
消极修辞对象的一般化及效果的数量化:从“的”的选用谈起*
2019-01-15 08:36:14陆丙甫于赛男
当代修辞学 2018年5期
陆丙甫 于赛男
(1 南昌大学 语言类型学研究所,南昌 330031; 2 复旦大学 现代语言学研究院,上海 200433)
提 要 本文依据当代语言学中语言信息结构和语言结构效能的研究成果来分析消极修辞。基于“消极修辞”作为一种“一般修辞”的基本性质,本文以“的”的去留为例,结合一些差异最小的“同义、同词、同序而异构”之“同义结构”的分析,说明消极修辞的最基本原理,并由此证明消极修辞研究吸取当代语法研究成果的必要性。文章也进一步通过“平均瞬时信息块数”和“平均依存距离”两种关于结构难度的计算对消极修辞的效果进行了量化分析。这两种结构难度的计算方法,可以应用于所有一般的短语或句子,因而也具有普遍的意义。文章通过对最最“一般”的语料的分析,显示了消极修辞研究和应用的巨大潜力与空间。
一、 消极修辞的发展回顾和前景展望
自陈望道在《修辞学发凡》中系统分析各类修辞方式,并归纳整理为“消极修辞”和“积极修辞”两大分野以来,修辞学的研究总体上在这两大理论领域展开。但考察已有研究成果,多偏重积极修辞,而对消极修辞(规范修辞、一般修辞)的研究,很长一段时间内,相对贫乏。
20世纪80年代开始,这方面才有所突破,如吴士文(1982:10-74)把消极修辞分成“音节对称、成分完整、消灭赘词、因果有据、严防暗换、结构相宜”等26类。内容相当丰富,但也颇为庞杂。如“音节对称”举例“明确是非、分清敌友”不能说成“明确正确非,分别清楚敌朋友”,这种明显不合格的句子,母语者一看就知道,事实上已经属于语法问题。又如“成分完整”也是语法问题,语法学界,默认成分完整是常态,重点研究的是什么条件下某些成分可以省略。至于像“严防暗换”,则是逻辑问题了。吴士文(1986:150-156)还列举了消极修辞“列举分承、称谓合体、事象升华、正面释言”四种“辞规”,但这些内容则又接近积极修辞。如“称谓合体”所举例子:将“出嫁的我”以不同方式表达为“嫁去爷的心肝女,嫁去娘的茉莉花,嫁去哥哥的亲妹妹,嫁去嫂子的大冤家”。这种手法就可归入积极修辞的排比。胡习之(2002:8-163;2014:180-396)对吴士文消极修辞理论有所丰富、发展,根据功能、结构、方法、系统是特定还是一般,将不具有明显规律性或模式化的修辞现象分别归入辞趣或辞风,将具有明显规律性或模式化的修辞现象分别归入辞格或辞规。
上述进展,受到积极修辞研究模式的影响,仍然以分类、定性为主。
近年来,有学者开始倡议修辞研究要跟语言学基础理论研究相结合,并强调重视机制原理的探索(如陆俭明2008,2015;郑远汉2015)。沈家煊(2008)一文作了一个很好的示范。他注意到《诗人多难》一篇文章中,唐代那些诗人“出场”的句子使用以下两种句式:紧缩形式“Y小X n岁”,如“李白小王维一岁”。松散形式“X出生之后n年,Y出生”,如“高适出生之后十年,杜甫出生”。文章中交替使用紧缩式和松散式,其中有什么规律?沈家煊发现,这跟前后两个诗人相差的年龄有关系:
1) 相差1—3岁的,都用紧缩式。
2) 相差10岁以上的,都用松散式。
3) 相差3岁和10岁之间的,两种句式混用。
为什么会出现这样的几种情况?沈家煊解释说,这是语言组织的“距离象似原则”在起作用,并引证了一些有关的心理学实验。
上述两种句式的选择,牵涉到吕叔湘先生所说的“合适性”(“得体、自然”),即不同语境下“各有所宜”的问题,也就是消极修辞问题。沈文提供了一个从心理学角度分析消极修辞的例子。
消极修辞,又称“一般修辞”。如潘庆云(1991)把积极修辞和消极修辞分别称为“艺术性修辞”和“一般性修辞”,并列举了“一般性修辞”适用的种种应用文语体。以此“一般性”衡量以上消极修辞的分类,显然都不够“一般”。根据“消极修辞表现出来的特色是质朴的、平凡的” (胡习之 2014:37)这一标准,理想的“一般性”,即普遍性,应该可以包括所有的结构表达。
