
面向任务口语对话系统中不含槽信息话语的端到端对话控制
2019-01-22 08:33黄锵嘉黄沛杰李杨辉杜泽峰
中文信息学报 2018年12期
黄锵嘉,黄沛杰,李杨辉,杜泽峰
(华南农业大学 数学与信息学院,广东 广州 510642)
0 引言
面向任务(task-oriented)的限定领域口语对话系统(spoken dialogue system,SDS)是自然语言理解领域内的研究热点之一。它有着广泛的应用场景,如信息咨询[1-4]、商品导购[5]、旅游虚拟助理[6]、导航系统[7-8]等自然语言智能助理。近年来,一系列端到端(end-to-end)SDS模型[2-4,9-11]取得了超过传统的管道式SDS模型的性能,从某种意义上归功于它们能有效避免传统的管道式设计存在的错误传递和错误累积问题。然而,经典的end-to-end训练方式比较适合面向非任务(non-task-oriented)SDS[9-11]。通过大量数据,能够训练有效的聊天机器人类型的SDS。对于面向任务(task-oriented)的SDS,则需要进一步解决如何有效捕捉任务领域的信息,并融入到动作策略的选择及应答[12]中。
最近的研究已经开始转向尝试以end-to-end方式训练面向任务的SDS[2-4]。通过采用记忆网络的推理方法来建模对话[2],以及将命名实体识别、数据库查询结果等语义特征结合到基于神经网络的end-to-end模型中[3-4],可在一定程度上实现含有领域语义槽信息的用户话语的系统应答动作策略的end-to-end学习。然而,面向任务SDS中表达多样的不含槽信息的话语,既不能像面向聊天SDS那样处理,又缺乏含有槽信息话语中的领域语义信息,其有效对话控制仍然是一个挑战。
本文在应用卷积神经网络(convolutional neural network, CNN)对“显式”话语序列提取得到的特征表达的基础上,通过构造和捕获对话序列中“隐式”的系统后台上下文信息,进一步丰富了处理不含槽信息话语的end-to-end系统动作分类模型的特征表达。本文的主要贡献包括:
(1) 提出一种融合“显式”话语特征和“隐式”上下文信息的end-to-end混合编码网络处理不含槽信息话语的对话控制。“显式”的话语序列的特征学习有助于捕捉不含槽信息话语的对话行为,“隐式”的系统后台上下文信息支持面向任务的对话策略学习。
(2) 在中文限定领域的面向任务SDS数据集的评估表明,在不含槽信息话语处理方面,与传统的管道式SDS模型和经典的end-to-end 模型相比,本文的方案能更好地捕捉对话上下文信息,在单回合处理以及对话段整体性能上都得到了显著的提升。
本文组织结构安排如下: 第1节介绍相关工作,第2节介绍本文提出的方法,第3节为测试结果及分析,第4节总结本文的工作并做简要的展望。
1 相关工作
1.1 管道式的SDS
