
基于OMNeT++仿真平台的改进型USAP仿真分析
2019-01-07 06:40:44黄佳欣郑春胜
航天控制 2018年6期
黄佳欣 郑春胜
北京航天自动控制研究所,北京 100854
飞行器间的协同作战是未来空战的重要形式,而协同作战的前提是组建具有较强通信能力的网络。不同于有线网络和无线蜂窝网络,移动Ad Hoc网络MANET(Mobile Ad-hoc NETworks)是一类不依赖于基础设施的由若干移动节点组成的自组织网络,可以满足飞行器组网的需求,具有广泛的应用前景。但其特殊的网络结构使得传统的网络协议不再适用,需要设计出专门的网络协议。其中,MAC协议(介质访问控制协议)作为Ad Hoc网络协议的重要组成部分,对网络的性能有非常大的影响。由David Young提出的USAP是针对Ad Hoc网络设计的分布式TDMA时隙分配协议。本文针对经典USAP在节点密度大和拓扑变化迅速的时候无法快速组网的情况,对协议进行了分析和改进,设置仿真场景并利用OMNeT++仿真软件仿真改进后的协议。结果表明,在多节点网络中,当节点需要进行频繁的时隙动态分配时,改进后的协议更符合实际场景的需要。
1 经典USAP介绍
作为一种移动多跳多信道无线网络的分布式TDMA协议,USAP的核心在于相邻节点间信息的及时交互,即节点根据接收到的信息更新自身消息表,发送节点根据自身消息表预约时隙池中满足约束条件的数据时隙进行数据包的发送。与传统TDMA协议在同一时隙只能有一个节点发送数据相比,USAP可以实现两跳邻域内时隙的无冲突分配,理论上一定程度增加了时隙利用率。
对于一个节点数为N,信道个数为F的网络,USAP的帧结构如图1所示。图中一个时帧由M个时隙组成,其中M的数值由设计者根据网络情况进行设计。每个时帧中的第一个时隙为引导时隙,用于分配给网络中的某个特定的节点广播其网络控制分组NMOP(net manager operation packet)。N个时帧组成一个超帧,以一个超帧为周期,每个节点都能分配到一个引导时隙用于广播自己的NMOP。