下面联系汉语中出现率最高的“的”字的使用,对几个极为一般的句子作一些分析。
吕叔湘《漫谈语法研究》一文(1978/1995:196)指出: 修饰语和被修饰语之间的“的”字,用和不用,在大多数场合不取决于语法(尽管有“的”与否是两种结构),而取决于修辞①。
郑远汉(2004)专门讨论了“的”的选用跟修辞的关系。其中提到“的”有调整节律的功能,并且指出《马氏文通》中已经提到相当于“的”的古汉语“之”具有这一功能。郑文也提到“的”跟语体的关系:疏朗风格者, 往往是能用“的”字的多用;严谨风格者,则往往是可不用“的”字的尽可不用。文艺作品中,多有描写、形容性定语,注重语言的情感因素,定语带“的” 字要多些; 科技作品、新闻报道之类, 求语言简省、结构紧凑, 则是能不用“的”字尽可不用。这一概括是宏观性的。
徐阳春(2008)强调了“的”字的动态用法,认为单说需要出现的“的”或偏正短语,作为一个临时板块进入更大的组合时,“的”字常常需要隐去,除非需要凸显偏项。例如“我的汽车”,与“方向盘”组合时,其中“的”要隐去,说成“我汽车的方向盘”。当然如果仍要凸显“我”,则可以保留“的”,说成“我的汽车的方向盘”。同样,“的”字隐现两可的偏正短语中,其隐现也与说写者是否凸显偏项有关。例如“我爸爸”与“我的爸爸”都是偏正短语,但是后者多了凸显“我”的语用功能。
上述对“的”隐现的分析,都高度概括,但不够细致、深入,因此也较难具体把握运用。如按徐阳春的分析,无法回答为何“我的汽车的方向盘”省略第一个“的”似乎比省略第二个更自然一些。其次,其他虚词在可用可不用两可情况下的隐现,通常也都跟凸显有关。因此“凸显说”在凸显“的”的特殊性方面不够到位。
吕叔湘(1965/1995)在修改作家冯牧《澜沧江边的蝴蝶会》一文时,劈头就把开头一句“很多人都听说过云南大理的蝴蝶泉和蝴蝶会的故事”改为“很多人听说过云南大理蝴蝶泉的蝴蝶会”。这里我们不妨琢磨一下:吕氏为何没有把其中“云南大理的蝴蝶泉和蝴蝶会”改成字数相同且跟原句更接近的“云南大理的蝴蝶泉蝴蝶会”呢?
这一改动的选择,上述郑远汉、徐阳春的分析都难以具体解释这一修改。下面我们就来回答这一问题,并由此进一步讨论定语标志“的”的去留规律。
二、 消极修辞研究要吸收当代语言学研究成果
2.1 “云南大理蝴蝶泉的蝴蝶会”的分析
根据一般的经济原则,“的”要尽量少用。但上述这个句子中,完全不用“的”而说成“很多人听说过云南大理蝴蝶泉蝴蝶会”,似乎不行。在只保留一个“的”的情况下,“的”具有把整个名词短语两分的效果。其结果,所得到的三个两分结构的清通程度是不同的:
(1) a. [云南大理蝴蝶泉的][蝴蝶会]
b. [云南大理的][蝴蝶泉蝴蝶会]
c. [云南的][大理蝴蝶泉蝴蝶会]
细细琢磨,确实是吕氏采用的(1a)最清通,而跟(1a)差别最大的(1c)最不清通。原因何在呢?
可能原因之一:(1a)最符合“核心靠近”原则。
Kuno(1974)用处理(process)过程中减低记忆负担的策略说明了“和谐”这个概念。他认为“和谐”的结构就是上位核心(即整个结构的核心)和下位核心(即从属语中的核心)邻接的结构。Dik (1997:402) 将这种结构特征称为“核心靠近”(Head Proximity)。所谓从属语,就是非核心成分,包括动词短语中的论元、状语名词短语中的定语。我们把两部分的核心词②都用黑体字加以标示。可以看出,(1a)中两部分的核心“蝴蝶泉”和“蝴蝶会”,结构距离最小;而(1c)两部分的核心“云南”和“蝴蝶会”,结构距离最大。
下例的消极修辞修改也同样反映了这个原则的落实:
(2) a. 乌云[吞没了][差不多一百层高的皇家银行顶端那巨大的怪兽形的银行徽记]。
b. 乌云[把差不多一百层高的皇家银行顶端那巨大的怪兽形的银行徽记][吞没了]。
