
基于主题网络的伪主题分析
2019-01-22 03:32高光来
中文信息学报 2018年12期
闫 蓉,高光来
(1. 内蒙古大学 计算机学院,内蒙古 呼和浩特 010021;2. 内蒙古自治区蒙古文信息处理技术重点实验室,内蒙古 呼和浩特 010021)
0 引言
概率主题模型,如LDA(latent dirichlet allocation)[1]和PLSA(probabilistic latent semantic analysis)[2]为用户在海量信息中筛选和挖掘有效信息发挥了重要作用[3]。目前,已经有很多工作致力于构建新的主题模型和改进算法来捕获主题结构[4-6]及实现主题模型的可视化[7-9]。该类文本主题分析技术多数为利用统计方法实现文本主题获取,通常考虑词频较大的词项对于文本内容的贡献。核心假设是利用文本集中包含特定数目的潜在主题变量,来构建文本语义描述空间。这些数目的潜在主题变量在表达文本集固有抽象的同时,也利用多个不同主题变量抽象地表示文本的不同语义, 实现了文本
间的区别。但这种方法由于受到其概率主题建模机理的限制,文本主题分析结果并不理想。原因有三点: 第一,利用统计方法获取这些潜在主题变量的同时,假设各潜在主题变量之间是相互独立的。尽管各潜在主题变量之间有结构,但潜在主题变量内部描述却无结构、无联系。而实际情况是,各潜在主题变量在表达文本时,它们之间并不是孤立的。同一词项会同时出现在多个不同潜在主题变量中,使得利用潜在主题变量实现文本内容表达效用降低。第二,文本主题建模所抽象表达的语义,是通过描述各潜在主题变量中排名靠前的那部分词项的分布来实现,但这些词项间并无明显关联关系,故人工界定主题解释非常困难。第三,各文本语义由于被“强制”利用特定数目的潜在主题变 量表达, 因“强制主
题”问题(forced topic problem)[10],可能会造成对不同文本的主题表达结果一致,无法有效辨识文本语义。尤其是对短文本的主题分析,会影响到与之相关的诸多文本处理任务。如,文本检索和文本分类等。
到目前为止,有诸多研究工作都致力于改善这种状况。其中值得关注的是,在过去的几十年间,大量的数据分析表明“无标度”特性广泛存在于各种网络中。近年来,学术界对语言的社会网络分析有较多成果[11-13],使得我们可以实现文本的复杂网络结构表达。并利用现有社会网络分析技术对其进行分析和研究,重新审视和实现文本理解。
本文致力于结合主题内部语义耦合关系与网络拓扑结构分析,识别和解释文本主题语义,梳理和获取更加细化的主题分析结果,提出一种基于主题网络的伪主题分析方法(pseudo topic analysis, PTA)。通过构造文本主题网络图,旨在通过对各主题网络的社区内部结构分析和解释,获取描述各主题词项之间更加细化的语义关联关系。调整主题网络中各词项重要度,凸显描述主题语义的词项,实现丰富和补充主题内容表达,有助于更好地解释主题表达内涵。
1 相关工作
复杂网络显著的动力学特征之一就是具有社区结构[14]。即社区内各节点连接紧密,但两个社区之间节点连接稀疏。知晓复杂网络社区结构,对更准确地理解并分析复杂系统的拓扑结构及动力学特性起着重要的作用。关于复杂网络社区结构的研究主要包括两种: 社区结构及关联关系的研究和社区结构识别的研究。
