
智慧物流分布式计算模型与创新服务研究
2019-01-19 08:26焦凯琳于自强
计算机技术与发展 2019年1期
焦凯琳,于自强
(1.济南市图书馆,山东 济南 250001;2.济南大学 信息科学与工程学院,山东 济南 250022)
1 概 述
“十三五”时期是信息技术变革的突破性阶段,在经济发展进入新常态的形势下,传统物流已难以满足业务多元化、运营规模化、管理数据化的要求。随着信息获取技术和数据感知技术的快速发展,物流行业所涉及的货物流转、车辆追踪等相关数据规模急剧增长。2008-2014年,中国快递量从15.13亿件迅速激增到135.59亿件,年复合增长率达36.79%,每一件快递的背后都隐含着大量数据。Avent公司全球运输副总裁Marianne McDonald表示,“每一桩运输交易都会生成超过50列的数据,以及超过2.5亿的数据值”。预计未来五年,中国物流大数据市场规模年增速将保持在40%左右。随着云计算[1]、物联网[2]、深度学习[3]等大数据处理技术和海量数据分析技术的蓬勃发展,许多领域的数据处理技术和应用服务发生了深刻变革[4-5],如何对物流行业的海量数据进行高效管理和深度运用,通过挖掘物流行业大数据的潜在价值,解决传统物流所存在的问题和自身瓶颈,实现物流行业的新旧动能转换,推动传统物流向智慧物流转型已成为现代物流行业发展的一个必然趋势。
当前,物流行业的信息化管理已经引起国内外相关行业的广泛关注[6-7],涌现出大量的物流信息管理平台。这些平台包括电商物流平台、区域配送平台、行业物流平台、供应链物流平台、公路货运信息平台、物流金融服务平台及在线仓储平台等。物流平台种类繁多,目前已经搭建并逐步完善的物流平台是电商物流信息平台。2013年5月阿里集团与金融机构及十余家快递公司共同投资成立“菜鸟网络科技有限公司”,旨在通过这个物流大数据信息平台实现淘宝、天猫商品全国24小时送达。
目前,国内物流信息管理平台在提高运力、节省成本方面取得了一定成效,能够对一些物流数据进行管理,但是缺乏以数据为导向的管理和服务模式,对海量物流数据的萃取和使用能力明显不足。例如,“四通一达”(申通快递、圆通速递、中通快递、百世汇通、韵达快递)合计约占快递行业市场份额的80%,但是对于大数据信息技术的研发和利用极为有限。面对当前每天1亿个包裹的运送量,很多物流企业库存高起、运力效率低下的问题日益显现。