注意,上述所谓“距离”仅仅指结构距离。我们可把“结构距离”进一步落实为“语义距离”,即“两部分的核心在意义上也尽量靠近”。显然,(1a)中两个核心“蝴蝶泉—蝴蝶会”之间的语义距离也小于(1b-c)的“大理—蝴蝶会”“云南—蝴蝶会”之间的语义距离(整个云南省除了蝴蝶泉之外的所有其他地方,都跟“蝴蝶会”无关)。
因此,我们可以把“核心靠近”分为“核心词结构靠近”和“核心词语义靠近”两种情况。在(1)中,两种情况是一致的:a的两个核心在语义和结构上都距离最近,c的两个核心在语义和结构上距离最远。在(2)中,两者就不一致了。语义上,两个变体中,动词跟宾语内部的核心词都是靠近的,但是结构上,a中两个相关核心词在结构上距离却很远。
可能原因之二:由“核心词语义”原理可以联系到广义的“语义靠近原理”。
这一原理的大意是:观念上靠近的成分在结构上也靠近(Haiman 1985:237-238)。具体地说,“云南、大理、蝴蝶泉”都是地名,而“蝴蝶会”是事件,所以前三个表达地名的名词因为语义接近,结构上也可先组成一大块而使三部分最靠近;表示事件的“蝴蝶会”可自成一块。这样处理才最符合“语义靠近原理”③。
可能原因之三:(1a)也符合“大块置前”原理,即大的信息块尽量前置,以便在脑力资源丰富的时刻就处理掉(陆丙甫2015:213-214)。关于这一点,后面第5节还会进一步通过量化加以分析。
可能原因之四:(1a)最符合“尾焦点”原理。陆丙甫(2003)认为“的”的基本功能是描写性标志,陆丙甫(2008)又通过“的”跟日语定语标志の/no/的比较,指出の具有凸显指称性旧信息的作用④,而“的”具有凸显描写性新信息的作用。旧信息趋向前置,而新信息趋向后置。因此,多项定语中,日语的の只出现在靠前的定语中,如指别词定语和数量词定语中;而汉语的“的”则趋向出现在靠后的定语中⑤,指别词定语绝对不能带,数量词定语通常不能带,除非隐含“这么多/少”意义时。上述(1a)中,“的”就出现在可以选择的三个位置中最靠后的位置。并且,靠后位置也是自然焦点的理想位置。
关于“的”的分布、功能,其隐现规律的语法性和修辞性,当然还牵涉到许多因素,我们将另外专门撰文,这里不作展开。本文只是强调,“的”的隐现牵涉到语言结构的处理难度,具有重要的消极修辞意义。
2.2 消极修辞研究的新取向
由此可见,消极修辞研究跟语法研究结合,需要吸收当代句法学的研究成果。随着汉语句法研究的深入,一些语法学者提出语法研究必须紧密联系并借鉴语用和修辞的分析。其实这种联系应该是双向的。修辞研究,特别是消极修辞研究,也需要主动借鉴语法研究的成果。考虑到语法研究的蓬勃发展而修辞研究相对滞后,修辞研究对语法研究的借鉴,可能更为迫切。
具体地说,首先就是消极修辞要吸收当代语言学中关于语言信息结构的研究(陆俭明 2017),以及与其密切相关而范围更大的语用、篇章研究。有关的文献很多,其中不少实际上解释了消极修辞现象,虽然一般都被看作是语法研究的深化而不看作消极修辞研究。其实,这些研究所强调的语境作用,不正是消极修辞的“各有所宜”这一“创造性”问题吗?
其次,消极修辞还必须结合当代语言学中关于语言结构效能的研究。这方面的研究,较早期的有Payne(1992),后继的研究集中反映在Hawkins(1994,2004,2014)一系列著作中,其中提到的“直接成分数/次数之比”(IC-to-word Ratio)、“形式最小化” (Minimizing Forms)、“在线处理最大化” (Maximizing On-line Processing)、“直接成分尽早识别原则” (Early Immediate Constituents)、“依存常规化准则”(Principle of Conventionalized Dependency)、“总域差” (Total Domain Differential)等等,都跟消极修辞效果的功能解释有密切关系。这方面我国语言学者尚未给予足够重视,在心理学界偶尔有一些研究文献。