图1 经典USAP帧结构
2 改进型USAP
2.1 帧结构设计
经典USAP需要经过一个超帧后网络内的所有节点才能完成一次信息的交互,无法快速适应网络拓扑结构的变化,并且当网络中节点数量增多时,会因为信息交互不及时导致时隙分配冲突,浪费大量的数据时隙。为保证控制信息的及时交互,协议增加了每一帧中引导时隙的个数。为简化协议的设计,本文只讨论单信道情况下的时隙分配,以此为基础不难设计出多信道情况下的协议。
改进后的协议帧结构如图2所示,其中,前N个时隙为引导时隙,引导子时隙长度为t1,在一个时帧内,为每个节点都分配了一个引导子时隙。后M个时隙为数据时隙,时隙长度设置为t2,一个时帧长度为N*t1+M*t2。
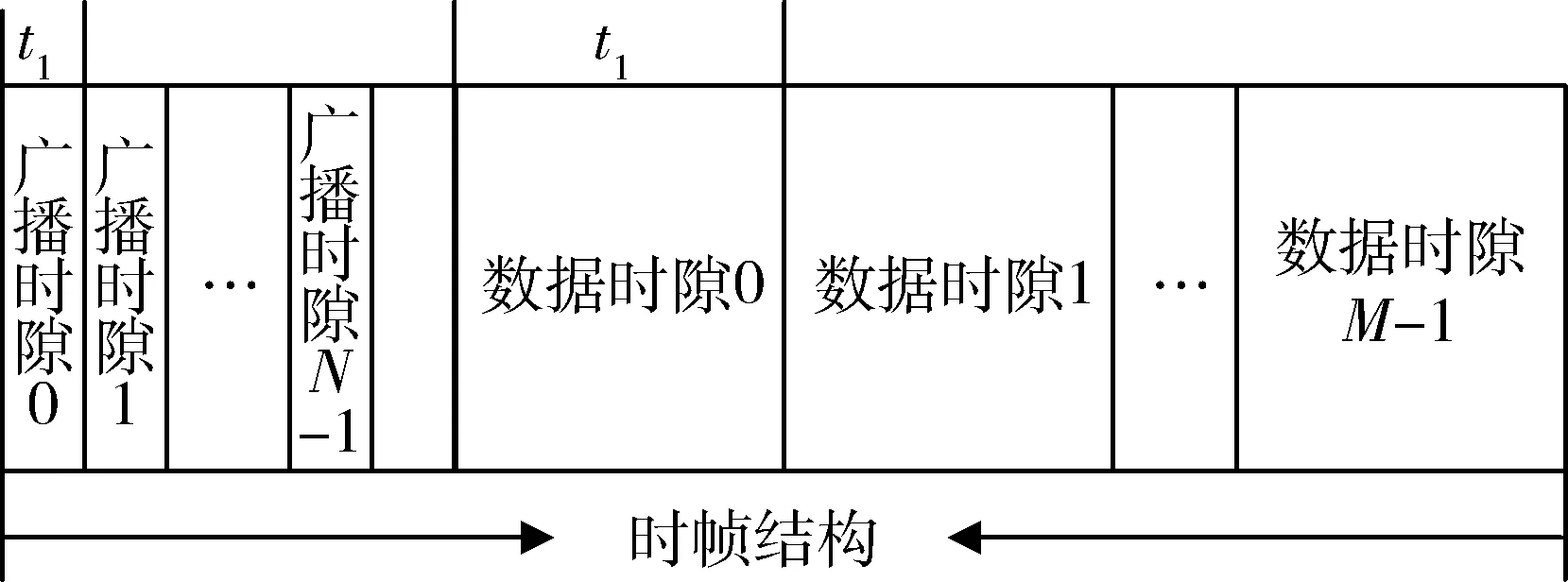
图2 改进USAP帧结构
2.2 网络控制分组中添加的信息
STNi(s):存储了节点i作为源节点在时隙s的目的节点的编号,未占用时隙对应为0;
SRNi(s):存储了节点i作为目的节点在时隙s的源节点的编号,未占用时隙对应为0;
NTi(s):节点i所有邻节点的时隙占用情况,在时隙s,若存在邻节点发送数据,NTi(s)为1,否则为0;
NMOP的长度取决于数据时隙的数量,对于一个最大容纳16个节点的网络,存储单个时隙信息需要9bit,NMOP长度为9*Mbit的时候就能将以上信息全部存入。
2.3 协议工作流程
网络中节点采用半双工通信,对于从节点i到邻节点j的单播,时隙分配满足以下条件,可实现数据的无冲突传输:
1)在时隙s,节点i和其邻节点j都没有发送或接收数据;
2)在时隙s,i的所有邻节点都没有接收数据;
3)在时隙s,j的所有邻节点都没有发送数据。
问题是数学的“心脏”,数学的发展源自数学问题的衍生,因此数学教学是基于“问题解决”的教学[16].在此意义下,数学教学的逻辑起点不是概念、原理和法则等知识本身,而是如何创设具有现实性和思考性的“问题”.基于此,首先编制了测试卷,具体包含两类问题.