针对当前物流行业在数据萃取和利用方面的不足,着眼未来规模更加庞大的物流数据所引发的技术挑战,文中将深入探讨海量物流数据的处理和利用,提出一种基于分布式服务器集群的海量物流数据存储和计算的平台架构,主要研究货物信息、承载状态、运输轨迹、GPS数据、用户信息等多种物流数据的快速接入、实时计算、高效存储和深度挖掘方面的问题,探索海量货物运输共享、运输路线动态规划、货物派送优先级计算以及对任意物品的实时查询追踪等创新性服务的数据处理技术,最终形成一个包含底层数据存储分布式存储平台、中间层实时计算模型和挖掘分析算法以及上层创新性应用服务的面向智慧物流的海量数据解决方案。
2 海量物流数据分布式存储和计算平台
物流行业中每一件货物的运输将产生文本数据、位置数据、运输工具的GPS数据、当前路况的拥堵数据、导航数据、货物的状态信息等若干类数据,要想对这些数据进行分析和利用,首先需要构建海量数据分布式存储和计算平台,实现对大规模物流数据的高效管理。该平台架构如图1所示,主要包含四个模块,即数据采集与并发接入模块、海量数据存储分析模块、流数据实时处理模块,以及自适应“双级”计算引擎。
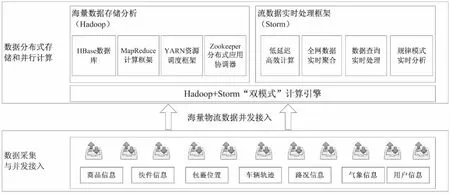
图1 海量物流数据分布式存储和计算架构
2.1 数据并发接入模块。
为实现可共享运输货物的实时匹配以及任意时刻任意货物状态的实时查询等功能,必须将每件货物所涉及的各种数据实时接入数据平台。当每天有上亿件包裹连续产生数据时,就相当于有上亿个数据源不断产生数据流,而传统技术难以实现对如此大规模数据流的实时接入。为此,基于分布式消息队列设计海量物流数据的高速并发接入模块。首先,数据并发接入模块的分布式架构利用多组队列同时接入数据,相互协同工作,并根据各队列负荷情况动态调整接入能力,自动分配更多队列接入海量数据,使整个接入层在应对海量数据接入时发挥最大接入效能。个别队列出现故障后会有其他队列替代,不会出现数据丢失,保证接入层的稳健性。其次,数据并发接入模块中的分布式消息队列充分利用操作系统自身缓存“写穿”和磁盘顺序写入的高效性,将所有接收的消息顺序写入磁盘,既允许消息持久化存储,又保证消息的效率读取和内存存取一致,超越硬盘读取速率几个数量级,保证接入的实时性。最后,引入数据跟踪反馈机制,如果消息队列中的每条数据被成功处理,该队列会收到一个确认反馈,然后永久删除该数据;否则,该队列将从硬盘中读取该数据,放至当前队列的末端,等待重发,以保证每条数据至少被处理一次。
