
低信噪比下高可懂度语音增强算法①
2019-01-07 02:41刘鹏
计算机系统应用 2018年12期
刘 鹏
(山西工程技术学院 信息工程与自动化系,阳泉 045000)
语音增强算法的评估表明,语音增强算法仅能通过抑制背景噪声来增强带噪语音的听觉舒适度以改善语音的质量,但却无法显著提高带噪语音的可懂度,大多仅可以保持语音的可懂度[1,2].事实上,在低信噪比的恶劣条件下,改善带噪语音质量的同时经常会伴有语音可懂度的降低.这是由于在抑制背景噪声的过程中导致原有纯净语音信号发生了较大失真,造成了语音可懂度信息的丢失,影响了听者的正确理解[3].现有的语音增强算法大都只使用最小均方误差(MMSE)来降低语音失真[4],却忽略了语音增强算法所导致的语音失真对差异类型语音分段的可懂度影响程度不同.
Chen F,Loizou PC 等学者基于信噪比相对均方根(Root-Mean-Square,RMS)对短时语音分段进行了分类研究得到:高均方根片段(短时信噪比不小于整体均方根的片段)、中均方根片段(短时信噪比小于整体均方根但不小于–10 dB整体均方根的片段)和低均方根片段(短时信噪比小于–10 dB整体均方根但不小于–30 dB整体均方根的片段).研究表明,中均方根分段包含大多数辅音-元音边界,更准确地模拟了语音可懂度[5].Wang L,Chen F 等学者利用 RMS 对语音信号进行分割,评估了基于RMS分割的语音信号边界如何影响语言可懂度预测的表现[6].Guan T,Chu GX 等学者将语音增强算法处理后的语音按照信噪比相对均方根分段研究后发现:语音增强算法所导致的语音失真对中均方根分段的可懂度影响更为严重,而这正是导致增强后语音可懂度下降的一个重要原因[7].
本文在子空间语音增强算法的基础上进行改进,提出了基于RMS分段的低信噪比下高可懂度子空间语音增强算法.该算法借助先验信噪比RMS对带噪语音的短时分段进行了分类增强,通过调整处于信噪比中均方根语音分段的增益矩阵分量来进一步减小中均方根分段的语音失真,降低了语音失真对增强语音可懂度的影响,从而在低信噪比条件下实现了增强后语音可懂度的提高.
1 子空间增强算法
假定纯净语音信号为x,带噪语音y与加性噪声d互不相关,即有y=x+d,其中y,x和d都是K维信号矢量.令为增强语音,H为在语音信号最小失真情况下的线性最优估计器,其维数为K×K.则有,且该估计器的误差信号ε为:

其中,εx和 εd分别表示语音信号的失真和残留噪声.εx的能量表示为:

定义


公式(4)中,αk为正常数.
经过矩阵特征值分解及公式化简[8,9],求解出约束方程(4)的解为:
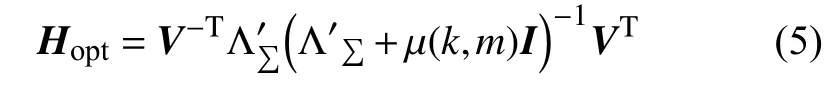
其中,µ(k,m)为短时帧m的第k个谱分量的Lagrange乘数,V是矩阵 Σ 的特征向量矩阵,是由矩阵 Σ 的非负特征值构成的矩阵(负值以零代换),即对于第m帧,第k个谱分量有:

因此,第m帧的增益矩阵为:

G(m)的第k个对角元素g(k,m)表示为:

Lagrange乘数µ (k,m)由下式确定:
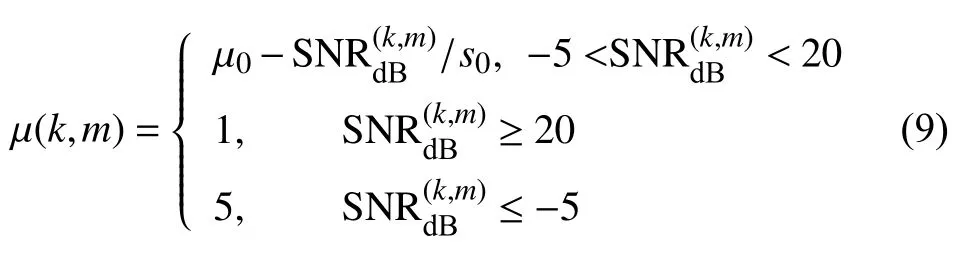
μ0和s0是由实验确定的常数,实验中μ0=4.2,s0=6.25.帧m的第k个谱分量的信噪比借助相应后验信噪比γ(k,m)作为其估计值,即10lgγ(k,m),且后验信噪比γ(k,m)可由公式 (10)求出.
习近平在谈到古丝绸之路的历史渊源时说到,“我们的先辈筚路蓝缕,开辟出联通亚欧非的陆上丝绸之路;我们的先辈扬帆远航,闯荡出连接东西方的海上丝绸之路”,以此阐明“一带一路”倡议不是没有根据的凭空想象,而是古丝路的一种新时代的延伸。他同时也指出,“历史是最好的老师”暗示我们要像我们的先辈那样携手推行“一带一路”倡议,增强了沿线各国建设“一带一路”的使命感。