当代语言学这些领域的研究,都可以用来解释语句的“清通度”,帮助我们把原本“只可意会,不可言传”的消极修辞的机制原理明确表达/阐述出来。
事实上,我们可以根据消极修辞所用到的关于语言结构效能的原理,为以往消极修辞现象的分类提供更明确的标准,乃至提出新的分类。关于这个,宜另外撰文讨论,这里不再赘言。
三、 两种结构难度计算的介绍
上述分析结构,还可以进一步通过结构难度的计算加以量化。
消极修辞的主要目的,最广义地说,就是降低句子的理解难度。当代心理语言学证明,句子理解过程,主要是个同步组块过程,即不断地把较小信息块组成较大信息块的过程。这一过程中,脑子中平均每时每刻要记住的离散信息块数量,是衡量句子结构难度的一个最基本的因素,可看作结构难度的基本指数“平均瞬时块数”(Mean Instant Chunk Number,简称MICN, Lu 1991,2001;陆丙甫 2015)。
近年来,刘海涛基于“依存语法”(Hudson 1990,2010;刘海涛 2009),提出了另一种计算结构难度的一般方法“平均依存距离”(Mean Dependence Distance,简称MDD, Liu 2008),并对数十种语言句法标注语料库进行了统计分析,认为人类语言具有依存距离最小化的特征,依存距离对句子线性结构模式的形成有着重要的影响 (Liu et al. 2017)。具体而言,句子中所有配对的“核心词”及其“从属词”之间的距离的总和除以“从属词”的词数所得到的数值,可以代表句子理解处理过程的难度指数。国外类似的研究也有一些,如Temperley (2008)的“依存长度最小化”(Dependency-length Minimization)。以下例子显示了这两种结构难度的计算方法:
(3)
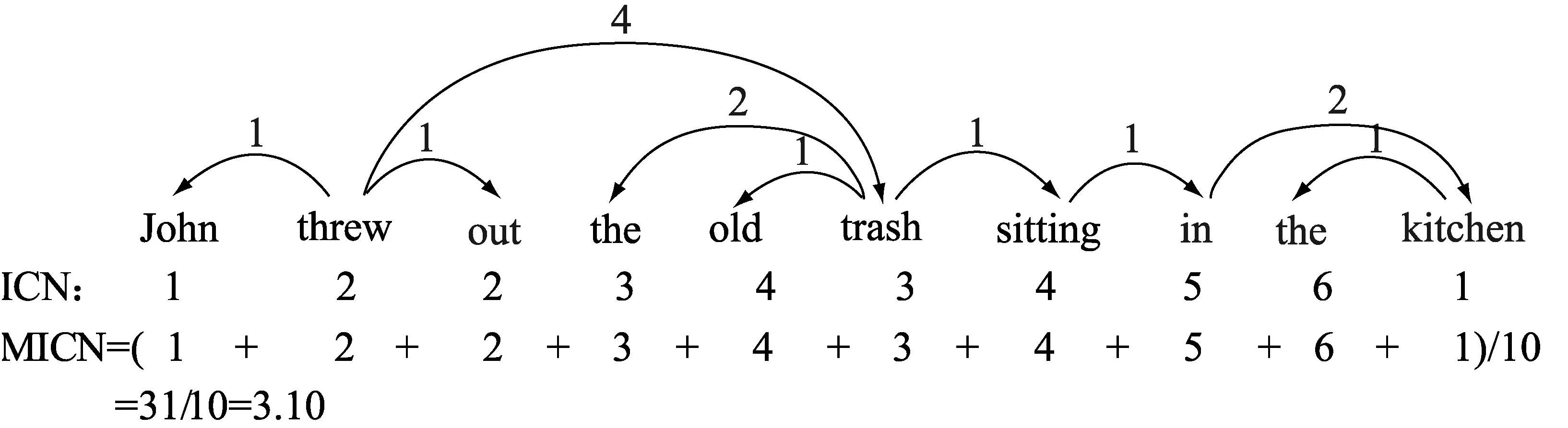
总依存距离=1+1+4+2+1+1+1+2+1=14
平均依存距离MDD=14/9=1.56 (除数9为“从属词”的总词数,即总词数10减去一个不从属于任何成分的全句核心词)。
以上每个词下面的“ICN”数字表示“瞬时信息块数”(Instant Chunk Number),即听到这个词时脑子要记住的离散信息块数。这个数值也可以看作“瞬时结构难度”。MICN是“平均瞬时信息块数”,即所有“瞬时信息块数”的总和除以整个结构的词数得到的数值。这个数值代表平均每接受到一个词脑子中记住的信息块数,即“平均结构难度”。注意,计算过程中,应假设解码者是个理想的本族语母语者,他严格按照正确反映所处理结构的树形图来组块:每个离散信息块都至少是代表一个句法结构体的节点⑥。
以上MDD是具体句子的“平均依存距离”(Mean Dependence Distance)。句子上方带箭头弧线,连接有依存关系的两个词:箭头指向的词是从属词,而弧线另一头是代表核心的起点。弧线上方数字代表依存距离。两个词如果相邻,依存距离为最小值1,如John threw 中的从属词John离其核心词threw的距离就是1。而trash跟其核心词threw中间有三个词(out、the、old),依存距离就是3+1=4。也就是说,两个词中间有N个词,则依存距离就是(N+1)。由于整个结构的全局核心词本身并不从属于该结构中的任何词,所以它没有依存距离;即上面这个句子中谓语核心词threw没有依存距离。因此,在计算平均依存距离时不算进去。如上面“平均依存距离MDD=14/9=1.56”中,总依存距离14除以9,而不是除以总词数10。注意,所谓“从属词”多数情况下是“依存语”中的核心词。
以下这个句子的三种语序变体,即同词同构只是语序不同的“同义结构”,因为语序不同,计算结果就显示出结构难度的不同⑦:
(4) a.

(4) b.