关于文本网络的社区结构研究,大体包括与文本处理相关具体任务实现和文本主题内容分析两种。其中,相关任务实现包括词义消歧[15]、文本分类[16]和信息推荐[17]等。文本的主题内容分析主要集中对文本主题识别研究[9,18-22]。Smith等[9]通过获取主题内各词项间关联关系构建各主题内部词项间的网络关系图和主题间的网络关系图。但该文所构建的词项间的网络关系图仅考虑了主题内部各词项间的局部关联关系,并未充分考虑各词项在文本数据集中的全局关联关系。Zhou等[18]利用社会网络社区发现方法,提出一种自动文本主题生成方法HLSM。Lancichinetti等[19]利用社区发现方法,优化概率主题建模结果。Arruda等[20]提出新的文本社会网络表示方法,同时兼顾文本内容和主题结构,获取词项间的语义关联关系。Akimushkin 等[21]研究了文本中不同部分的词共现网络的拓扑演化。Chen等[22]利用社区识别算法实现文本主题发现,其工作本质上构建的是一种基于知识源的主题网络图,通过模块度计算划分社区获取主题分布,并利用各主题节点的紧度值评估其对于文本内容贡献的重要程度。
但是,这些方法并没有从主题内部各词项间所具备的潜在语义耦合关系与网络拓扑结构相结合,实现对文本各主题的理解。从某种角度而言,其分析结果仍是一种粒度较粗的文本语义分析。但事实是,出现在不同主题中的相同词项对于主题内容贡献程度不同。其不同的语义贡献程度不仅仅体现在词项-主题概率分布中的概率值大小的差异,还在于词项间语义关联关系的强度程度不同所体现的语义表达不一致。
近几年,付京成等[23-24]的研究致力于通过研究社区内部结构,从而获取更加合理的网络中各节点在社区结构中的作用。即,在社区结果内部识别两种不同的社区组织结构。分别为领导者社区和自组织社区。其中,在领导者社区内部存在一个或者多个具有较大度数的节点,其地位要高于自组织社区中各节点。各领导节点不仅连接了社区中其余节点,还保证了社区的稠密和维护社区之间的通信,体现的是网络拓扑结构中的中心性原则。自组织社区内各节点度数基本一致,各节点在社区中的地位等同,体现的是网络拓扑结构中的自组织性原则。
综上,我们可在文本主题建模的复杂网络结构中,通过社区划分识别其内部的领导社区和自组织社区,实现从复杂网络社区内部结构,来审视主题变量在抽象表达文本语义过程中的生成机制。从而,细化明确各主题变量所隐含的内部语义。这将有助于文本的主题语义分析,减少“强制主题”问题对文本分析影响,获取更加精细的文本间语义相似度。
2 基于主题网络的伪主题分析
基于主题网络伪主题的分析过程,本质上是在各主题的网络拓扑结构中,分析和识别其隐含的社区结构。并将表达主题内涵的词项通过社区内部结构分析,实现主题内部语义耦合关系与网络拓扑结构相结合,获取新的主题特征来描述原主题分析结果。即不断地修正主题网络中各词项节点的重要程度及词项节点对之间的关联程度,将其作为新的主题分析结果。图1为伪主题分析获取构架图。

图1 伪主题分析获取构架图
2.1 主题网络图的构建
