
实时演进数据序列集的内在模式提取与行为预测①
2019-01-07 02:40艾锐峰欧阳军孙云鹏
计算机系统应用 2018年12期
艾锐峰,欧阳军,程 杰,周 凯,孙云鹏
1(解放军 63850 部队 总体所,白城 137001)
2(解放军 63850 部队 水文装备试验站,烟台 264100)
借由数据集合内在模式的提取、内涵知识的挖掘 形成有价值的信息,以用于分析、评估、预测和控制,是目前大数据和人工智能领域的主要研究内容之一[1,2].当根据应用场景和数据特点对数据进行处理时,若从时间纬度进行考察,可分为:① 无时序要求,即数据本身是一种事物性逻辑关联关系而非时间序列,或者数据为时间序列其处理应用无时序要求[3,4];② 严时序要求,即数据本身为时间序列,对其处理是利用历史时间序列分析实现对紧随其后的预测、控制等[5,6];③ 介于二者之间,数据本身包含时间序列集和非时间序列集,通过对其处理以用于未来[7,8].第三种数据集具有普遍性,应用于各种领域[9,10].第一种数据集也可按照数据收集的时间戳构建成时序序列结构[11],以用于描述所代表事物的演进过程.
通过实时演进的数据序列集的分析处理实现对事物未来行为的预测是数据分析的主要目的之一.基于数据挖掘的行为预测,从整个处理流程来看,要实现从序列的建模、分割、相似性度量与搜索、聚类与分类、在线模式匹配,到最终的预测决策.目前的研究主要集中在序列的分割[12,13],相似性搜索[14],相似性度量[15],序列的建模、聚类和分类[16–20]等方面,侧重于单一方法的性能提升,对融合整个流程以提升预测性能需要深入研究.文献[21,22]介绍了一类模式挖掘方法,主要用于从数据库中提取频繁出现的特定模式以找出数据的某种特性,为静态分析,对实时演化的时间序列集的行为预测缺乏论述.文献[23]试图通过序列的模糊比对实现预测,但参入比对的序列为现时子序列,现时子序列如何延展到未来时刻没有分析.文献 [24,25] 给出了多尺度融合的数据挖掘方法,但对挖掘后的预测没有做进一步的研究.文献[26]给出了对复杂系统数据挖掘分层建模的方法,其所构建的模型对历史数据的拟合很好,但是其预测效果并没有定量给出.目前实用的时间序列预测方法为传统的ARIMA类方法,但在非平稳条件及混沌情况下,性能下降.
综上所述,通过数据挖掘的方法可以对实时演进数据序列集在特定情况下的未来行为作预测,但应当在模式提取时加入预测的考量.若仅基于在数据中找相似点、聚类,然后比对预测,缺乏指向性.再则,要实现预测,未来数据不可获取,只有当下数据和历史数据,而复杂事物的非平稳性、突变性,使得当下子序列与模式的匹配,并不能够说明未来的情形,需要在序列分割、模式提取和在线匹配识别时向前延展.鉴于此,本文以实时演进数据集为对象,通过融合处理,提出了一种基于多时间粒度分层分割、模式提取、主题发现与联合决策的预测方法.
1 序列建模与模式提取
现实世界中所观测录取的数据是客观事物行为的记录和关联因子的描述.构建数据序列集Φ=〈X,U,Y,V〉(X={x},U={u},Y={y},V={v})以刻画随时间而不断向前演进的客观事物R.R的主要行为由多元时间序列x=[xi(t)](i=1,2,···,m1)和m2个非时间序列u=[ui](i=1,2,···,m2)记录,关联的影响因素由多元时间序列y=[yi(t)](i=1,2,···,m3)和m4个非时间序列v=[vi](i=1,2,···,m4)描述.以R在t时刻之前的数据集 Φ (t)的分析实现对R在t+ Δt时刻的行为预测即为要解决的问题.
