
LSTM深度学习在短期95598话务工单异动预警中的应用
2019-01-07 05:52景伟强朱蕊倩魏骁雄葛岳军
浙江电力 2018年12期
罗 欣,张 爽,景伟强,朱蕊倩,魏骁雄,陈 博,葛岳军
(1.国网浙江省电力有限公司电力科学研究院,杭州 310014;2.浙江华云信息科技有限公司,杭州 310008)
0 引言
如何预测短期话务工单异动已成为95598日常分析工作的重点和难点[1]。历来依靠人工检阅、手工清理数据进行指标预测的方式已严重跟不上发展需求(分析模式单一、效率低下、及时性差且浪费人力资源)。目前,人为通过同比、环比数值和增幅数值来确定异动阀值,不能实时、准确、科学地设定阀值,导致监控预警、问题定位和趋势预测能力不足[2]。
本文基于深度学习技术,通过建立科学的指标异动预测模型,研究各项指标的数理关系,实现短期话务工单置信异动预测与智能预警应用,从而提高95598指标分析与质量管控的工作效率,发挥辅助决策作用。
1 LSTM神经网络深度学习概述
LSTM(长短期记忆)神经网络是一种改进的时间序列RNN(循环神经网络)[3],由Sepp Hochreiter和Juergen Schmidhuber提出,是循环网络的一种变体,带有所谓长短期记忆单元,可以解决梯度消失的问题。LSTM可以学习时间序列长短期依赖信息,适用于处理和预测时间序列中的间隔和延迟事件[4]。
LSTM将信息存放在循环网络正常信息流之外的门控单元中,这些单元可以存储、写入或读取信息,就像计算机内存中的数据一样[5]。单元通过门的开关判定存储哪些信息,以及何时允许读取、写入或清除信息。LSTM神经网络的记忆功能就是由各层的阀门节点实现的,阀门有3类:遗忘门、输入门和输出门。遗忘门决定何时忘记输出结果,从而为输入序列选择最佳的时间延迟;输入门从外部接受新的输入并处理新来的数据;输出门将计算所有结果并为LSTM神经网络单元生成输出。这些阀门可以打开或关闭,用于判断模型网络的记忆态(之前网络的状态)在该层输出的结果是否达到阈值从而加入到当前该层的计算中[6]。