本文采用标准的LDA对文本数据集进行主题建模。设文本数据集D有K个主题T={T1,T2,…,TK},即有K个主题网络图,表示为G={G1,G2,…,GK}。其中,每一个主题网络可以表示为无向图Gi=(Vi,Ei),i∈[1,K]。每个主题网络的节点集,表示为V={v1,v2,…,vn},节点总数记为n=|V|,节点v的度记为kv;每个网络的边集E中每条边ei,j对应V集中节点对(vi,vj)之间的连接关系,边总数记为m=|E|。图2为构建的主题网络图。

图2 构建的主题网络图
其中,在每个主题网络图中,各节点是描述该主题的各词项节点,各节点的权重体现的是该词项节点描述主题内容的重要程度。节点对之间的连边权重体现各词项在描述主题语义时,所体现的语义关联关系。具体的定义如下所述。
2.1.1 节点的权重定义
本文把数据集主题建模后,将描述各主题排名靠前的n个词项作为各主题网络图的n个词项节点。节点的权重即为该节点在主题网络中的重要度。实质上,本文的伪主题分析就是从各主题网络中,抽取出更能抽象表达各主题内容的节点描述特征,并利用这些新的描述特征来构造数据集的伪主题分析结果。这就要求这些新的描述特征,不仅能够抽象各词项节点在各个主题网络中的重要程度,同时也要增加不同主题网络之间的区别。基于以上原则,将主题网络Gi中各节点的权重定义为式(1)。
其中,N(vj)表示节点vj邻接节点的集合,φi,vj表示在主题i(即主题网络Gi)中第j个词项vj的概率值,kvj表示节点vj的度数。w(v,w)表示节点对(v,w)之间的边权重。
2.1.2 边及边权重定义
判断每个主题网络中每个词项节点对之间是否存在连边,可以通过计算该节点对之间是否存在某种语义联系来获取。本文将利用工具Word2Vec[注]http://code.google.com/p/word2vec,将每个词项节点用词向量来抽象表示,通过计算两个词项节点向量之间的相似度值的大小,判断该节点对之间是否存在连边。若节点对相似度大于0,则该节点对存在连边。反之,该节点对不存在连边。
为了能够更加准确地度量描述主题的各词项节点对的关联强度,需要对主题网络中节点连边的权重进行定义。通常,各种不同类型的复杂网络中边权重往往具有一定的实际意义,有助于社区的识别。因此,本文在定义主题网络图中节点连边权重的时候,不仅要考虑网络的拓扑结构,还要考虑节点之间连边的实际意义。这里,我们的工作主要是想通过对主题的网络结构描述,实现从网络结构角度描述文本特征,弥补统计方法对文本语义结构刻画的不足。因此,在主题网络的边权重定义时,要从整个数据集层面来考虑。本文的边权重定义如式(2)所示。
其中,
其中,|E(G)|表示图G的边总数。sim_con和sim_word分别表示节点对之间的网络拓扑结相似度和词向量相似度。N(v)∩N(w)表示节点v和节点w的公共邻接节点集合。
2.2 主题网络图社区结构分析
描述主题的各词项,在共同抽象地表达主题语义时,对主题语义的贡献程度是不一样的。首先,体现在词项—主题概率分布中的概率值大小的不同。通常,概率值较大的词项认为贡献程度较大。另外,还体现在这些词项间语义关联关系的强度不同所体现的语义表达的不一致。通常,主题所表达语义是由其中少数词项通过协调和语义关联其他词项实现的,且其所表达语义描述较强。同时,其他词项对这部分词项所表达语义起补充作用,且彼此间关联关系较弱。这些均为主题内部的耦合关系。