R受到各种因素的作用,其数据随机性、确定性并存,如金融经济数据、海洋气象数据、战场数据等.可以认为R受到宏观基本规律的约束、当下现实因素的作用、微观层次的扰动以及外部稀疏的偶然性冲击.根据以上推论,R在某一时刻的最终行为可以认为是由以上四方面共同作用决定,则如果由数据序列集Φ=〈X,U,Y,V〉导出表征以上四个方面的数据序列集:A,表征宏观规律;B,当下作用;C,微观层面;E,外部冲击,则借由 Ψ =〈A,B,C,E〉上的内在模式提取,再进行融合预测,将更符合事物逻辑,有望提高预测的准确度.由 Φ 导出 Ψ 可根据多时间粒度的概念[3,17],借由多时间粒度的分层与分割实现.
1.1 基于时间粒度的序列分层与分割
以多元时间序列x=[xi(t)](i=1,2,···,m1)为例.若xi(t)可获得不同时间采样间隔的序列xi(nT1),xi(nT2),···,xi(nTZ),则以待预测的时间粒度为中间层B,将xi(t)分成A、B、C三层:

若记录数据只有一种固定采样率的序列xi(nT0),采用平均的方式,将xi(nT0)整合出三层序列xi(nTA)、xi(nTB)、xi(nTC),记为A、B、C.对Y的操作按照与X对齐的方式同步处理.
从序列xi(nTA)、xi(nTB)、xi(nTC)(简记为xi(n))中提取模式,需要对其进行分割.对序列xi(n)的分割即是将xi(n)按照等时间长度或者变时间长度划分为一族子序列,通过子序列的聚类分析提取内在模式.
设x=[xi(n)]为m维 长度为N的多元时间序列,虚拟一个维度m长度W的窗.令W=ξW0,W0根据应用场景给定,ξ为调整系数.跨度L为窗W向前滑动截取的步长,Tz≤L≤W.窗W自x的起点,滑动到尾点,截取一系列子序列sk,得到子序列集合S=(s1,s2,···,sK).当L=Tz时,则一步一截取,前后子序列有重叠部分,计算量较大;当L=W时,S成为x的一个首尾相衔接的子序列分割,截取效率高,但当出现跨子序列的模式时,可能遗漏.针对具体应用,合理选取L值(或者根据子序列聚类分析结果与L值的对照关系,通过试验比较,确定L值).具体算法如下:

算法1.序列分割算法1)从集合X中输入待分割序列样本 ,指定初值 ,调整系数,.ξ=0.5+0.1i xW0 ξ∈[0.5,1.5]i=0,j=1 2)令 ,.W W=ξW0 3)根据 ,由 ,给定跨度值 .L=Lj Tz≤L≤W L∈[L1,L2,··,LJ]4)令 ,由 起始位置向前截取长度为 的子序列,赋给 .s2 xWs1 5)滑动截取窗向前步进L,截取 ,循环操作直到序列尾点,得到一个截取集 .j=j+1 Si,j=(s1,s2,··,sK)6)令 ,返回第4)步,直到L遍历 .i=i+1[L1,L2,··,LJ]7)令 ,返回第2)步,直到 遍历 .Si,jξ[0.5,1.5]8)合并截取集 为最终集合 ,即为序列 分割后的全体子序列集.9)返回第1)步,输入下一个待分割序列样本.S Sx
S为x的一个分割,由不等长的一系列子序列sk组成,代表了在时间粒度Tz上、在一定时间区间内,序列可能呈现出的各种表现形式.通过S的聚类分析,提取其中蕴含的内在模式,可用于对x未来时刻行为的预测.
以海洋数据集为例,不同海区的水温序列总集可看做X,特定海区的水温序列可以看做x,则既可以进行总体特征分析也可以进行特定区域特征分析.