如图1所示,阀门节点利用sigmoid函数将网络的记忆态作为输入计算;如果输出结果达到阈值,则将该阀门输出与当前层的计算结果相乘作为下一层的输入;如果没有达到阈值,则将该输出结果遗忘掉。每一层(包括阀门节点)的权重都会在每一次模型反向传播训练过程中更新。
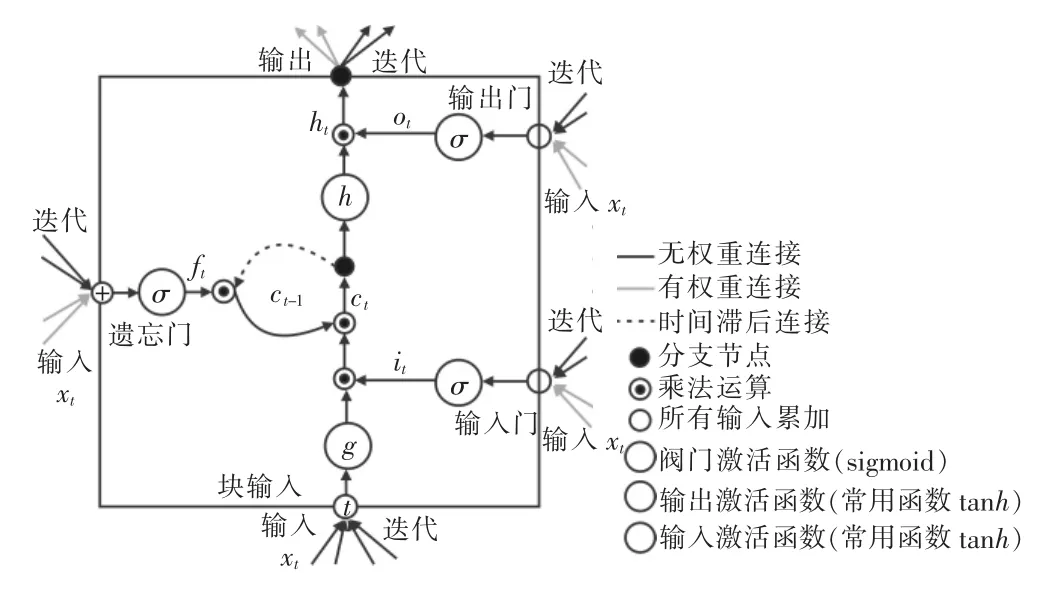
图1 LSTM神经网络细胞的结构原理
这些门依据接收到的信号而开关,并且与神经网络的节点类似,它们会用自有的权重集对信息进行筛选,根据其强度和导入内容决定是否允许信息通过。这些权重就像调制输入和隐藏状态的权重一样,会通过循环网络的学习过程进行调整。也就是说,记忆单元会通过猜测、误差反向传播和用梯度下降调整权重的迭代过程学习何时允许数据进入、离开或被删除。
如图1所示,将输入时间序列表示为X=(x1,x2, …,xn),存储单元的隐藏状态为 H=(h1,h2,…, hn), 输出时间序列为 Y=(y1, y2, …, yn),LSTM神经网络的计算如下[7]:
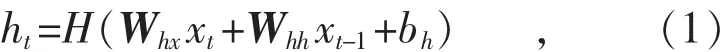
式中:ht表示t时刻隐藏单元状态的输出;xt-1表示t-1时刻输入时间序列;Whx表示时间序列输入xt到隐藏单元状态ht之间的权重向量;Whh表示隐藏单元状态ht与ht-1之间的权重向量;ht-1表示t前一时刻的隐藏单元状态输出;bh表示隐藏单元状态输出ht的偏差。

式中:pt表示t时刻目标预测输出;Why表示隐藏单元状态ht到输出时间序列yt-1之间的权重向量;yt-1表示t前一时刻输出时序数据;by表示目标预测输出pt的偏差。
进一步分解,其中隐藏单元状态计算公式为:
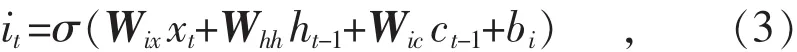
式中:it为输入阀门;Wix表示时间序列输入xt到输入阀门it之间的权重向量;Wic表示输入阀门it到cell状态输出ct-1之间的权重向量;bi表示输入阀门it的偏差;σ表示sigmoid函数。