2.2 海量数据分布式存储模块。
要想实现对海量物流数据的深入分析,首先需要对这些数据进行高效存储和管理,为此,设计了基于服务器集群的海量数据分布式存储模块。该模块主要采用Hadoop系统中的HDFS文件系统和HBase数据库[8-9],实现对物流数据中文本结构化数据和图片、视频等非结构化数据的有效存储。HDFS是一个分布式的、可扩展的、可移植的文件系统,构建于Linux所使用的普通文件系统之上,分布式特性使其能够利用集群内各节点联合的存储能力,将数据存储由TB级别提高到PB级别。在该平台中,HDFS作为海量数据最底层的存储组件,能够为上层模块和组件提供统一的数据存取接口。HBase是一个分布式列存储数据库,以HDFS作为底层文件系统,为海量数据的管理提供了易于理解和操作的手段。与传统的关系型SQL数据库的行式存储有很大不同,HBase的列式存储易于分块进而易于并行化分解和查询,能够达到几亿条/秒的快速数据查询、检索速度。HBase的分布式特性使其具有极强的扩展性,存储能力和检索速度随着硬件的增加而线性增加。
2.3 流数据实时处理模块
为了支撑物流信息实时查询等功能,许多物流数据需要被实时处理,为此,该平台引入了分布式流数据实时处理模块。该模块采用Actor-Model模型[10-11],可以部署在多服务器组成的集群之上。该模块由若干个逻辑处理单元(PE)组成,每个物理节点可根据自身负载运行任意数目的PE。PE之间通过发送和接收Event的形式进行数据传输。每个Event可以表示为一个三元组
2.4 “双模式”计算引擎
该平台作为海量物流信息处理的底层平台,需要支撑上层多种智慧物流的相关业务,这些业务既包括一些涉及批数据处理的分析研判业务(例如根据历史数据分析和预测一个物流公司未来一段时间的业务量),也包括一些与数据实时处理相关的查询跟踪业务(例如查询一件包裹的实时位置和移动轨迹)。由于上述业务所涉及的数据处理模式不同,不同业务的数据处理需要在不同数据模块之间切换,导致计算复杂性增大。为此,该平台设计了批处理计算模式和流处理计算模式相统一的“双级”计算模式。该计算引擎通过大数据的分割与备份技术,实现数据并行访问,同时保证多点失效情形下的数据安全。