
基于生成对抗网络的人脸图像翻译
2019-01-21 09:24:16吴华明刘茜瑞王耀宏
天津大学学报(自然科学与工程技术版) 2019年3期
吴华明,刘茜瑞,王耀宏
基于生成对抗网络的人脸图像翻译
吴华明,刘茜瑞,王耀宏
(天津大学数学学院,天津 300072)
针对人脸照片和人脸素描间的图像翻译问题,本文基于对偶生成对抗网络模型,对其目标函数附加两个损失函数建立新的网络模型.通过参数优化实验不断优化本文提出的模型,从而找到最优参数;通过直观和量化对比实验表明本文提出的模型在人脸数据上的图像翻译效果无论在清晰度还是在保持面部特征方面是目前基于生成对抗网络的图像翻译模型中表现最优的,并对相关GAN模型的稳定性进行了对比;最后通过效果分析实验说明了所附加的损失函数的具体作用.
生成对抗网络;人脸数据;图像翻译;损失函数
图像翻译是图像处理的一个重要研究领域,图像翻译就是把两个具有不同特征的图片域进行相应转换,包括不同域间的风格变换、物体变形、季节转换、图像增强等.按照传统方法,这些任务都是根据不同风格模式的图像间的内在差异分开进行处理的.在过去的几年里,通用的端到端的深度学习框架,最显著的是利用全卷积网络[1](FCNs)和条件生成对抗网络[2](CGANs)推动了图像翻译的发展,使得多种图像翻译问题可以得到统一的处理.经历了针对特定领域单任务的图像翻译到多领域多任务图像翻译的转变,从需要带标签配对的图像集到只需无标签非配对的图像集的转变,图像翻译过程越来越简单,功能却越来越强大.本文主要研究生成对抗网络(GAN)在图像翻译方面的相关模型及其在人脸数据上的应用.

由于进行有监督的学习和获得大量的带标签的配对数据可能很费时间,耗费较大的财力物力,有时甚至是不可能的,例如将日光场景转换为夜景,即使用固定摄像机,由于场景中经常有移动的物体,造成所得的配对图像有不同程度的内容差异.随后出现了利用非配对无标签数据进行非监督学习的模型CycleGAN、DualGAN和DiscoGAN.Zhu等[7]受循环一致思想[8]的启发提出了CycleGAN模型,解决了利用非配对无标签数据解决图像间的风格转移问题.Kim等[9]为确保图像在不同域转化时保持图像的某些特征,比如方向角、面部特征等,提出了DiscoGAN.Yi等[10]受原始的自然语言处理对偶学习方法[11]的启发,提出DualGAN模型,解决如何利用无标签非配对的数据进行具有不同特点的两个域之间的图像翻译问题.这3个非监督学习模型的网络模型结构很相似,都是由2个GAN结构[12]组成.在目标函数、生成器、判别器的构成上略有不同.3个模型在各自数据集上都取得了不错的实验效果,在人脸数据上的图像翻译效果在清晰度和保持面部特征方面仍有待提高.
本文针对在人脸数据上的图像翻译问题,在DualGAN模型的基础上进行改进,通过在DualGAN的目标函数的基础上附加2个L1损失函数来改善实验效果.通过参数优化实验,寻找最优参数,优化本文提出的模型;通过直观和量化对比实验表明本文提出的模型在人脸数据上的图像翻译效果在清晰度、保持面部特征方面是目前基于生成对抗网络的图像翻译模型中表现最优的,并对相关GAN模型的稳定性进行了对比;最后通过效果分析实验说明了所附加的损失函数的具体作用.
1 模型的建立
1.1 模型结构
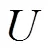

(1)
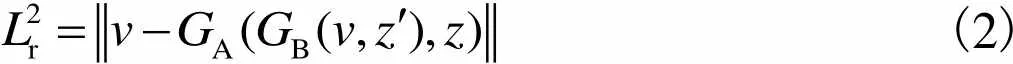
(2)

(3)

(4)
1.2 目标函数
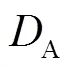
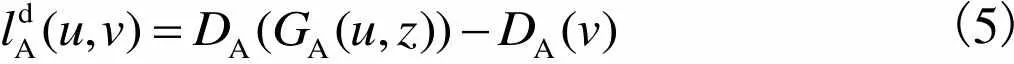
(5)