1.2 模式提取
序列集合S=(s1,s2,···,sK)是x的子序列集,假定存在x的内含模式集Γ =(Γ1,Γ2,···,ΓP),则 ∀sk∈S,∃Γp∈ Γ,使得:
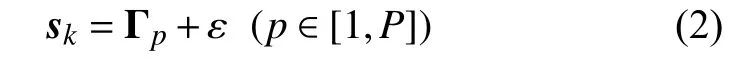
其中,ε是子序列sk与它所分属模式 Γp之间的差异,sk与Γp越相似,ε越小.对于度量相似性的处理方法,有闵可夫斯基距离法、动态时间弯曲距离法(Dynamic Time Warping,DTW)[15,27]、扩展 Frobenius 范数法 (Extended Frobenius Norm,Eros)等.闵式距离简单直观,其特例欧式距离是常用的距离计算方法,但它对波动、噪声非常敏感,且需要序列等长.Eros不满足距离三角不等式,对于本文后续预测处理不适用,因而下面采取DTW进行相似性度量.DTW通过时间序列弯曲部分的自我复制,实现序列相似波形的对齐匹配,不要求序列等长.
设si=(si,1,si,2,···,si,Ni),sj=(sj,1,sj,2,···,sj,Nj)是维度为m,时间点长度分别为Ni、Nj的两个多元子序列,其DTW距离[15]:

其中,d0(si,1,sj,1)为si,1,sj,1的基距离,用欧式距离计算.
对分割得到的子序列集合S根据DTW距离进行相似性度量,利用 K-mean 法进行聚类.设在 A,B,C 层上分别聚合为PA、PB、PC簇,以各簇质心所对应的子序列及各簇内复现频数靠前的若干子序列作为标准模式,得 到,.
对Y的操作按照与X对齐的方式同步处理.于是由R 的原始数据序列集 Φ =〈X,U,Y,V〉,经过前述处理,得到X,Y→A,B,C→ ΓA,ΓB,ΓC.非时间序列集U、V根据时间戳对应归类为孤立事件集E=(eU,eV).于是完成了 Φ → Ψ → Ω0,Ψ =〈A,B,C,E〉为 Φ经多时间粒度分层整合后的数据序列集,Ω0=〈ΓA,ΓB,ΓC,E〉为 Ψ 经过时间分割、相似度量、聚类分析后的内在模式表征集.
2 主题发现与预测策略
根据 R 记录数据所提取的内在模式表征集Ω0=〈ΓA,ΓB,ΓC,E〉,对它未来行为进行预测,可以有多种策略,应进行融合处理.
2.1 主题发现
对于R而言,可知的是t0及t≤t0前的数据序列集.在t0时刻附近的表现受到宏观、中观、微观层及外部冲击的影响,呈现的序列对很多事物而言不一定具有连续性和稳定性,但是其呈现的模式具有近似意义上的可复现性.当特定模式出现时,R的后续行为表现出相对稳定性.即总体上不一定可以准确预测,但是当序列开始呈现这种特定的模式时,利用这种稳定的表现,向未来进行延展,即可以用于此时刻R未来行为的预测.这些特定模式定义为主题模式.Ω0=〈ΓA,ΓB,ΓC,E〉囊括了R的行为特征.主题模式集M=(mm)(m=1,2,···,M)可以由提取的标准模式集合 ΓA,ΓB,ΓC,E,中的模式组合得到,如公式(4)所示.

其中,pA∈[1,PA],pB∈[1,PB],pC∈[1,PC],pU∈[1,PU],pV∈[1,PV].组合方式可以基于专家经验或者对全集合进行遍历.具体如下:
第一步:对于mm,基于相似性度量,从一定时长L的历史数据序列中进行匹配,统计其出现频数f(mm).
第二步:根据 R 预测要求,以二元决策(H0,H1)为例(天气预报的下雨、不下雨,证券价格的涨跌等;对于非二元决策,可以进行预测区间离散化处理,形成一个多元决策问题,处理方式一致),统计当出现mm时R后续行为为H0、H1的出现频数.
