
基于Spark的模糊聚类算法实现及其应用
2019-01-21 00:57:02吴云龙李玲娟
计算机技术与发展 2019年1期
吴云龙,李玲娟
(南京邮电大学 计算机学院,江苏 南京 210023)
0 引 言
入侵检测系统(intrusion detection systems,IDS)[1]在保障企业网络的安全性方面扮演着至关重要的角色。为了有效监测访问行为的异常与否,数据挖掘技术被广泛应用到入侵检测系统中。数据挖掘算法分为两类:有监督和无监督[2]。无监督的聚类算法有K-Means、模糊C均值聚类(fuzzy c-means,FCM)等。FCM[3]在传统C-均值算法中添加隶属度矩阵来判定某条数据所属类别。这种算法在运算过程中需要多次迭代,当数据量特别大或者数据样本属性很多的时候,运算速度会大大降低。为了提高FCM算法对大数据的聚类效率,设计了FCM算法基于具有实时计算特点的大数据计算平台Spark[4]的并行化实现方法。该方法采用HDFS分布式存储底层数据,运用RDD对数据进行转换,用持久化技术进行中间结果的重用。为了检验该并行化FCM算法的有效性,用该算法对KDD CUP 99数据集聚类来进行入侵检测,首先对入侵检测数据集KDD CUP 99[5]进行了特征值提取等预处理,然后利用实现的FCM算法对训练数据集聚类得到聚类中心,再用测试数据集进行聚类效果检验。
1 相关技术
1.1 FCM算法分析
聚类分析可以在大量数据中挖掘隐藏的规律[6]。从聚类的结果来看,聚类算法可以分为两大类:软聚类和硬聚类。硬聚类是把某一个数据点明确划分到某一个类;软聚类是将样本个体通过隶属度标识出与各个类簇的隶属关系[7],模糊C均值聚类算法FCM是经典的软聚类算法[8]。模糊的概念是指,用[0,1]之间的隶属度来确定某个点属于某个类的程度。每条数据对所有类中心点的隶属度之和为1。FCM算法的步骤[9]如下:
步骤1:指定分类数和加权指数m,确定迭代次数,随机生成初始化隶属度矩阵并满足式1的约束条件。
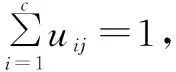
(1)
其中,j表示第j条数据;uij表示第j条数据隶属于第i个中心点的隶属度,取值范围为[0,1]。
步骤2:按聚类中心的迭代公式(见式2),根据uij构成的隶属度矩阵U,计算聚类中心。
(2)
其中,m是一个加权指数,可以控制聚类结果的模糊程度,取值范围为m∈(1,∞)。
步骤3:按式3计算目标函数J。
(3)
其中,dij=‖ci-xj‖,为第j条数据与第i个中心点的欧氏距离。
如果相邻两次迭代趋于收敛,小于指定阈值或者超过指定迭代次数,则结束;否则执行步骤4。
步骤4:根据新的聚类中心,按隶属度的迭代公式(式4)重新计算隶属度矩阵U,并返回到步骤2。
(4)
1.2 Spark平台
Spark是大规模数据的通用分布式并行计算平台。与Hadoop MapReduce编程模型不同,Spark利用RDD(resilient distributed datasets)进行计算,运算过程中的输出结果可以直接存于内存中。Spark以其分布式内存计算的特点,可以提升需要多次迭代的算法的效率。
