
基于强化学习的分布式智能入侵防御方案设计
2019-01-21 00:57:00李炳星
计算机技术与发展 2019年1期
李炳星,季 薇
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
认知无线电(cognitive radio,CR)[1]作为下一代无线通信技术,有效解决了频谱资源紧缺的问题,极大提高了频谱利用率。CR采用动态频谱接入方式实现次用户对频谱资源的二次利用,是目前被一致认可的解决频谱利用率低的最佳方案。其中,协作频谱感知(cooperative spectrum sensing,CSS)技术是认知无线电技术中的关键环节,CSS不仅可以提高频谱感知效率,而且可以克服无线环境中的阴影衰落、多径效应等的影响。然而,无线信道的开放性与复杂性,使得协作频谱感知极易受到恶意用户的攻击,致使频谱感知的可靠性与稳定性受到很大影响,因此频谱感知过程中恶意用户的检测与防御变得尤为重要。
在分布式协作频谱感知过程中,常见的恶意攻击是主用户伪造攻击(primary user emulation,PUE)[2]和频谱感知数据篡改攻击(spectrum sensing data falsification,SSDF)[3],目前研究较多的是后者。针对SSDF攻击,文献[4]提出一种动态信任度管理机制方法,当某认知用户为诚实用户的概率大于其为恶意用户的概率时,该认知用户被视为诚实的认知用户;相反,当某认知用户为恶意用户的概率大于其为诚实用户的概率时,该认知用户被视为恶意的认知用户。但是,在邻居用户中存在较多恶意用户的情况下,诚实的邻居用户将会被误判为恶意用户。文献[5]提出一种信任值异常检测的防御机制,该机制借助认知用户的信号接收强度(received signal strength,RSS)值判断主用户状态。其中,融合中心通过邻居用户的最大与最小信号接收强度计算出邻居用户对主用户的判决结果。当与融合中心判决结果一致时,表示该邻居用户是诚实用户,反之则表示该邻居用户是恶意用户。然而,当环境中存在大量的噪声时,将一定程度上影响邻居用户的RSS,最终导致融合中心做出错误的判决结果。文献[6]提出一种基于信任的防御方案,每一个认知用户视为一个融合中心,并以融合中心的感知能力作为基准对认知用户的信任分数进行奖惩。具有较低信任分数的用户被视为恶意用户剔除出去,不参与一致性融合。文献[7]提出一种基于密度的防御方案(density-based MU detection,DBMUD),该方案根据认知用户的信誉度来选择两个信誉度较高的用户,并以这两个诚实用户的信誉值为基准来筛选潜在的恶意用户。然而,此方法对于邻居中诚实用户不足两个的情况并不适用。