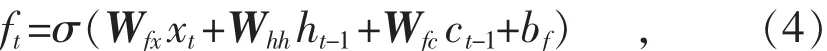
式中:ft表示遗忘阀门;Wfx表示时间序列输入xt到遗忘阀门ft之间的权重向量;Wfc表示遗忘阀门ft到cell状态输出ct-1之间的权重向量;bf表示遗忘阀门ft的偏差。
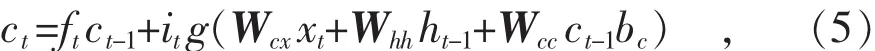
式中:ct表示cell状态输出;Wcx表示时间序列输入xt到前一时刻cell状态输出ct-1之间的权重向量;Wcc表示cell状态输出ct到前一时刻cell状态输出ct-1之间的权重向量;bc表示cell状态输出ct的偏差;g为sigmoid函数,范围为[-2,2]。
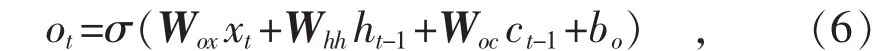
式中:ot表示输出阀门;Wox表示时间序列输入xt到输出阀门ot之间的权重向量;Wox表示输出阀门ot之间的权重向量到cell状态输出ct的权重向量;bo表示输出阀门ot的偏差。

式中:h为sigmoid函数,范围为[-1,1]。

对于目标函数,采用式(9)表示平方损失函数:

2 基于LSTM深度学习的话务工单预测方法
2.1 基于深度学习算法的话务工单预测模型
2.1.1 话务工单预测总体设计
由于在深度学习训练过程中涉及成千上万的神经元经过数亿次权重与偏向最优计算,因此在训练过程中占用计算资源较高。如图2所示,本文提出在线预测与离线学习分离模式的预测模型,在一定周期内对样本数据与增量数据进行模型记忆学习,保证预测模型的适应性与时效性,有利于提升系统整体性能与资源利用率。
2.1.2 基于LSTM深度学习的话务工单预测算法模型结构
在LTSM深度学习算法结构设置方面[8],本文设置6层网络结构,输入层神经元数为10,隐藏层神经元数分别为200,100,200,100,输出目标为1,并选用tanh非线性函数作为隐含层的激活函数,以identity函数作为输出层的激活函数。