传统的管道式SDS由一系列有关联的模块组成,一般包括自动语音识别(automatic speech recognition,ASR)、口语语言理解(spoken language understanding,SLU)、对话管理(dialogue management,DM)、自然语言生成(natural language generation,NLG)、以及语音合成(text-to-speech,TTS)等五大模块[13-14]。管道式设计的局限性一方面在于其模块一般是独立训练的,本质上很难将系统适应到新任务领域。例如,当其中一个模块采用新数据进行训练或者在设计上进行了改动,与之相关联的模块也需要重新训练或者设计,但这样的做法需要耗费大量的精力。此外,模块间的错误传递会导致错误累积,并且前序模块的错误会向后续模块传播,不容易追踪和确定错误的来源[15]。
1.2 面向非任务的end-to-end SDS
面向非任务(non-task-oriented)的end-to-end SDS[9-11]主要受到序列到序列(sequence to sequence)学习[16]的启发,将对话当作是从源到目标的序列转换问题,采用编码器(encoder)网络[17]将用户话语编码为表示其语义的分布式向量,然后通过解码器(decoder)网络生成系统应答。这些模型通常需要大量的数据来训练。它们适合创建有效的聊天机器人类型的SDS,但缺乏完成特定领域任务的能力,例如,与数据库交互[12]并将有用的信息融入到应答中。
1.3 面向任务的end-to-end SDS
近年来,研究者们开始研究适合面向任务SDS的end-to-end可训练模型。Wen等[4]提出了一种模块化连接的基于神经网络的end-to-end可训练模型。该模型分离了意图估计、状态确认、策略学习和响应生成等模块。Bordes和Weston[2]提出了一种使用end-to-end记忆网络的推理方法来建模对话。他们的模型直接从响应列表中选择系统响应,而没有经过状态追踪模块。Williams等[3]将命名实体识别、数据库查询结果等语义特征结合到基于神经网络的end-to-end模型中,优化了系统动作策略学习的性能。
表1是一个面向手机导购的SDS示例。在目前研究进展中,对于携带任务领域语义信息(槽信息)的用户话语(表1对话话语中的(4)、(6)、(8)、(12)、(16)),采用已有的研究方法,可有效地实现从用户话语到系统动作的end-to-end学习,无需通过管道式设计的槽信息填充、对话行为识别和对话策略等模块化的独立学习过程。具体例如,若是“陈述句”,模型输出“主动引导”的系统动作,记录下用户提供的信息,并引导用户进一步提供更多必要信息;若是疑问句,模型输出“查询并回复”的系统动作,结合话语相应的问句类型(如(8)的“特指问”、(12)的“选择问”)查询数据库并回复。
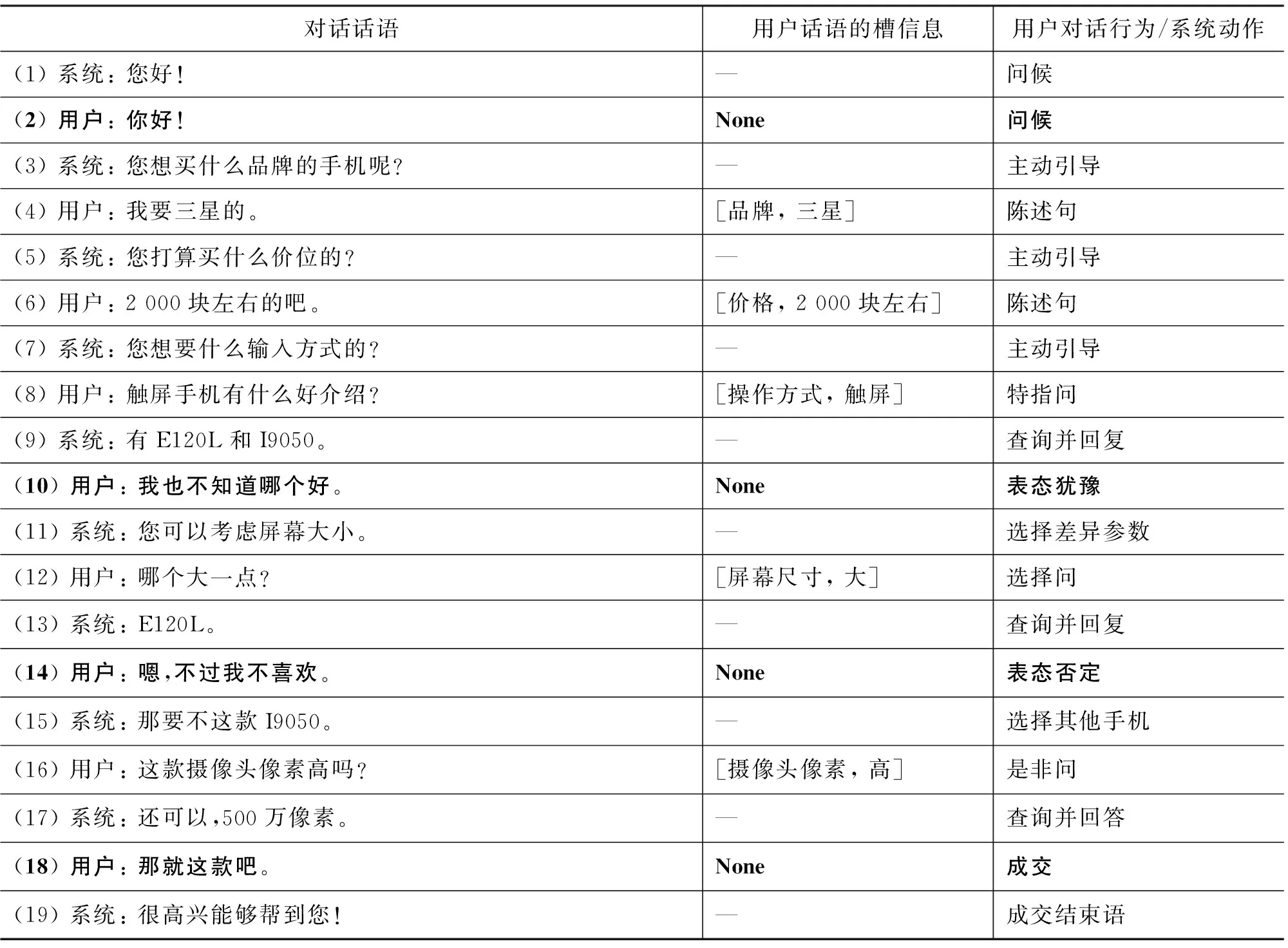
表 1 面向任务的SDS示例 (None表示不含槽信息)
然而,对于不含槽信息的用户话语(表1对话话语中的(2)、(10)、(14)、(18)),其表述更像面向聊天的用户话语,但又不能像面向聊天SDS那样处理话语。因为,会脱离所面向的任务的流程,不利于任务的完成。另外,相对比于含有槽信息的话语,不含槽信息话语,因缺乏领域语义信息,且此类话语表达多样,其有效对话控制仍然是一个挑战。