强化学习[8-10]对环境的要求低,通过对周围环境不断的学习和观察,可使智能体在任何时间任何状态下都能够做出最优的选择。强化学习应用于协作频谱感知过程,可以帮助认知用户选取最优的邻居用户进行合作或者放弃一些邻居用户,达到恶意用户甄别的效果。文献[11]提出一种基于强化学习的恶意用户的防御方案,认知用户通过不断地选取邻居用户进行协作频谱感知,将频谱感知结果与最终感知结果不同的认知用户视为恶意用户。文献[12]利用强化学习思想,每次选取信誉度较高的认知用户作为新的簇头(融合中心),簇头根据邻居用户的感知值进行邻居用户的信誉值更新计算,将信誉值较低的视为潜在的恶意用户。然而,此方案在恶意用户发起间断性攻击时,将不能有效地甄别出恶意用户。
为有效抵御恶意攻击,文中提出一种结合强化学习与信誉值的分布式智能入侵防御方案。该方案中,每个认知用户被视为一个智能体,在每一步迭代过程中,智能体通过查询Q矩阵,选取最优的邻居用户进行合作(信誉值较高的邻居用户),并获得瞬时回报和累积回报。当认知用户的判决结果与融合中心的判决结果一致时,给予一定的信誉值奖励,反之给予惩罚,将信誉值低于一定阈值的视为潜在的恶意用户,最终智能的恶意用户放弃恶意攻击,开始发送正确的感知值,达到全网一致性融合。
1 强化学习模型
强化学习的基本思想是:当智能体选择一种行为后,智能体获取较高的回报,其中包括瞬时回报与累积回报,之后智能体通过不断学习来选取最佳的行为决策[13]。在强化学习中,Q学习[9,14-16]作为一种单智能体算法,常被用于实时的网络环境中。并且这个智能体在其整个生命周期中,一直都在不断学习,观察和做出最佳的行为决策。强化学习的抽象模型包括三个主要的组成元素,分别是状态,行为和回报。状态表示在观察周围环境后影响智能体做出决定的因素。回报一方面表示性能参数得到最大化,如网络性能参数得到最大化,另一方面表示最小化,如簇中的恶意用户数量达到最小化。行为表示智能体为了实现最大的回报所采取的某种行为。
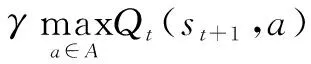
Qt+1(st,at)←(1-α)Qt(st,at)+α[rt+1(st+1)+
(1)
其中,α的范围是0≤α≤1,表示学习速率或者步长;γ的范围是0≤γ≤1,表示折扣因子。当智能体更多的考虑瞬时回报时,α设置为1。当智能体更在意长期回报时,γ设置为1。
正如式1所示,在每一步迭代过程中,智能体通过不断地观测和学习周围环境,当其选择一个合适的行为时,其对应的Q值增加。为了在一段时间内实现累计回报的最大化,智能体开始采用最优或者接近最优的决策称为π*决策(或者一系列行为),使得智能体能够实现一个最优的Q值,π*决策具体由式2所示。
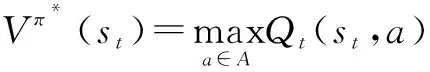