传统基于统计的概率主题建模方法,由于受其建模机理限制,无法获取主题内部耦合关系。值得注意的是,这种耦合关系与社区内部结构非常相似。我们可以利用社区内部结构分析方法应用到主题网络内部耦合关系的获取。其中,社区内部结构分为领导者社区和自组织社区[23-24]。在领导者社区内部存在少数几个领导节点高度关联其余节点。同时,其余节点必须通过这几个少数节点的支配才能相互联系。在自组织社区内部各点,不存在任意节点具有支配其他节点的功能,且社区内部各节点地位等同。
在付京成等2017年的工作中,通过计算社区内各节点度数的方差,与相同节点数的随机零模型的节点度数的方差比值作为社区划分依据[24]。但在实际的网络中,节点属性描述特征不仅包括节点度数,还包括具体网络中节点的实际含义,即节点点强度。在本文所描述的主题网络中,网络中各节点点强度即为其描述主题内涵的强度大小。所以,我们对划分依据进行了部分调整,如式(6)所示。
其中,VARreal和VARrand分别表示主题网络中社区的节点度数及点强度的方差和对应随机社区的节点度数及点强度的方差。随机社区节点的点强度就是节点的点度数。这里,我们采用和文献[24]相同的阈值标准,将1作为阈值。当ρ>1时,识别为领导者社区;当ρ<1时,识别为自组织社区;当ρ=1时,既不是领导者社区也不是自组织社区。
除此之外,在实际的主题建模过程中,一定会有一部分词项同时出现在多个不同主题描述中的情况发生。即有部分词项节点在社区识别过程中,会出现在多个不同社区中,存在重叠社区现象。通常,处于重叠社区的那些节点,对完成网络间语义信息流动和不同网络间意义的关联起到关键作用。所以,在实际的主题网络社区识别结果中,对于处理重叠社区的那部分词项节点,本文将适当增加其节点属性重要度。
2.3 新的主题特征的获取
在整个伪主题分析获取构架中,最关键的部分就是识别主题网络中最能体现主题语义内涵的词项节点信息。直观地讲,重要程度大且能够最大语义关联其他节点的那些节点,是最有可能体现主题语义内涵的。这与社区内部结构中的领导者节点特点是一致的。本文将各主题网络图结构中,处于领导者社区且权重较大的节点,作为体现主题语义内容新的主题词项特征集。
3 实验与结果分析
3.1 实验数据
本文将对中、英两种不同语料进行实验。其中,中文采用NTCIR8[注]http://research.nii.ac.jp/ntcir/index-en.html提供的新华社简体中文四年的
新闻语料XINHUA(2002~2005年),包括 308 845 个文档,涉及多种主题新闻语料。英文采用MEDLINE[注]http://medline.cos.com提供的五年的医疗文档语料OHSUMED(1987~1991年),包括 348 566 个文档,涵盖270种医学杂志发表的医疗文献。表1列出了中、英两个不同数据集的基本情况。
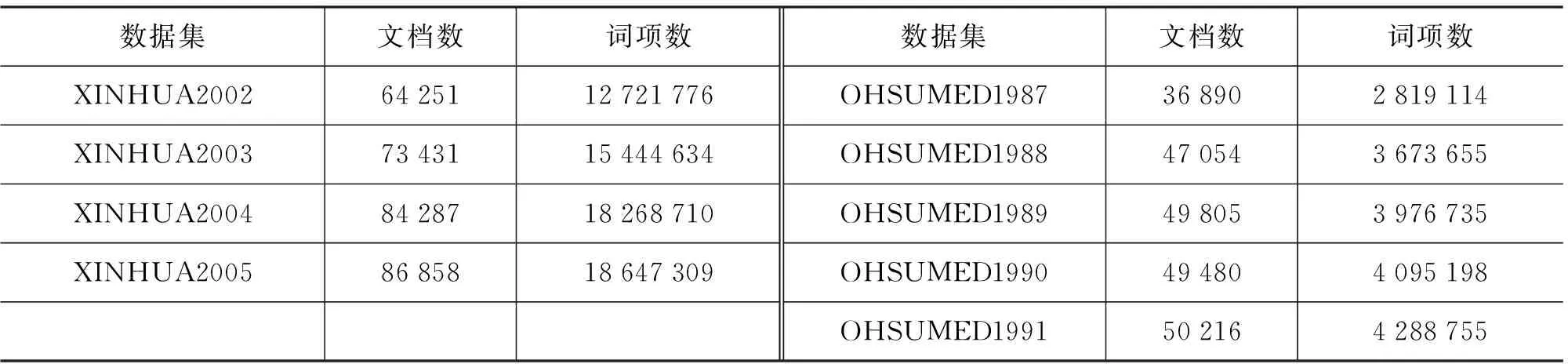
表1 实验数据集描述
3.2 社区划分方法及评价指标