上述约束条件成立,则时隙可实现无冲突分配,这一假设是建立在所有节点的时隙分配情况都得到了及时交互的基础上。但实际上,网络中节点只能按顺序发布自己的NMOP,存在节点间控制信息更新不及时的情况,加上传输过程中网络控制分组的丢失,实际上都会使时隙分配存在冲突,因此,在协议中加入了冲突检测部分,冲突检测可分为接收端冲突检测和发送端冲突检测2类。
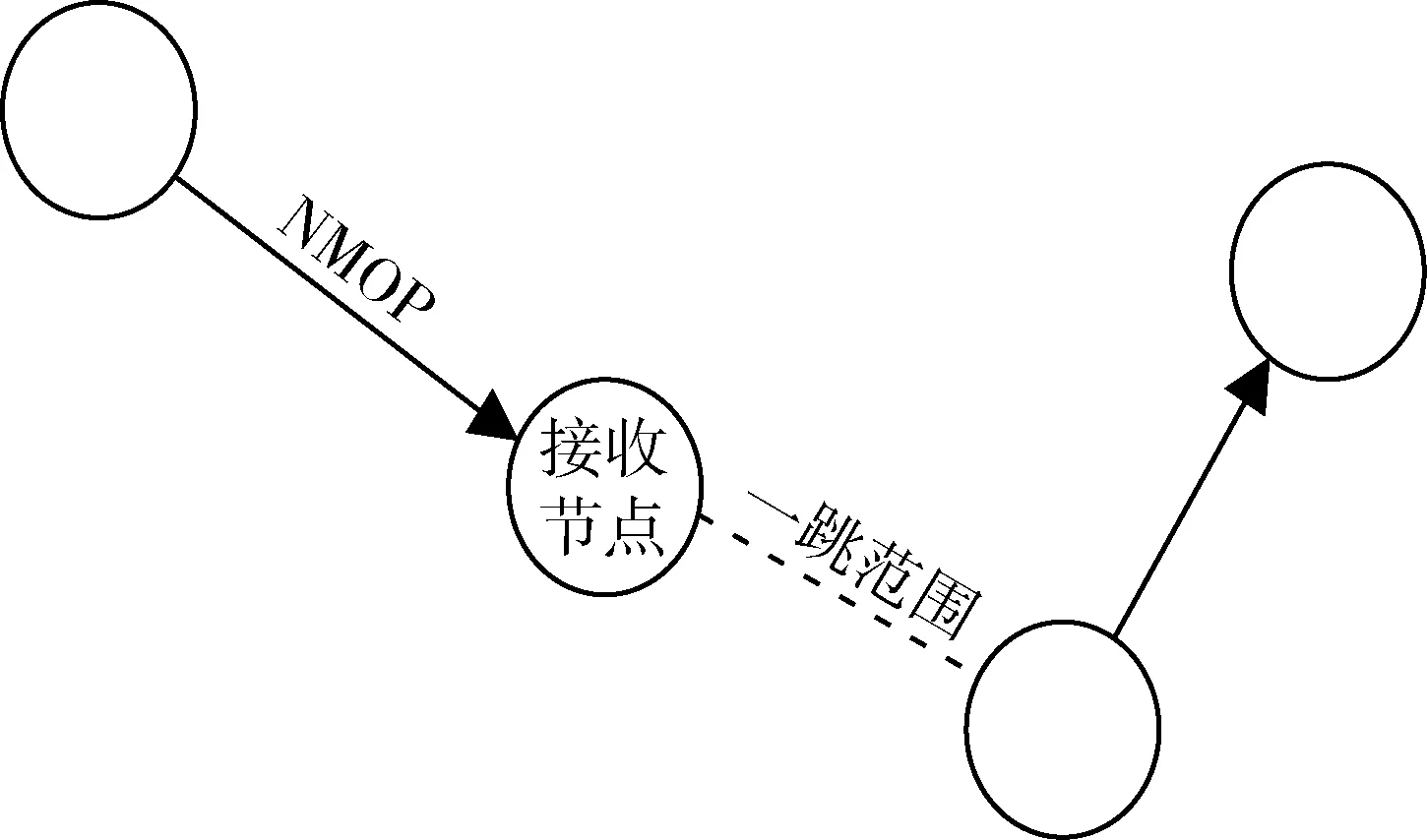
图3 接收端冲突1

图4 接收端冲突2
接收端冲突检测指节点作为接收节点时可以检测到的冲突,分为以下3种:
1)在时隙s,接收节点收到某一节点的接收请求,但是该接收节点存在另一邻节点正在发送消息,且目的节点不是该接收节点,如图3所示;
2)在时隙s,接收节点收到某一节点的接收请求,但该接收节点已被分配接收另一节点发送的消息,如图4所示;
3)在时隙s,节点计划向某一邻节点接收数据,但该接收节点的本地时隙分配表显示该邻节点并未发送数据。
发送端冲突检测指节点作为发送节点可以检测到的冲突,主要用于判断接收节点是否对自己的时隙申请进行了确认,冲突描述如下:目的接收节点发送来的NMOP中的SRNi显示对方在此时没有接收数据。
规定一个时帧中,每个节点能且只能选择一个数据子时隙用于发送数据,当目的节点发生改变,则需要根据本地存储的时隙分配表判断当前数据子时隙是否继续可用,若不能,则需放弃当前时隙并重新选择可用时隙。引导阶段协议工作流程如图5所示,网络中的节点在分配到的引导子时隙内进行时隙选择并将结果存入NMOP发送出去,其一跳范围内的节点在接收到NMOP后进行冲突检测,若不存在冲突,则更新本地时隙分配表,等待自己的引导子时隙并发送网络控制分组,完成对申请时隙的确认。