第三步:计算决策 H0、 H1的正确率 η( H0/mm)、η(H1/mm),如公式 (5)所示:
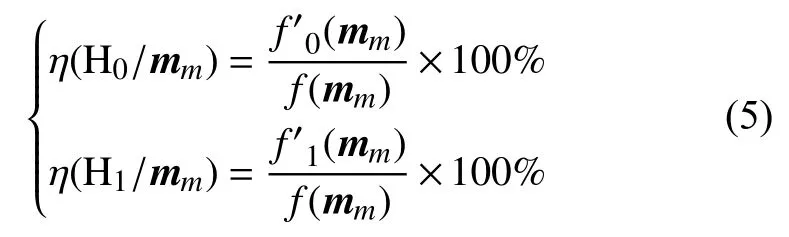
设定正确率门限 δ(δ ∈(0.5,1.0]),对于η(H0/mm)≥ δ的mm归于 H0主题模式MH0,η( H1/mm)≥ δ 的mm归于H1主题模式MH1.再根据出现频数f(mm)对MH0、MH1中mm由高到低排序,设定频数门限 ω ,剔除f(mm)<ω的低频度模式.至此,得到可资利用的主题模式MH0、MH1.
2.2 预测策略
对于实时演进的系列集R而言,现时刻为t0,则可获得的即为t≤t0之前的数据和相关联的孤立事件u,v.需要以其为基础对t0+Δt时的行为进行预测.在t0时刻,以1.1节的时间粒度处理方法,实时在线截取A层的待匹配子序列xA(nTA),记为xA(n),同样处理得到xB(n),xC(n).xA(n),xB(n),xC(n)的时间点数分别为NA,NB,NC,其值取对应层标准序列长度的平均值(为了描述简单,假设A,B,C层都只有一种时间粒度,实际处理中可以在每一层尝试多种时间粒度).在t0时刻附近,R 的行为由Rt0=<xA(n),xB(n),xC(n),u,v>表示.
图1 余集获取示意图
(1)主题发现预测
分析2.1节利用历史数据挖掘主题模式的过程,及这种在线匹配、主题发现预测的策略,可知其为低频度模式.鉴于此,制定主题发现预测方法的补充策略,即联合决策预测.
(2)联合决策预测
联合决策预测策略为对xA(n)、xB(n)、xC(n)在余集中分别匹配,只要在各层匹配上标准模式,抽取标准模式进行联合推断.方法如下:
第一步:根据DTW距离度量,根据KNN法对xA(n)在余集中 进行分类处理.设定参数 ρ ∈[70%,90%],截取xA的后 ρ部分与si的前 ρ部分,分别记为xA,ρ、si,ρ,计算DTW距离d(xA,ρ,si,ρ).若经过分类处理xA属于簇,则将簇标准模式赋给xA,并认为的后1-ρ序列即为xA向前延展的预测值.记此预测为DA.对xB、xC进行同样处理,得到DB、DC.
第二步:以二元决策 (H0,H1)为例,制定规则 :只有当DA、DB、DC同时指示x(t0+Δt)的行为为H0时,推断为 H0,同理处理 H1(也可以根据宏观、中观、微观的先验知识,对DA、DB、DC进行加权处理,本文采取“同时指示”这种强准则).则由DA、DB、DC进行联合预测的正确概率如公式(6)所示:

其中,Pf1=Pf(H0)Pf(A)Pf(B)Pf(C),Pf2=(1-Pf(H0))(1-Pf(A))(1-Pf(B))(1-Pf(C)),Pf( H0)为 H0出现的先验概率,Pf(A)、Pf(B)、Pf(C)为根据DA、DB、DC决策的正确概率(在此假设DA、DB、DC决策相互独立,若完全相关则退化为单层模式),与模式复现的稳定性相关.