RDD是Spark的核心。逻辑上,RDD存放数据;物理上,真实数据存放在各个分区中,每个分区可能位于不同的Worker节点之上。RDD的数据在默认情况下都放在内存中,因而Spark对内存的要求也很高。当内存不能满足运行需求时,它会把RDD数据序列化到磁盘。RDD具有容错性,由于把数据同时存放在多个分区中,当某个节点出现分区数据丢失或者损坏等故障时,会自动重建丢失数据。
Spark提供了丰富的算子来操纵RDD,每个算子发出的指令最终会落实到对每个分区里数据的操作上。开发者通过Scala、Java或者Python调用RDD算子操作分布式数据集。RDD根据算子是否立即执行,可以分为两类:Transformation类和Action类。Transformation类操作会发生延迟计算,不会真正运行,需要Action类操作的触发才提交作业。
运算过程中,会生成多个RDD,从一个RDD转换到另一个RDD。Action类每次操作都会得到结果,如collect()、first()等。
Spark有4种运行模式:本地模式、Standalone伪分布式模式、基于Mesos的集群模式和基于YARN的集群模式。在Standalone模式下,Spark的架构如图1所示。
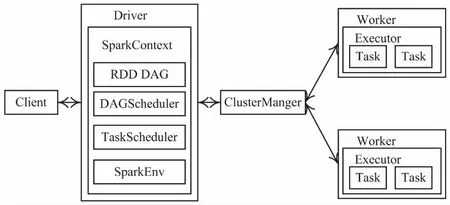
图1 Spark架构(Standalone模式下)
ClusterManager为Master(主节点),控制整个集群,监控Worker。Worker为从节点,负责控制计算节点,启动Executor或Driver。RDD的每个分区可能在不同的Worker机器上,每台Worker节点可能有多个Executor,每个Executor可能有多个Task在运行,Task和分区是一一对应的,所以partition分区的数量也影响着Task的并发程度[10]。
Standalone模式下任务提交运行的步骤是:Client提交应用,Master接受Client提交的任务并命令Worker启动Driver;Driver向Master或者资源管理器申请资源,某种意义上,Driver就是SparkContext,执行应用程序中的main()函数,创建SparkContext,SparkContext负责与ClusterManager通信,对Spark进行初始化,并创建DAGScheduler作业调度模块和TaskScheduler任务调度模块等;从Hadoop的HDFS加载数据,生成RDD,构建RDD DAG,将DAG图分解成Stage(当碰到Action操作时,就会催生Job;每个Job中含有1个或多个Stage,一个Stage包含一个或多个Task,Stage一般在获取外部数据和Shuffle之前产生);DAGScheduler把一个Spark作业转换成Stage的DAG(directed acyclic graph,有向无环图),根据RDD和Stage之间的关系找出开销最小的调度方法,然后把Stage以TaskSet的形式提交给TaskScheduler,在解析DAG图时,根据Shuffle来划分Job内部的Stage,并给出Stage之间的依赖关系;TaskScheduler借助ActorSystem将任务提交给集群管理器;Task在Executor上运行,运行完毕释放所有资源。