如此,通过节点间信息的交互,完成了节点两跳范围内时隙的无冲突选择和确认。每个节点在接收到NMOP后都要进行发送端冲突和接收端冲突3检测,分别是为了判断自己的接收请求是否被确认和判断邻节点中是否有节点放弃数据子时隙。当节点接收到其它节点的接收请求时,需要进行接收端冲突1、2的判断。若未检测到冲突,节点则根据NMOP中的信息对自身的时隙分配表进行更新。
3 仿真验证
3.1 仿真工具介绍
OMNeT++(Objective Modular Network Testbed in C++)仿真平台是一款面向对象的、基于组件的、模块化的开源网络仿真器,具有较好的组织性和灵活性。一个完整的OMNeT++仿真中一般包含拓扑描述语言NED文件、消息定义文件、简单模块源文件和OMNeT++配置文件4个部分,其中简单模块源文件用于为简单模块编写仿真内核、实现模块功能,是仿真中的核心部分。
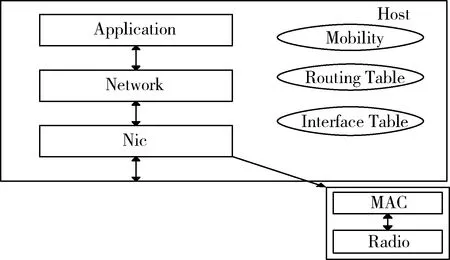
图6 节点构造模型
本文采用了支持在OMNeT++中进行移动无线网络仿真的INET框架,INET协议栈的开发设计采用的是分层结构,只要定义好协议栈间接口不改变,就能独立对各层协议栈进行研究。本次仿真中,节点构造模型如图6所示,其中应用层模块(Application)、网络层模块(Network)和网络接口模块(NIC)起到了数据传输的作用,Mobility模块用于定义网络中节点的移动,Routing Table和Interface Table模块分别为路由表和网络接口列表。
3.2 仿真场景

图7 10节点网络拓扑图
