
基于三维残差稠密网络的人体行为识别算法
2019-01-06 07:27郭明祥宋全军徐湛楠董俊谢成军
计算机应用 2019年12期
关键词:深度学习
郭明祥 宋全军 徐湛楠 董俊 谢成军


摘 要:針对现有的人体行为识别算法不能充分利用网络多层次时空信息的问题,提出了一种基于三维残差稠密网络的人体行为识别算法。首先,所提算法使用三维残差稠密块作为网络的基础模块,模块通过稠密连接的卷积层提取人体行为的层级特征;其次,经过局部特征聚合自适应方法来学习人体行为的局部稠密特征;然后,应用残差连接模块来促进特征信息流动以及减轻训练的难度;最后,通过级联多个三维残差稠密块实现网络多层局部特征提取,并使用全局特征聚合自适应方法学习所有网络层的特征用以实现人体行为识别。设计的网络算法在结构上增强了对网络多层次时空特征的提取,充分利用局部和全局特征聚合学习到更具辨识力的特征,增强了模型的表达能力。在基准数据集KTH和UCF-101上的大量实验结果表明,所提算法的识别率(top-1精度)分别达到了93.52%和57.35%,与三维卷积神经网络(C3D)算法相比分别提升了3.93和13.91个百分点。所提算法框架有较好的鲁棒性和迁移学习能力,能够有效地处理多种视频行为识别任务。
关键词:人体行为识别;视频分类;三维残差稠密网络;深度学习;特征聚合
中图分类号: TP391.41(图形图像识别)文献标志码:A
Human behavior recognition algorithm based on three-dimensional residual dense network
GUO Mingxiang1,2, SONG Quanjun 1*, XU Zhannan1, DONG Jun 1, XIE Chengjun1
(1. Institute of Intelligent Machines, Chinese Academy of Sciences, Hefei Anhui 230031, China;
2. University of Science and Technology of China, Hefei Anhui 230026, China)
Abstract: Concerning the problem that the existing algorithm for human behavior recognition cannot fully utilize the multi-level spatio-temporal information of network, a human behavior recognition algorithm based on three-dimensional residual dense network was proposed. Firstly, the proposed network adopted the three-dimensional residual dense blocks as the building blocks, these blocks extracted the hierarchical features of human behavior through the densely-connected convolutional layer. Secondly, the local dense features of human behavior were learned by the local feature aggregation adaptive method. Thirdly, residual connection module was adopted to facilitate the flow of feature information and mitigate the difficulty of training. Finally, after realizing the multi-level local feature extraction by concatenating multiple three-dimensional residual dense blocks, the aggregation adaptive method for global feature was proposed to learn the features of all network layers for realizing human behavior recognition. In conclusion, the proposed algorithm has improved the extraction of network multi-level spatio-temporal features and the features with high discrimination are learned by local and global feature aggregation, which enhances the expression ability of model. The experimental results on benchmark datasets KTH and UCF-101 show that, the recognition rate (top-1 recognition accuracy) of the proposed algorithm can achieve 93.52% and 57.35% respectively, which outperforms that of Three-Dimensional Convolutional neural network (C3D) algorithm by 3.93 percentage points and 13.91 percentage points respectively. The proposed algorithm framework has excellent robustness and migration learning ability, and can effectively handle multiple video behavior recognition tasks.