(6)
DualGAN的生成器的目标函数在WGAN的基础上加的是L1损失函数而非L2,因为L2时常会导致图像模糊[11, 14].DualGAN的最终目标函数为
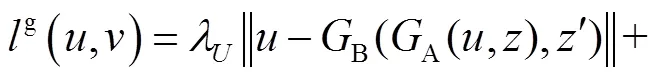
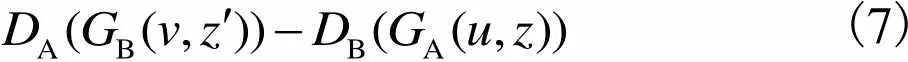
(7)
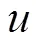

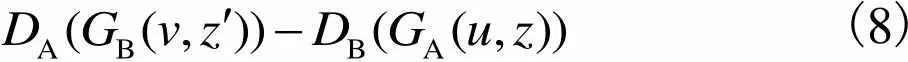
(8)
1.3 网络结构
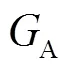
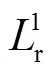
1.4 训练过程

算法1 本文模型的训练过程.
循环.
结束条件.
直到收敛.
2 实验及结果
2.1 参数优化实验

图2 在不同参数下人脸素描向人脸照片的翻译结果

图3 在不同参数下人脸照片向人脸素描的翻译结果

图4 当参数、取时人脸素描向人脸照片的翻译结果

图5 当参数、取时人脸照片向人脸素描的翻译结果
2.2 对比实验
2.2.1 直观对比
发现在人脸素描向人脸图像翻译的结果中(如图6所示),监督学习的模型CGAN和Pix2Pix生成的图像比较清晰,但有大量的人脸出现畸形和扭曲.非监督学习的模型CycleGAN、DiscoGAN和原始DualGAN模型的结果相比较,DiscoGAN生成的图像的结果最差,生成的比较好的图像有人脸的轮廓和眉目,但图像还是比较模糊,生成的较差的图像只能看到大概的人脸轮廓.DualGAN生成的图片相对DiscoGAN的比较好,大部分图像的人脸轮廓眉目甚至细纹都有,但缺点是图像的某些细节比如眼睛会出现模糊不清的现象,CycleGAN生成的图像结果最好,保持了输入的人脸素描的脸的轮廓、五官、细纹等特点,但与本文的模型生成的图像进行对比,CycleGAN生成的图像整体带着朦胧感,给人模糊不清的感觉.
比较人脸照片向人脸素描翻译的结果(如图7所示),监督学习模型CGAN生成的图片比较清晰,但在大多数人脸的鼻子和嘴巴处出现畸形和斑驳.监督模型Pix2Pix生成的图片,单从图片生成的质量来说,生成的图像人脸轮廓和五官都比较清晰,但跟输入图像或GT图像进行对比,发现Pix2Pix模型并没有很好地保持输入图像的面部特征.非监督学习的模型CycleGAN、DiscoGAN和原始DualGAN模型的结果相比较,DiscoGAN生产的图像最差,没有素描的线条特征,有的甚至没有人脸的轮廓. CycleGAN生成的图像整体保持了输入图像的特征,但没有素描的线条特征,图像表面好像加了一层小方格,不具有人脸素描的特点.DualGAN生成图像的结果相比前两者整体比较好,既保持了输入图像的面部特征,也具有素描的线条特征,与GT图像比较接近.但如果细致观察,本文的模型生成的图像与DualGAN生成的图像相比,本文的模型生成的图像在五官的细节上更加清晰.