(2)
强化学习拥有不断地探索和利用周围环境的能力,智能体通过选择不同的行为,去探索和学习周围环境,这可能使得智能体获得的瞬时回报较低,但是通过不断的探索和学习,可能使智能体获得较高的累积回报。
2 基于强化学习的分布式智能入侵防御方案设计
2.1 系统模型
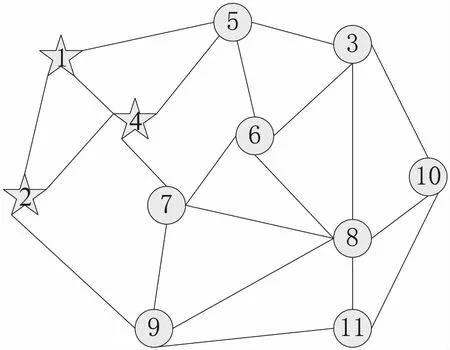
在认知无线网络场景中,一个认知网络可以包含若干个主用户与多个次用户,假设主用户距离认知网络的距离较远,主用户有较强的发射功率,整个认知网络均在主用户的发射范围内。假设在一个感知时段内,主用户的状态与认知网络的拓扑结构均保持不变,即从认知用户开始进行频谱感知到全网达成共识为止。具体的网络模型如图1所示。
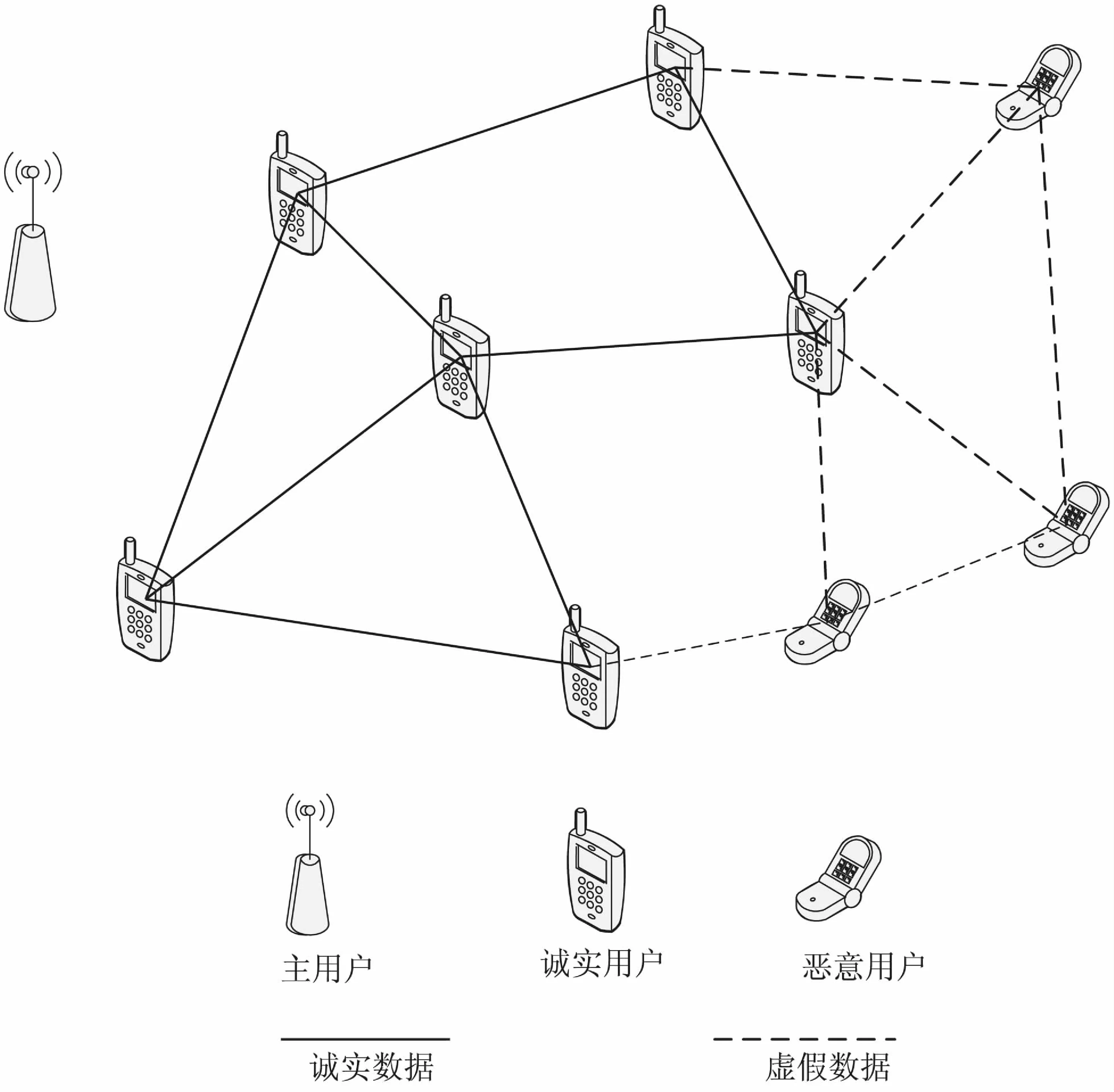
图1 分布式CRN拓扑结构
这里使用一个无向链路图G=(V,ε)表示图1所示的网络模型,其中V={1,2,…,n}表示整个认知网络中的认知用户,ε∈V2表示认知用户间的连通关系,使用矩阵S={bij}来表示各个认知用户之间的连通关系,其中bij∈{0,1}分别表示认知用户i与j是否为一跳可达的。使用Mci={j∈V,bij=1}来表示认知用户i的所有一跳可达用户的集合。
2.2 信誉模型
在分布式网络中,认知用户的信誉值表示认知用户的诚实度[17],信誉值较高表示该认知用户为诚实用户可能性较高,反之则为恶意用户。在分布式场景中,没有融合中心,每一个认知用户视为一个融合中心,与邻居用户进行数据交互,因此融合中心可以选择信誉度较高的邻居用户进行数据交互。
通过信誉值来判别认知用户的可靠性,能够有效地甄别潜在的恶意用户,融合中心收集邻居用户的感知值进行判决。当融合中心判定该邻居用户为潜在的恶意用户时,会给其对应的惩罚,反之给予对应的奖励。在每一次迭代过程中,认知用户的信誉值都会进行对应的更新计算,融合中心选取最优的邻居用户进行数据融合。
2.3 算法流程
文中提出将强化模型与信誉值相结合的防御方案。在该方案中,每个认知用户均视为一个智能体,通过不断地观察和学习其邻居用户,认知用户选取信誉度较高的邻居用户进行数据融合,当认知用户选取一邻居用户进行数据融合时,若该邻居用户未发起恶意攻击,则邻居用户的信誉值会得到对应的奖励,信誉值越高表示该邻居用户越可靠,认知用户可以获得更高的回报,接下来将更加倾向于与该邻居用户进行数据交互,反之信誉值较低的即为潜在的恶意用户。具体的方案流程如图2所示。
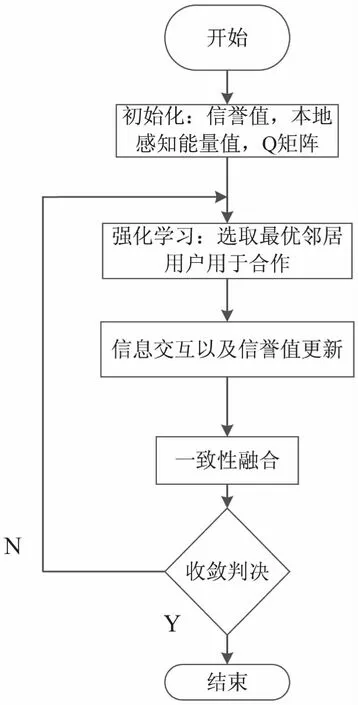
图2 算法流程
认知用户作为智能体,其三个主要组成部分(状态、行为、回报)如下所述:
状态-state:表示认知用户的邻居用户集合;
