
一种基于多属性模糊决策的英文韵律短语边界预测方法
2019-01-10 06:40:32汪丹丹
西安文理学院学报(自然科学版) 2018年6期
汪丹丹
(安徽城市管理职业学院 信息工程系,合肥 230011)
语音合成技术作为人工智能技术的典型代表,现已广泛应用于生活的各个领域.韵律短语边界预测作为语音合成系统文本分析前端的核心模块,关系着语音合成系统的效果和体验.
现阶段,英文韵律层次的划分一般采用ToBI标准[1-2],分别记音素间的间隔为LP边界、单字词间的间隔为L0边界、隐词组间的间隔为L1边界、次词组间的间隔为L2边界、主词组间的间隔为L3边界、子句间的间隔为L4边界,以及句子间的间隔为L5边界,共七个层次.超音段特征会随着韵律层次的不同而有所区别,主要体现在三个方面:一是停顿时间;二是层次后边界音节的时长变化;三是层次后边界音节的调域和均值的变化.考虑到L2和L3在这三方面的表现比较相近,标注人员很难根据听感人工精确标注出来,因此,在人工标注阶段、训练阶段和预测阶段,通常都将L2记为L3,不作区分.
L3边界预测方法是以决策树为基础的预测方法,但这种方法有自身局限性,其训练数据的均衡性以及决策算法本身无法达到全局最优.为了改善预测效果,本文在传统的决策树方法之上,将决策树使用的聚类属性与模糊决策相结合,提出通过多属性模糊决策方法,来预测英文L3边界.
模糊决策是以模糊集合论为基础,融合了决策理论,重点处理模糊现象[3].本文以模糊决策方法为基础,采用多属性模糊决策方法成功地解决了L3边界预测问题.实验表明,使用这种方法的L3边界预测效果比基于决策树的预测方法的效果有较大提升,F-Score由64.4%提升到69.3%,不可接受率也从28.6%降低到21.4%.
1 传统的基于C4.5决策树的L3边界预测方法
英文语音合成系统的文本分析前端一般包括词典词和非词典词的预处理、L1边界划分、L3边界预测、L4语调预测等.L3边界预测是在L1边界划分基础上,通过判断各个L1边界是不是L3边界来进行分类.这是比较典型的分类问题,所以通常L3边界预测都是采用传统而有效的决策树的方法来实现.
决策树的具体实现方法有很多,其中C4.5决策树采用ID3算法作为核心算法,通过数据属性从大规模的数据中挖掘规律,规律则以C4.5决策树的形式来表示.本文基线系统即是采用此方法搭建的[4],其输出属性为{PL1,PL3},输入属性为:
(1)前前词的词频,前词的词频,当前词的词频,后词的词频,后后词的词频;
(2)前前词的词类,前词的词类,当前词的词类,后词的词类,后后词的词类;
(3)前前词含有的L0数目,前词含有的L0数目,当前词含有的L0数目,后词含有的L0数目,后后词含有的L0数目;
(4)前前一个L1的长度(指L1中含有的单词数),前一个L1的长度,当前L1的长度,后一个L1的长度,后后一个L1的长度.
根据PL1和PL3的大小即可判断该L1边界是不是L3边界.
2 基于多属性模糊决策的预测方法
传统的基于决策树的预测方法属于数据驱动方法,人工只能在属性筛选环节进行干预,难以使用专家经验.因此,本文在使用基线系统属性的基础上,提出多属性模糊决策的方法,通过三角模糊数理论[5-6]对模糊语言型的属性值赋值,决策者只需以模糊语言形式提供较少信息,系统就能输出更为合理的结果.
2.1 三角模糊数
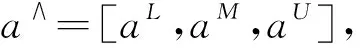
(1)
式中,μ(x)表示元素x属于a∧的真实程度,当aL=aM=aU时,则三角模糊数a∧蜕化为一实数.
2.2 多属性决策
多属性决策是在获取到相关一组可能的决策结果后,对这组结果进行择优排序[7-8].多属性决策可以使用不同的算子来实现,本文使用了OWGA算子[9]:
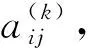
(2)
(2)对各L1边界的决策结果xi(i∈N)进行归纳汇总,并通过OWGA算子计算其多属性决策值zi(w):
(3)
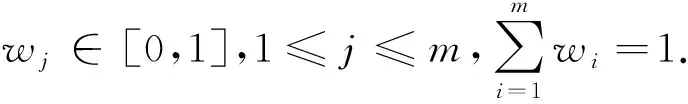
(4)对各L1边界的多属性决策值zi(w)进行排序,选出最优解对应的L3边界划分结果.
3 实验
3.1 标注数据库
基于中国日报(China Daily)近三年的新闻语料,本文建立了一个包含11 027句英文句子的L3标注数据库.其中,L3边界共有29 177个,L1边界共有50 269个.