“双模式”计算引擎将批处理计算模式(MapReduce)和流计算模式集成于同一个计算模型,对上层提供统一的计算接口,并隐藏层内的实现细节。层内需要将上层用统一计算接口实现的计算任务重写并判断应该用两个引擎中的一个或者两个全用来处理这个任务。重写主要是将统一计算模式提供的scatter()和gather()基本原语重写为map()、reduce()(批处理计算模式)或emit()(实时流处理计算模式)。图2(a)和(b)是批处理计算模式和流处理计算模式各自的计算过程。图2(a)所示的MapReduce任务是一个二层结构,第一层是通过map()原语将任务分散到各个Mapper节点并行处理,第二层是通过reduce()原语将中间处理结果收集到Reducer节点合并后将结果输出。图2(b)所示是一个流计算任务,流计算的基本处理单元是PE,PE间不限层数,通常根据任务来确定流向。PE和PE之间的信息交互原语是emit()。
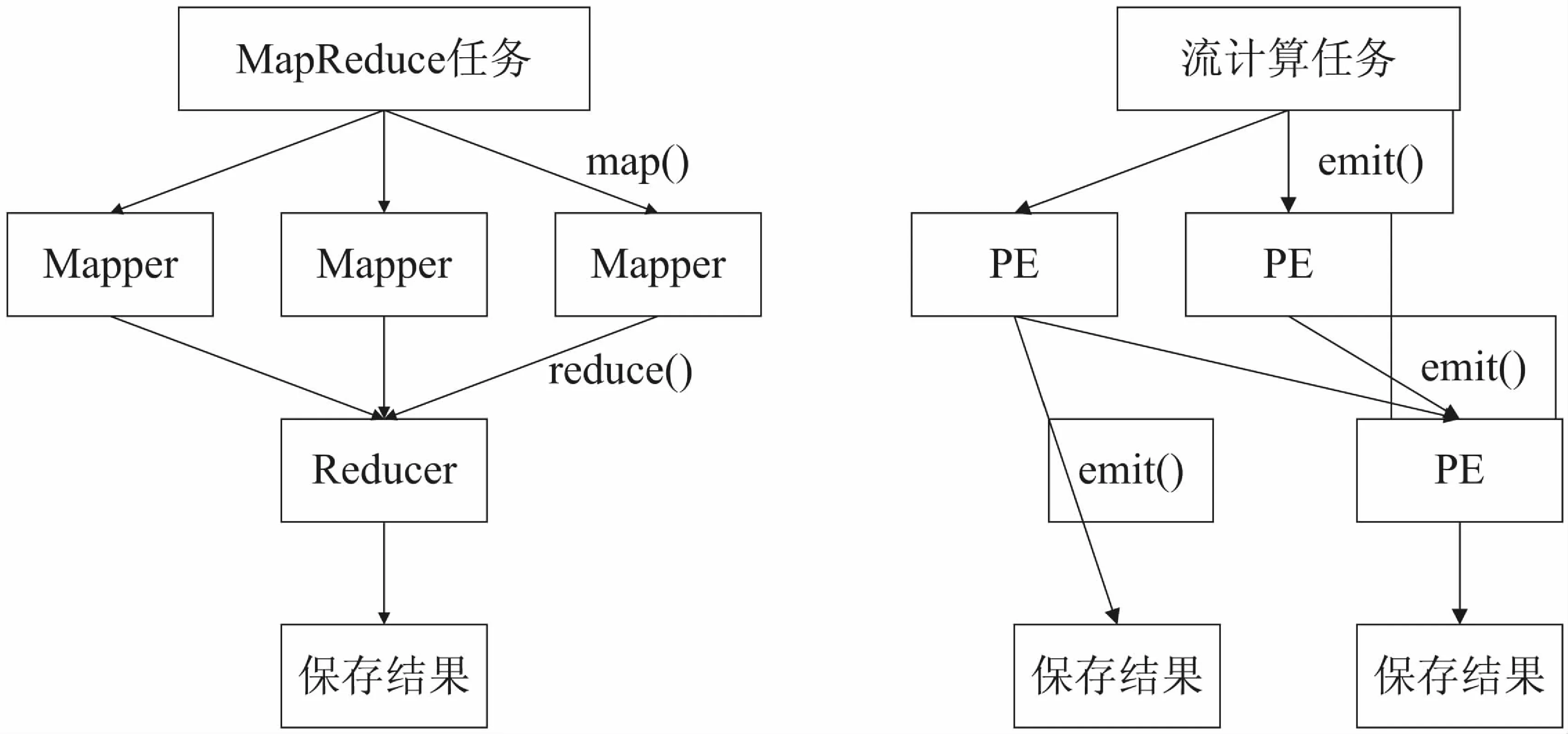
(a)MapReduce任务重写 (b)流计算任务重写
3 面向智慧物流的创新应用服务
基于底层海量物流数据分布式存储和并行计算平台,文中拟构建“海量货物共享运输策略”、“海量物流包裹位置的实时查询技术”及“包裹派送优先级计算问题”等创新物流服务,并设计出构建各项服务的技术路线,智慧物流创新服务技术框架如图3所示。
3.1 海量货物共享运输策略
“互联网+物流共享”是智慧物流的一个重要研究领域。然而,目前的物流现状是众多物流公司货物运输通常由自己的运输网完成,而物流公司之间很少共享运输网络,以至于相同区域某段时间内一些物流公司的运力闲置,而另一些公司的运力不足。此外,当物流公司A需要将一批货物从S1运送到D1,而物流公司B打算将一批货物从S2运送到D2,如果两组地点满足S1→S2→D2→D1或者S1→S2→D1→D2等关系,两批货物则可以由一家物流公司承运,以减少运输成本。为解决类似问题,该课题将研究面向海量货物的共享运输策略,将任意货物表示为pi(Si,Di),该问题就转化为相似轨迹的最大分类问题,即尽可能地将可以共享运输的货物分为一类,从而减少总的运输代价。该问题为当前聚类方法[12]提供了很好的应用场景。针对该问题,文中提出了货物运输轨迹相似性的启发式分组算法。该算法首先在整个运输区域上建立不同粒度的包裹运输路线索引(ML-Index),如图4所示。