本文采用基于模块度最大化最好的社区划分算法之一BGLL算法[25]作为主题网络社区划分方法。
由于本文所构建的主题网络是无社区划分标签,所以评价标准采用模块性EQ[26]来度量社区发现质量。
设社区划分结果为C={C1,C2,…,CM},EQ值的计算如式(7)所示。

其中,M为社区划分数,Ov表示在最终社区划分结果中节点v属于的社区数,A是原始网络的邻接矩阵,m是社区划分前原始网络的总边数。
3.3 主题获取
本文采用开源的JGibbLDA[注]http://sourceforge.net/progjects/jgibblda/工具实现对文本数据集的主题建模。设置初始主题数目K=10,超参数设定α=50/K、β=0.01;Gibbs采样的估计迭代次数设定为100次,返回主题描述词项个数word_number=20。主题数目依次取K=10、20,直至100,分别对数据集进行主题建模。为了降低少数低频词对文本建模结果的影响,实验预先去除了数据集中词频低于5的部分词项。其中包含XINHUA中130 363个词项和OHSUMED中77 322个词项。本文利用困惑度Perplexity[6]度量建立的主题模型的生成性能,取困惑度取值最低值对应的主题数目作为数据集的最佳主题数目K。
模型困惑度值采用式(8)计算:
其中,Rtest表示有J个文档的测试集,Nj表示第j篇文档dj包含的词项数;P(dj)表示模型产生文档dj的概率。由图3所示中、 英数据集Perplexity值变化曲线,可知中、英文数据集最佳主题数目分别为60和70。
3.4 实验结果和分析
表2为中、 英两种不同文本数据集原始的主题分析结果(top-20)和经过伪主题分析的样例结果比较。图4为相应样例的伪主题图结果描述。
从表2和图4的结果可以看出,对各主题网络的伪主题分析结果不仅可以更加体现主题表达内涵,还进一步体现了这些词项间的关联关系。
图5为中英数据集各主题网络图模块性结果。
从图5结果来看,本文所提方法对各主题网络模块性整体表现良好。图5中存在个别主题的模块性值较低,分析其主要原因是由于该主题描述中组成词项关联关系缺乏影响社区划分结果。
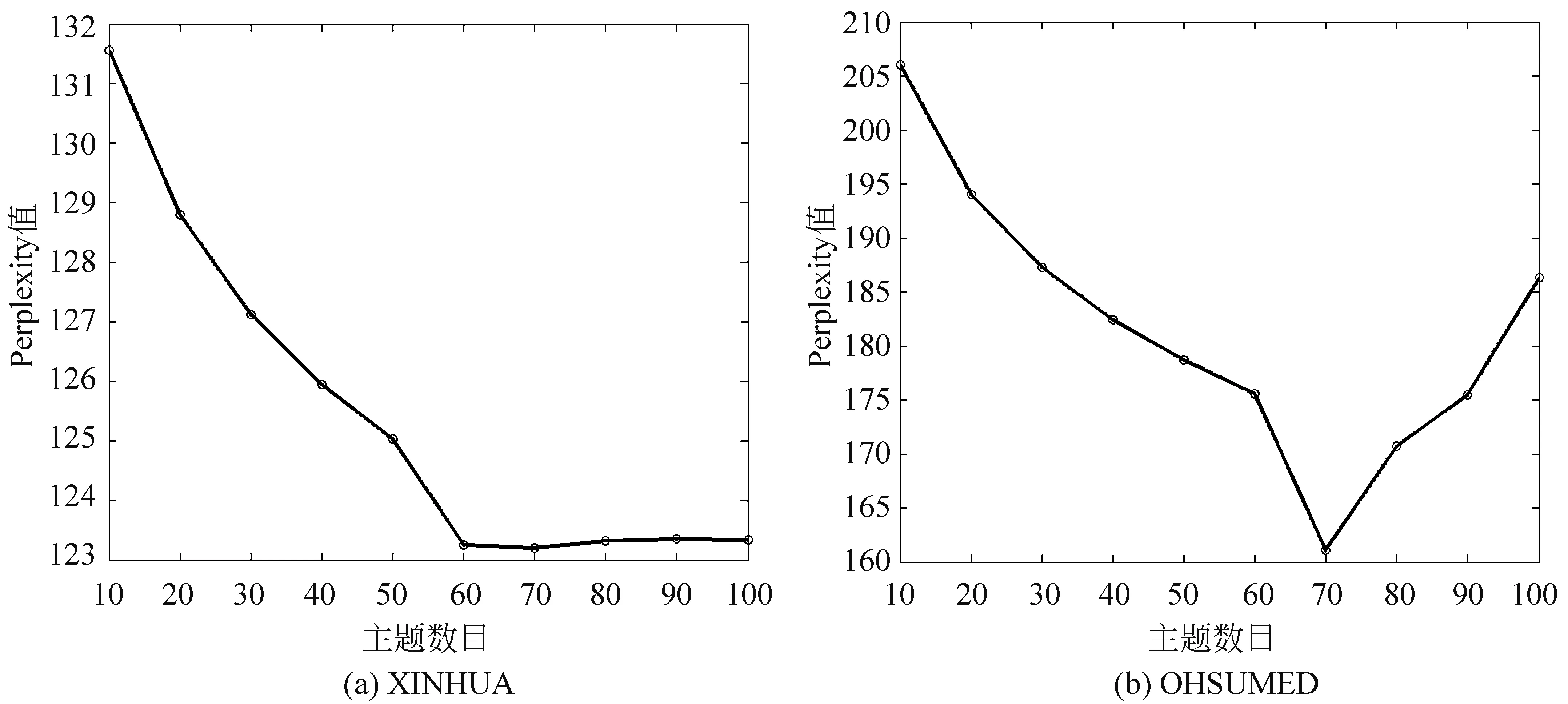
图3 中英数据集Perplexity值变化曲线

XINHUA数据集OHSUMED数据集主题原始主题分析结果伪主题分析结果主题原始主题分析结果伪主题分析结果Topic 2增长,去年,今年,美元,经济,出口,下降,增加,统计,同期,达到,消费,占,显示,季度,上升,同比,达,报告,减少增长,经济,美元,消费,同期,同比,出口,达到,上升,统计Topic 4expression, cells, class,sur-face, lines, complex,ex-pressed, T-cell, molecules, cells., major, bound, interfer-on, HLA-DR, murine, mole-cule, sites, interleukin, dis-tinct, transcripts sites, complex, dis-tinct, interferon, lines, HLA-DR, molecules, cellsTopic 