
数据清洗技术在DICOM格式医学图像质控中的应用
2019-01-17 02:38:46郝烨唐桥红李佳戈王浩孟祥峰任海萍
中国医疗设备 2018年12期
郝烨,唐桥红,李佳戈,王浩,孟祥峰,任海萍
中国食品药品检定研究院 光机电室,北京 100050
引言
人工智能的发展[1-2]对数据集提出了强烈的需求,推动了医学数据的大规模开发。由于不同机构、组织自发的数据采集和信息录入缺乏可比性,数据采集过程中容易引入不唯一、不完整、不正确的不可用数据[3]。为了保证数据质量,有必要在数据录用前对数据进行预筛选或预评价,其中的关键步骤之一是使用数据清洗技术剔除不可用数据。由于医学数据的形式极其丰富,数据清洗技术需要针对不同数据类型和不同问题进行开发[4]。
除了数据质量之外,患者隐私保护也是数据清洗关注的重点内容。国内外法规对于患者隐私保护的要求均非常严格,不仅关系到医疗器械研发、临床研究的合规性,也影响生产、经营与研究的合法性,而医学数据难免记录患者隐私信息,这需要进行有效的脱敏与确认。
在众多医学数据格式之中,医学数字图像通讯协议(Digital Imaging and Communications in Medicine,DICOM)格式在数据清洗方面具有代表意义,是本文研究的重点。DICOM标准是广泛应用于放射医疗领域(X射线、CT、核磁共振、超声等)的医学图像国际标准,是医学成像设备中部署最广泛的标准之一。现阶段,大部分医学图像数据的分析及应用都建立在DICOM标准基础上[5],针对DICOM图像的数据清洗技术是对医学图像进行数据分析及应用的基础。本文介绍了对DICOM格式的CT图像进行预处理和清洗的流程设计和实践经验,包含伦理确认、数据质量的确认和隐私保护等内容,以期引起对清洗环节的重视,并对相关医学图像数据的管理和质控工作起到借鉴和规范作用。
1 背景介绍
1.1 患者隐私保护相关法规
数据清洗技术在生物医学领域中的应用与其他环境中有所不同,主要是医学图像不同于其他信息,其中涉及患者隐私等诸多伦理问题。因此,开展基于医学图像的数据研究和分析必须首先关注数据是否脱敏,是否符合相关法律和条例规定。我国目前尚无成熟法案专门规定患者隐私相关内容,但是在原卫生部、原国家食品药品监督管理局、原国家中医药管理局2012年联合公布的《医疗机构从业人员行为规范》[6]中明确说明了“尊重患者隐私权”等。
在国际上,1995年欧盟通过了《个人数据保护指令》针对个人数据采取统一立法模式,后来被2018年5月25日生效的《通用数据保护条例》取代。《通用数据保护条例》对个人数据、与健康相关的数据等概念都给出了明确定义,并对公共健康领域内如何在保护数据主体权益的情况下开展研究作出了详细说明。
为了保障患者隐私问题,促进国家在医疗健康信息安全方面电子传输的统一标准,美国国会在1996年颁布了 《健康保险可携带性与责任法案》(Health Insurance Portability and Accountability Act,HIPAA)[7],旨在为各种医疗机构及商业合作者提供病人隐私保护方面的行动指南。法案中规定,对于去除特定标识的健康信息数据便可以自由使用不受限制[8-9]。基于HIPAA法案及国内外相关规范中的隐私规定,我们在数据清洗时对患者ID 等可能被用来识别到个人的隐私信息进行了提取和查验,以保证数据的合规性。
1.2 DICOM标准介绍
DICOM标准,是美国放射联合会和美国国家电子制造商协会联合制定的[10],目的是为了解决由于医疗设备厂家不同带来的通讯困难等问题。现在国际通用的DICOM标准是3.0版本,于1993年正式发布。
DICOM标准详细规定了传输医学影像及其相关信息的交换方法和交换格式。DICOM的文件组织是按照患者、研究、序列和图像四个层次进行的[11]。在DICOM文件中最基本的单元是数据元素。DICOM数据元素主要由四部分组成:标签、数据描述、数据长度和数据域[12]。DICOM中对应的所有数据元素都可以通过标签来唯一标识,DICOM中人为将标签分为两个部分:组号和元素。标签和元素的对应关系可以通过查阅标准来描述。数据描述用以说明数据对应的类型,数据长度指明数据的字节数,数据域则包含了该数据元素的数据。数据具体格式如图1所示。