图6 在不同GAN模型下人脸素描向人脸照片的翻译结果
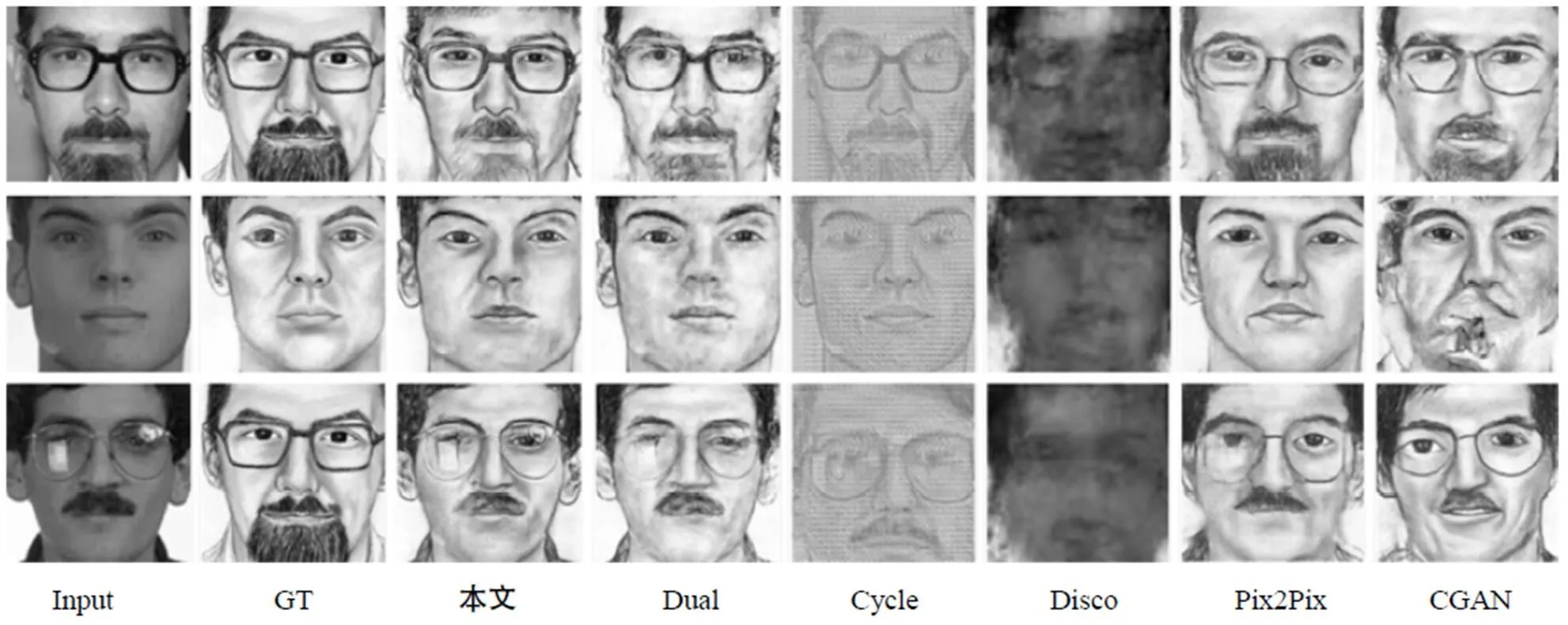
图7 在不同GAN模型下人脸照片向人脸素描的翻译结果
总体上,在人脸数据上图像翻译的实验中,本文的模型的结果相比其他模型的结果更加好.
2.2.2 量化对比
为了进一步说明实验结果,本文对实验结果进行了量化对比.由于数据太多,本文没有对所有的模型的结果进行量化对比.本文选出在人脸数据上翻译较好的DualGAN、Pix2Pix和本文模型的结果与GT图像进行了量化对比.具体方法:本文在测试集中随机抽取24张图,其中前12张用于研究人脸素描向人脸照片的图像翻译的量化对比,后12张用于研究人脸照片向人脸素描的图像的量化对比.为研究人脸素描向人脸照片的图像翻译结果,在DualGAN、Pix2Pix和本文模型的图像翻译结果中以及GT图像中分别找到前12张图相对应的人脸照片,给出每张图的输入的人脸素描,把来自上述3个模型相应的图像翻译的结果以及相应的GT图像随机排列,通过根据每个输入图像的图像特征对这4张随机排列的图像翻译结果进行评分,评分标准具体如下:很差为1分,差为2分,一般为3分,好为4分,很好为5分.本文通过编辑电子调查问卷的方式对数据进行收集,最终得到206份来自不同IP地址的评分结果,得到4类来源不同的图像在前12张图像翻译的平均分,最后根据每类图像的12个平均分再算平均分.通过对比4类图像翻译结果的最终平均分进行量化对比.研究人脸照片向人脸素描的量化对比实验用后12张图做上述类似处理.