行为-action:表示通过不断地观测,学习,查询邻居Q矩阵,从邻居用户集合中选取信誉值较高的邻居用户用于后续的数据交互;
回报-reward:回报即信誉值的奖惩rt+1(st,at)∈{1,-1},其中-1表示发送虚假的感知值,1表示发送正确的感知值。
算法步骤如下:
步骤1:初始化。
初始化认知用户的本地感知能量值和信誉值以及Q矩阵,以及计算认知用户的一阶可达邻居集合及其相应的度数。其中i={1,2,…,V},j={1,2,…,V},i与j均表示认知用户,k表示迭代次数。
步骤1.1:每一个认知用户均有一个初始的感知能量值,一个初始的信誉值。
Pi=P0-(10βlog10(ni/n0)+Yi+Zi)
(3)
xi(0)=Pi,k=0
(4)
Ri(0)=R,k=0
(5)
式3中,Pi表示认知用户i感知主用户能量值;P0表示主用户的发射功率;β表示路径损耗因子;n0表示参考距离;ni表示感知用户到主用户间的距离;Yi表示由阴影衰落损失的能量值;Zi表示由多径效应而损失的能量值;式4中的xi(0)表示认知用户i的初始感知能量值,在每一步迭代过程中,xi(0)都会被更新,这里使用xi(k)表示;式5中的Ri(0)表示认知用户i的初始信誉值,这里假设所有认知用户的初始信誉值相同,在之后的每一步迭代过程中,认知用户的信誉值均会被更新,这里使用Ri(k)表示。
步骤1.2:初始化每个认知用户i的一跳可达邻居用户集合Nci(0)以及对应的度数di(0),在接下来的强化学习过程中,认知用户i将从其一跳可达邻居用户中选取最优的认知用户进行数据融合。
步骤1.3:初始化Q矩阵Q(st,at),并且初始值均设置为0。
步骤2:强化学习,选取最优的邻居用户用于后续信息交互。
通过强化学习算法,认知用户选取最优的邻居用户用于后续信息交互,并且甄别潜在的恶意用户。具体的强化学习算法如下:
在每一步迭代过程中,重复进行如下步骤:
步骤2.1:认知用户查询Q矩阵,并观察当前的状态st。
步骤2.2:将st←st+1作为当前状态。
步骤2.3:选取一个行为at并执行,获得瞬时回报rt+1(st+1)。
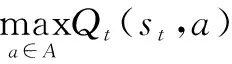
步骤2.5:根据式1更新Q矩阵。
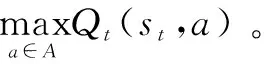
通过步骤2,认知用户选取最优的邻居用户用于合作,然后进行步骤3的信息交互。在信息交互的过程中,通过对恶意用户进行检测,伴随着信誉值的更新计算。
步骤3:信息交互及信誉值更新。
每个认知用户均有一个初始的信誉值,此方案中,将初始信誉值设置为2,在每一步迭代过程中,均会进行信誉值的更新计算,如式6所示:
Ri(k)=Ri(k-1)+(-1)b(k)+bi(k)