在此基础上,本文将标注数据库分为了两部分,一部分用于训练,占总数据的绝大部分,共10 027句;剩余部分用于测试,约占总数据的十分之一,共1 000句.测试数据又随机地分为了两半,一半用于客观测试,另一半用于主观测试,各500句.
针对客观测试,本文选用了F-Score作为评价指标:
(4)
而针对主观测试,本文选用不可接受率作为评价指标,即选取了三名英语专业八级水平的实验员对L3边界的预测结果进行判断,确定可接受还是不可接受.
3.2 实验结果
通过对比测试发现,使用多属性模糊决策的新系统相对基线系统而言,在500句客观测试集上的F-Score由64.4%提升到69.3%,其中召回率得到了较为有效的提升,由63.6%提升到70.9%,由此可以判断新系统预测出了更多的合理的L3边界划分结果.
另外,主观测试方面,新系统与基线系统相比,不可接受率从28.6%降低到了21.4%(见表1).这也在一定程度上说明了多属性模糊决策的L3边界决策结果更为合理.
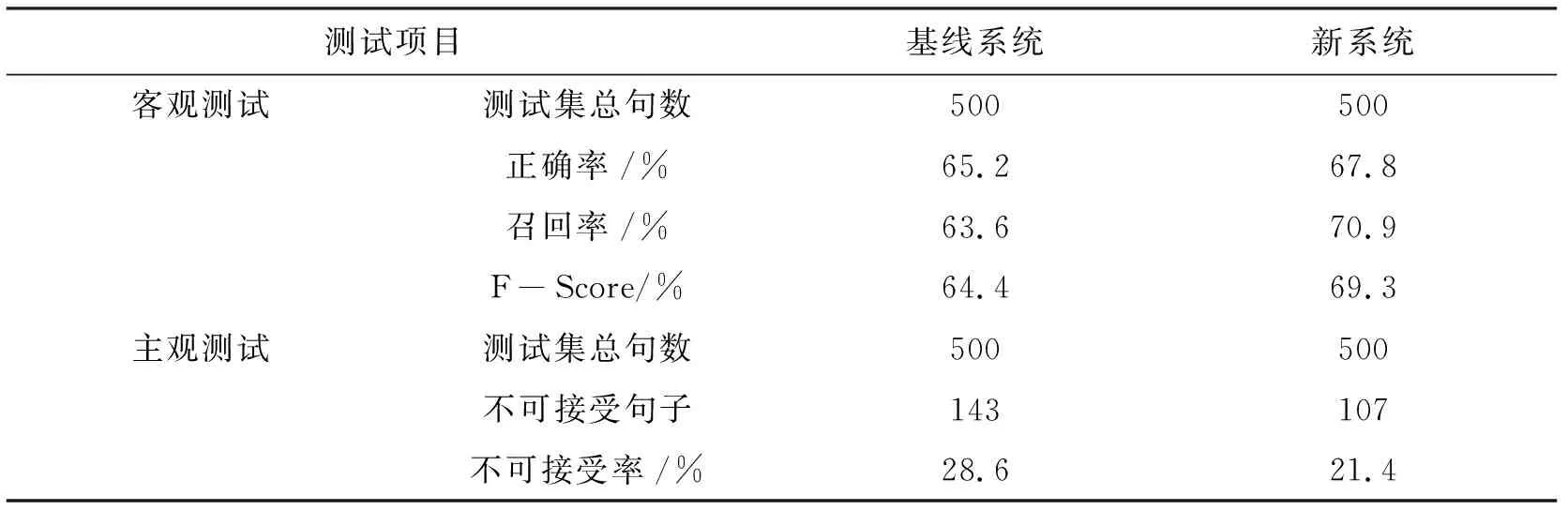
表1 实验结果
4 结语
本文在英文L3边界预测中,将决策树使用的聚类属性与模糊决策相结合,提出通过多属性模糊决策方法来预测英文韵律短语边界.与基于决策树的预测方法相比,F-Score由64.4%提升到69.3%,不可接受率也从28.6%降低到21.4%,基于目前的标注集与测试集,该方法在一定程度上具有有效性.
但考虑到很多句子(特别是单词数较大的句子)L3边界的答案是多样化的,因此F-Score不能完全客观的体现不同方法的性能,重点还是要看主观测试指标不可接受率,后续可以考虑一些工程化的手段来改善系统的不可接受率,比如适当降低常用短语内部边界是L3边界的概率等.
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
新世纪智能(英语备考)(2019年10期)2019-12-16 09:07:54
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
广东蚕业(2019年3期)2019-05-14 05:37:40
新世纪智能(语文备考)(2019年3期)2019-01-12 09:08:10
电子制作(2018年16期)2018-09-26 03:27:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
现代语文(2016年21期)2016-05-25 13:13:29
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