如图3所示,{d,y}表示输入变量和输出变量,其中 d[d0,d2,…,d9],d0, …,d9分别表示 t,t-1,…,t-9时的话务量;y为t+1时输出话务量或者 t, t-1,…,t-9 日工单量, mi,fi和 wi分别表示第i层神经元的数量、激活函数和权重;li表示第i层神经元的输出,也是li层神经元的输入;l0表示预测模型的输入l0[d0,d2,…,d9],预测模型的输出是末层神经元的输出l5的y。每一层的输出 li与输入 li-1, fi, wi和 bi的关系见式(10):

2.2 话务工单预测模型的机器学习训练
2.2.1 样本数据分类及归一处理
95598话务数据受单位地域差异、24 h制及工作日与非工作日等客观因素影响,差异明显,同时工单数据还需考虑各业务子类间的差异。因此,话务数据按照供电单位、24 h制和日类型(工作日、周末和节假日)多种维度进行样本数据分类,工单数据则按照供电单位、业务分类和日类型(工作日、周末和节假日)多种维度进行样本数据分类。
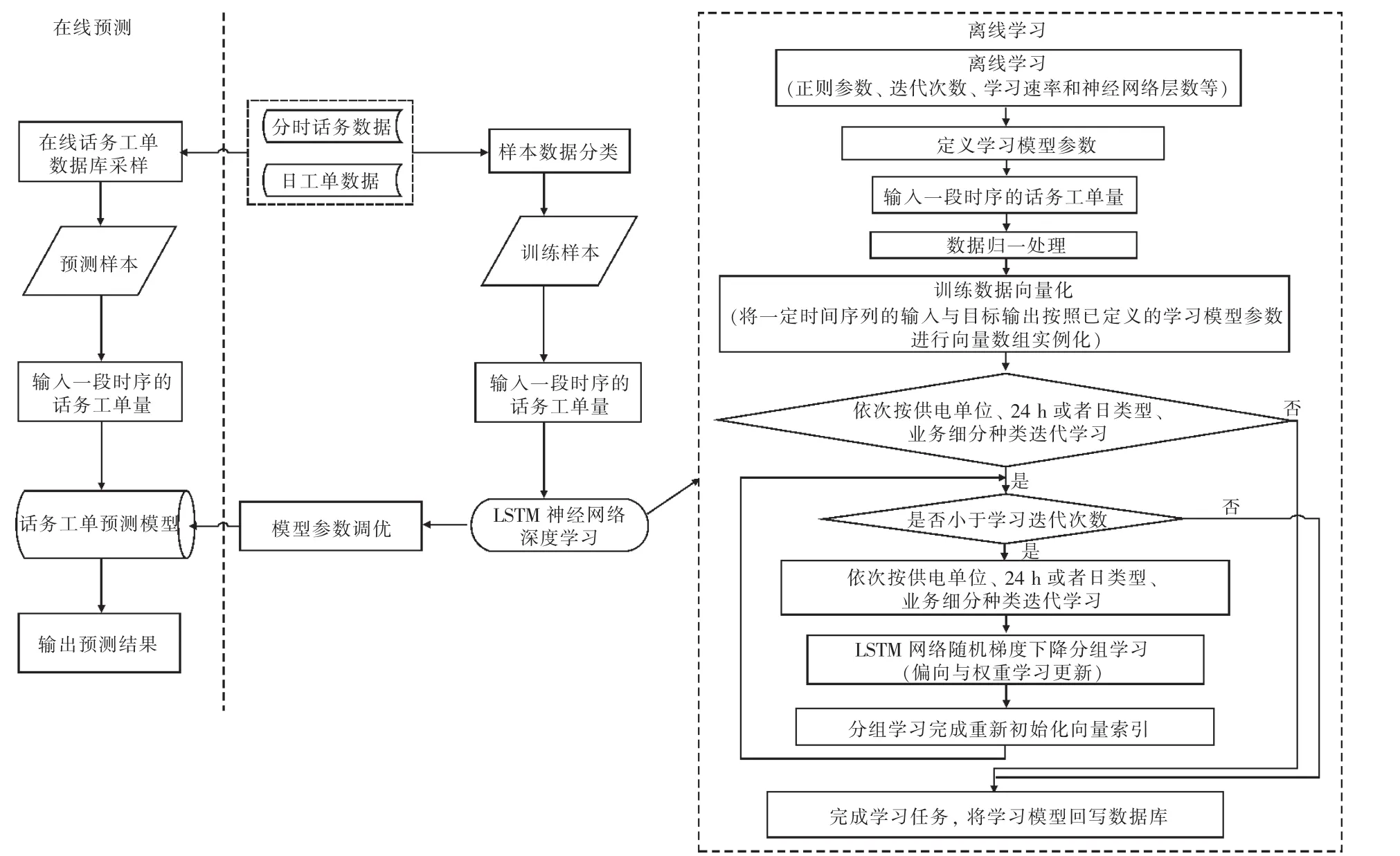
图2 话务工单预测总体设计
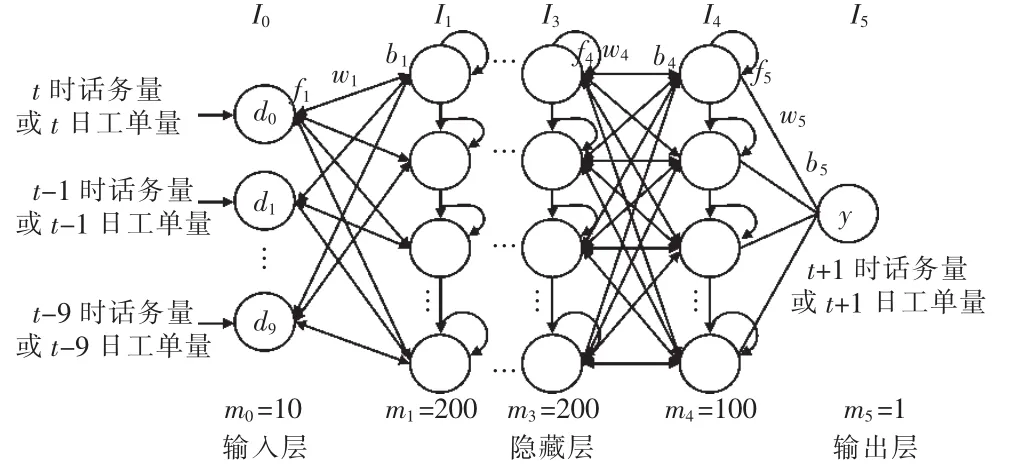
图3 基于LSTM深度学习算法的话务工单预测模型
充分考虑到学习训练过程中激活函数sigmoid和tanh函数的特性,减少数据训练过程中的时间消耗和资源占用,则在机器学习训练过程对各维度的时间序列样本输入数据进行归一化[9-10]处理,将样本数据规范化至[0,1]范围,当在数据预测过程中对目标输出进行反归一化时,则计算公式为:
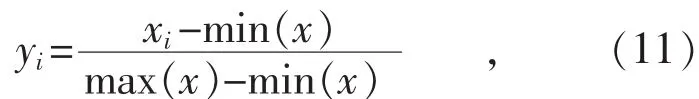
式中:xi表示时间序列第i时刻的输入;x表示所有时间序列输入;yi表示归一化目标值。
2.2.2 随机梯度下降学习训练策略
基于深度学习的话务工单预测模型的机器学习训练主要应用随机梯度下降算法对所有参数进行统一训练,以调整隐含层参数并最终获得输出层参数[11]。