(6)
其中,Ri(k)表示认知用户i在第k步迭代时的信誉值;b(k)表示融合中心的判决结果;bi(k)表示认知用户i的判决结果。只有当融合中心与认知用户i的判决结果相同时,认知用户视为诚实用户,给予信誉值加1奖励,否则给予减1惩罚。此方案中选取合作的邻居用户均是信誉度大于2的认知用户。
步骤3.1:bi(k)的计算如下:
(7)
这里假设λ对于所有的认知用户均适用,λ的具体计算公式根据文献[18]可得,如式8所示,ψi(k)的具体计算如式10所示。
(8)
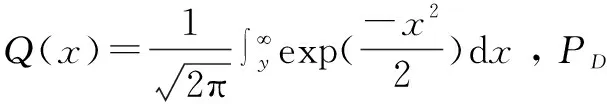
(9)
(10)
步骤3.2:b(k)的计算如下:
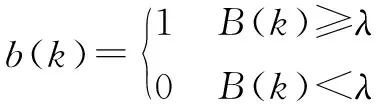
(11)
(12)
其中,D(k)表示信誉度较高的邻居用户集合,此方案中选取信誉度大于2为标准,即
D(k)={j|Rj(k)≥2,j∈Mci(0)}
(13)
yj(k)为信誉值权重,其表达式为:
(14)
(15)
步骤4:一致性融合。
认知用户选取邻居用户中信誉度较高的邻居用户进行数据融合,最终智能的恶意用户放弃恶意攻击,发送正确的感知值。
(16)
步骤5:收敛判决。
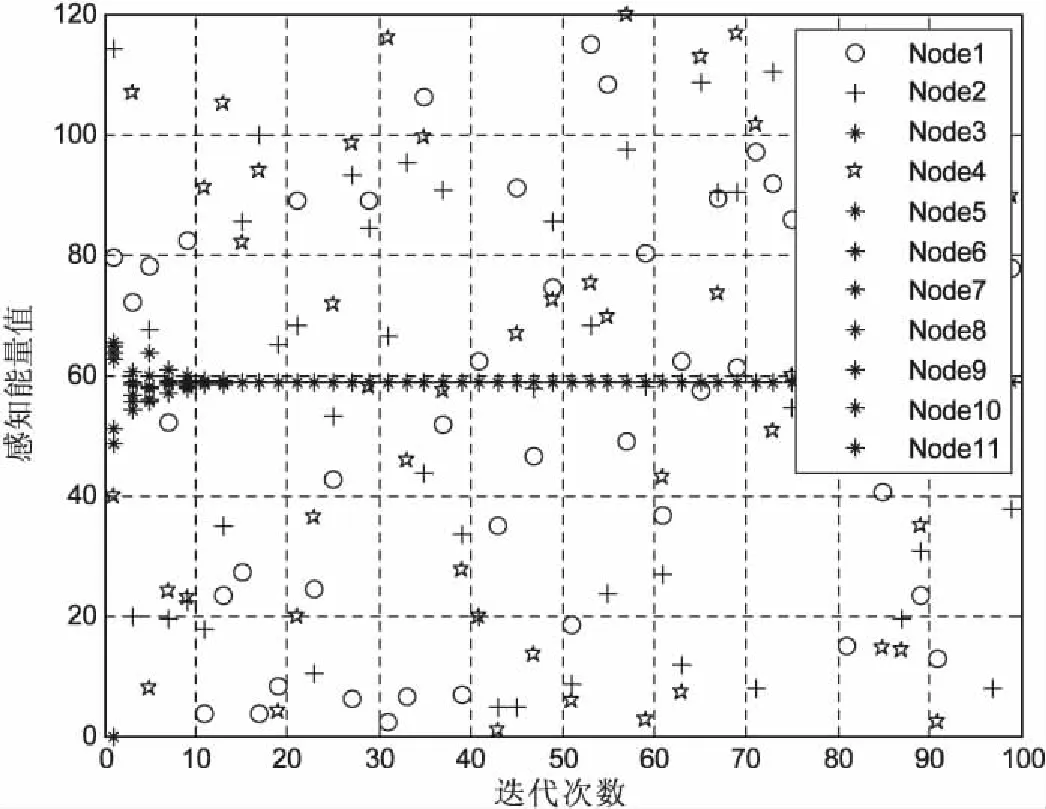
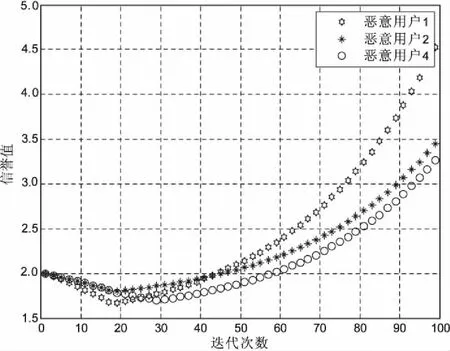
更新迭代次数:k=k+1;当k≥Tm,Tm为预先设置的迭代收敛次数,那么整个感知系统将停止迭代。当k 在信息融合阶段,由于防御策略,迭代次数的影响,系统最终的收敛值与真实值会有一定的偏差,最终收敛值x*为: (17) 其中,N是认知网络中的认知用户数;V是用户集合;xj(0)是迭代结束后的感知值;η是由于安全策略,迭代次数导致的最终偏差值。 文中使用的仿真工具为MATLAB。网络拓扑结构如图3所示,该网络由11个认知用户组成,共有22条链路,其中假设用户1,2,4为恶意用户,攻击方式相同。假设各个认知用户所感知的信道为独立同分布的Suziki衰落信道,主用户发射功率66 dB,相对距离值取为1 km,认知网络到主用户的距离值取为5 km,认知网络的范围选取长和宽均为1 km,各认知用户间可达通信范围值取为300 m,噪声功率值取为-80 dB,阴影衰落参数值取为3 dB,信道损失参数值取为3,每个认知用户的初始信誉值取值为2。最大迭代数设置为100,缓存级数取值为5,一致性融合的收敛阈值取为0.04,感知时长设为0.5 ms,蒙特卡洛值取10 000,每个认知用户的本地感知结果由本地能量感知得到。在该方案中,强化学习的学习速率α为0.4,折扣因子γ为0.6。 图3 认知网络拓扑 文中研究的攻击模型主要有自私型攻击与干扰型攻击两种。