当平台接收到一个待分配的包裹时,则根据该包裹的运输轨迹,将其添加到ML-Index。当运输车辆信息在该平台时,则根据该车辆设定的起点和终点计算该车辆的运输轨迹,然后根据ML-Index索引结构,查找与车辆运输轨迹较为相近的物流包裹,并将物流包裹分配给该车辆。此时,ML-Index的作用是为查找相似轨迹提供不同粒度的索引,便于设计多层剪枝策略,从而迅速缩小搜索区间,提高查询效率。当ML-Index中某个起点和终点相似轨迹的包裹数量达到某个阈值后,而平台现有的运输车辆信息与该组包裹轨迹不匹配时,平台将会向管理人员发出运送请求,安排单独车辆对该批包裹进行运输,从而保证包裹运输的即时性,避免造成运输延误。
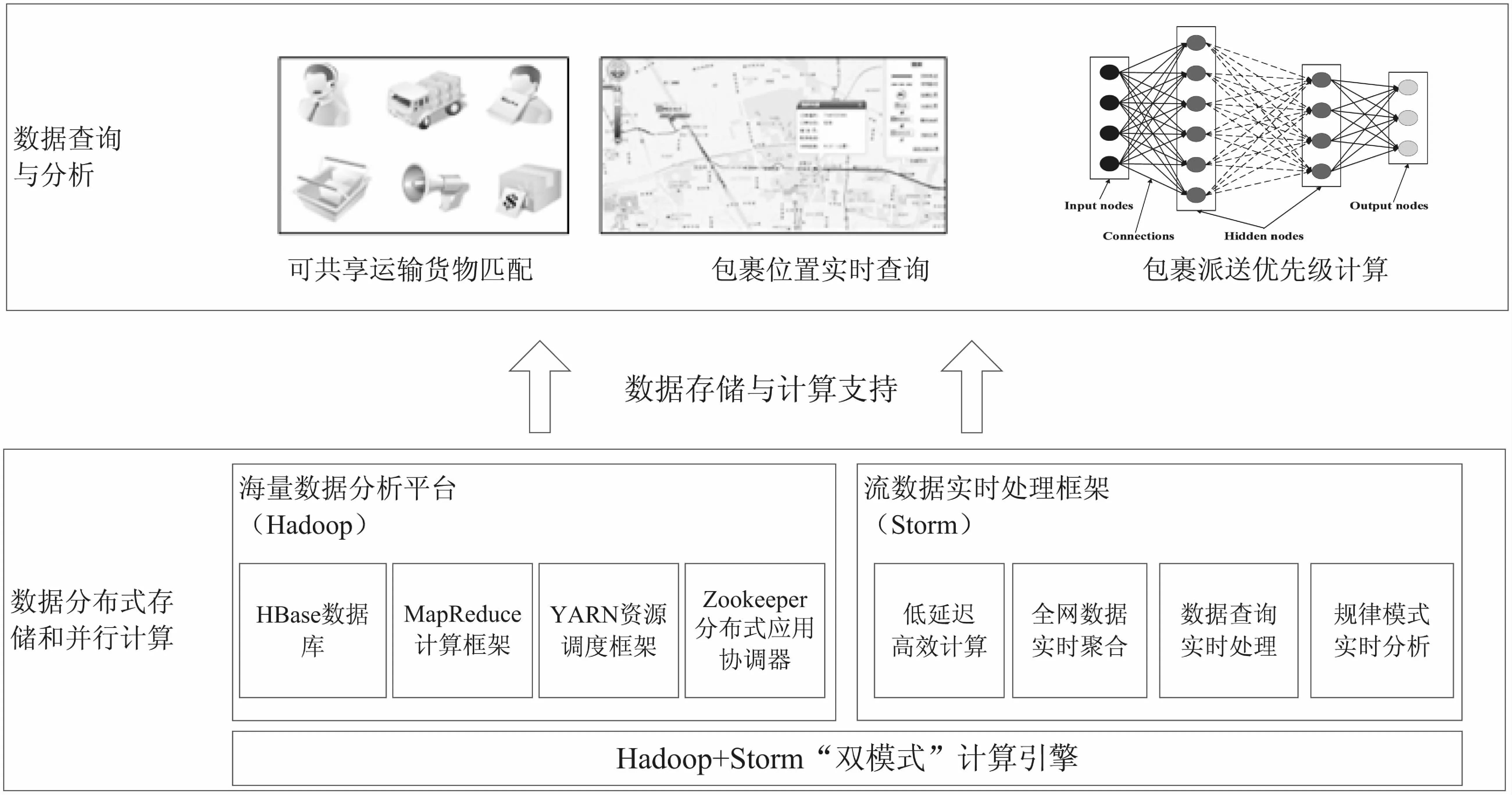
图3 智慧物流创新服务技术框架
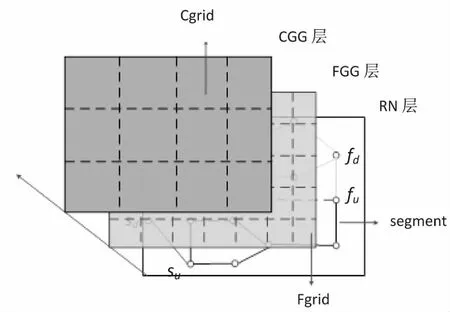
图4 ML-Index索引架构
3.2 海量物流包裹位置的实时查询技术
为实现物流包裹位置的实时查询,首先设计海量包裹位置的索引结构。由于该项目的数据存储平台是基于多服务器集群的分布式存储系统,传统的基于单机的数据索引技术难以解决该项目海量数据索引的需求。因此,提出面向海量物流数据的分布式索引技术,主要包括针对包裹、商品结构化数据的倒排索引,针对包裹位置、车辆轨迹等时空数据的R-tree索引,以及两种索引结构之间的关联索引机制。
具体来说,该课题所设计的海量物流数据分布式索引结构(logistics data index,LDI)(如图5所示),底层是基于多数据节点数据存储模式,每个数据节点中存储着大量的商品、运输工具等信息构成的结构化数据,以及包裹和运输工具的位置、轨迹数据,而且这两种数据存在对应关系。对于商品、运输工具等信息构成的结构化数据,LDI对其建立倒排索引,能够快速得到用户查询的包裹信息;对于包裹和运输工具的位置、轨迹数据,LDI通过R-tree对其建立索引,能够快速得到某个包裹当前的位置信息。基于LDI分布式索引结构,当提交商品位置查询后,平台基于LDI的倒排索引能够快速找到与用户查询商品对应的包裹,然后根据LDI的关联索引,得到该包裹与其运输工具在R-tree的位置信息,实现对查询的实时响应。