Key words: human behavior recognition; video classification; three-dimensional residual dense network; deep learning; feature aggregation
0 引言
视频理解是计算机视觉领域极具挑战性的一项任务,视频中的人体行为识别是其中重要的分支,随着研究的深入,目前已经取得了很大的进展。根据视频序列提取特征的方式不同,文献[1-3]提出行为识别方法可以分为两类:基于手工构造特征的方法和基于自动学习特征的方法。早期的人体行为识别算法中,通常采用手工构造的特征描述视频中的局部时空变化,如尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)[4]、方向梯度直方图(Histogram of Oriented Gradients, HOG)/HOF(Histogram of Oriented Optical Flow)[5]、运动边界直方图(Motion Boundary Histogram, MBH)[6]、轮廓[7-8]、动作属性[9]和密集轨迹特征[10-11]等。在众多的手工构造的特征描述符中,由法国国家信息与自动化研究所(Institut National de Recherche en Informatique et en Automatique, INRIA)[10-11]提出的基于改进的密集轨迹特征(Improved Dense Trajectories, IDT),它通过Fisher Vector特征编码方式在动作识别中表现出优越的性能。手工构造的特征通常仿照人类视觉特点及其他先验知识来设计特征本身,它主要针对某一特定任务设计,往往无法适应所有场景,且计算复杂。随着深度学习算法的兴起,基于自动学习特征的方式逐步取代了传统精心设计特征的过程,同时模型自主学习适用于当前任务的特征,网络能够端到端地训练,都使得模型的计算更具效率。在众多的深度学习网络结构中,卷积神经网络(Convolutional Neural Network, CNN)的运用最为广泛。
CNN在静态图像领域获得了很大的成功[12-16]。它在研究视频处理方面也具有很大的优势。为了在深度卷积模型中同时对空间和时间信息进行编码,Ji等[17]对2D卷积网络进行了简单而有效的扩展,提出了三维卷积神经网络模型,用于学习动态连续的视频序列,深入学习时空特征。Tran等[18]经过系统研究找到了三维卷积神经网络的最佳卷积核大小,并提出了适用于大规模数据集的三维卷积神经网络(Three-Dimensional Convolutional neural network, C3D),并利用C3D提取视频时空特征,提取到的特征具有很强的通用性,且计算高效。此外,Tran等[19]在深度残差网络框架中进行了三维卷积神经网络改进,提出了Res3D网络,改进网络在运算速度、识别精度等方面都优于C3D。Hara等[20]提出Kinetics数据集具有足够的数据训练深的三维卷积网络,并且经过Kinetics数据集预训练的简单三维体系结构优于复杂的二维体系结构。Tran等[21]又将三维卷积网络中的三维卷积运算都分解成两个独立的连续运算——二维空间卷积和一维时间卷积,提出了R(2+1)D网络,该网络与C3D相比有效地增加了模型的容量,同时有利于网络的优化。三维卷积网络由于其简单有效的策略受到了广泛的关注和应用,但网络也存在一些缺陷,比如:由于其巨大的网络参数而导致网络收敛非常困难,Chen等[22]提出了一种轻量级的多纤维网络架构,显著地降低3D网络的计算复杂度,同时提高了模型的識别性能。Yang等[23]提出了非对称三维卷积神经网络模型,除降低参数量和计算成本外,引入了多源增强输入和多尺度 3D卷积分支来处理视频中不同尺度的卷积特征,通过融合RGB和光流帧的有效信息显著提高模型的表达能力。