本文在应用卷积神经网络(convolutional neural network, CNN)对“显式”话语序列提取得到的特征表达的基础上,通过构造和捕获对话序列中“隐式”的系统后台上下文信息,进一步丰富了end-to-end系统动作学习模型的特征表达,实现了不含槽信息话语的end-to-end对话控制。
2 结合“隐式”上下文信息的end-to-end模型
2.1 总体技术框架
图1是本文提出的处理不含槽信息话语的融合“显式”话语特征和“隐式”上下文信息的end-to-end混合编码网络模型结构图。
(1) “显式”的话语特征。口语话语是一种典型的短文本,故本文采用了在短文本理解中广泛采用的CNN提取话语的特征表达。用户句子首先通过句子特征表达完成从自然语言到低维实数向量的映射,完成句子特征的表达。通过CNN不同的卷积窗口大小对输入特征进行卷积操作,提取不同粒度的特征组合,池化层实现对卷积特征的聚合统计,在保留重要特征的同时对特征起到降维作用。在池化层后面是dense层(隐藏层),dense层能够对卷积层和池化层提取到的多粒度词语特征进行权衡,并选择出最有价值的特征,而dropout机制能够有效防止模型过拟合。
(2) “隐式”的后台系统上下文特征。后台系统上下文信息主要包括两个方面的作用。一方面是更准确地“捕捉”对话上下文的概要信息。比如用户“连续不含槽信息的回合数”、“上回合讨论对象”(具体商品还只是某一商品属性,或是商品无关)、“是否已推荐商品”,单纯依靠对话话语序列输入的end-to-end模型, 很难直接通过对话序列“获取”这些信息;另一方面,是提供直接从对话序列无法获取的信息。比如“候选商品数量”是系统内部掌握的信息,可由系统根据当前的对话上下文已确定的商品槽信息查询数据库得到。值得注意的是,对于含有槽信息的话语的处理,当前的主流模型,不论是管道式SDS还是end-to-end SDS,都带了商品槽信息获取。

图1 融合“显式”话语特征和“隐式”上下文信息的end-to-end混合编码网络模型结构(以商品导购SDS为例)
最后,将“显式”的话语特征和“隐式”的后台系统上下文特征进行拼接,并连接softmax分类层,输出对不同系统动作预测的概率分布。
2.2 卷积神经网络模型
卷积神经网络(convolutional neural network, CNN)在短文本理解方面取得较好的应用效果[18-19]。本文采用了Kim[18]提出的卷积神经网络结构模型,该模型采用了多种核尺寸实现对句子进行不同粒度特征的提取,不同粒度的特征对实验结果有改善的作用。
在原始的全连接神经网络中,假设第l隐藏层有ml个节点,第(l-1)隐藏层有nl-1个节点,这时连接第l层与第(l-1)层的参数个数将达到nl-1×ml个。当nl-1和ml都很大的时候,参数空间会很大,也意味着计算量加大,从而导致训练过程也会特别慢。因此, 采用卷积神经网络可以很好地解决这
个问题,卷积神经网络第l层的神经元只与第(l-1)层的局部相连接,这时连接第l层与第(l-1)层的参数个数为(nl-1-ml+1)。
其中,hl表示第W(l)层的输出,W(l)表示连接第(l-1)层和l层的滤波器,⊗代表卷积运算,b(l)为偏置,f为激活函数。