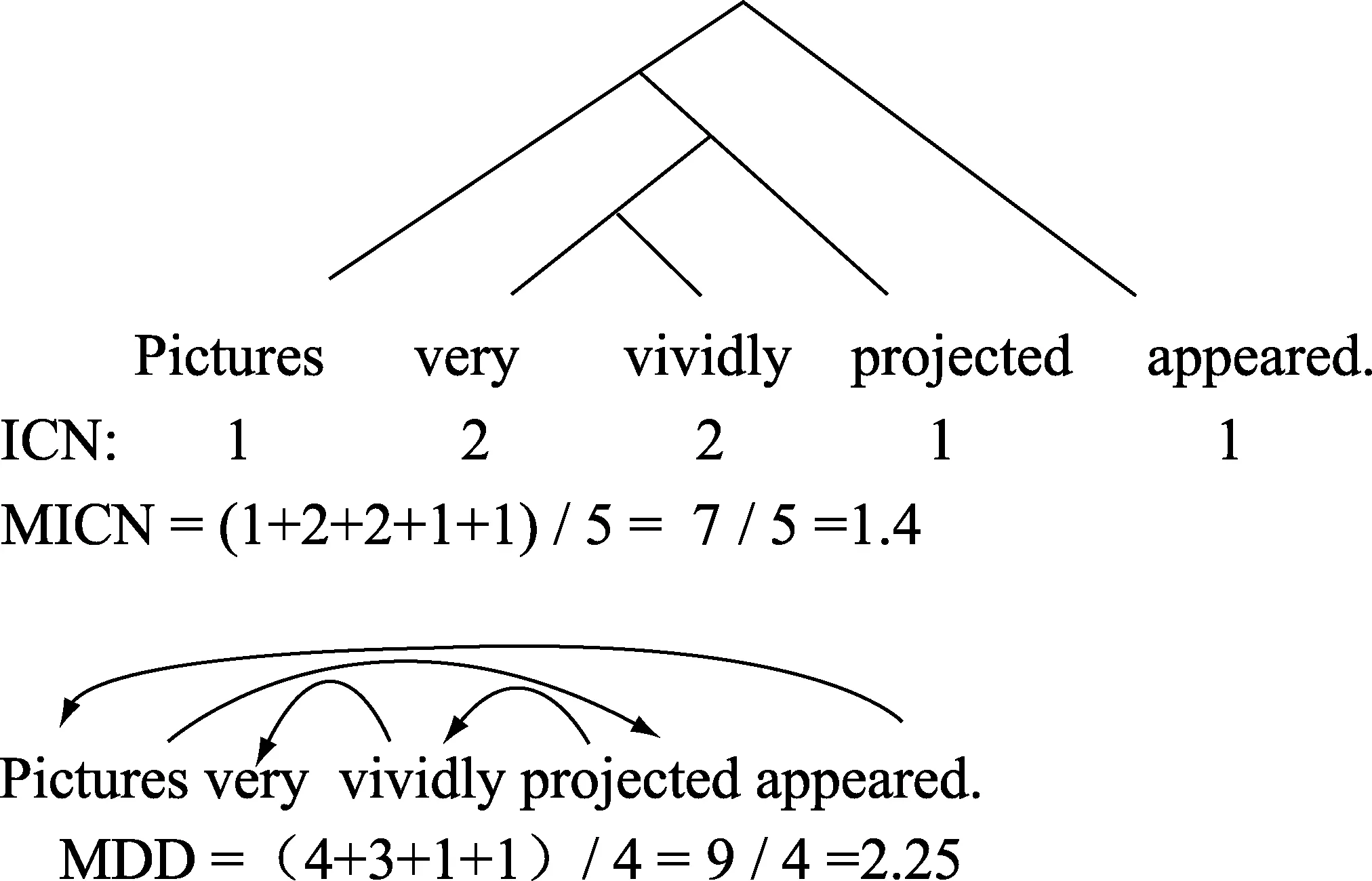
(4) c.