因此,按照子空间算法增强后的语音为:
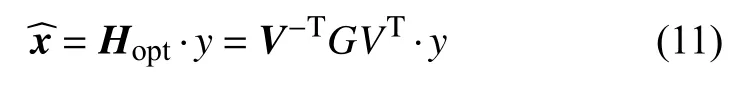
2 子空间算法改进
基于先验信噪比相对均方根对短时语音分段按照如下公式确定类型:

借助公式(12)可以实现基于短时先验信噪比的RMS语音段分类,进而筛选出受语音失真可懂度影响更为严重的中均方根分段(对应公式中的M-level).其中,ξ(m)代表帧m的先验信噪比,ξRMS代表含噪语音短时分段的先验信噪比相对均方根,其计算公式如下:

令ξ(k,m)为帧m第k个谱分量的先验信噪比,可借助“直接判决”法[10]和公式推导[11]依据下式确定其值:

其中,α为平滑系数,通常在 0.8 至 1 区间取值,改进算法中其取值为0.98.公式(14)表明,语音增强过程中语音分段的先验信噪比可由增益矩阵和后验信噪比估计得出.公式(14)中第m–1帧第k个谱分量的增益矩阵元素g(k,m-1)和后验信噪比 γ (k,m-1)可分别通过公式(8)和公式(10)求出.
相关研究表明[12],低信噪比(信噪比小于零)的条件下,信噪比和增益矩阵的估计值高于其真实值也是增强后语音可懂度降低的一个重要原因.对带噪语音进行短时分段处理后,由于原语音增强算法中语音失真对中均方根分段的可懂度影响更为严重,因此可以通过文献[12]提出的人工引入偏差的方法来调整增益函数,调整公式(12)中对应的中均方根区域(M-level)的增益函数值,具体依照公式(15)对增强算法的增益矩阵分量进行调整,来进一步减小低信噪比条件下中均方根分段的语音失真,从而有效提高增强语音的可懂度.
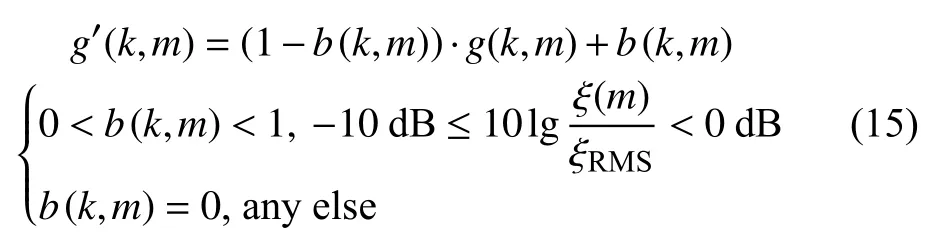
公式 (15)中,b(k,m)为增益调整系数,实验中当时将 b (k,m)在区间[0.1,0.9]分别以步长0.1取值发现,b(k,m)=0.2所得到的效果最好.G'(M)为基于短时先验信噪比RMS分类调整后的增益矩阵,可由公式(16)求出.

因此,依据改进算法,具体的实施步骤如下:
(1)按照子空间增强算法计算得到原有增益矩阵G;
(2)依据公式(12)将语音分段基于短时先验信噪比RMS进行分类,筛选出受语音失真可懂度影响更为严重的中均方根分段(M-level);
(3)根据公式 (15)确定增益调整系数b(k,m),进而通过公式(16)得到调整后的增益矩阵G'.(4)最后,改进增强后的语音为:
3 实验结果与分析
为了研究改进算法对带噪语音可懂度的提升效果,在Matlab平台开展模拟实验.背景噪声来源于NOISEX-92 中的 babble,car,street和 train,纯净语音材料来源于“普通话言语测听材料MSTMs”[13].实验中选取MSTMs中语句测试表的60个句子,按照选定的信噪比加入同一类噪声,再通过选定的方式处理后获得一个测试条件(condition).对带噪语音的增强处理方式有:加噪未处理,原算法处理和改进算法处理.实验中语音可懂度的评价分别选用了客观评价法和主观试听法.语音可懂度客观评价和主观试听均在4种噪声(babble,car,street和 train)、3 种低信噪比 (–5 dB、–10 dB和–15 dB)和3种处理方式的条件下进行,分别产生了36个测试条件.实验中信号的采样频率统一为8 kHz,量化精度为16 bit,改进算法中带噪语音按照16 ms进行短时分段处理.
3.1 客观评价结果与分析
语音可懂度客观评价选用归一化协方差(Normalized Covariance Metric,NCM)评价法[14].相关研究说明[15],归一化协方差(NCM)法与主观试听的相关度r=0.89,其预测的标准偏差σe=0.07,优于PESQ[14](r=0.79,σe=0.11)等其它客观方法.实验中把选取的MSTMs中60个日常句子的归一化协方差NCM平均值分别作为相应测试条件下语音可懂度的客观评价值.表1~表3给出了实验中语音可懂度的NCM评价结果.