4教育,大学,学生,学校,儿童,人才,培训,妇女,专业,学习,就业,青年,培养,学院,青少年,工作,务,职业,高校,社会培养,儿童,职业,工作,妇女,服务,就业,青少年,青年,教育,培训,人才Topic16observed, study, studies, dis-tribution, suggesting, rapid, investigated, epitopes, demon-strated, potential, determined, absorption, staining, possibili-ty, labeled, quantitative, re-spect, identical, preparations, investigated staining, deter-mined, potential, i-dentical, rapid, suggesting, possi-bilityTopic 6上海,国际,举办,世界,城市,中心,协会,来自,展览,举行,活动,主办,上海市,成功,申办,博览会,今天,中国,世博会,浦东 世界,博览会,展览,城市,上海,举办,活动,中心,主办,协会,举行Topic18hospital, patient, support, study, time, program, costs, nursing, programs, status, ad-mitted, elderly, community, care, patients, survey, recom-mended, systems, improve, benefitsunderwent, dura-tion, radiation, preoperative, tumor, surgery

图5 中英文本集各主题网络图EQ值结果
总体而言,本文所提方法在主题内容发现过程中,综合考虑了网络的拓扑特征和原始描述主题词项的权重信息,能够给出更符合主题所表达语义的伪表达结果。
4 总结
本文提出了一种基于主题网络的伪主题分析
方法。该方法综合考虑网络拓扑结构和主题网络社区内部结构,从全局数据集角度考虑,评估主题网络各社区节点重要度,实现从网络结构角度抽象描述文本语义特征,弥补统计方法对文本语义结构刻画的不足。对实际文本数据集的主题网络的伪主题分析实验中,模块性表现良好。本文所提方法可以帮助用户更好地分析和理解大规模数据,进一步应用于文本主题内容可视化分析应用中。
猜你喜欢
科学与信息化(2021年8期)2021-03-31
开放教育研究(2020年2期)2020-03-31
活力(2019年21期)2019-04-01
哲学评论(2018年1期)2018-09-14
大学教育(2017年5期)2017-05-10
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
西南交通大学学报(社会科学版)(2015年4期)2016-03-29
长江学术(2016年4期)2016-03-11
快乐作文·中年级(2015年3期)2015-03-26
