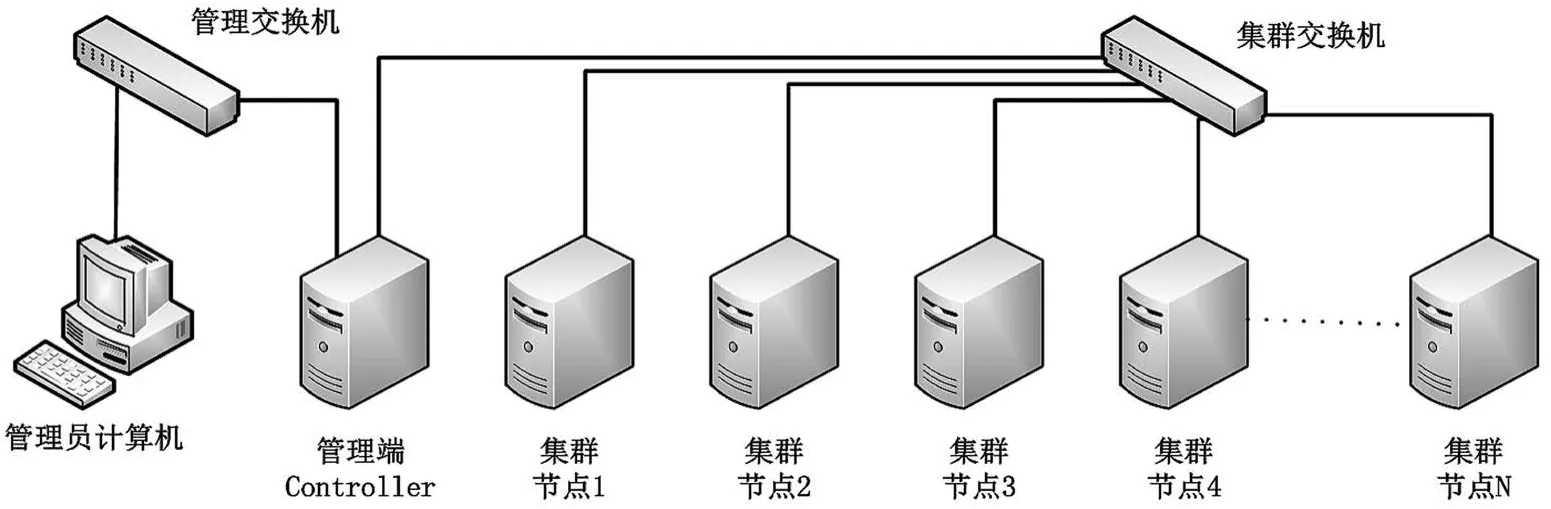
图1 网络拓扑
2 大数据集群管理系统设计方案
2.1 概述
本方案中集群管理系统放置在集群管理服务器主机上,与集群内主机直接互通,拓扑如图1所示。
从用户的角度看,集群管理服务器(或controller)提供集群管理的各种功能和必备服务,同时对集群管理客户端(WEB/CLI)提供基于HTTP的API。管理员通过客户端访问controller,controller通过网络连接下发相应的管理命令,同时也接受集群主机状态上报请求。
为了提供操作系统部署的功能,controller需要运行dhcp、tftp、nfs服务供集群主机网络启动。datasource服务供主机cloud-init正确初始化主机和安装操作系统。为了给集群提供域名服务,controller也需要运行域名解析服务。Ambari服务器和安装源也运行在controller。
2.2 集群初始化流程
集群初始化部署开始前,需要完成一些准备工作,如集群规划(确定集群域名、网络配置、角色划分等)、硬件检查(主要是否支持电源管理)等,然后按照如下步骤进行部署:
(1)通过安装介质将包含管理系统的操作系统安装到controller;
(2)通过客户端访问controller;
(3)进行网络初始化设置,包括域名、IP地址段等信息;
(4)增加集群主机信息,包括IPMI信息、主机名、地址等;
(5)初始化集群,选择主机身份与启用的服务;
(6)集群开始自动部署。
2.3 集群管理
集群完成初次部署后,系统提供主机管理与组件管理两大功能。
主机管理方面,系统提供如下功能:
(1)电源管理,实现主机开机与关机功能;
(2)上线下线,当主机因为各种原因(如硬件损坏)不能正常工作时,可以通过下线功能进行维护,并尽量减少该主机运行的组件影响;
(3)主机配置,更改主机名、网络配置等。组件管理方面,系统提供如下功能:
(1)新增删除组件,可以新增或者删除组件,如hive、pig、spark等;
(2)启动停止组件;
(3)组件配置修改,针对每个组件有不同的配置可供修改,如hdfs修改存储的冗余数,yarn可以修改container的资源占用等。
3 大数据集群管理系统的实现
为了实现上述系统,需要整合多个现有技术。下面从关键技术及其用法出发,讲述功能实现的方法。
3.1 关键技术
3.1.1 电源管理
电源管理是主机管理的基础,不同类型的主机支持不同类型的电源管理方案,如主流服务器都支持IPMI方案,而像VMware的虚拟主机和Amazon等公有云都有自己的解决方案。为了支持不同类型的方案,系统做了一个可扩展的电源管理,功能有查询电源状态、开机、关机与调整启动顺序。下面以IPMI和VMware方案举例说明。
(1)IPMI
IPMI是智能型平台管理接口(Intelligent Platform Management Interface)的缩写,是管理基于Intel结构的企业系统中使用的外围设备采用的一种工业标准。该标准由英特尔、惠普、NEC、美国戴尔电脑和SuperMicro等公司制定。用户可以利用IPMI监视服务器的物理健康特征,如温度、电压、风扇工作状态、电源状态等[4]。对IPMI服务器的管理可以通过ipmitool工具包完成,如(<>内为用户输入参数):
开机:ipmitool-I lanplus-H<bmc_address>-U<user>-P<password>chassis power on
关机:ipmitool-I lanplus-H<bmc_address>-U<user>-P<password>chassis power off
查询电源状态:ipmitool-I lanplus-H <bmc_address>-U<user>-P<password>chassis power off
设置网络启动优先:ipmitool-I lanplus-H<bmc_address>-U<user>-P<password>chassis bootdev pxe options=persistent
(2)VMware
VMware旗下的桌面级产品(workstation)和datacenter产品(vShpere)都支持通过vShpere SDK来远程管理。Pyvmomi模块是该SDK的Python绑定,可以在python中方便调用,如(<>内为用户输入参数):