话务工单预测模型学习训练的目的是找到能最小化二次损失函数C(w,b)的权重和偏向。其中权重w和偏向b的更新规则方程为:
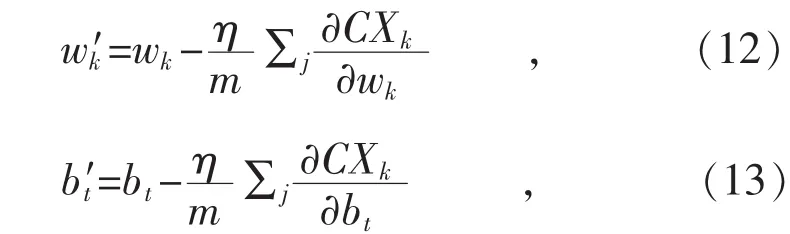
式中:Xk为所有话务工单学习训练样本中取第k个输入最小采样块;m为所有话务工单学习训练样本分割最小采样块总数;η为学习步长;l为所在网络层;为损失函数C(w,b)基于权重w的微积分偏导;为损失函数 C(w, b)基于偏向b的微积分偏导。
2.3 话务工单异动预警预测
通过机器学习训练的话务工单预测模型[12],可实现话务工单随着时间自适应学习进行动态智能预测,但目标输出的话务工单数据只能作为理论预测值,将预测值上限与下限作为合理置信区间,根据实际业务需求设置异动预警系数,则异动预警阀值公式为:

式中:ywarn表示公式中定义的话务工单置信异动区间;ytheory表示话务工单理论预测值;δwarn表示置信异动系数,默认取20%。
在基于时间序列不断学习预测过程中,为避免非正常异动突增话务工单数据干扰模型进而导致预测趋势变形,需要对样本预测数据进行自动修正处理。
如图 4 所示, 某单位某日 11:00—18:00 出现话务明显突增的情况,如果在机器学习预测过程中依据话务突增数据作为输入样本数据,则会出现如图4所示13:00—17:00的理论预测值与预警阀值的曲线明显变形,从而影响话务异动自动预警诊断。通过对话务突增明显的数据进行理论值自动修正,可采取昨日同时段同单位的理论预测值作为该异动修正值,如图 5所示,13:00—17:00的理论预测值与预警阀值曲线显示正常。
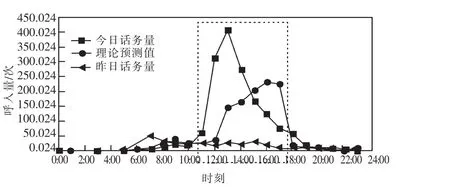
图4 未经修正的话务学习预测异动预警
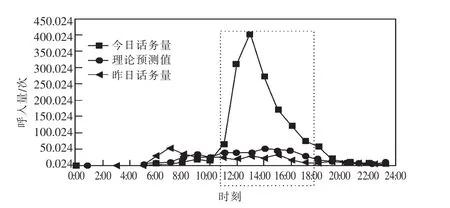
图5 经修正的话务学习预测异动预警
3 实例分析
3.1 系统数据集及误差评价指标