分别设置10节点与16节点网络如图7和8所示,网络为分布式拓扑结构,节点间的连线表示两节点在一跳范围内,可实现直接通信,非一跳范围内节点数据的收发需要其它节点的转发。

图8 16节点网络拓扑图
3.3 仿真参数
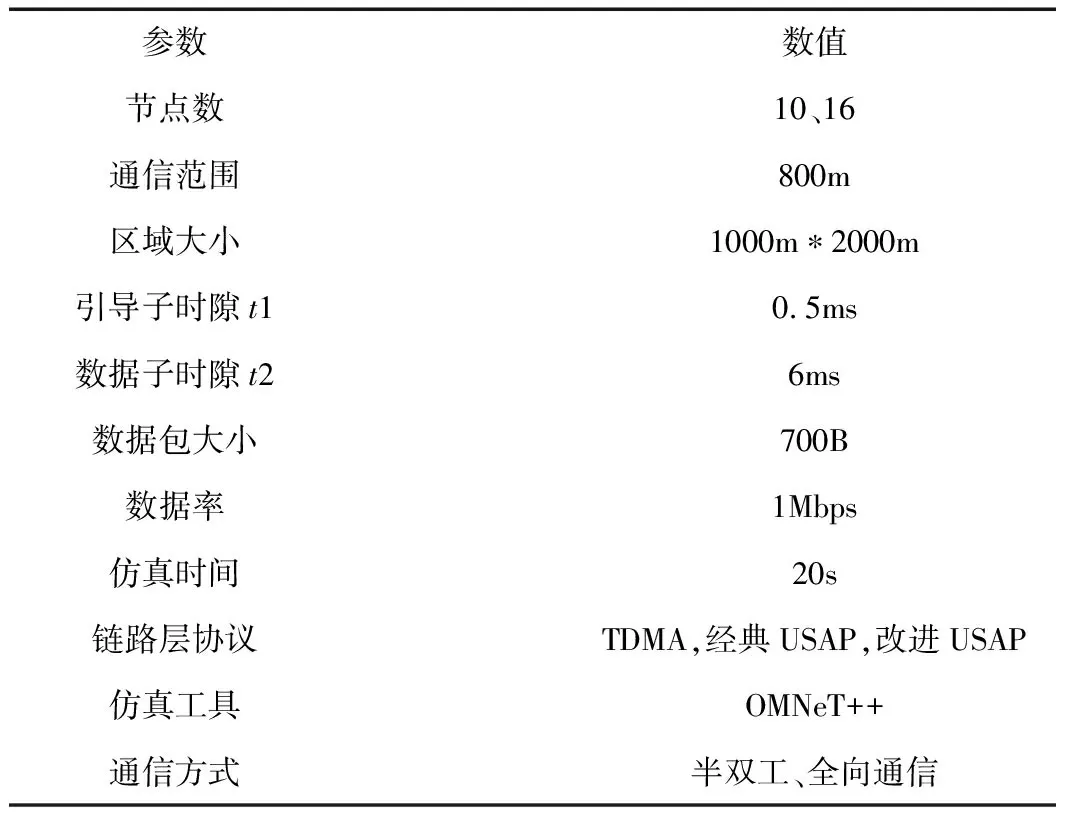
表1 仿真场景参数配置
为存入2.2中描述的所有交互信息,10节点网络的NMOP长度需大于78bit,16节点网络的NMOP长度需大于128bit,NMOP长度受网络节点个数影响较大,文中将NMOP长度设置为416bit以满足更大规模网络设计的需要。对应1Mbps的数据率,将引导子时隙t1长度设置为0.5ms,数据子时隙t2长度设置为6ms。10节点网络对应时帧长度为47ms,引导时隙部分为5ms,16节点网络对应时帧长度为56ms,引导时隙部分为8ms。
3.4 性能指标
1)时隙分配耗时:指开始时隙分配到每个有传输需求的节点都能在一个时帧内实现无冲突传输所用时间;
2)成功收包数:仿真阶段所有目的节点成功接收数据包的个数;
3)平均端到端时延:指数据分组从离开源节点开始到到达目的节点为止所经过的平均时间;
4)总发包数:在仿真时间内,所有节点产生的数据包的个数,用来体现网络负载。
4 实验、结果与分析
利用图7所示的10节点网络对改进USAP进行仿真,截取某一时帧数据时隙对应时间段内消息传输情况如图9所示。在该时帧内,host[4]和host[5],host[7]和host[8],host[6]和host[9]皆在同一数据时隙内实现了消息的无冲突传输。

图9 消息传输情况
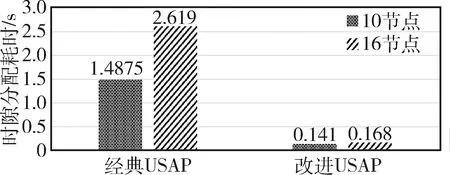