本文量化对比结果如表1所示,由表中数据可以看出,在人脸素描向人脸照片(S2P)图像翻译的结果中,4类图像的最终的得分相差相对较大,本文模型的最终得分仅次于GT图像,其次为DualGAN模型的得分,Pix2Pix模型的得分最低.在人脸照片向人脸素描(P2S)的图像的翻译的结果中,4类图像的最终得分相差相对较小,本文模型得分与GT图像仅差0.07分,其次为DualGAN模型的得分,Pix2Pix模型的得分仍为最低.综上,在DualGAN、Pix2Pix和本文模型在人脸数据上的图像翻译结果中,本文模型得分最高,本文图像翻译结果最好.
表1 不同GAN模型图像翻译结果真实度平均分
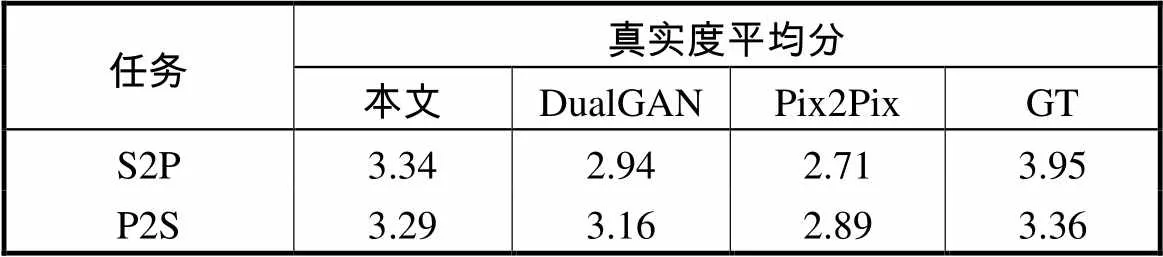
Tab.1 Average realness scores of images translation with various GAN models
此外,通过计算这4类图像的真实度得分的方差,进而对不同模型的图像翻译的稳定性进行了比较.如表2所示,在人脸素描向人脸照片的图像翻译结果中,Pix2Pix模型图像翻译的稳定性最好,本文的模型真实度方差比DualGAN模型大0.04,两模型的稳定性相差不大.在人脸照片向人脸素描的图像翻译结果中,Pix2Pix模型图像翻译的稳定性依然最好,DualGAN模型真实度方差比本文的模型大0.38,所以本文模型的稳定性要比DualGAN好.
表2 不同GAN模型真实度方差
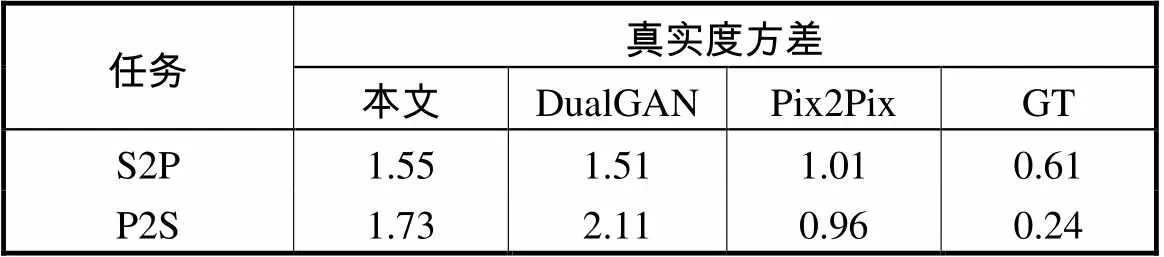
Tab.2 Variance of realness scores with various GAN models
2.3 效果分析实验
2.3.1 DualGAN为基础