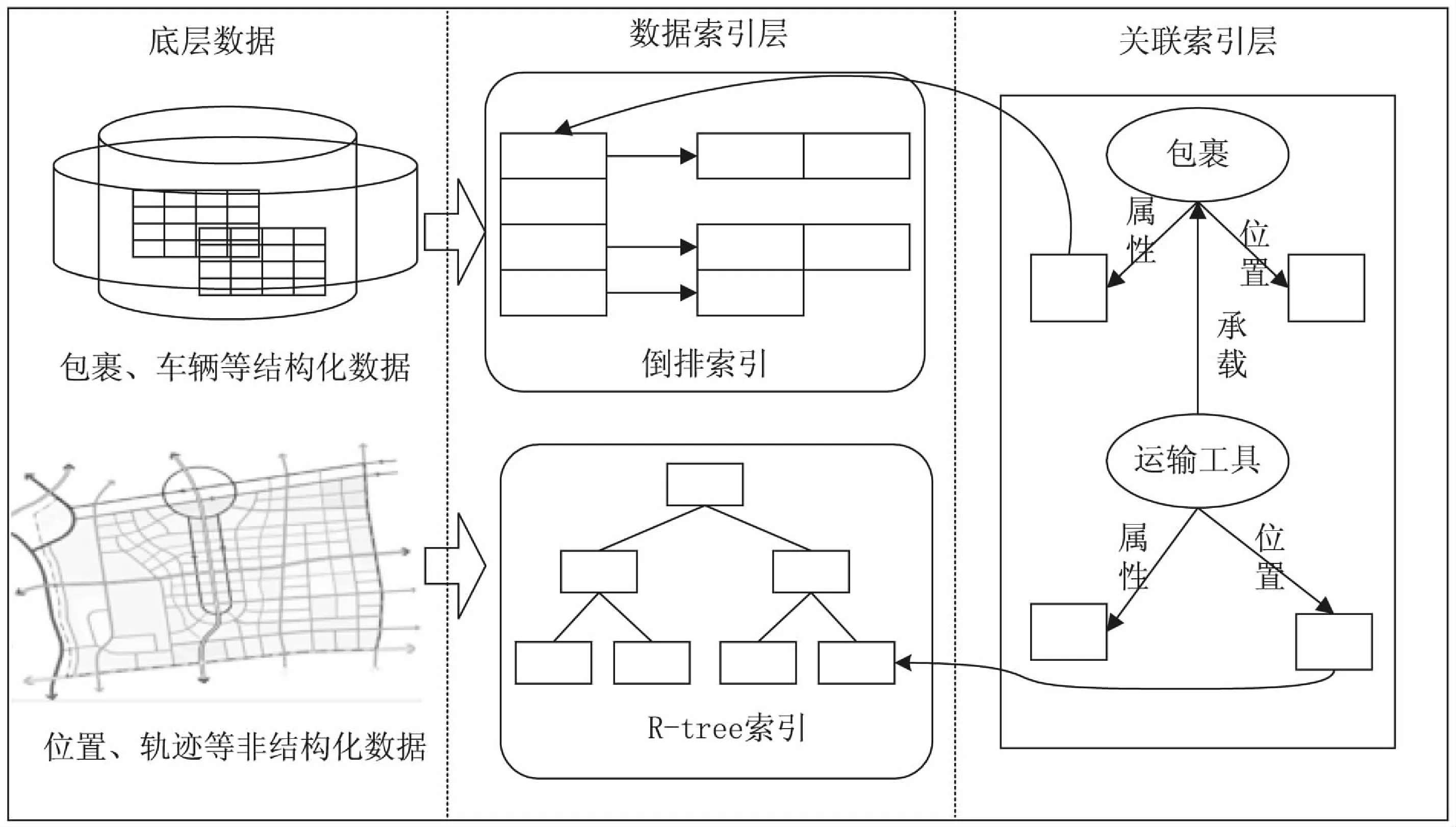
图5 LDI索引架构
3.3 包裹派送优先级计算问题
现实中一个有趣的问题是当快递员以尽可能少的时间将一个包裹送达后,正好赶上客户外出,便由客户小区的门卫代收。而该包裹的物品并非客户急需,以至于客户在5天后才从门卫处取走快递。该现象反映的一个问题是不同用户对接收包裹的渴望程度并不相同,这就表明可以为每个包裹设置不同的派送优先级。派送优先级越高的包裹,则对其优先派送。例如,对于用户非常迫切收到的包裹,可以给它设置一个较高的派送优先级,使用户能够尽快收货;而对于一些用户并不着急接收的包裹,则可以设置一个较低的派送优先级,适当地延后派送,既可以减少快递员的工作强度又不会影响用户体验。
这里,如何为每一个包裹计算派送优先级是一个极为复杂的线性回归问题,需要考虑商品的属性、用户评价记录、天气状况等诸多因素。为此,文中研究了基于深度学习模型计算不同包裹的派送优先级。在该方法中,首先通过对包裹派送的历史数据进行标注,生成训练集。训练集中每条数据格式为
4 结束语
围绕海量物流数据的快速计算和智能分析这一核心课题,提出了应对大规模物流数据的分布式存储和实时计算的底层平台,研究了面向智慧物流的多项创新性服务及其涉及的关键科学问题,即大规模货物的运输路线共享问题、海量物流包裹位置的实时查询追踪问题,以及极具特色的货物派送优先级计算问题,并给出了具体的技术路线。下一步,将根据相关技术路线实现一个完整的海量物流数据计算与应用平台,为智慧物流的相关研究提供可借鉴的平台架构和技术路线。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
电气技术(2022年8期)2022-08-20
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
导航定位学报(2022年2期)2022-04-11
军民两用技术与产品(2021年5期)2021-07-28
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
软件(2020年3期)2020-04-20
当代陕西(2019年14期)2019-08-26
中学数学杂志(初中版)(2016年5期)2016-11-01