(5) “平均瞬时信息块数”和“平均依存距离”的计算比较:

a.b.c.MICN1.001.401.60MDD1.002.252.50
两种计算的结果基本趋向一致,都是a句式难度最低,b句式次之,c句式最高。具体数值虽然不同,但趋向基本一致。
根据初步的测试,最高瞬时信息块数(ICN)没有超过七左右的(陆丙甫 2015);并且,平均瞬时信息块数(MICN)不会超过四左右(陆丙甫、蔡振光 2015)。这两个数字正好分别符合“短时记忆限度七左右”(7±2,Miller 1956)和“工作记忆限度四左右”(4±1,Cowan 2000)。这从一个侧面表明了两种计算确实反映了人类记忆机制对人类语言结构复杂度的普遍约束。
Liu(2008)对20种语言的数据库语料作了统计,结果也显示没有一种语言的语料库“句子平均依存距离”(可称为“语料库平均依存距离”)是超过4的(语料库平均依存距离在罗马尼亚语中最低,为1.798;在英语中是中等,为2.543;在汉语中最高,为3.662)。
四、 一个汉语实例的结构难度计算
下面我们对本文开头提到的例子进行量化的验证。

(6) a. [云南 大理蝴蝶泉的][蝴蝶会]
ICN: 1 1 1 1 1
MICN=(1+1+1+1+1) / 5 = 5 / 5 =1.00
MDD =(1+1+1+1)/ 4 = 4 / 4 =1.00

b. [云南大理的][蝴蝶泉蝴蝶会]
ICN: 1 1 1 2 1
MICN= (1+1+1+2+1) / 5 = 6 / 5 =1.20
MDD =(1+1+2+1)/ 4 = 5 / 4 =1.25

c. [云南的][大理 蝴蝶泉蝴蝶会]
ICN: 1 1 2 2 1
MICN= (1+1+2+2+1) / 5 = 7 / 5 =1.40
MDD =(1+3+1+1)/ 4 = 6 / 4 =1.50
(7) 计算结果显示,两种计算法的大致倾向一致。

a.b.c.MICN1.001.201.40MDD1.001.251.50
五、 数学归纳法思路在语言现象分析中的运用
以上是多层定语中三个“的”中保留一个的情况,我们再来看看保留两个的情况。保留两个“的”可得出以下三种变体:
(8) 1. 云南大理的蝴蝶泉的蝴蝶会 2. 云南的大理蝴蝶泉的蝴蝶会
3. 云南的大理的蝴蝶泉蝴蝶会
由于保留两个“的”的结果具有把整体切分成三块,而三块的组合又有两种选择,结果可得到六种切分:
(8) 1a.[云南大理的蝴蝶泉的][蝴蝶会]1b. [云南大理的][蝴蝶泉的蝴蝶会]
2a.[云南的大理蝴蝶泉的][蝴蝶会]2b. [云南的][大理蝴蝶泉的蝴蝶会]
3a. [云南的大理的][蝴蝶泉蝴蝶会] 3b. [云南的][大理的蝴蝶泉蝴蝶会]
根据“核心靠近原则”,可以看出只有1a与2a两部分的核心词是靠近的。由此可以认为这两个结构比其余的都要容易理解。
进一步的问题是要比较1a与2a的清通程度。既然两个格式后半部是一样的,为了简化,可以把其中不同的前半部抽出来比较,并把相同的最后一个“的”去掉:
(8) 1a′. [云南大理的蝴蝶泉] 2a′. [云南的大理蝴蝶泉]
可以看出1a的前半部也符合“核心靠近原理”。所以,1a′胜出。
这一分析,本质上也就是“数学归纳法”思路的运用,即同样原理的重复运用: 设多层定语结构“X的Y的Z”,在无其他因素干扰的状况下,优选省略形式是“XY的Z”,现在我们把XY看作一个整体,用A表示,原式就成了“A的Z”,扩展成“A的Z的B”,套用对“X的Y的Z”的分析,就会得出以上的结论。是否所有这类其中任何相邻两项都具有潜在修饰关系的多层定语结构都可以这样分析?下面我们来看另一个例子。
六、 另一个实例的结构难度分析
下例跟“云南大理蝴蝶泉的蝴蝶会”有所不同的是:组成这个结构的四个词,不用插入“的”字也完全成立,作为一个固定组合及专有名称也很自然。而“云南大理蝴蝶泉的蝴蝶会”不可能是专有名称。下面我们分析没有“的”的情况,这是个“同义、同词、同序、五重结构歧义的结构体”,即可以有五种不同的结构切分。
(9) “上海 市区 建筑 管理局” 的5种切分方式:
a.上海3市区2建筑1管理局
ICN: 1 1 1 1
MICN=4/4=1.00

上海3市区2建筑1管理局|
1 1 1 1
MDD: (1+1+1)/3=3/3=1b. 上海2市区3建筑2管理局
ICN: 1 2 1 1
MICN=5/4=1.25

上海2市区3建筑1管理局
2 1 3 4
MDD: (2+1+1)/3=4/3=1.33
c. 上海2市区1建筑2管理局
ICN: 1 1 2 1
MICN=(1+1+2+1)/4=1.25
IDD: 1市区2管理局1管理局