系统应用数据来源于浙江电网某地区采集的95598分时话务量数据和每日各业务工单量数据。其中95598的话务工单量是一种受多种因素影响的非线性时间序列数据,这些因素可能包含用电负荷、气象等外部主观因素,同时也包含分时类型(22:00—7:00 低峰时段、 8:00—11:00 高峰时段、 14:00—17:00 高峰时段)、 日类型(工作日、 周末和节假日)和单位差异等客观因素[13]。这些客观因素在一定时间序列下存在动态非线性关系,通过机器学习各类因素数理关系,对话务工单预测与异动预警精确度具有重要意义。
涉及业务工单数据,根据国家电网95598业务类型分类,包括故障报修、业务咨询、投诉、举报、建议、意见、服务申请和表扬。同时这些业务细分有448种,如表1所示。

表1 95598业务细分种类对应种
对于话务工单预测准确度的评价[14-15],本文选取准确率P和平均绝对百分比误差EMAPE作为评价标准:
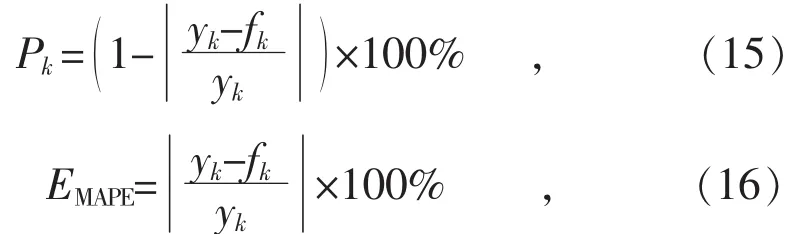
式中:yk和fk分别为k时刻的实际话务工单量和理论预测值。
3.2 模型参数设置
在模型训练与预测过程中,通过观察比对损失函数下降趋势和准确率来权衡模型参数设置。
本文所采用的LSTM神经网络模型参数如表2所示。为更好地适应实际应用,进行了多次实验测试以获得更好的性能参数。经实验反复验证,批量大小设置为30个,准确率相对稳定。其中1个Epoch(迭代次数)表示所有的训练样本数据全部通过网络训练1次。
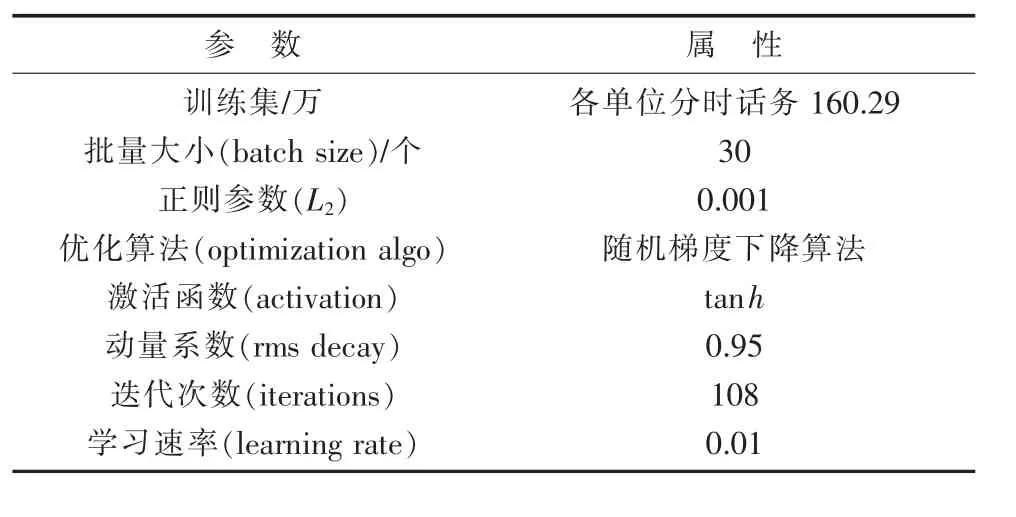
表2 LSTM深度学习模型训练参数
由图6、图7可知,不同的学习速率对损失函数和准确率影响明显,Epoch(1个Epoch等于全部样本集中训练一次)值达到108次左右损失函数趋于稳定,则迭代次数iterations(1个iteration等于使用1个Batch大小样本训练一次)取值108;同时结合图中损失函数与准确率趋势,则学习速率设置为0.01。
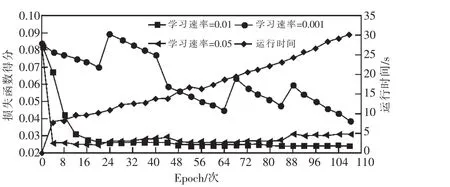
图6 训练过程中不同学习速率与损失函数对比结果