实际的预测要求是在本层(B层)时间粒度上对x(t0+Δt)的行为作出判断.由公式(6)推导可得到:
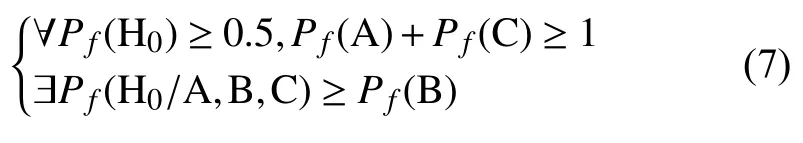
考察公式(7),假设序列总体上呈现随机漫步,毫无偏向,则Pf(H0)=0.5,此时可以认为模式识别无意义,Pf(A)=0.5、Pf(C)=0.5;若序列具有偏向,则或者Pf(H0)>0.5或者Pf(H1)>0.5,考虑到DA、DC是根据提取的模式进行匹配识别作出的二元判断,其准确度应Pf(A)≥0.5、Pf(C)≥0.5.综上所述,Pf(H0/A,B,C)≥Pf(B)的条件可以认为满足,即在退化条件下,“同时指示”这种强准则下的联合决策正确率也至少等于基于本层的决策Pf(B),若序列展现偏向性,则联合决策的正确率将会提升.
综合两种预测策略,设计下面的整体预测方案:

算法2.整体预测方案1)经历史数据处理得到标准模式库 ,经主题挖掘得到主题模式集合 、 .S′AΩ0=〈ΓA,ΓB,ΓC,E〉MH0=(mH0)MH1=(mH1)2)获取聚类分析后的余集 、 、 .t0 S′BS′C3)以当前时刻 为基准向后截取并整合出待匹配子序列 ,,.xA xAxBxC4)采用DTW距离度量,根据KNN法对 ,,在余集 、 、中进行分类、匹配.若匹配不上,不做预测,转入3),等待序列向xBxCS′AS′B S′Ct0

注:若存在孤立事件的冲击,则通过历史对照的方法,加入模式匹配中.
3 系统实现与实例分析
基于上述模型构建与算法设计,在计算机系统上予以实现并选取实例进行效果分析.
3.1 系统实现
前述模型与算法中,变跨度滑窗子序列截取、DTW距离计算、相似性搜素、K-mean法聚类分析和KNN分类等,计算量都较大,为了更好的从历史数据序列中提取模式,需尽可能的采用较长的时间序列,从而造成计算量急剧上升.在线匹配预测,其计算量要小于模式提取的过程.鉴于此,采用分布式并行处理架构,如图2所示.
整个系统由A、B两个子系统组成.A系统采取外部云计算托管;B系统在线监控实时处理,由N个并行计算节点组成.软件设计采用Python语言粘合MPI并行编程环境的方式.以Python编制数据端口,将数据导入分发,一份为模式提取全时长数据库,一份为在线数据片集.将模式提取并行计算程序布置在外部云系统上,在全时长数据库上进行提取操作,维持一个标准模式库并进行主题模式的挖掘,所得到的模式库发往B系统.在本地并行计算机系统上布置在线匹配预测的并行计算程序,将模式库与在线数据片集结合,根据数据序列的驱动,实时更新处理.累积一定时间,在A系统上重新启动模式提取处理,监测R是否会演化,出现新的标准模式或者主题模式则更新模式库,并发往B系统.
3.2 实例分析
本文目的是构建一种通用的处理架构,主要面向气象海洋数据、战场数据以及经济金融数据.出于数据获取便利性的考虑,下面以石油期货相关数据为例进行算法验证.
试验数据:NYMEX原油期货主力合约数据(2002.1.1至2016.1.1,取其年月周日分的价格序列的开盘价、收盘价、最高价、最低价、相关的宏观经济数据以及关联国际事件),2002.1.1–2012.1.1为模式提取数据区间,2012.1.2–2016.1.1为模拟预测处理数据区间.