MDD: (1+2+1)/3=1.33 d. 上海1市区3建筑2管理局
ICN: 1 2 2 1
MICN=(1+2+2+1)/4=1.5
IDD: 1市区3管理局2建筑
MDD:(1+3+2)/3=2 e. 上海1市区2建筑3管理局
ICN: 1 2 3 1
MICN=(1+2+3+1)/4=1.75
IDD: 1市区2建筑3管理局
MDD:(1+2+3)/3=2
以上上标数字表示切分顺序,如(9a)第一次切割分成“上海市区建筑 / 管理局”两部分,第二次再把其中第一部分分成“上海市区 // 建筑”。最后结果是“上海///市区//建筑/管理局”。从c开始,把代表每个词依存距离的箭头弧线简化为IDD(Individual DD)数字,数字的下标文字为该从属词所从属的核心词。两种计算法得到的结构难度的结果,也是基本一致的。
(10)

a.b.c.d.e.MICN1.001.251.251.501.75MDD1.001.331.332.002.00
计算结果表明,在这类N项成分组成的结构中,如果“任何相邻两项都能组合”的话,最好的切分显示这样的特征:同步组块过程遇到任何一个新词都跟前面的所有成分组成一个大块。这个切分的结果,也就是除了最后一项之外,前面(N-1)项成分能组成一个大块,再跟最后的第N项结合。这是最大程度上符合“大块置前”(陆丙甫2015:213-214)的结构分析。
七、 “基础难度”之外的其他因素
前面说过:如果要在“云南大理蝴蝶泉蝴蝶会”中插入一个“的”,最佳选择是“云南大理蝴蝶泉的蝴蝶会”。因为其中“云南、大理、蝴蝶泉”都是地名,而“蝴蝶会”是事件,所以前三个表达地名的名词因为语义接近,可先组成一大块,表示事件的“蝴蝶会”可自成一块。这样处理最符合“语义靠近原理”。
不过,上一节的(9),这方面情况略有不同。如果“上海市区建筑管理局”要插进一个“的”,理想的插入处不是类似(11a)的“上海市区建筑的管理局”,而是“上海市区的建筑管理局”。这是因为,“建筑”跟“管理局”中的“管理”有密切的语义关系,即论元关系。
可见,除了基本结构决定的基本结构难度外,其他许多因素,包括细微的语义差异,都影响到消极修辞具体处理的选择。这些可以说是“语义难度”和“语用难度”。但是,结构难度计算至少提供了一个普遍适用,因而也是必不可少的“基础难度”。在基础难度之上,可以加上各种其他因素导致的难度,才能精确地反映结构处理的实际难度。
困难是不同因素导致的难度如何跟基础难度之间进行换算。此外,在组块计算中把实词和虚词的效果加以区分,也是一个尚未解决的重要问题(陆丙甫 2015:224-226)。看来这些是需要借助脑电图、眼动仪等仪器测量的心理语言学的实验才能解决的问题。
八、 消极修辞研究和运用的巨大潜力
“简洁、明白、通顺、平匀、稳密”这些消极修辞的基本要求,都显得比较抽象、概念化,很难具体把握,更不用说以此来分类了。因此,也就难以深入下去。
吕叔湘(1965)对冯牧“澜沧江边的蝴蝶会”进行消极修辞加工的结果,正如吕先生自己所说,“原文有三千七百字,改作的字数为原作的一半多一点。我相信,我的改作没有‘伤筋动骨’,原作的内容实际上都保存下来了。如果把对西双版纳一般风景的描写,再压缩一下,还可以减去二三百字,就只有原作的一半了”。
冯牧是知名散文作家,其“澜沧江边的蝴蝶会”也是篇流传甚广的优秀散文,甚至收进了《最美的散文大全集》(外文出版社2012)。但是这样一篇不需修改已经很优秀的散文,在消极修辞方面可改进的余地竟然可以这么大!“可以不改而仍然可改”,才是消极修辞的更高境界。以这个高标准去衡量,可知消极修辞运用的空间是多么巨大!也可知语文教学和全民语文修养的提高,都离不开修辞学的发展。正如吕叔湘(1983)所说,“语文教学的进一步发展就走上修辞学、风格学的道路”。
一般认为修辞学的核心问题是对同义结构进行分析、比较并加以选择。经典的例子就是“春风又绿江南岸”中选择了“绿”而舍弃了由“到、入、满”等构成的“同义结构”(林兴仁 1980)。但这算不算严格的“同义结构”,一直存在争议(陈光磊 1983)。如果说在积极修辞领域对此有争议的话,说消极修辞中主要分析的是“同义结构”的选择,争议就少得多。
本文分析的都是典型的“同义结构”。不仅“同义”,而且包含的词语也一样,即“同词”。甚至还是“同样语序”,即“同序”。所不同的只是理解时的“组块”方式,或“层次切分”不同。这可以说是最典型、最简单的“同义结构”,可以作为研究的起点。
九、 余言:科学始于对简单现象的深刻思考
科学体系是个从简单到复杂的推导体系。任何科学体系都要以最简单、最平凡的现象的分析为起点,如几何学中的公理和演绎逻辑三段论,都简单得如同废话。修辞学及整个语言学都应该朝此方向努力!