恶意用户常见的攻击策略[19]主要有随机性攻击(random attack,RMA)、间歇性攻击(intermittent attack,ITA)、持续性攻击(always attack,ASA)。 假设认知用户1,2,4为潜在的恶意用户,主要对恶意用户发起的随机型攻击RMA,持续干扰型攻击ASA&&IFA,持续自私型攻击ASA&&SFA等三种攻击场景进行仿真比较,且假设恶意用户发起攻击方式相同。 图4表示在恶意用户1,2,4发起RMA的情况下,认知网络的收敛性能。由仿真可见,文中方案能够有效地抵御恶意用户发起的RMA攻击,恶意用户1,2,4被甄别之后,将不让其参与一致性融合过程,可以获得更加可靠的收敛值,具有较低的收敛误差。 图4 RMA攻击场景下,认知网络的收敛性能 图5表示在恶意用户1,2,4发起持续自私型攻击ASA&&SFA的情况下,认知网络的收敛情况分析。由仿真可见,文中方案能够有效地抵御ASA&&SFA攻击,具有较快的融合速率,较低的收敛偏差,极大提高了网络的可靠性。 图6主要比较了恶意用户1,2,4信誉值的变化情况。可见,当恶意用户1,2,4发起RMA攻击时,通过提出的强化学习与信誉值结合方案,能够有效地甄别其恶意行为,因此其信誉值是降低的,当智能的恶意用户开始发送正确的感知值时,信誉值会受到奖励,此时信誉值是增加的。 图6 恶意用户1,2,4信誉值变化曲线 主要研究了在分布式协作频谱感知过程中几种常见的攻击方式,提出一种基于强化学习的分布式智能入侵防御方案。将强化模型与信誉模型相结合,每一个认知用户通过不断地强化学习选取最优的邻居用户进行合作,同时进行信誉值的奖惩,最终智能的恶意用户主动放弃恶意攻击,发送正确的感知值,实现全网共识。仿真结果表明,该方案能有效抵御恶意攻击,极大地提高了网络的健壮性与稳定性。3 仿真分析
3.1 存在恶意攻击仿真分析
3.2 性能分析
4 结束语
猜你喜欢
公民与法治(2022年12期)2023-01-07 09:16:26
计算机应用文摘·触控(2022年8期)2022-05-25 13:27:53
空间科学学报(2021年6期)2021-03-09 06:20:14
华人时刊(2019年13期)2019-11-26 00:54:42
测控技术(2018年7期)2018-12-09 08:58:22
华人时刊(2016年19期)2016-04-05 07:56:08
淮海医药(2015年2期)2016-01-12 04:33:19
无线电通信技术(2015年3期)2015-12-23 11:37:00
党员文摘(2014年11期)2014-11-04 10:42:47
无线互联科技(2014年7期)2014-09-24 00:07:42