from pyVim import connect
from tools import task
SI=connect.SmartConnect(host=<HOST>,user=<user>,pwd=<password>,port=<port>)
VM=SI.content.searchIndex.FindByDnsName(None,<name>,True)
print VM.runtime.powerState#查询电源状态
TASK=VM.PowerOn()#开机
TASK=VM.PowerOff()#关机
tasks.wait_for_tasks(SI,[TASK])
3.1.2 网络启动PXE
PXE(Preboot Execute Environment,预启动执行环境)是由Intel公司开发的最新技术,工作于Client/Server的网络模式,支持工作站通过网络从远端服务器下载映像,并由此支持通过网络启动操作系统。启动过程中,终端要求服务器分配IP地址,再用TFTP(Trivial File Transfer Protocol)或MTFTP(Multicast Trivial File Transfer Protocol)协议下载一个启动软件包到本机内存中,由这个启动软件包完成终端(客户端)基本软件设置,从而引导预先安装在服务器中的终端操作系统[5]。PXE可以引导多种操作系统。目前,几乎所有主机都内置了PXE启动功能。
PXE启动需要controller开启DHCP服务和TFTP服务。集群主机需要设置为网络优先启动,以避免主机已有操作系统,而导致与管理系统中主机状态不一致的问题。所以,必须动态提供TFTP服务器上的文件,当主机还没有成功部署操作系统时,TFTP服务器提供PXE需要的内核和文件系统。当主机已经成功部署时,则直接返回失败。主机PXE启动失败后,会自动从已安装的系统引导。
3.1.3 NFS
从网络安装操作系统除了需要PXE启动提供的内核和initrd外,还需要提供一个完整功能的文件系统,这可以通过NFS实现。在controller端开启NFS,在PXE内核启动参数后添加NFS参数,主机即可以NFS为根文件系统运行。
3.1.4 Cloud-init
当主机从PXE启动后,根据主机的状态,需要完成相应的任务,如检测主机硬件信息、安装操作系统等,这时需要借助cloud-init。顾名思义,cloud-init是为了完成云上主机的初始化工作而开发的,已经成为虚拟机元数据管理和OS系统配置初始化的事实标准。最早,cloud-init由ubuntu的母公司Canonical开发,主要思想是当用户首次创建虚拟机时,将前台设置的主机名、密码或者秘钥等存入元数据的服务器。这些元数据在cloud-init中被称为userdata,而提供数据的来源为datasource。Controller会建立一个datasource的http服务器,Cloud-init在启动过程中访问datasource获取userdata。根据userdata的信息,将网络配置(主机名、域名、域名服务器、IP地址以及网关)等信息设置完成,然后写入ssh公钥。
3.1.5 Curtin
Curtin是由Canonical开发的快速、自动安装操作系统的工具。Curtin除了能通过配置文件描述如何进行磁盘划分、网络配置以及需要安装的软件包以外,还支持hook功能,可以在安装过程中执行需要的脚本,如将Ambari安装源的key获取并导入。
3.1.6 Ambari
本系统中,所有大数据组件的管理工作实际都由Ambari完成,系统仅负责调用Ambari提供的restful API来完成实际的工作。
3.2 主机管理
主机管理的核心是主机状态管理。任意主机处于下列状态之一:
(1)新建(NEW):管理员添加主机信息至主机数据库,并有完善的电源管理信息。系统可以自由控制主机的电源状态。
(2)就绪(READY):已探测出基本的硬件信息,如磁盘数量以及容量、网卡数量等。在此可以更改磁盘分区、地址等配置。READY状态的主机也可以再次执行探测硬件信息的操作,适用于主机硬件有更新的情况。
(3)已部署(DEPLOYED):操作系统已经正常安装,网络和基础运行环境已正常运行。Ambari agent端已正常安装并接受controller管理,此时该主机可以进行大数据组件的配置与管理。