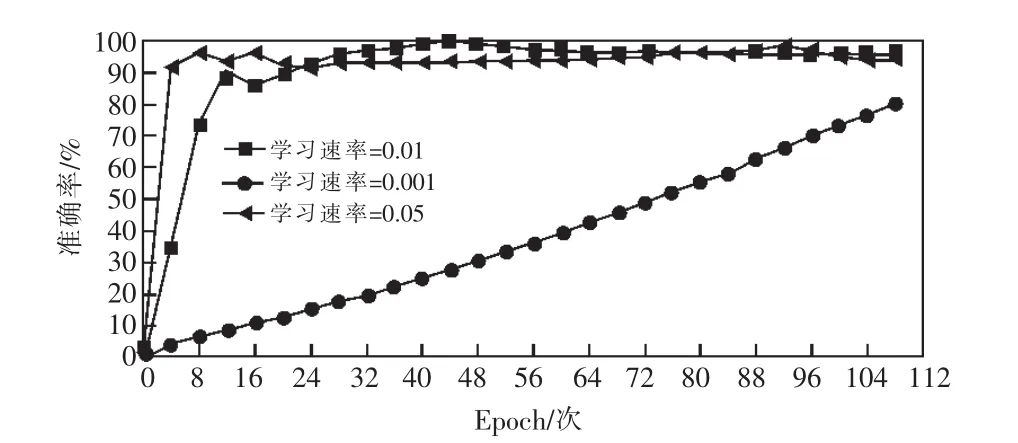
图7 训练过程中不同学习速率与准确率对比结果
由图8、图9可知,不同L2正则参数对损失函数影响相对明显,但对准确率影响相对较少,则正则参数(L2)设置为 0.001。
如图10所示,不同的激活函数对准确率影响明显,由图10趋势可以看出隐藏层的激活函数应该选择tanh函数。
如图11所示,不同动量系数对准确率影响相对较少,则动量系数采用默认设置为0.95,有利于更快的性能来递归神经网络模型。
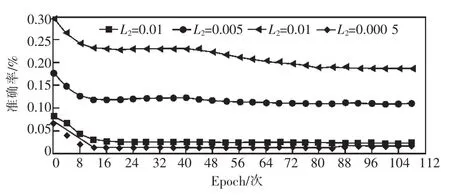
图8 训练过程中不同正则参数(L2)与损失函数对比结果
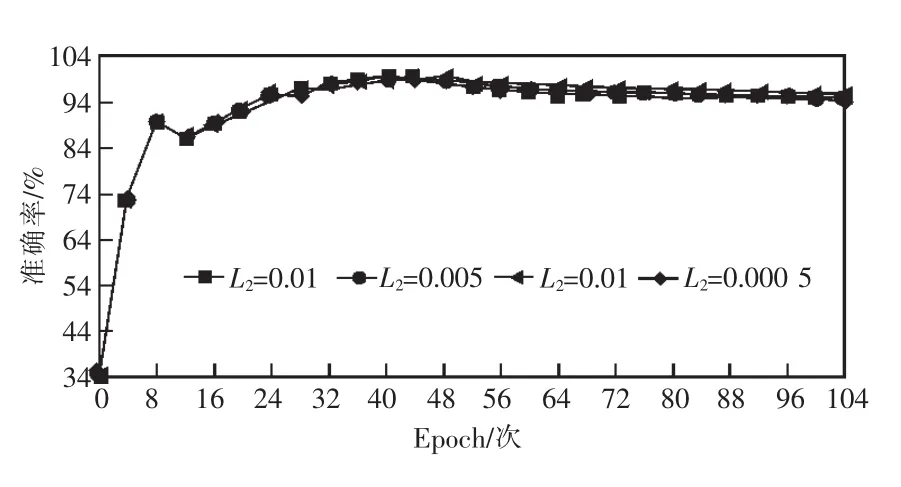
图9 训练过程中不同正则参数(L2)与准确率对比结果
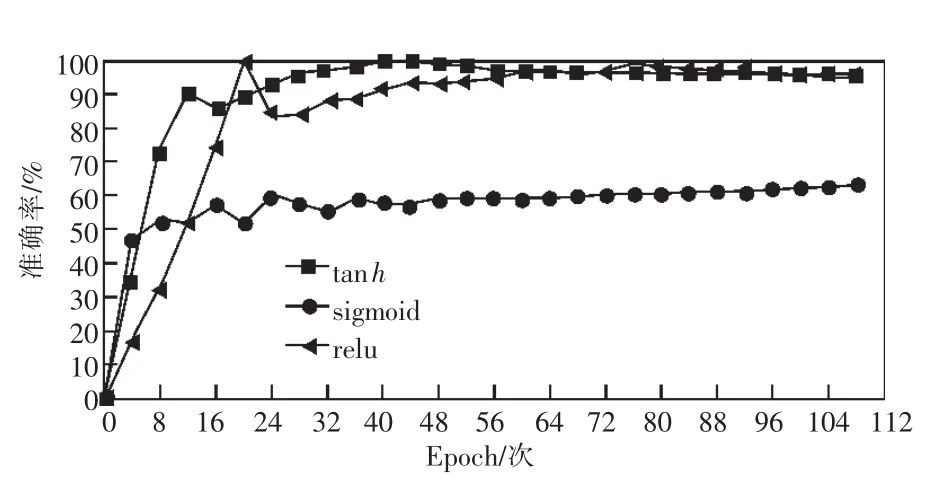
图10 训练过程中不同激活函数与准确率对比结果
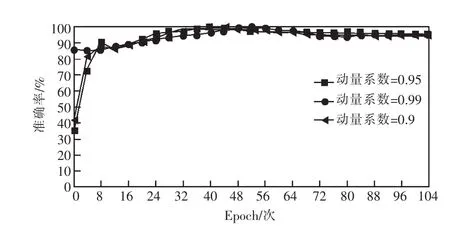
图11 训练过程中不同动量系数与准确率对比结果
3.3 预测结果分析
在对某地市公司7:00近150天话务样本机器学习训练过程研究发现,损失函数得分与训练准确率之间关联紧密[16-18],如图12所示。损失函数得分随着迭代次数的增加而趋于稳定,训练的准确率会随着训练迭代次数的增加而逐步增加,最终稳定的训练准确性预测结果为91.08%左右。
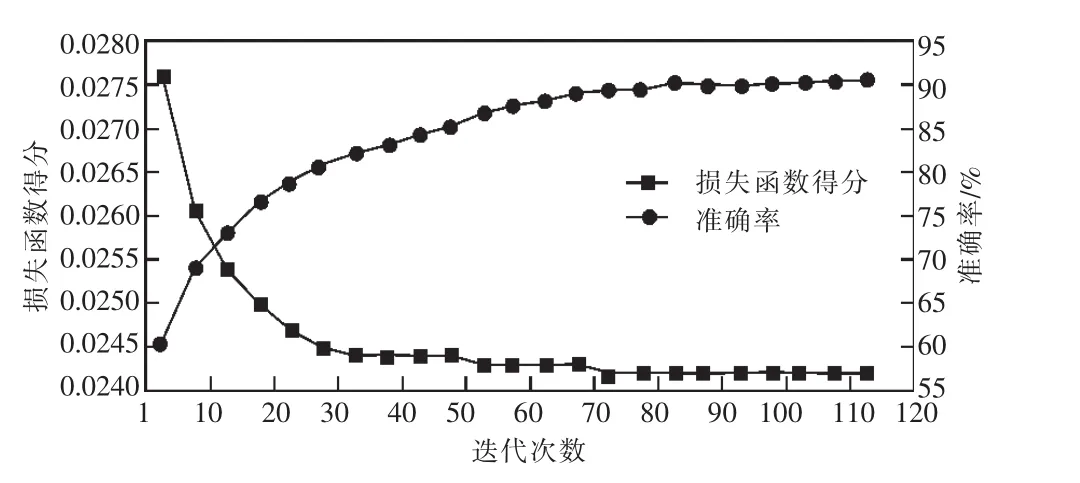
图12 训练过程中损失函数与准确率关系
使用准确率P和平均绝对百分比误差EMAPE分析评价指标对某地市公司工作日与非工作日话务预测结果进行评价,由表3可知:总体预测结果符合预期,预测准确率在90.19%以上,这其中并未排除不可预见人为因素引起的话务波动导致模型预测结果发生偏移。
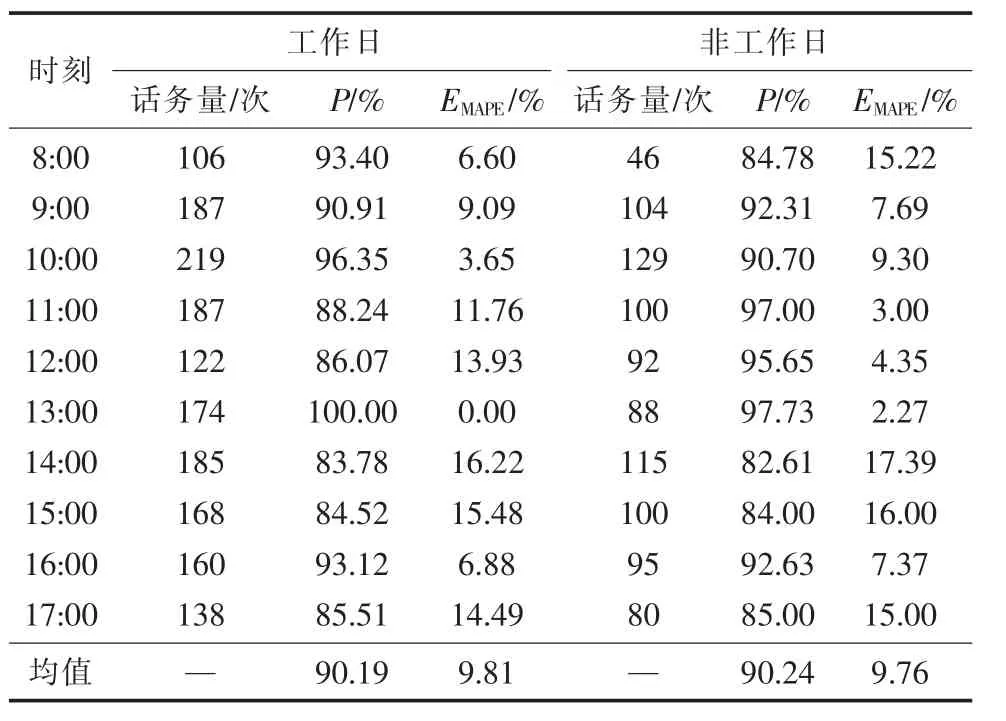