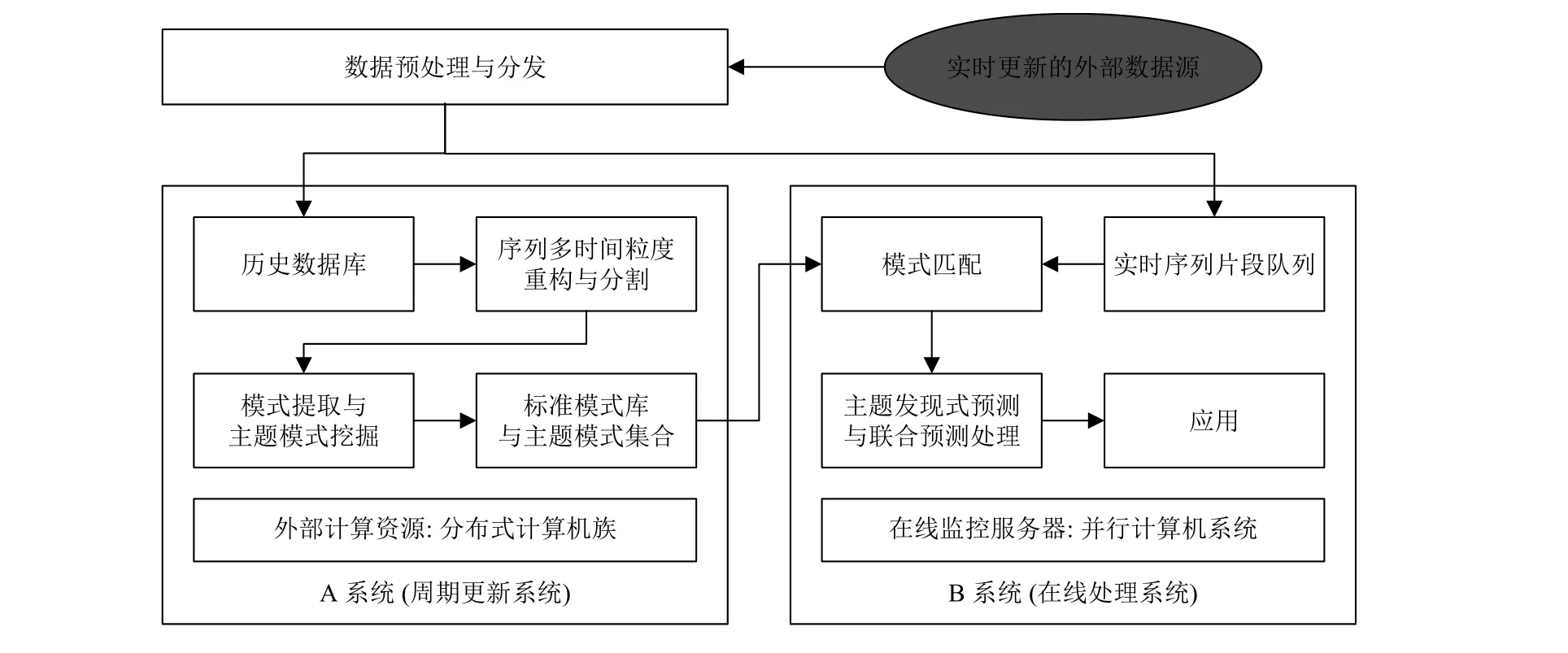
图2 系统框图
经处理,A层时间粒度取为6T(T代表一日)、B层为T、C层为2个小时,以B层日预测为目标,预测日线上T+n日价格行为(本文取T+2日的预测).匹配百分比 ρ =0.8.K-mean 聚类时,设置A、B、C层初始分类数目均为6.根据程序数据结果,A层额外抽取频繁子序列2个,B层4个,C层1个.最终提取结果为:A层标准模式数PA=8,B层标准模式数PB=10、C层标准模式数PC=7.
根据图3、图4的统计,取出现频数较高、对H0预测正确概率较高的组合模式作为主题模式MH0=(mH0);对H1预测正确概率较高的组合模式作为主题模式MH1=(mH1).
根据上述结果,定义:F1,主题发现式预测;F2,联合决策式预测;F3,传统的基于日线的ARIMA预测;F4,日线子序列模式匹配预测;F5,分层小波分解预测,对5种方法的预测性能进行比较.其中,F5为将日线通过小波变换,分解为表示宏观的和表示细节的部分,在每层上分别用ARIMA递推,再相加的方式进行.模拟预测数据区间为2012.1.2-2016.1.1共计4年.