2 Spark平台上FCM算法的并行化实现
2.1 算法实现要点
(1)避免反复读取同样的数据。
文中采用RDD缓存(cache),把在计算过程被多次用到的数据cache到内存。
(2)中间结果的持久化。
Spark的Transformations类操作会延迟执行,它在Action类算子提交任务到Spark Context时触发,如果计算中其他的Action类操作用到中间结果,可以手动调用persist将中间结果做持久化操作。persist可以设置不同参数,不同的参数代表不同的存储级别。如果把persist参数设置为MEMORY_ONLY,其功能同cache功能。
(3)减少通信开销。
broadcast是以类似洪泛的方式广播数据。它是只读变量,保持数据一致性,可以把迭代过程中的聚类中心广播到各个分区,在FCM算法的实现过程中,会不断迭代产生新的中心点,需要把新的中心点广播到各个节点,使得下一次只计算每条数据和新的中心点之间的距离。这样可以高效地分发变量,减少通信开销。
2.2 基于Spark的FCM并行化流程
基于Spark的FCM算法并行化实现流程见图2。
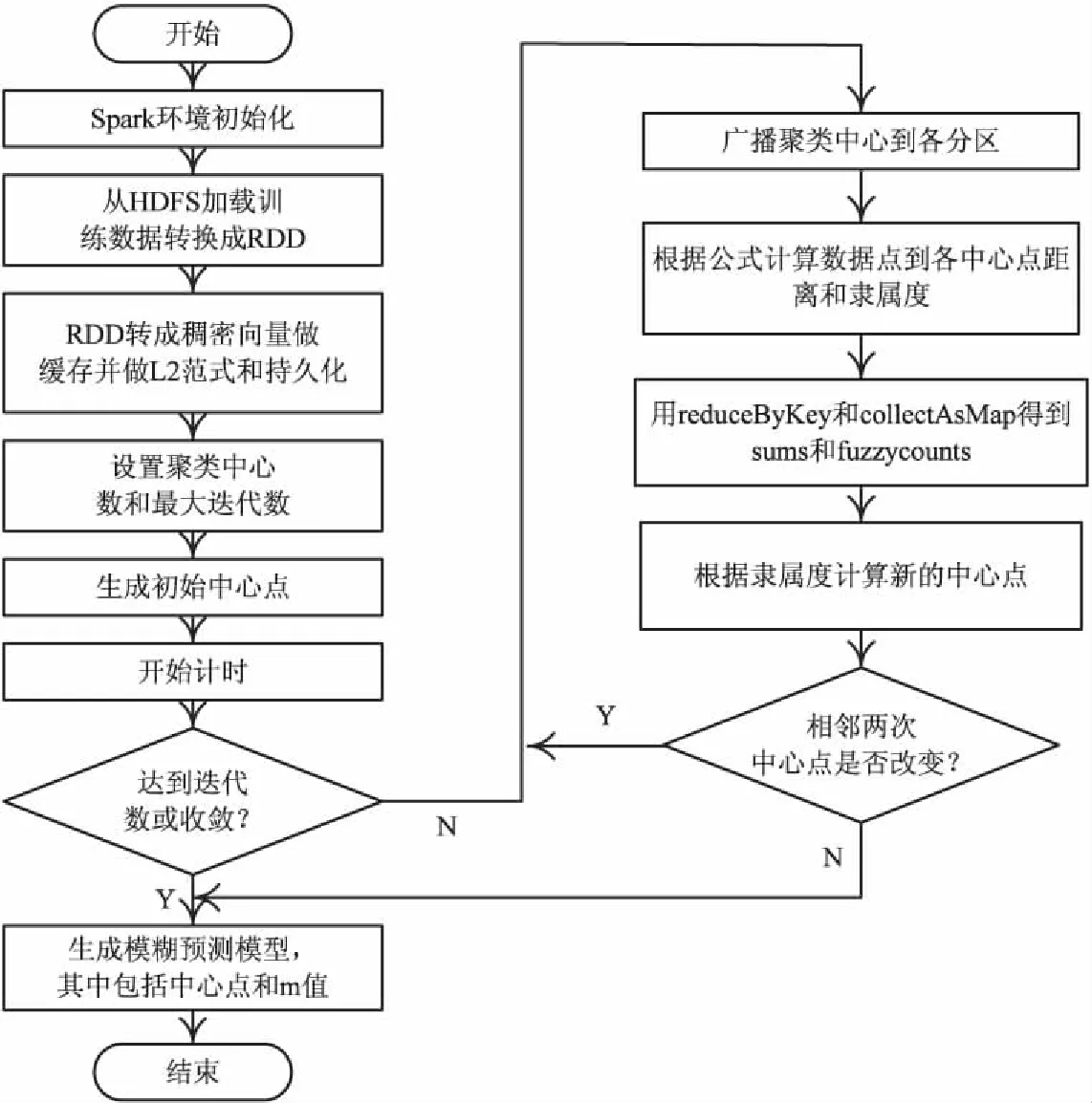
图2 算法实现流程
Step1:把文本数据上传到Hadoop的HDFS文件系统,在应用程序中通过sc.textFile()加载进RDD,然后把数据转换成稠密向量,这里把数据cache到内存,计算过程中数据直接从内存中获取。对数据做L2范式,即求向量各元素的平方和然后求平方根,并且做持久化。
Step2:初始化聚类中心,采用takeSample API随机抽取部分训练数据集的方法获得初始聚类中心,并把聚类中心广播给各个partition。开始计时,便于最后统计运行时间。
Step3:利用mapPartiotions对每个分区进行计算。计算数据点到各中心的隶属度和数据点到各簇的距离和,隶属度满足式1。距离的计算可以调用Spark MLlib提供的MLUtil.fastsquaredDistance(x1,x2),x1和x2数据结构为数据点向量和其L2范式的组合;隶属度的计算依据式2。
Step4:用reduceByKey和collectAsMap得到sums和fuzzycounts。sums表示在并行度为i情况下,数据点到各簇的距离和;fuzzycounts表示在并行度为i情况下,各数据点到类中心的隶属度和。
Step5:基于sums和fuzzycounts,依据式4计算新的中心点,并比较相邻两次中心点有没有发生改变,如果未发生改变则更换标志位,迭代结束,最后返回预测模型FuzzyCMeansModel,它包含了聚类中心和m值。否则迭代次数加1,继续迭代。
Step6:用FuzzyCMeansModel的预测函数来预测数据点对某个簇的隶属度([0,1])。把最终结果存入文本,用于计算聚类准确率。
3 Spark平台上基于FCM的入侵检测实验