此外,三维卷积网络在时空特征建模方面与最先进的基线方法有一定差距。Diba等[24]在ResNext等基础架构中引入了时空通道相关块(Spatio-Temporal Channel correlation block, STC) 作为其新的残差模块,能够有效地捕获整个网络层中的时空信道相关性信息。Hussein等[25]侧重关注行为识别中的时间线索,为了对长时程范围内的复杂动作建模,提出了Timeception卷积层改进的3D卷积网络,它使用了多尺度时间卷积,通过关注短时程细节来学习长时程依赖性。
为了补充对视频时间维度信息的建模,文献[26-27]采用两个CNN分别对原始单帧RGB图像和视频帧的光流图像进行特征学习,最后对输出进行信息融合,设计了学习时空特征的双流网络架构。Wang等[28]结合了稀疏时间采样策略和视频片段融合,引入时间片段网络(Temporal Segment Network, TSN)来提高对视频的长程时间结构建模能力。还有一系列研究集中在利用时间和空间网络之间的相关性来提高识别性能,例如:Feichtenhofer等[29]提出使用残差连接来进行双流网络之间的时空交互;Feichtenhofer等[30]又在模型中引入fusion 信息,具体分析了网络不同融合特征对识别结果的影响;Carreira等[31]将双流网络的卷积和池化内核都扩展为三维形式,提出了一种双流I3D(Inflated 3D ConvNet)模型,通过大型数据集Kinetics上进行预训练,它取得了多个数据集上的最先进结果(在UCF-101的识别率为97.9%,在HMDB-51的识别率为80.7%)。
双流网络及其衍生的模型形成了强大的基线,但由于其稠密采样策略和光流场的计算复杂且耗时,限制了其在现实世界中的应用。Ma 等[32]提出的循环神经网络——长短期记忆(Long Short-Term Memory, LSTM)网络对视频长时序结构建模是另一种主流的方法。Donahue等[33]提出了卷积层和长时序递归结合的长时序递归神经网络,可用来学习可变长度输入,并模拟复杂的动态时序。Ng等[34]提出通过在每帧卷积特征上连接多个堆叠LSTM来计算全局视频级特征。Wu等[35]研究表明通过LSTM进行多流长时序建模可以提高行为识别的性能。Carreira等[31]提出LSTM网络能够对视频长时段以及高层运动变化进行建模,但却不能捕捉重要的精细底层运动,并且网络训练也较为耗时。
1.2 三维残差稠密网络
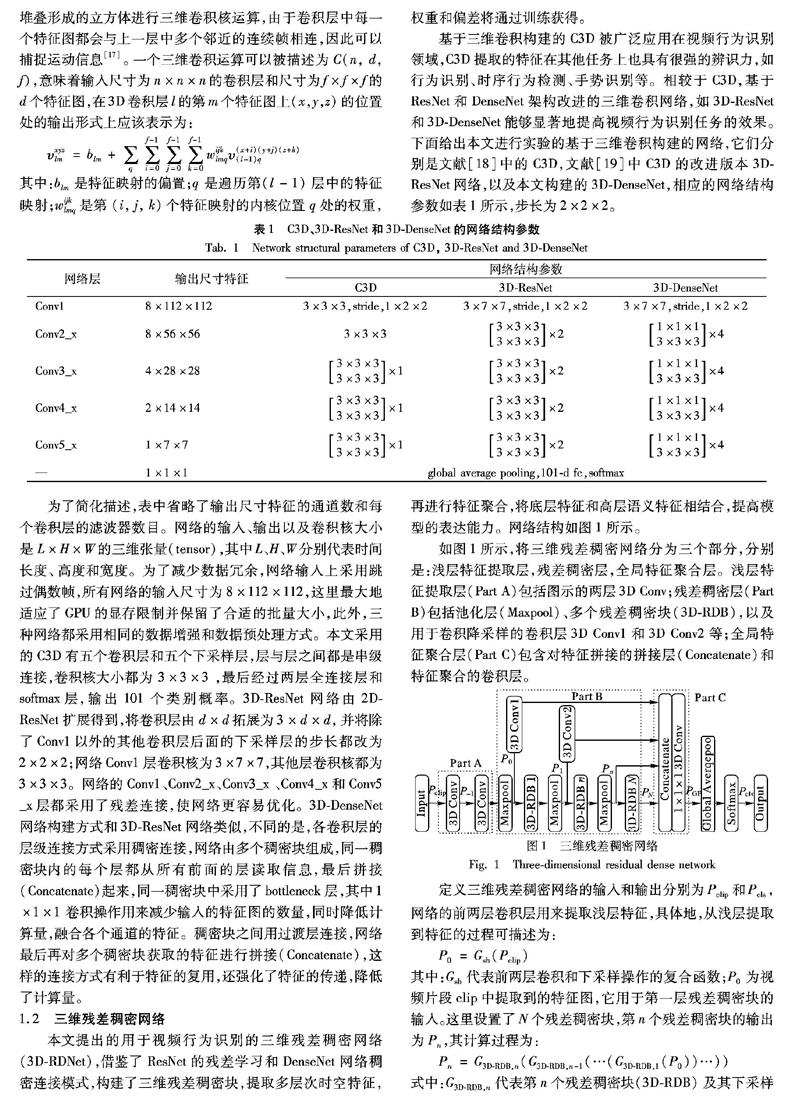
本文提出的用于视频行为识别的三维残差稠密网络(3D-RDNet),借鉴了ResNet的残差学习和DenseNet网络稠密连接模式,构建了三维残差稠密块,提取多层次时空特征,再进行特征聚合,将底层特征和高层语义特征相结合,提高模型的表达能力。网络结构如图1所示。
如图1所示,将三维残差稠密网络分为三个部分,分别是:浅层特征提取层,残差稠密层,全局特征聚合层。浅层特征提取层(Part A)包括图示的两层3D Conv;残差稠密层(Part B)包括池化层(Maxpool)、多个残差稠密块(3D-RDB),以及用于卷积降采样的卷积层3D Conv1和3D Conv2等;全局特征聚合层(Part C)包含对特征拼接的拼接层(Concatenate)和特征聚合的卷积层。
定义三维残差稠密网络的输入和输出分别为Pclip和Pcls,网络的前两层卷积层用来提取浅层特征,具体地,从浅层提取到特征的过程可描述为:
P0=Gsh(Pclip)
其中:Gsh代表前两层卷积和下采样操作的复合函数;P0为视频片段clip中提取到的特征图,它用于第一层残差稠密块的输入。这里设置了N个残差稠密块,第n个残差稠密块的输出为Pn,其计算過程为:
Pn=G3D-RDB,n(G3D-RDB,n-1(…(G3D-RDB,1(P0))…))
式中:G3D-RDB,n代表第n个残差稠密块(3D-RDB)及其下采样(Maxpool)的计算操作,而当n=N时,G3D-RDB,N只包含残差稠密块的计算操作。G3D-RDB,n是复合运算函数,包括了多层卷积和整流线性单位。由于Pn是由第n个残差稠密块内的多个卷积层运算产生的,可以将Pn视为局部稠密特征。
3D-RDNet通过多个3D-RDB提取到多层次局部稠密特征之后,进一步进行全局特征聚合(Global Feature Aggregation, GFA),GFA充分利用了前面所有层的特征。具体地,将输入的不同层次的特征Pn都卷积采样为1×7×7特征图Xn,并进行l2范数归一化,然后用拼接层(Concatenate)对来自不同层次的局部稠密特征Xn进行拼接,再用1×1×1的卷积进行特征聚合和通道调整,得到全局特征聚合的特征图。其中对局部稠密特征拼接的过程可描述为:
PGFA=GGFA([X0,X1,…,XN])
其中:PGFA是经过全局特征聚合输出的特征图;GGFA是1×1×1卷积的复合函数,它用于自适应地融合来自不同层的特征;[X0,X1,…,XN]是指N个经过三维残差稠密块和卷积采样后的特征图的拼接。
综合上述操作,网络从输入clip中提取到浅层特征,然后经过多个残差稠密块得到丰富的局部特征,再经过全局特征聚合得到全局特征,最后通过softmax分类器得到各个种类的分数。整个网络3D-RDNet计算过程可表示为:
Pcls=GRDNet(Pclip)
其中:GRDNet为3D-RDNet整个网络的运算操作;Pcls为网络的输出。
1.3 三维残差稠密块
三维残差稠密网络由多个三维残差稠密块组成,图2为三维残余稠密块(3D-RDB)的网络结构图。3D-RDB主要包含稠密连接层、局部特征聚合(Local Feature Aggregation, LFA)和局部残差学习(Local Residual Learning, LRL),这使得网络能够充分学习多层卷积特征。
1.3.1 稠密连接模式
3D-RDB模块由多个卷积层、整流线性单元(Rectified Linear Unit, ReLU)和批规范化层(Batch Normalization, Batch Norm)组成的特征提取单元重复多次的串联形成,这有利于训练更深的网络。前面3D-RDB学习到的特征直接传递给当前3D-RDB内的每一层,同时,模块内部每层之间都有直接的连接,这种稠密连接方式使得特征和梯度的传递更加有效,促进了特征复用,保留了前向传播的特性,还提取了局部稠密特征。这里定义Pn-1和Pn分别为第n和n+1个3D-RDB的输入,那么第n个3D-RDB的第a个Conv层的输出可以表示为:
Pn,a=σ(Wn,a[Pn-1,Pn,1,Pn,2,…,Pn,a-1])
其中:σ表示内核为ReLU的激活函数;Wn,a中是第a个卷积层的权重,这里为简便表示省略了偏置项。假设Pn,a由多个特征图组成, [Pn-1,Pn,1,Pn,2,…,Pn,a-1]是指由第(n-1)个3D-RDB,以及第n个3D-RDB内的卷积层1,2,…,(a-1)输出的特征图的拼接(Concatenation)。
1.3.2 局部特征聚合
3D-RDB通过稠密连接模式学习到多层次时空特征后,接下来对局部稠密特征进行融合,具体地,通过提取一系列来自先前3D-RDB和当前的3D-RDB中的卷积层特征,然后对其进行拼接,再引入了1×1×1卷积层用于自适应地融合具有不同层级的一系列特征,将此操作命名为局部特征聚合(Local Feature Aggregation, LFA)。其计算过程可描述如下:
Pd,LF=GnLFA([Pn-1,Pn,1,Pn,2,…,Pn,a,…,Pn,A])