图10 协议时隙分配耗时统计
分别在10节点和16节点的网络中对经典USAP和改进USAP进行仿真,仿真参数见表1,记录时隙分配耗时如图10。由图可知,改进USAP时隙分配耗时远低于经典USAP,10节点网络中耗时缩短了90.52%,16节点网络中耗时缩短了93.59%。并且,在10节点网络中,改进USAP耗时0.141ms,为3个时帧长度,经典USAP耗时1.4875ms,为35个时帧,而在16节点网络中,改进USAP耗时仍为3个时帧,经典USAP耗时增加为54个时帧。由此可知,在10节点和16节点的网络中,改进USAP都只经过了3个时帧便完成了时隙的无冲突分配,在网络规模变化不大的情况下,耗时受节点个数变化影响不大,都可以快速地完成时隙的无冲突分配。然而,经典USAP在10节点网络中经过35个时帧完成时隙分配,在16节点网络中经过54个时帧完成时隙分配,受网络规模影响大。

图11 时隙占用状态统计
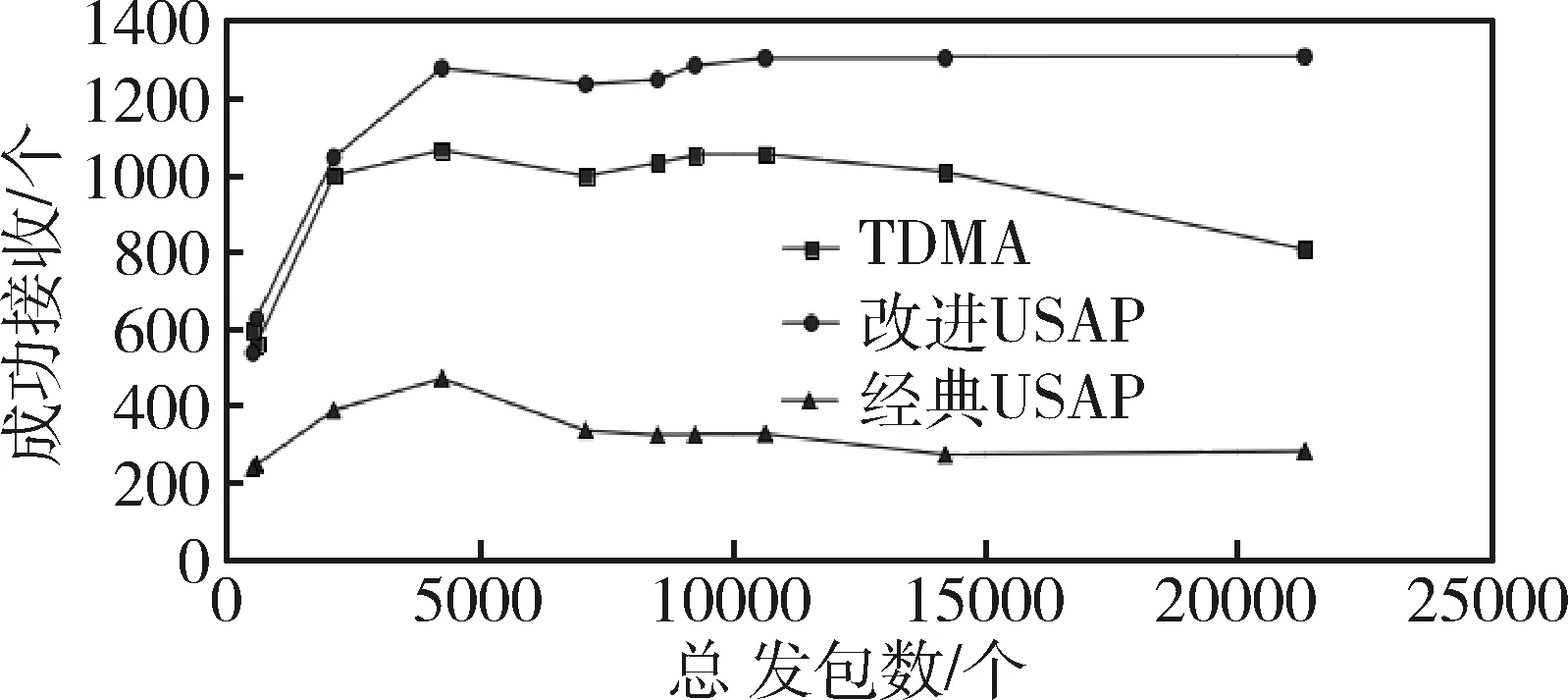
图12 协议成功收包总数统计
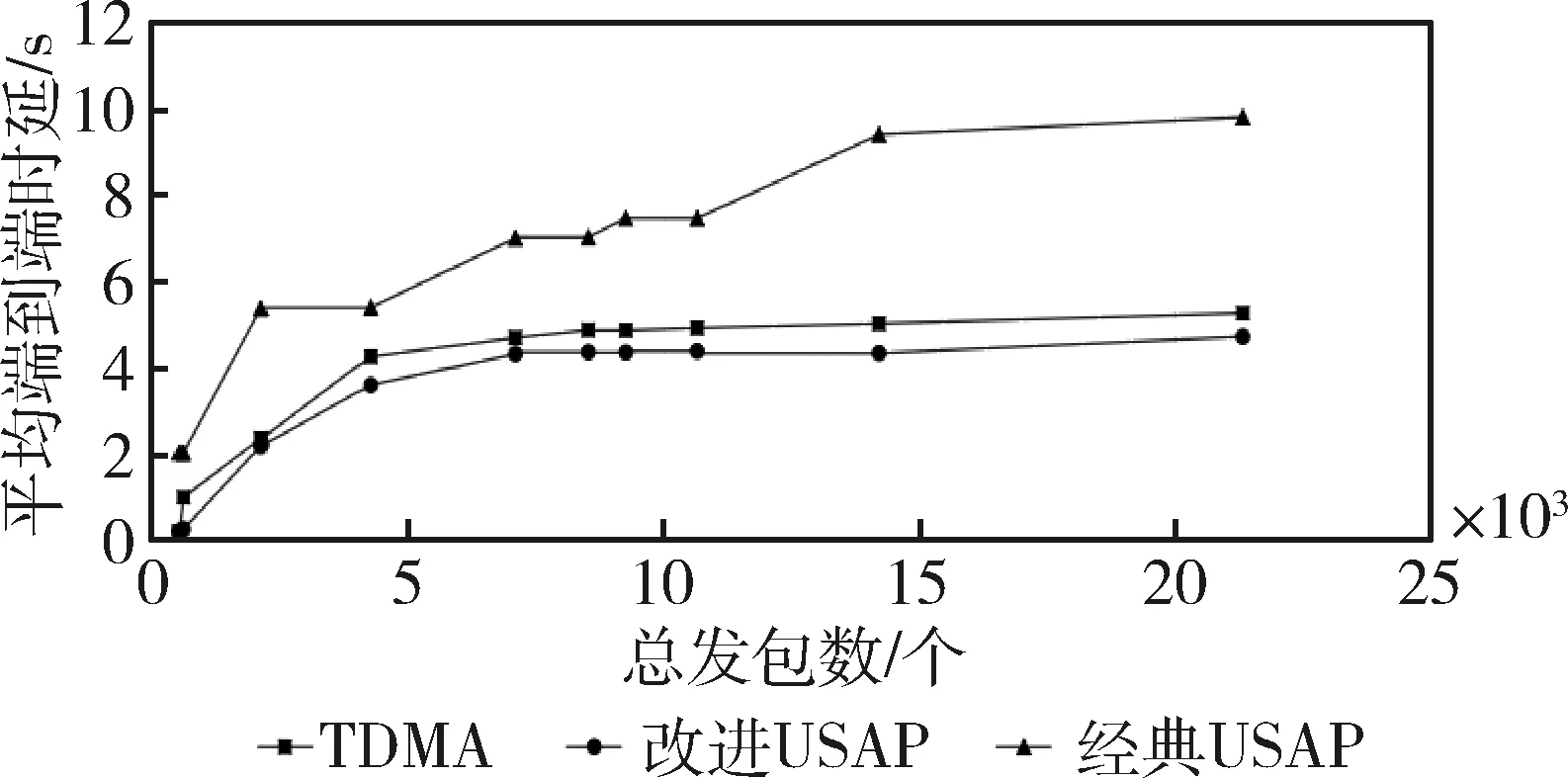
图13 协议平均端到端时延统计
经典USAP无法适应拓扑结构快速变化网络的直接原因是时隙动态分配时间长。USAP对时隙的分配与网络拓扑结构有关,当网络拓扑结构发生变化,节点需要重新选择可用时隙,在这种情况下,节点间信息交互不及时会使得时隙分配耗时过长导致算法难以达到收敛。仿真中,为避免路由请求报文对实验产生干扰,令网络中节点静止,使用静态路由协议,设置每个节点交替地向不同目的节点发送数据包。