3.1 KDD CUP数据集
实验选取了KDD CUP 99的10%的数据集。这是一个模拟网络攻击的数据集,包含了41个网络属性,每条记录结尾的label显示了正常还是攻击。按照大类来分,它包含了正常和异常两种类型的数据。正常访问的label为Norml,异常数据包括四大攻击:拒绝服务攻击DOS、远程登录攻击R2L、非法获取Root用户特权攻击U2R、探测式攻击Probe。
3.2 数据预处理
在数据挖掘中,从数据源得到的原始数据可能会存在冗余性、空值或者数据不完整等问题。为了提高挖掘的质量和计算速度,往往通过数据清洗、数据降噪、数据降维、数据集成、数据转换和数据简约等手段进行预处理[11]。在实验中,为了提高聚类效果,对数据做了如下预处理。
(1)数据简约。
有些属性对聚类效果不仅没有帮助,还会大大降低数据挖掘的效率,可以采用属性选择和数据采样技术加以简化。文中采用属性选择来去除对聚类效果意义不大的属性,参考文献[12],保留了7个特征:Duration、Protocol_type、Service、Flag、Logged_in、Count、Srv_count。用python脚本提取对应的特征值并保存到另外一份文本中,特征值提取代码如下:
#需要提取的特征属性
index=[0,1,2,3,11,22,23]
result=[]
temp=[]
tmp=[]
for line in open("resourcedata"):
tmp=line.split(",")
for i in index:
temp.append(tmp[i])
result.append(temp)
temp=[]
#把result列表数据写到文件中
(2)数据转换。
数据转换就是把数据从一种形式转换到另外一种形式。把数据集中的字符属性与数值属性转换,进行归一化,以便于FCM算法的计算。数据用python脚本处理的过程是:首先将保留的7个属性中的字符型属性定义为枚举;然后读取字符属性,按照其属性值转换为枚举中定义的值;最后再把结果保存到数据文件中。相应的python伪代码如下:
fromenum import Enum
classprotocol_type(Enum):
tcp='1'
udp='2'
icmp='3'
protocol_type[tcp].value
(3)空值处理。
空值作为数据对象的值,参与运算仍然是空值。数据挖掘中,空值的存在会使运算混乱,甚至可能无法完成。文中把空值置为“0”。
预处理前数据为41个属性,其中还有空值;预处理后保留了7个重要属性,空值也做了处理。
3.3 实验环境
实验中搭建了单机环境和Standalone集群环境。单机环境硬件为HP g6-2025TX,CPU型号为Intel CORE i5-3210M,双核处理器,内存8 G,硬盘读写速度为415 MB/s。软件环境为Ubuntu 14.04,JDK版本为JDK1.8,Hadoop版本为2.7.3,Spark版本为2.1,Scala版本为2.10.4。Standalone集群环境为Master节点一台,Worker节点两台,节点软件配置与本地模式相同。