图1 DICOM数据的具体格式
在DICOM格式的CT图像中,许多数据信息都可以在文件头中表示,共包含四级属性,患者、检查、序列、图像。比如:患者信息主要包含患者姓名、患者ID等个人信息,检查信息主要包含该检查的ID、时间、类型、部位等信息,序列信息主要包含该图像序列的识别码、图像方位、层间距、层厚等信息,图像信息主要包含图像的标识码及图像采样率等基本信息。
在针对DICOM文件头的数据清洗过程中,主要是读取患者数据确定数据是否完成脱敏,是否合规;读取检查和序列的识别码确定图像的唯一性,通过图像的标识码判定图像是否连续完整,此外,通过读取层厚、层间距等信息基本可以确定图像的质量并加以筛选。涉及的主要Tag见图2。
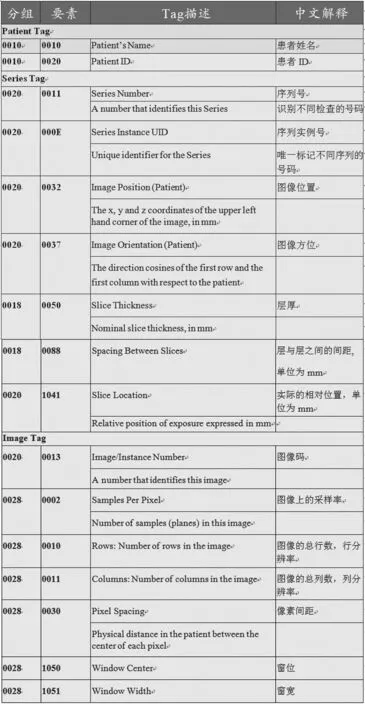
图2 DICOM文件数据清洗中关键标签及释义
2 数据清洗方法与应用
2.1 清洗目标的设定
数据清洗首先应设立清洗目标,明确数据的完整性、有效性和正确性如何体现[13]。在医学影像领域,数据清洗的常见目标包括以下几点:① 对图像的可读性、唯一性进行筛选,去除不完整、不唯一的图像;② 对质量差的或者不满足临床诊断要求的图像进行剔除,比如全黑图像或者层间距过大或过小的图像;③ 对患者隐私信息进行提取和检查,确保图像的合规性。
2.2 清洗方案设计
数据清洗一般来讲就是根据清洗目标,去除各种不合规或质量不达标数据[14]的过程。简单来讲,数据清洗过程可分为以下几个步骤:① 对伦理批准情况进行确认;② 针对要避免的数据质量风险明确清洗规则;③ 根据数据情况及清洗规则,制定清洗流程;④ 对清洗流程进行评估与验证;⑤ 输入原始数据,完成清洗;⑥ 清洗后的数据审核及确认。
将数据清洗技术应用于DICOM格式医学影像时,除了考虑最基本的DICOM图像的合规性、可读性、连续性、唯一性等基本指标外,还应该根据数据集建设的需求,对DICOM 3.0格式的医学图像质量进行细化规定。
2.3 应用实例
以下用肺结节医学影像数据集为例,介绍图像清洗的具体操作。
参照国际竞赛和研究经验[15],肺结节产品研发使用的医学影像数据集经常采用DICOM 3.0格式的肺部CT图像,为了提升数据质量,数据清洗过程中除了保证数据的合规性、可读性、连续性和唯一性等基本指标外,还应重点考虑CT图像层间距和层厚的协调关系,避免出现太大非扫描区域,导致信息不完整。根据低剂量螺旋CT肺癌筛查专家共识,重建层厚≤0.625 mm的设备可以无间隔重建,对于重建层厚介于0.625~1.20 mm之间,重建间隔≤层厚的80%[16];在肺亚实性结节的影像处理中,根据肺亚实性结节影像处理专家共识,对层厚<1 mm的设备可以无间隔连续重建,对扫描层厚>1 mm,重建间隔选择准直层厚的50%~80%,以免漏诊或者误判[17]。考虑肺结节数据集的数据和设备来源的多样性问题,建议在清洗规则中将层间距/层厚的范围限定在[0.6, 1],以便为后续的数据分析提供高质量的数据。
根据上述分析,将肺结节医学影像数据集的数据清洗流程设计,见图3。
2.3.1 清洗方案的实施
本次肺结节医学影像数据的清洗工作具体实施步骤如下:
第一步,对原始数据进行伦理批件人工审核,筛除未经伦理批准的数据,以确保数据来源的合规性。
第二步,依照上述清洗流程图编写清洗程序,将人工审核伦理通过的数据应用清洗程序进行清洗,以确认数据真实唯一可用,排除无法读取、不完整的数据、无使用价值的数据和重复数据。
第三步,脱敏的检查,在第二步中如果出现敏感信息非空白的数据,需要人工审核信息是否脱敏(包括原始图像、头文件、附加信息中涉及患者隐私的任何信息或字段)并剔除未脱敏数据。