卷积操作的应用虽然使得连接层与层之间的权重参数空间大大减少,但卷积操作后输出的神经元个数与全连接的神经网络相比并没有多大改变。若此时在卷积结果后接一个softmax分类层,则其参数空间仍然相当庞大。因此,通常的做法是在卷积操作之后执行一个采样操作,也称为池化(pooling)。池化操作不仅能进一步减少参数的个数,还能降低特征的维度,从而避免了过拟合现象[20],如式(2)所示。
其中,pool表示池化操作,常见的有最大池化和平均池化,本文采用最大池化(max-pooling)作为采样函数。
2.3 “隐式”的后台系统上下文信息
本文提出的方案中,从对话信息流中持续采集的“隐式”的后台系统上下文信息如表2所示。本文

表2 “隐式”系统上下文特征
期望通过增加这4类后台系统上下文信息,可有助于捕捉对话流程的“隐式”上下文(相比于“理解”用户话语的文本信息得到的“显式”特征),有效地实现不含槽信息话语的end-to-end对话控制。
(1) 连续不含槽信息回合数。该特征记录了用户连续没有主动提供商品相关信息(槽信息)的回合数。一般而言,出现这种情况或者是用户缺乏主动主导对话的习惯,或者是用户进入了连续闲聊的状态。加入这个特征有助于增加模型选择“主动引导”动作的概率,将对话“带回”导购流程。
(2) 是否已推荐商品。该特征用于标识“推荐商品”这个系统动作是否出现过。系统是否已经向用户推荐过商品,潜在有助于对用户的一些对话行为,例如,“表态肯定”、“表态否定”等做出正确的系统动作选择。
(3) 上回合讨论对象。该特征不容易直接通过模型从对话序列上下文直接“理解”得到,但系统却能做出较为准确的记录。上回合讨论的对象的不同,也会影响系统做出不同的系统动作选择。
(4) 候选商品数量。该特征结合系统当前的对话上下文已确定的商品槽信息查询数据库得到。一般而言,在候选商品依然较多时宜继续引导用户表达特定商品属性的需求,而在候选商品较少时则可能适时推荐会更合适。尤其是候选为空时,需要及时告知用户。
3 实验
3.1 数据集
实验数据采用中文手机导购领域的对话语料库。训练数据从多年的系统日志中整理得到,选取了516段对话过程没出现系统错误,并且包含有不含槽信息话语的对话段,用于模型训练及模型超参数调节。在训练集中,用户话语4 938句,不含槽信息的话语为1 180句,占语料库的23.89%。
测试数据采用13名测试人员测试产生的对话过程没出现系统错误,且包含不含槽信息话语的对话段(共159段),用于本文提出方法与研究进展方法的评估和对比。训练和测试数据的总体统计结果如表3所示。
本文用于训练Word2Vector模型的数据是由中国中文信息学会社会媒体专委会提供的SMP2015微博数据集(SMP 2015 Weibo DataSet)。本文只使用了该数据集的一个子集(1.5G),该子集超过1 000万条微博数据,词汇表的词语数为519 734个。

表3 数据集的统计结果
3.2 系统动作
系统动作是系统根据当前的上下文情况以及与用户交互过程中可采用的对话行为,也是本文的end-to-end对话控制的输出。系统确定了系统动作之后,再结合一些来自数据库的信息生成完整的系统应答。