由于本文规定在一个时帧中,网络中每个节点能且仅能分配到一个数据子时隙,因此,当目的节点发生变化时,节点需要重新选择可用时隙,如此,时隙随着目的节点的变化动态分配,以达到考察不同协议时隙分配效率的目的。当改进后的协议能快速地完成时隙的动态分配这一假设得到验证,则不难知道该协议可以适应动态变化的网络。
利用图7所示的10节点网络分别对TDMA、经典USAP和改进USAP进行仿真,host[0]与host[2]为目的节点,其它节点产生向这两节点传输的数据包。截取0~2s内host[3]对时隙的占用状态如图11所示,状态量为1表示当前有可用时隙,状态量为0表示节点放弃了当前时隙且需要重新选择可用时隙。由图可知,目的节点发生变化,网络内节点不断地对时隙进行动态选择,且很快就能选择到可用时隙。改变发包速度,得到各协议在不同负载下成功的收包数和平均端到端时延,分别如图12和13。由图12可知,改进USAP成功接收数据包的个数随着负载量的增加而增加,直至达到稳定,且整体高于其它两组,经典USAP成功接收数据包数量最低。由图13可知,三者的平均端到端延时都随着网络负载量的增加而增加直至达到稳定。整体上,改进USAP时延最低,经典USAP时延随负载量提高增加明显,且为三者最高。若只从平均端到端时延和成功收包数这两方面来对协议性能进行评估,性能由高到低分别为改进USAP、TDMA和经典USAP。在需要动态分配数据时隙的网络中,经典USAP的性能要低于传统TDMA,并没有起到改善网络性能的作用,这是因为实现时隙无冲突分配的前提是控制帧的及时交互使得每个节点都能及时获取两跳范围内时隙分配情况,但经典USAP信息交互效率低,导致时隙分配算法难以达到收敛,网络内节点无法及时得到可用的数据子时隙而造成了大量时隙浪费,使网络性能降低。改进USAP通过增加一个时帧中引导时隙的个数,提升了节点间信息交互的效率,因此,协议性能得到改善。