表1 信噪比SNR=–5 dB,不同条件下语音的 NCM 值
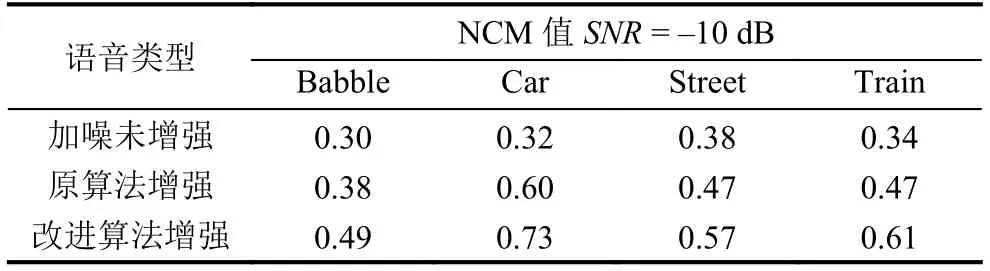
表2 信噪比SNR=–10 dB,不同条件下语音的 NCM 值

表3 信噪比SNR=–15 dB,不同条件下语音的 NCM 值
归一化协方差(NCM)评测值与主观试听可懂度正相关,因此处理后的带噪语音NCM值越大说明其主观可懂度越高.从表1~表3语音NCM测试值的对比可以看出:改进算法由于对增益矩阵进行了调整,进一步减小了低信噪比条件下中均方根分段的语音失真,而这种失真对语音整体的可懂度具有较大影响,所以相较于其它两种对带噪语音的处理(加噪未增强和原算法增强),改进算法增强提高了增强后带噪语音的可懂度.
3.2 主观试听结果与分析
可懂度主观试听实验招募了27名在校大学生作为试听对象.为了防止重复试听所导致的人为记忆对测试结果的影响,试听采取3人分组,每组只对选定的信噪比条件下的单一处理方式语音进行试听,测试条件下的可懂度主观试听值为试听中3人准确识别率的均值.表4~表6给出了实验中可懂度主观试听的评价结果.

表4 信噪比SNR=–5 dB,不同条件下语音的主观试听值

表5 信噪比SNR=–10 dB,不同条件下语音的主观试听值
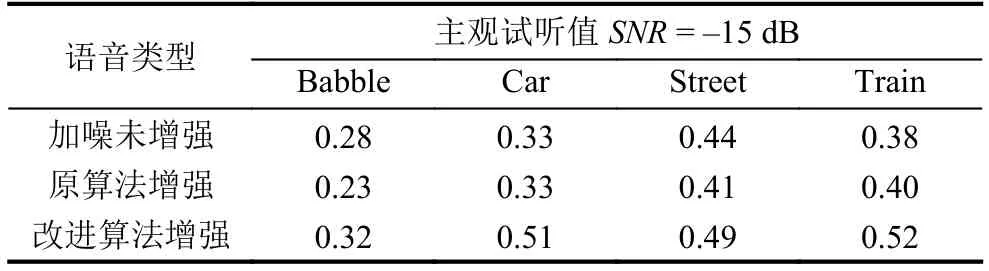
表6 信噪比SNR=–15 dB,不同条件下语音的主观试听值
由于语音增强算法所导致的语音失真对中均方根分段的可懂度影响更为严重,在低信噪比的恶劣条件下对语音整体可懂度影响很大,调整中均方根分段的增益分量后,增强语音的主观试听清晰度得到改善.因此,改进算法将带噪语音基于短时分段信噪比均方根分类增强,实现了低信噪比条件下增强语音可懂度的提高.
4 结论语
本文在子空间语音增强算法的基础上提出了低信噪比条件下基于短时分段信噪比RMS分类增强的改进算法.该算法基于短时信噪比RMS判断语音分段类型,然后针对中均方根分段适当调整增益矩阵分量,改进了现有算法单纯基于最小均方误差(MMSE)来抑制语音失真却忽略了失真对差异类型语音分段的影响程度不同这一不足,进一步降低了低信噪比条件下语音失真对降噪后语音可懂度的影响.在模拟实验中,选取NCM评价法和主观试听法分别对改进算法的语音可懂度性能开展了客观和主观对比实验验证.结果表明,改进算法有效提高了低信噪比条件下增强语音的可懂度.但值得注意的是,本文所提出的子空间改进算法相较于原算法多增加了一个后置滤波的过程,这将一定程度上增加算法的复杂度.因此,在非低信噪比的条件下(信噪比大于零),由于原有算法导致的语音失真对可懂度影响并不严重,此时不适合使用本文所提出的改进算法.
猜你喜欢
心理学报(2022年10期)2022-10-12
现代仪器与医疗(2022年1期)2022-04-19
北京理工大学学报(2021年12期)2022-01-13
北京航空航天大学学报(2021年6期)2021-07-20
电声技术(2020年7期)2020-12-16
舰船电子对抗(2020年1期)2020-04-27
电子制作(2019年19期)2019-11-23
北京航空航天大学学报(2019年9期)2019-10-26
飞天(2019年6期)2019-07-08
新高考·高二数学(2015年2期)2015-05-27