(4)下线(OFFLINE):主机下线,如果该主机有某个服务运行,那么该主机会退出该组件服务。
这些状态的转换如图2所示。
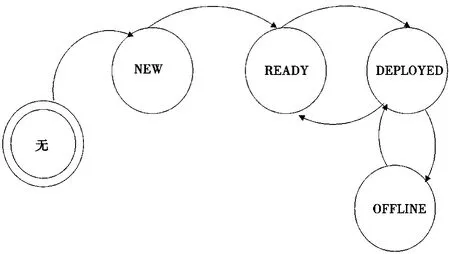
图2 主机状态转换
状态转换的具体流程如下。
(1)无→NEW:将主机纳入管理系统。主机信息分为两部分,一是基本主机信息,包含主机名和MAC地址(用以分辨各个主机),二是主机电源管理信息。电源管理信息必须管理员手动输入,而主机基本信息可以手动输入,也可以从自动保存的备用主机信息库选取,减轻了管理员部分工作。当新的主机通过PXE启动后,在cloud-init运行时请求datasource,controller会发现没有该主机信息,然后将该主机信息加入备用主机信息库。主机发现没有自身状态信息就会自动关机。
(2)NEW→READY:系统会主动开启主机,主机从PXE启动后,在cloud-init处会执行探测硬件信息。探测的信息包括CPU的型号、内存等,最重要的是磁盘和网卡信息。探测完成后,主机会自动关机。管理员可以在这里编辑磁盘分区、网络配置等。此时,主机已经做好安装操作系统的所有准备。
(3)READY→DEPLOYED:主机在网络启动后,cloud-init调用Curtin完成操作系统的安装与配置。Curtin会chroot至新系统中,完成网络配置文件写入、SSH公钥写入、Ambari安装key导入以及安装基础运行环境(Python,JRE)。Cloud-init在curtin成功完成后会通知controller更改主机状态为DEPLOYED,从而完成整个操作系统的安装过程。
(4)DEPLOYED→OFFLINE:标记主机下线后组件管理会将该主机从集群中暂时去除。
(5)OFFLINE→DEPLOYED:标记主机上线后,集群组件将重新激活。
(6)DEPLOYED→READY:已部署的机器可以退回至READY状态,这需要将主机退出集群,清除磁盘数据。
(7)任意→无:删除主机,该主机不再接受系统管理。如果主机上有任意运行的组件,需要退出组件,卸载组件。同时,管理员可以确定是否需要格式化硬盘,以便清除数据。
3.3 组件管理
组件管理是通过调用Ambari导出的API实现的。下面通过curl工具示例获取某个主机安装的组件列表(其中,Cluster是集群id,HostName是主机id):
curl-uadmin∶admin-H’X-Requested-By∶ambari’-s-XGEThttp∶//localhost∶8080/api/v1/clusters/$Cluster/hosts/$Host?fields=host_components
一般组件管理功能Ambari都有对应的API处理,有两个功能需要特别注意。
(1)Ambari代理安装。为了接受Ambari服务端的管理,所有集群内主机都需要安装Ambari代理。这需要调用Ambari的bootstrap API来实现。而bootstrap的实现依赖于集群主机SSH的公钥访问。在调用bootstrap时,需要在输入信息中传入可以访问集群主机的SSH私钥,然后通过不断查询安装请求状态,即可知道代理是否成功安装。
(2)集群初始化,集群初始化需要分为两个步骤。第一,需要搜集集群的初始化配置信息。第二,将集群配置信息转换为json格式,调用Ambari的blueprint API来完成集群的初始化。搜集初始化配置信息,主要是确定哪些主机加入集群、运行哪些组件以及每个组件的参数。比如,HDFS需要确定name server、standby以及data node分别由哪些主机担任。
4 结 语
本文提出的大数据集群管理系统解决了在现有系统中存在的各种弊端,为集群管理提供了一个有效的解决方案。同时,该系统还有很多需要改进的地方,如支持更多的组件、更多类型的主机等,这将是下一步的研究内容。
猜你喜欢
能源工程(2022年2期)2022-05-23
无线互联科技(2020年10期)2020-08-14
装备制造技术(2019年12期)2019-12-25
军事运筹与系统工程(2019年4期)2019-09-11
海峡姐妹(2019年6期)2019-06-26
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
农家科技中旬版(2016年1期)2016-03-03
现代企业(2015年4期)2015-02-28