5 结论
针对经典USAP在多节点网络中因为时隙分配效率低造成大量时隙浪费,导致网络性能较差的情况,设计了一种基于经典USAP的链路层协议。使用OMNeT++软件进行仿真,分析比较不同协议在同一仿真场景下的性能。结果表明,改进后的USAP在时隙分配效率、时延和收包数3方面的性能较经典USAP有了较大的提升,更适用于多节点Ad Hoc网络。但本文没有在动态网络下对改进USAP的性能进行考察,后续的研究中可结合网络层动态路由对移动网络进行仿真。并且,本实验中使用固定分配的方式为网络内节点分配引导时隙,未考虑节点动态入网的情况,这也将是后续研究的重点。
猜你喜欢
环球时报(2022-04-16)2022-04-16 14:38:15
井冈教育(2020年6期)2020-12-14 03:04:32
铁道通信信号(2020年9期)2020-02-06 09:15:22
数学大王·趣味逻辑(2019年5期)2019-06-13 20:27:43
小学科学(学生版)(2019年5期)2019-05-21 01:00:18
经济技术协作信息(2018年30期)2018-11-22 06:20:24
铁道通信信号(2018年9期)2018-11-10 03:26:46
舰船电子对抗(2016年3期)2016-12-13 05:15:55
广西大学学报(自然科学版)(2016年5期)2016-11-12 06:28:54
计算机工程(2014年10期)2014-06-07 05:53:21