在当前实验的中文手机导购SDS中,共有12种系统动作(表4)。其中包括社交动作的设计,使得用户对系统应答的体验更加自然,如“问候语”、“闲聊结束语”等。而任务相关动作设计的目的在于协助用户进行导购,如“主动引导”、“推荐候选手机”等动作。

表4 系统动作(实验采用的手机导购SDS)
3.3 实验设置
本文实验包括了CNN的特征选择以及研究进展方法的对比,实验中模型训练的参数调节均采用k-折(本文采用5折)交叉验证。
本文方法,融合“显式”话语特征和“隐式”上下文信息的end-to-end混合编码网络(explicit and implicit context hybrid code network,EIC-HCN),对比的三种研究进展方法如下:
(1) DA+DM: 该方法作为对比的传统的管道式SDS方法,对话行为(DA)识别采用了Wang等人提出CNN-RF混合模型[21],对话管理(DM)采用POMDP进行建模[14]。
(2) MemN2N: 采用了Bordes和Weston[2]提出的记忆网络对SDS进行建模,实现了SDS以end-to-end的方式进行学习。
(3) CNN(BOC(N_utterances)): 采用了Severyn和Moschitti[19]的方法作为经典的end-to-end模型的另一个代表,将原始的序列对话中的近N个用户话语作为输入,并最终输出系统动作的预测。在本文实验中,经过5折的交叉验证,该对比方法选择了N=3。
测试采用了Bordes和Weston[2]实验中的评估方法,对单回合和对话段两个层面进行评估。
3.4 评价方法
目前针对口语对话系统性能的评价没有一个统一标准[22]。有直接以人工标准(Gold-standard)作为评判[23],较为客观。但由于特定用户话语潜在存在不止一个合适的系统应答动作,所以偏向“严格”。也有采用主观的评价。例如,人工对系统的预测结果进行满意度的评分[24-25],但这样的做法容易受主观性影响。也有其他研究工作为每一个用户的请求定义了一个候选集[2, 26],若系统预测结果在候选集合里,则认为是正确的,但人工定义这样的候选集需要耗费较多的人力资源。综合已有的评价标准,本文基于中文手机导购系统为背景,采用了以下的评判方法。
(1) 客观评价
对测试集中每一句不含槽信息的用户话语对应的系统应答的系统动作进行人工检查确认,然后以人工标准(Gold-standard)作为评判,模型输出和Gold-standard一致时为正确,不一致时为错误。
(2) 主观评价
对于不同方法预测的系统动作,人工对系统的预测结果进行满意度的评价。满意判为正确,不满意的判为错误。本文对以下三种情况判为不满意(也即是错误)。
① 答非所问。系统回答与用户询问存在逻辑或语义的错误。如系统选择“闲聊结束语”去应答用户的问候等。
② 违反上下文。系统应答动作与当前用户的历史上下文相矛盾。如在“未推荐手机”的情况下,执行“成交结束语”、“购买确认”、“选择其它手机”等动作。