图3 肺结节医学影像数据集数据清洗流程图
第四步,将清洗后的数据质量问题归类输出,人工溯源到原始数据逐一审核确认。
本次数据清洗共发现4大类数据质量问题,通过人工溯源的方式将原始数据对应的质量问题一一核对确认,发现人工溯源一致性为100%,这说明依照上述步骤进行数据清洗的方法准确有效,既可以快速准确发现数据问题,完成数据清洗工作,同时也节省了大量的人力和时间成本。
2.3.2 清洗结果及数据质量问题分析
在本次数据清洗中,以数据质量总体通过率作为最终的定量指标,其定义是通过伦理审核、脱敏审核、数据清洗之后的数据量除以清洗或审核前的数据总量。肺结节医学影像数据集的指标,数据质量总体通过率、伦理通过率、清洗通过率、脱敏通过率分别为96%、100%、96%、99%。
本次数据清洗发现了以下几类数据质量问题:
(1)存在不唯一数据。清洗过程发现了与现有的公开数据库存在重合的重复图像,这说明提供数据的机构在数据管理方面存在问题,或者由于其他原因导致公开数据集的数据混入国内临床数据。
(2)存在不满足特定要求的数据:例如规定CT图像的层间距层厚比值的可用区间为[0.6, 1]时,筛除了一批间距过大甚至不连续的图像,例如图4所示的例子,相邻两张图像由于间距过大,在轮廓上无法匹配,也无法进行肺结节的标注。

图4 层间距大于层厚的两张连续扫描的CT图像
(3)存在不完整图像、不可读图像、纯色图像、图像缺损、序列缺层、立体区域不连续等多种情况,暴露出数据质量上的种种缺陷。
(4)存在未脱敏数据:部分被剔除的医学影像在图像或头文件中显示非脱敏的患者信息,有泄露患者信息的风险,说明患者隐私保护的措施目前尚不完备。
上述问题的产生,根源要从DICOM 3.0标准的执行角度分析。DICOM 3.0标准虽然对数据交换格式和协议做了清楚的规定,但是并未规定数据存储的具体要求,在具体应用中,这部分由使用者自行决定。在CT等医学影像领域,由于行业管理的规范性不足以及不同的医师操作习惯不同,导致最终的DICOM数据格式不统一。因此会出现不完整、不唯一、不合要求的数据,数据质量参差不齐。这些问题在数据清洗中应及时被发现并加以矫正。
由于数据的收集、传输、存储过程中都会存在引入不可用数据的风险,建议从以下几个方面控制数据质量,提升清洗效果:① 数据管理人员应当加强对数据来源的追溯,充分隔离公开数据集、验证集和测试集,避免数据污染;② 充分考虑数据的特殊要求并在数据清洗时提出针对性清洗规则,通过数据清洗将不满足规则的数据筛除,可以很好提升整体数据质量。
3 总结
为了保证数据多样性,医学影像数据集中的数据来源往往途径较多,加上医学图像数据的处理方式很难统一,容易产生不可用或者质量不过关的数据,这对下一步的数据使用造成了障碍。本文从DICOM数据格式标准和相关法规出发,明确了数据清洗的目标,设计了数据清洗流程,进行了实践检验,并且在应用中发现了不同机构的数据集存在的共性质量隐患,本研究可在数据收集阶段加强数据的质量控制,对提高基于DICOM格式的医学数据集的数据质量提供帮助,同时本文工作也为其他医学数据清洗工作提供了借鉴思路。
猜你喜欢
中国典型病例大全(2022年11期)2022-05-13 21:44:11
中国药学药品知识仓库(2022年8期)2022-05-09 13:54:24
中国临床医学影像杂志(2021年10期)2021-11-22 07:46:38
中老年保健(2021年6期)2021-08-24 06:53:54
中老年保健(2021年9期)2021-08-24 03:50:24
中国医学影像学杂志(2021年6期)2021-08-13 08:43:08
中国民间疗法(2021年1期)2021-04-20 02:30:30
家庭医学(下半月)(2020年4期)2020-05-30 12:42:42
中国生殖健康(2019年10期)2019-01-07 01:21:06
幸福(2017年18期)2018-01-03 06:34:42