表3 话务工作日与非工作预测结果对比
由图13可知,预测的日话务曲线与理论预测曲线的吻合度比较高[19-21]。其中每月5日左右为话务规律性突增,图13中话务低谷2月14—22日为春节放假期间,由于春节期间话务属于非典型节假日话务变化,需要结合历年春节这段时间单独建模学习与预测,这样才能保证良好的预测结果。
针对某县公司的服务申请业务用电异常来核实这一类工单预测异动情况,图14直观显示1月11日、2月2日—7日这几天发生工单量明显异动,超出理论预测值和预警异动阀值,从而可快速引导业务分析人员定位问题。
4 结语
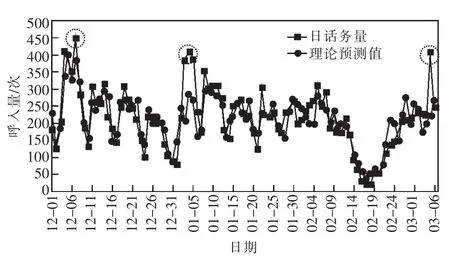
图13 近100天话务预测趋势
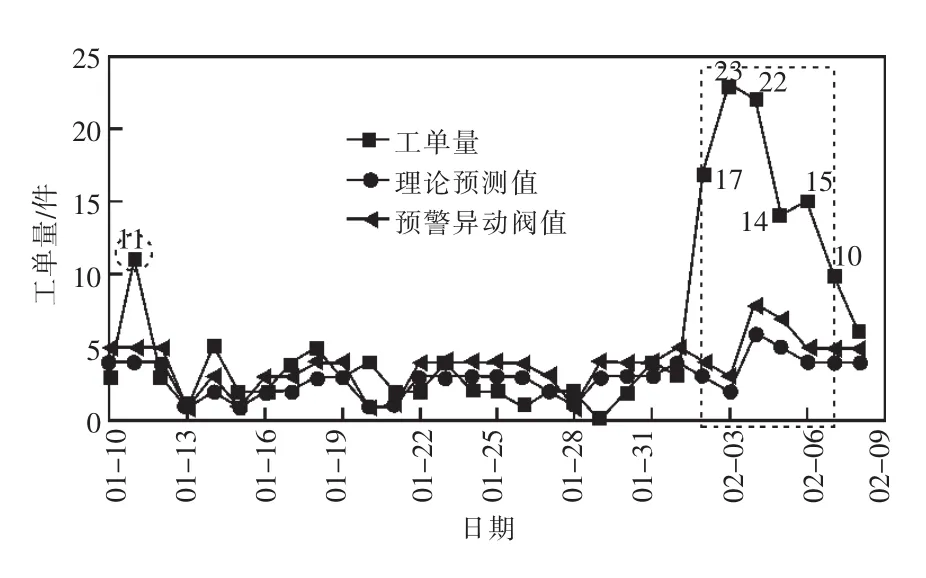
图14 用电异常核实工单预测异动趋势
本文提出了一种基于LSTM神经网络深度学习建模的短期95598话务工单预测异动预警方法,这是第一次将深度学习建模应用于95598话务工单预测的异动预警中。与以往的话务工单异动分析方法只关注于话务工单浅层结构的梳理关系不同,通过基于LSTM深度学习的话务工单预测方法,构建面向95598的时间序列预测与智能异动预警相结合的综合辅助支撑技术,实现技术创新改变工作方式,用数据说话,更高效、更精益、更智能地从大量指标中取得指标分析预警,提高了95598指标分析与质量管控的工作效率。
猜你喜欢
流程工业(2022年3期)2022-06-23
心理学报(2022年5期)2022-05-16
煤气与热力(2021年3期)2021-06-09
当代陕西(2020年17期)2020-10-28
信息技术时代·中旬刊(2019年1期)2019-10-21
人大建设(2018年5期)2018-08-16
中学科技(2014年11期)2014-12-25
太空探索(2014年3期)2014-07-10
郑州大学学报(理学版)(2012年4期)2012-03-25
中国新技术新产品(2010年6期)2010-09-07