③ 态度消极。系统在应对导购任务进程采取消极的应对动作。具体表现如,在 “已推荐手机”的情况下没有积极地向用户做出“购买确认”动作;在满足向用户推荐手机的条件下未向用户做出“推荐候选手机”动作;或在导购任务未完成的条件下,多次持续地与用户进行任务无关的交谈。
3.5 实验结果及分析
3.5.1 客观评价
(1) 原始特征选择
本文对比字袋(BOC)、词袋(BOW)、Word2Vector(W2V)、position encoding(PE)[12]等不同CNN原始特征表达的效果。结果如表5所示。w2v特征表达中对句子字数的句子编码进行验证。
从表 5 可看出,BOC和BOW的特征表达均优于W2V和 PE 的特征表达。而字相比词在 SDS领域中能够更好地对句子特征进行表达,这也体现了 SDS 中话语口语化的特点。
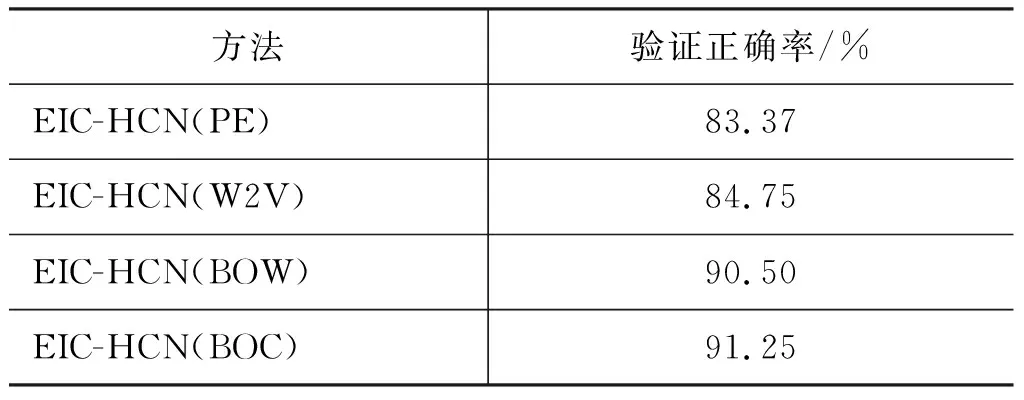
表 5 不同原始特征识别效果
(2) 研究进展方法对比(客观评价)
本文提出的方法与研究进展方法对比结果如表6 所示。本文的方法选用了字作为原始特征,采用了字袋的向量表达方式(BOC)。MemN2N模型和CNN(BOC(N_utterances))模型采用原始的对话序列作为上下文。
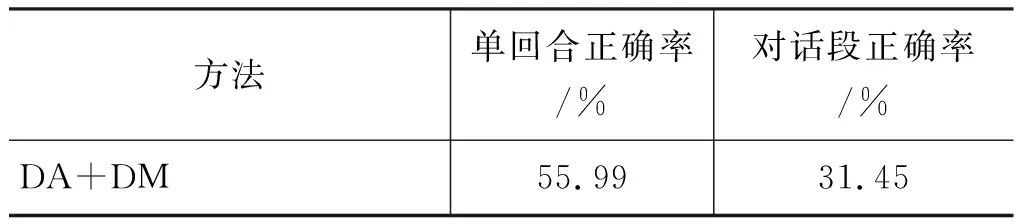
表6 本文提出方法与研究进展方法的对比(采用客观评价)

续表
从表6测试结果表明,本文提出的方法比传统管道式模型(DA+DM)、记忆网络模型MemN2N、以及经典的end-to-end CNN模型CNN(BOC(N_utterances))在单回合正确率分别提高了27.40%、23.46%和16.78%;在对话段评估上,本文提出的方法比三者正确率分别提高了33.33%、34.59%和24.53%。这表明本文的方案能够较好地解决不含槽信息话语end-to-end对话控制的挑战。此外,虽然经典的end-to-end模型在非任务领域有优异的表现,但在任务领域的性能并没有显著地超过管道式SDS模型。本文融入模型的“隐式”上下文信息有效地弥补了经典end-to-end SDS在用户对话上下文刻画方面的不足。
3.5.2 主观评价
(1) 研究进展方法对比(主观评价)
我们进一步以主观评价为标准,对比了本文提出的方法EIC-HCN与研究进展方法,结果如表7所示。

表7 本文提出方法与研究进展方法的对比(采用主观评价)
从表7可以看到,从主观评价角度,所有模型的正确率(人工评价的系统动作的满意率)都得到一定程度的提升。尤其是管道式SDS取得了和两个经典end-to-end模型相当的单回合正确率。我们的模型取得了优于对比方法的性能,正确率达到了接近90%。
(2) 细分错误类别分析
表8给出了不同方法的单回合动作预测错误(也即是人工评价中的不满意)分类,为了方便不同方法之间的横向比较,统计数据采用了每种错误类型的回合数占总回合数的比例。在具体的分析中,存在着同时满足两个或两个以上错误分类的例子,所以不同错误分类的占比总和会略大于总错误率。
表8不同方法的单回合错误分类(比例为全部测试样例的百分比)
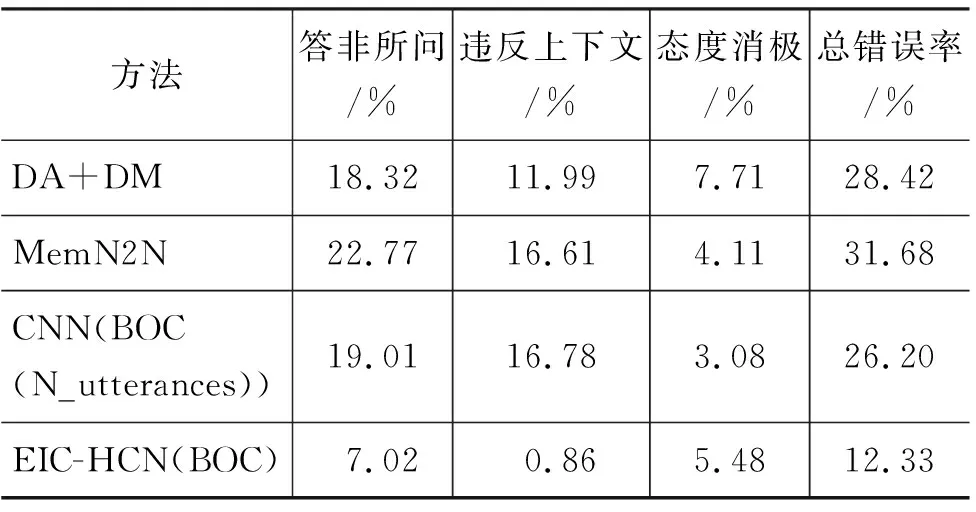