F1:抽取MH0中 H0决策正确率最高,且在2002.1.1–2012.1.1中出现频数排序在前30%的主题模式进行匹配预测;同理抽取MH1中主题模式.在F1预测做出时,同步记录 F3、F4、F5的预测结果.其决策的统计结果如表1所示.
由表1可发现,F1相比其他方法有较高的正确率,说明经过主题模式挖掘,某些特定的复合模式出现时,其后续的行为十分稳定,用之预测有较高的准确率.但是其中预测最准确且复现频率排序前30%的主题模式出现的频率也只有年平均18.3次,十分稀疏.
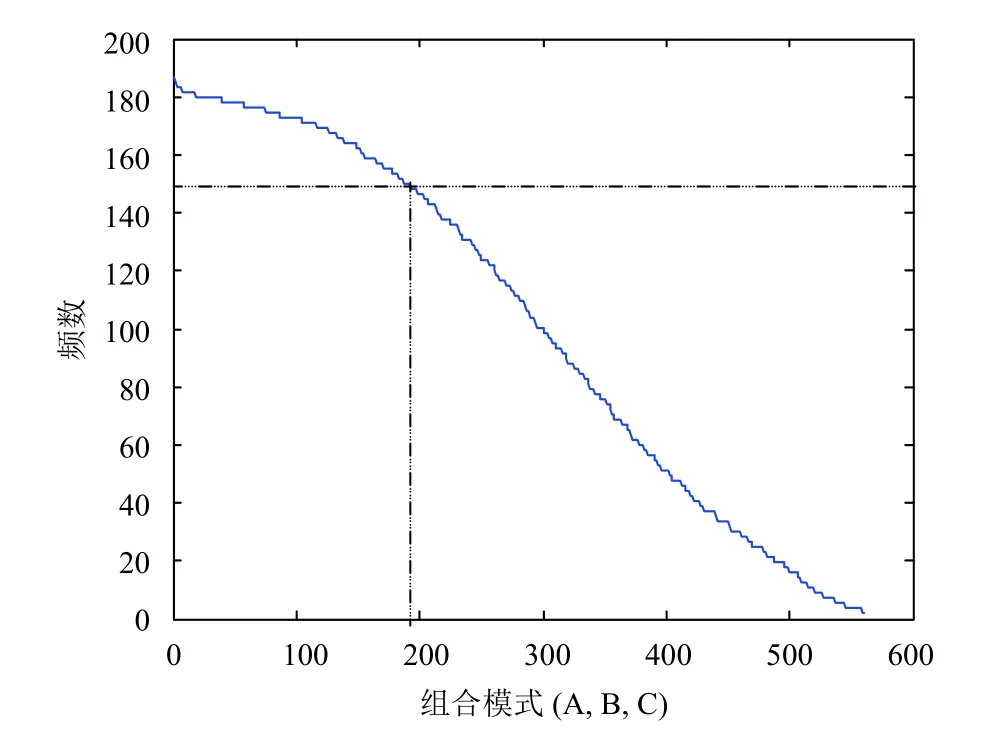
图3 组合模式在历史数据集中的出现频数
F2:通过在线分层匹配处理,当均匹配上时,启动决策.若“同时指示”H0或 H1,则取此指示为决策,统计正误;否则放弃.同步记录 F3、F4、F5 的预测结果.其决策的统计结果如表2所示.
根据表2结果,F2也比F3、F4、F5准确率要高,但是其复现频率也不高,年平均出现49.5次,且联合决策的放弃数也较高.将F1、F2结合,按照前述算法2的流程进行在线监测,可以提高可预测的频数.