科学发展史启示我们,科学始于对简单现象的深思,如牛顿对苹果落地的深思。曹冲称象说明他已经意识到浮力定律,但因为没能像阿基米德那样对浮力现象进行深思而终究没有发现浮力定律,千古美谈实为千古遗憾。
前文例(9)显示,四个单位组成的结构体,如果任何两个相邻的都可以组合的话,实际可能的切分有5种。进一步思考可以发现,五个这样的单位组成的结构体,可以切割成14个“同义同词同序异构体”。实际上,数学上不难得到一个普遍的由N个这样的单位构成的异构体数量(傅思泉 2005):
其中P为排列,n为词语数。当只有两个词语时,排列只可能一种,同时:

P7=……=132P8=……=429 ……
当有7个名词组合成偏正结构时,居然有429种可能的潜在层次,解码处理时决不会容纳如此多的选择,必然只会选择一种感知难度最低,理解最省力的组块策略。那么哪种排列组合方式是最省力的呢?
根据我们以上的分析,可以看出,最好的分析就是能使同步组块过程遇到任何一个新词就跟前面大块结合的那种切分得到的组合方式。
实际上,这类其中任何两项都能组合的多层修饰结构在实际语言中并不多见,即使有的话我们也能轻易地排除那些明显不通顺的处理;似乎没有必要考虑那么多。这是实用角度的考虑。但是作为理论,特别是基础理论,就是需要考虑所有的潜在可能性⑧。只有基础理论发展了,实际应用才有广阔的发展空间。
注释
① 具体地说,“的”必用和禁用都是语法问题,只有“可用也可不用”时的选择,才是修辞问题。
② head一词,在句法中可以指“核心语”,也可以指“核心词”。Dik使用时,实际上是指核心词,后面讨论中牵涉到的核心,也都指核心词。为表达精确起见,一般就用“核心词”。
③ 事实上,在“语义靠近象似性”这一总原理下,可以细分出种种不同的落实形式。陆丙甫(2016)指出可以分成六种情况。前面所说“核心靠近”是其中之一。经常被提到的还有“联系项居中”原则(Dik 1997:406)。我们不妨把这里所说的看作第七种,可命名为“(语义靠近则)优先组块”原则。
④ 当然,“新—旧”信息跟“描写性—指称性”这对范畴并不是简单的对应关系。但是,至少可以说,其对应是一种无标记的组配或“自然关联”(沈家煊 1999:31),即指称性信息多数是旧信息,而描写性信息多数是新信息。
⑤ 这里所谓“靠后的定语”,要排除黏合式定语,因为黏合式定语本质上是复合词,见下面2.2节中有关分析。
⑥ 这里面有一些细节要求,如只有生成语法中认为是可以作为移动单位的XO单位“词”和作为最大投射短语的Xmax才可看作一个自足的信息块。关于这个,本文暂不讨论。
⑦ 此例引自Yngve (1961)解释他的“深度理论”时所用。该理论认为编码者编出一个词时所记住的后面要出现的成分数目反映了结构难度,如完成了主语后,所记住的后面的成分只有谓语一个,此时“深度”就是一。关于对该理论的评介,见陆丙甫(2015:199-200)。
⑧ “根据潜在的最大可能”这种推向极端的分析方法,是科学理论抽象化的一个表现。不妨说,理论研究跟应用研究的主要区分就是:前者强调可能性,后者则强调现实性。中国古代应用数学发展程度极高,但理论成就不多,重要原因是缺乏推向极端的抽象精神。如朱世杰在《四元玉鉴》已解出了四次方程X-9X4-81x3+729X2-3888=0的一个解是3,但却没有追问最多能有多少解。中国古代数学主要是由许多具体用例和解法构成,这样就难以发展起一般性的理论。数学理论则要求得出一切解,其中有些是负数、无理数、复数,在日常生活中毫无意义,但那却是数学的基础理论所必需的。甚至不仅要找出一切可能的解,还要论证必然不可能存在的解。语法学中,这种根据最大可能性的分析法也是最基本的分析原则。早期的语文研究,建立在收集实际语料的基础上。实际语料当然是最基本的,因此丝毫不能忽视。但从理论要解决最大可能性的角度看,它又是不充分的。自生成语法开始,对不成立的句子的研究也得到了重视。这是一个巨大的进步。
猜你喜欢
科学与社会(2023年4期)2024-01-11 08:08:44
青年歌声(2021年2期)2021-03-05 09:02:08
音乐世界(2020年4期)2020-09-10 20:57:26
新世纪智能(英语备考)(2019年12期)2020-01-13 06:07:26
民族音乐(2018年5期)2018-11-17 08:20:00
Coco薇(2017年8期)2017-08-03 20:58:26
高中生·天天向上(2016年12期)2017-02-28 08:23:52
初中生学习·高(2016年8期)2016-05-14 15:38:57
海峡姐妹(2015年3期)2015-02-27 15:10:14
中国卫生(2014年12期)2014-11-12 13:12:44