方法答非所问/%违反上下文/%态度消极/%总错误率/%DA+DM18.3211.997.7128.42MemN2N22.7716.614.1131.68CNN(BOC(N_utterances))19.0116.783.0826.20EIC-HCN(BOC)7.020.865.4812.33
从表8可以看出,在不同方法的错误分类中,“答非所问”和“违反上下文”是错误分类的主要组成部分。同时,相比研究进展方法,本文提出的方法在“答非所问”和“违反上下文”的错误率得到明显的减少,而“态度消极”需在系统任务和用户体验感之间做出权衡,相比研究进展方法,本文方法在该错误分类中并没有得到明显的改善。
具体错误分析如下:
(1) 答非所问。造成“答非所问”错误的主要原因在于对用户话语的语义理解失误。MemN2N方案采用的记忆网络并不能较好的结合用户话语中字或词之间的联系,错误最多。而CNN能够通过卷积操作实现对用户话语语义的有效提取,实验结果得到一定的改善。本文提出方案EIC-HCN(BOC)显著地将该分类的错误率降低到7.02%。
(2) 违反上下文。MemN2N和CNN(BOC(N_utterances))方案采用经典的end-to-end模型通过原始对话序列去捕获对话的上下文信息。两个方案在该错误分类占比分别为16.61%和17.78%,这说明记忆网络和单纯依靠“显示”话语特征的CNN并不适应长距离的对话任务。传统管道式SDS(DA+DM)和本文方法EIC-HCN(BOC)都采用了一些构造性的上下文特征,能够有效的克服上下文信息难以捕获的问题。本文的方法则还避免了管道式模型的错误传递。在该错误分类中,本文方案将错误率降低到0.86%。
(3) 态度消极。本文着重对“答非所问”和“违反上下文”错误分类进行研究和分析,这是因为大部分错误是由这两类错误引起的。在“态度消极”这个分类上,本文方法与研究进展方法的实验结果并没有显著的差别,未来的工作会对该类别进行研究。
4 结束语
为了有效地处理面向任务SDS中不含槽信息话语,本文提出了一种融合“显式”话语特征和“隐式”上下文信息的end-to-end混合编码网络模型。在应用CNN对“显式”话语序列提取得到的特征表达的基础上,通过构造和捕获对话序列中“隐式”的系统后台上下文信息,进一步丰富了系统动作分类模型的特征表达。在中文手机导购领域SDS的测试表明,本文的方法取得了优于研究进展中管道式SDS、经典的记忆网络和CNN训练的end-to-end模型的应用效果。在客观评价和主观评价两方面,都取得了单回合准确率和对话段准确率的显著性能提升。未来工作主要是完善“态度消极”错误分类的改进探索,进一步丰富后台系统上下文特征的构造,以及采用AMT (amazon mechanical turk) 服务[27]进行更大规模的测试。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
河北画报(2021年2期)2021-05-25
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
浙江人大(2014年6期)2014-03-20
浙江人大(2014年5期)2014-03-20