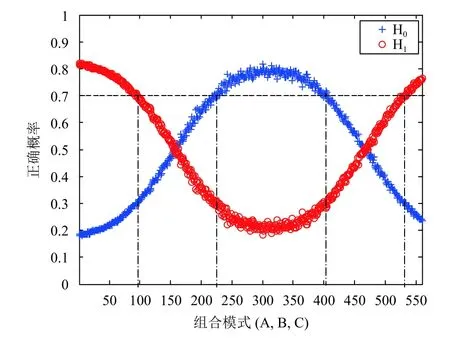
图4 组合模式在历史数据集中预测的正确率统计
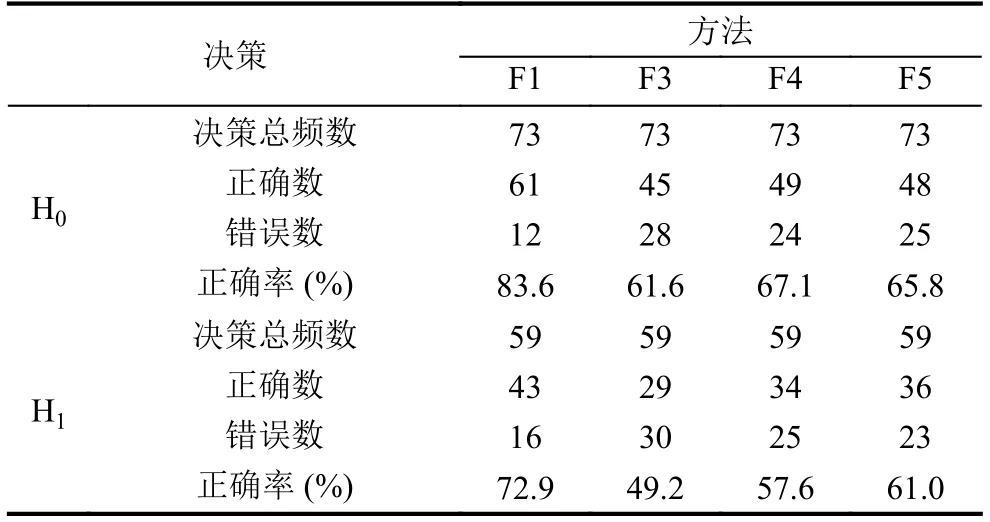
表1 F1 方法与其他方法预测性能比较

表2 F2 方法与其他方法预测性能比较
综合言之,准确性的提高得益于特定模式的挖掘和联合判断,但这种处理同时注定了在线处理时,只能等待序列在实时演进过程中呈现出此模式近似态时才可进行决策.考察实际应用场景,这种新的预测方法具有意义(如在投资决策中,当机会出现时再投入显然比贸然介入更有利;在海洋水文参数与作战场景呈现某种特定态势时,作出未来态势推断并付诸行动比较适宜),而常规的时时刻刻做未来预测的准确性值得警惕.
4 结束语
复杂事物行为的数据序列集,变化复杂、序列前后时刻存在逻辑上的不确定性、且概率分布未知、具有混沌突变性.在实时演进过程中,其平稳运行与突然变化相互杂交,无法实时推断下一时刻会发生什么.但是某些模式或会反复出现.当在监测过程中,这些特殊形态显现大部的时候,其后续有较大概率按照此模式运行.文中根据事物影响因子的宏微观特性,将序列集通过多时间粒度和跨度的分层分割,提取代表各层特性的标准模式集,再挖掘具有稳定延展表现的主体模式,构建出主题模式在线匹配和联合决策的预测方法.此方法与传统的几种序列预测方法相比,具有较高的预测准确性,但是在线复现率不高.如果对算法中的部分门限和参数进行放宽处理,则可以提高频数,但是预测准确性可能降低.准确率、复现率与门限和参数的对应关系、折中处理等,需要结合具体应用场景作进一步研究.
猜你喜欢
黄河之声(2022年10期)2022-09-27
佳木斯大学学报(自然科学版)(2022年3期)2022-06-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
纺织科学研究(2021年9期)2021-10-14
粉末冶金技术(2021年3期)2021-07-28
小型微型计算机系统(2020年10期)2020-10-21
决策(2018年8期)2018-12-10
决策(2018年11期)2018-11-28
