
一种融合贝叶斯概率的社区结构发现方法研究
2019-01-21 00:56:52王刚
计算机技术与发展 2019年1期
王 刚
(安康学院,陕西 安康 725000)
1 概 述
针对社区发现的研究是当前国内外研究的热点之一[1]。社会网络(social networks)是指社会中个人之间、组织之间或者个人与组织之间比较持久、稳定的社会关系模式,通常表示为节点的集合,同一社区节点集合之间的连接较多,如果节点集合之间连接较少,则认为属于不同的社区。研究网络中的社区有助于分析网络行为,对于个性化推荐具有重要的意义。
目前主要的社区发现算法有谱平分法[2-3]、KL算法、层次聚类法、GN算法等。谱平分法由于涉及到许多矩阵特征向量的计算,计算的时间复杂度可达O(n3),在大数据环境中,它的效率成为瓶颈。有研究人员从社会学角度研究了社区结构,研究了人际之间的信任关系及提取[4],对相似度计算方法进行改进[5-6],采取角色连接轮廓方法从结构上进行划分,发现它们属于外围串类型。也有研究人员利用社会网络个体间的关系类别和个体间对应社会属性相似度引入关系模型来进一步量化团队成员个体间的关系强度[7]。此外,还有学者对从朋友关系、距离变化等角度发现社区结构进行研究[8-9]。上述研究能在一定条件和背景下发现成员之间的关系和结构,这些算法注重于网络节点的信息,如出度、入度[10],而对社区结构的动态、不对称、模糊的特性考虑不够。通常认为,结构上临近的节点,应该属于一个社区,而且关系是对称的,即:如果a信任b,那么b就信任a。而实际应用中,考虑到一些具体的关系[11],上述结论不一定有效,如应用GN算法,可能会把边“a→b”作为两个社区的分界线,如果a和b本身属于事件非常重要的成员,把他们分割到两个社区就不合适。因此,结合社区结构的动态、不对称、模糊的特性,探讨一种新的方法很有必要。根据信息熵理论,随着网络节点的扩充,信息量增加,网络蕴含不确定信息的概率就会增加[12]。因此,一个社区内部,由于成员的增加,出现不确定性信息的概率应该增加,熵就增加,反之,则减少。一个社区内部,由于信息交流频繁,表现为一个稳定的综合体,不确定信息出现的概率不会剧烈增加或减少,这使得根据节点集合熵的变化来确定不同的社区成为可能。判断一个节点是否属于一个社区,可以通过判断节点加入社区后社区熵的变化来确定。
对于确定节点a、b之间关系的紧密程度,有许多方法,如计算余弦相似度、皮尔逊相似度系数等。通常的相似度计算方法不能很好地解决应用数据的动态模糊性,而贝叶斯概率在描述个体之间关系的动态和模糊性方面有一定的优势,因此文中提出了一种融合贝叶斯概率和熵的社区发现算法,并将其与余弦相似度计算方法进行比较。
2 信息熵及贝叶斯网络的建立
2.1 信息熵
1948年,香农第一次将熵这一概念引入到信息论中,从此,熵这一概念被作为信息的度量,在自然科学和社会科学等领域应用广泛,并成为一些新学科的理论基础[13-14]。当一种信息出现概率更高的时候,表明它被传播得更广泛,或者说,被引用的程度更高。
一个信源发送出什么信息是不确定的,衡量它可以用其出现的概率来度量,信息熵概率公式表示为:
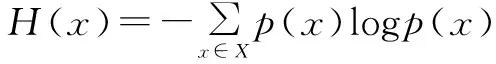
(1)
其中,x表示随机变量,与之相对应的是所有可能输出的集合,定义为符号集H(x);p(x)表示输出概率函数。
信息熵用来度量系统的有序化程度,一个系统越是有序,信息熵就越低,系统越是混乱,信息熵就越高。
2.2 贝叶斯概率与贝叶斯网络的生成
贝叶斯概率是由贝叶斯理论所提供的一种对概率的解释,它将概率定义为主体对一个命题的信任程度。贝叶斯网络通常表示为有向无环图,刻画一组变量的联合概率分布,每个变量在贝叶斯网络中表示为一个节点,网络弧表示断言“此变量在给定其直接前驱时,条件独立于其非后继”,当Y到X存在一条有向的路径,称X是Y的后继。对每个变量有一个条件概率表,表示该变量在给定其立即前驱时的概率分布[15]。贝叶斯法则提供了计算假设概率的方法,提供了从先验概率p(h)以及p(D)和p(D|h)计算后验概率p(h|D)的方法。
贝叶斯公式表示为:
(2)
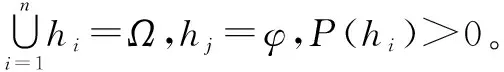
当前推荐系统通常采用关联规则挖掘方法,可能产生大量的序列模式。序列模式只是项集(Item set)的简单组合,依据支持度和可信度进行剪枝,而支持度和可信度依据项的个数计算得来,这样有些序列模式可能被认为毫无意义而被剪枝,如因果关系。由于刻画项之间深层关系存在的局限性,由于没有达到支持度阈值而被剪枝,而项之间的因果关系是非常重要的关系,不能简单凭借数量来判断,应该根据概率来判断是否剪枝。
[15] Hasan Alwi, Dendy Sugono, Politik Bahasa:Rumusan Seminar Politik Bahasa, Jakarta: Pusat Bahasa, 2003, pp. xii-xiv.
贝叶斯概率在描述事件因果关系方面具有优势,所以采用贝叶斯条件概率来描述项之间的概率关系,依据概率的大小,寻找社区中的项集合,这样就能发现和挖掘项之间的因果关系,并用于推荐系统中,从而克服其他方法的局限性。
以商品推荐为例,利用算法1构建了用户贝叶斯关系网络图,它以用户为节点,节点之间的边表示用户之间的贝叶斯关联概率,形成的有向图如图1所示。
图1 用户关系边有向图
算法1:生成贝叶斯关系网络有向图。
Begin:
(1)一条记录包含多个商品,构成节点U={Ui},Ui={gk}