3.4 聚类准确度分析
对相同样本在不同模式下运行FCM算法得到的检测率如图3所示。考虑到数据集包含四大类攻击和正常类型,聚类中心数设置为5。
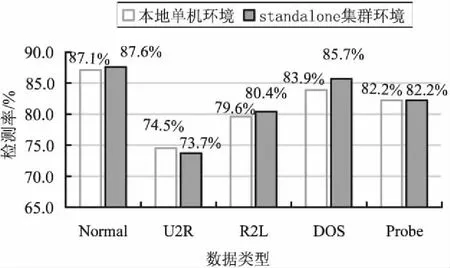
图3 在单机和Standalone集群环境下的检测率对比
检测率为:

(5)
由图3可以看出,FCM算法不会因为在分布式集群环境下处理数据而影响聚类结果,这说明FCM算法按照文中设计的方法在Spark上并行化运行,具有较好的鲁棒性和准确度。
预处理前后的数据上的检测率对比结果如图4所示。可以看出,预处理后的数据上的检测率更高。
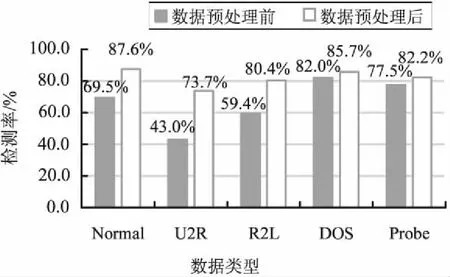
图4 Standalone集群环境下数据
3.5 聚类时效对比
预处理前后的数据的聚类时间对比结果如图5所示。可以看出,对预处理后的数据的处理速度更快。
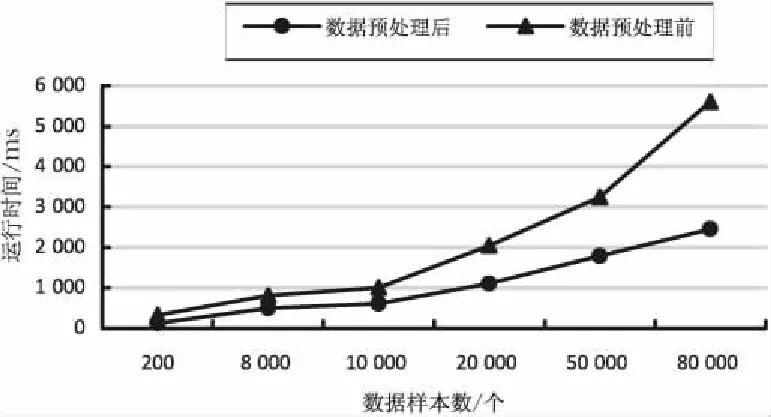
图5 Standalone集群环境下数据预
对预处理后数据分别在单机环境和Standalone集群环境下聚类的时耗对比结果如图6所示。
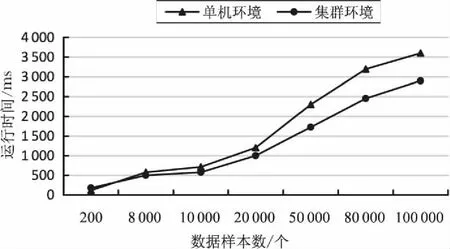
图6 单机和集群环境下预处理后数据的聚类时间对比
可以看出,当数据量不是很大时,单机环境和集群环境处理数据消耗的时间相近。集群环境下很多时间用在Shuffle过程中,甚至单机环境下处理数据的时效更高。这说明:小数据量并不适合在集群下处理。但是随着数据量的增多,集群环境对数据的处理速度明显快于单机环境。
4 结束语
文中主要研究FCM算法如何在Spark平台并行化实现,扩充了Spark MLlib,并将并行化的FCM算法应用于对入侵检测数据集的聚类。合理调用Spark RDD算子实现模糊聚类,把可缓存到内存的中间结果做Cache,降低中间读写磁盘操作的时间,且通过广播聚类中心方式高效分发变量,减少节点间网络通信消耗。另外,对比了KDD CUP 99数据集分别在单机和集群环境下的检测率和运行时间,并对比数据集预处理前后的检测率和聚类效率。应用结果表明,所设计的并行化方法提高了FCM算法的速度,对KDD CUP 99数据集的预处理降低了实验数据的维度,提高了准确度和处理速度。
猜你喜欢
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
当代陕西(2019年13期)2019-08-20 03:54:22
电子制作(2018年11期)2018-08-04 03:25:40
制导与引信(2017年3期)2017-11-02 05:16:56
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
工业设计(2016年11期)2016-04-16 02:50:19
环境科技(2015年6期)2015-11-08 11:14:26
电网与清洁能源(2015年2期)2015-02-28 16:03:07
测绘科学与工程(2014年5期)2014-02-27 07:06:14