图8 人脸素描向人脸照片翻译的结果与附加损失函数

图9 人脸照片向人脸素描翻译的结果与附加损失函数
2.3.2 DiscoGAN为基础

图10 Disco和Disco+的图像翻译结果
2.3.3 CycleGAN为基础

图11 Cycle和Cycle+的图像翻译结果
在DualGAN模型、DiscoGAN和CycleGAN模型的基础上分别进行了效果分析实验,得出结论:所附加的双向损失函数并不是可以改善所有的GAN相关的图像翻译模型,改善效果和相关GAN模型的具体网络结构有关.
3 结 语
本文在DualGAN的模型基础上通过修改目标函数来改善模型,通过一系列实验说明了在人脸数据上,本文提出的模型在图像翻译清晰度和特征保持方面要优于之前的相关的GAN模型,并对相关GAN图像翻译模型的稳定性进行了比较.不足之处在于本文的模型在测试集的少量图像的翻译结果不稳定,会出现斑点.此外模型只是在单通道的人脸数据上优于各深度学习领域的图像翻译网络模型,在多通道图像上的实验效果并不是最好的,接下来工作希望进一步对模型进行改善,提高模型的稳定性,并使其在多通道图像上的实验效果也能达到最好.
[1] Long J,Shelhamer E,Darrell T. Fully convolutional networks for semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Boston,USA,2015:3431-3440.
[2] Mirza M,Osindero S. Conditional generative adversarial nets[J]. Computer Science,2014:2672-2680.
[3] Goodfellow I J,Pouget-Abadie J,Mirza M,et al. Generative adversarial nets[C]// International Conference on Neural Information Processing Systems. Kuching,Malaysia,2014:2672-2680.
[4] Isola P,Zhu J Y,Zhou T,et al. Image-to-image translation with conditional adversarial networks[C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,USA,2017:5967-5976.
[5] Ronneberger O,Fischer P,Brox T. U-net:Convolutional networks for biomedical image segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Calcutta,India,2015:234-241.
[6] Li C,Wand M. Precomputed real-time texture synthesis with markovian generative adversarial networks [C]//European Conference on Computer Vision. Amsterdam,The Netherlands,2016:702-716.
[7] Zhu J Y,Park T,Isola P,et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[EB/OL]. https://arxiv.ogr/abs/1703.10593,2017.
[8] Sundaram N,Brox T,Keutzer K. Dense point trajectories by GPU-accelerated large displacement optical flow[C]//European Conference on Computer Vision. Crete,Greece,2010:438-451.
[9] Kim T,Cha M,Kim H,et al. Learning to discover cross-domain relations with generative adversarial networks[EB/OL]. http://cn.arxiv.org/abs/1703.05192,2017.
[10] Yi Z,Zhang H,Tan P,et al. DualGAN:Unsupervised dual learning for image-to-image translation[C]// IEEE International Conference on Computer Vision. Venice,Italy,2017:2868-2876.
[11] He D,Xia Y,Qin T,et al. Dual learning for machine translation[C]//Advances in Neural Information Processing Systems. Barcelona,Spain,2016:820-828.
[12] Liu M Y,Tuzel O. Coupled generative adversarial networks[C]//Advances in neural information processing systems. Barcelona,Spain,2016:469-477.
[13] Arjovsky M,Chintala S,Bottou L. Wasserstein gan [EB/OL]. http://cn.arxiv.org/abs/1701.07875,2017.
[14] Larsen A B L,Larochelle H,Winther O. Autoencoding beyond pixels using a learned similarity metric[C]// International Conference on International Conference on Machine Learning. New York,USA,2016:1558-1566.
(责任编辑:王晓燕)
Face Image Translation Based on Generative Adversarial Networks
Wu Huaming,Liu Qianrui,Wang Yaohong
(School of Mathematics,Tianjin University,Tianjin 300072,China)
With regard to the problem of image translation between face photo and face sketches,a new network model was established by adding two loss functions to the objective function of the DualGAN. Through optimization experiments of the parameters,the proposed model was continuously optimized to find the optimal parameters. The qualitative and quantitative comparison experiments show that the proposed model has excellent translation performance in face data in terms of sharpness and facial features,and it is now the best among the related GAN network models. The stability of related GAN models was then compared.Finally,the effect analysis experiment clarified the specific function of the additional loss functions.
generative adversarial networks;face data;image translation;loss functions
10.11784/tdxbz201801034
TP391.4
A
0493-2137(2019)03-0306-09
2018-01-03;
2018-04-28.
吴华明(1986— ),男,博士,讲师,whming@tju.edu.cn.
刘茜瑞,liuxirui57@tju.edu.cn.
国家自然科学基金资助项目(11601381).
the National Natural Science Foundation of China(No. 11601381).
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
江苏安全生产(2021年6期)2021-08-05 07:47:22
中学生数理化·中考版(2021年3期)2021-07-22 07:41:30
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28 08:43:52
歌剧(2020年4期)2020-08-06 15:13:32
雨露风(2020年8期)2020-04-26 19:55:51
动漫星空(2018年9期)2018-10-26 01:17:14
读者(2016年23期)2016-11-16 13:27:55