End
3 社区结构的发现
社区内各要素的内部及其相互间具有相对稳定的关系,个体成员之间因为互动而形成相对稳定的结构,由于蕴含有的共同信念和意愿,成员之间表现出强的趋一性。根据熵理论,由于系统的稳定和凝聚性,新的信息加入会对原系统的熵造成波动,如果新加入的节点与原系统能融入在一起,或接近度比较高,熵值的波动就较小,否则熵值的波动就较大。可以根据熵值的变化程度来决定新加入的节点是否被系统接纳。该算法随机确定一个节点为栈顶,建立一个栈,采用递归的思想,根据节点加入时熵值的变化,用阈值进行剪枝,超过阈值的节点不会加入到已有社区集合,满足条件时结束递归,输出产生的社区。
Begin
(1)k=0
(2)建立节点堆栈S
(3)确定栈顶U0,U0可以随机选取
(4)选取U0的邻节点{Uk}
(7)输出标记为True的边E(H0,Hk)
(8)k=k+1,选取标记为False的边节点Hk,作为栈顶,转步骤3,直到所有节点标记完成或社区数满足要求
End
算法采用堆栈的形式遍历了关系网络图,属于一个社区的边进行了标记。算法可以发现不能划分到社区的孤立点,对应到事件集合中的某些离散值独立的事件。算法在实际运行过程中能够发现满足要求的社区。
4 实 验
实验对上述算法的正确性进行测试,同时展示发现的社区结构,并与其他算法进行比较,展示该算法的有效性。
实验选取图书馆图书借阅记录10条,每条记录包括借阅人员的学号,专业,借阅书籍类别。利用算法1计算出读者之间的关系矩阵,矩阵的值Uij为有向边Ui→Uj之间的条件概率,可见Uij不一定等于Uji,如图2所示。

U1U2U3U4U5U6U7U8U9U10U110.20.40.10.40.50.30.10.20.5U20.7510.50.250.750.50.750.7500.75U30.570.2810.140.570.5700.280.140.14U40.20.20.210.20.400.200.4U50.570.430.570.1410.570.430.280.140.57U60.630.250.50.250.510.250.130.250.5U70.380.38000.380.2510.130.380.38U80.250.750.50.250.50.250.2510.50.25U90.6600.1700.170.330.50.3310.17U100.630.380.130.250.50.50.380.250.131
图2 用户关系矩阵
把信息熵的阈值设置为0.5,发现的社区结构如图3所示。

图3 基于信息熵变化发现的社
由于不具有出入度的特征,所以不能根据出度、入度来发现社区结构。
相似度计算方法也是发现社区结构的一种常用方法。为便于对比研究,文中选用余弦相似度计算方法来发现社区结构。采用与方法1同样的数据,该方法采用余弦相似度计算出节点之间的相似度,并根据相似度大小发现社区结构,如图4所示。

图4 基于余弦相似度的社区结构发现
从两种方法发现的结果来看,两种结果存在一些共同点,也存在一些差异。两种方法都发现了U2,U5,U6,U10属于一个社区,方法1发现U1,U3与U5,U6,U10属于一个社区,不同之处在于,方法1发现的社区结构是有向图,方法2发现的结构是无向图。在实际生活中,有向图显然具有更好的科学性,描述的信息更准确。如图3中,U5到U6有一条有向边,而U6到U5没有有向边。本实验中,如果U5发生,U6发生的概率为0.57,图3无法描述这些信息。所以方法1具有较大的优越性。方法2之所以没有发现U1,U3,是因为彼此之间相似度较低,而方法1计算的是彼此之间的概率,所以被发现的可能性较大。
从两种方法对比来看,方法1能够发现更有价值的社区结果,同时对成员之间的关系进行描述,方法2不能做到这点。
5 结束语
提出的方法既能发现社区结构,也能发现社区内成员之间的动态模糊关系,这里用贝叶斯概率来描述成员之间的关系,采用了信息熵变化趋势来发掘社区成员。现实中,社区成员之间的关系有很多,如关联关系、因果关系、相反关系等,深入发掘这些关系并用于个性化推荐系统尤为重要。文中只用余弦相似度进行了对比,对该方法进行了改进,还需要与其他相似度计算方法进行对比。所用的样本记录远称不上大数据,在大数据环境下该方法表现如何有待进一步探索。根据熵的变化判断成员是否属于一个社区,熵阈值确定很重要,如何确定更好的阈值,使得发现的结果有更好的可用性,也是目前所有社区发现方法面临的问题。
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05 06:49:10
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
中学生数理化·中考版(2021年6期)2021-11-22 07:52:30
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
电子测试(2017年12期)2017-12-18 06:35:48
数理化解题研究(2017年4期)2017-05-04 04:07:54
雷达学报(2017年6期)2017-03-26 07:52:58
铁道通信信号(2016年6期)2016-06-01 12:10:20
池州学院学报(2015年3期)2016-01-05 01:13:00