其中:GnLFA表示第n个3D-RDB中1×1×1 卷积层的复合运算,它可以减少特征图数量,减少计算量,同时融合各个通道。随着稠密网络的增长率变大,LFA将有助于非常稠密的网络训练。
1.3.3 局部残差学习
在足够深的网络结构中,为了确保网络中各层级之间的最大信息流,3D-RDB中采用了残差网络的跳跃连接方式,它将具有相同特征映射大小的特征图连接起来,这样每一层的输出都直接连接到了后续层的输入。这种从前面层到后续层的跳跃连接缓解了网络梯度消失问题,增强了特征传播,促进了特征重用,保留了前向传播的特性。第n个3D-RDB的输出可表示为:
从表4中可以看出:在KTH数据集上的准确率,三维卷积网络相较其他算法有较大的优势;同时三维卷积的改进网络3D-ResNet和3D-DenseNet都较C3D取得了更好的结果,准确率分别比C3D提高了1.61个百分点和2.08个百分点;而且本文提出的三维残差稠密网络相较C3D高出了3.93个百分点。
将在KTH训练集上训练好的模型对整个数据集进行测试,可得到如图6所示的混淆矩阵,其中,图片右侧的颜色刻度代表的含义为颜色越深(越接近1.0)行为分类精度越高。从混淆矩阵可以看出,3D-RDNet网络在KTH数据集上的整体识别率很高,但模型对奔跑、慢跑以及散步等行为的辨别不是很好,一方面是因为这些动作相似度较高,另一方面还有视频本身的分辨率较低,容易造成误判。总体来说,3D-RDNet网络对KTH数据集有较好的识别效果,在KTH训练集上训练好的模型对整个数据集进行测试,得到了97.2%的识别率。
2.4 UCF-101和真实场景数据集实验
本文还对UCF-101数据集和建立的真实场景数据集进行了测试,两个数据集在实验过程中的设置基本相同。实验从头开始训练,网络的输入为从每段视频中提取的连续16帧视频片段clip,将视频帧宽和高resize为171×128,经过数据预处理,将输入尺寸裁剪为8×112×112。在网络优化方面,采用带动量的随机梯度下降法,网络初始学习率设置为0.01,动量参数为0.9,学习率衰减率为10-4,目标函数为交叉熵损失函数,网络训练周期为25,批量处理大小设置为16。
4种网络C3D、3D-ResNet、3D-DenseNet和3D-RDNet等人体行为识别算法在UCF-101和真实场景数据集的实验结果如表5所示。其中,准确率都是基于视频连续16帧片段clip计算的,即Clip top-1。
从表5中可以看出:1)在UCF-101数据集上,本文模型(3D-RDNet)网络相较3D-ResNet和3D-DenseNet的人体行为识别率分别提高了11.87个百分点和10.52个百分点,同时较C3D提高了13.91个百分点,表明在复杂数据集上结合了稠密连接和残差学习思想的3D-RDNet网络依然比单一网络结构更优异,并且在识别准确率上远優于它们,验证了本文设计网络的有效性和优越性能。2)在真实场景数据集上,本文模型的识别效果也优于其他网络,取得了94.66%的识别率。综上表明3D-RDNet网络依然能够胜任真实场景下的任务,网络具有较好的鲁棒性和迁移学习能力。
3 结语
针对传统的3D卷积神经网络算法缺乏对网络多层次卷积特征充分利用的问题,本文提出了一种基于视频的人体行为识别的三维残差稠密网络架构,并在公共数据集和真实场景数据集上验证了算法的有效性。本文的主要工作在于:1)改进了三维卷积神经网络,提出了三维残差稠密网络,在保证网络准确率的同时降低了模型的复杂度;2)提出了一种网络构建模块——三维残差稠密块,通过稠密连接模式、局部特征聚合和局部残差学习强化了网络充分学习多层卷积特征的能力,降低了原有视频信息在网络训练过程中丢失的风险;3)所提算法使用多个三维残差稠密块提取多层次时空特征,再经过全局特征聚合,将底层特征和高层语义特征相结合,提高了模型的表达能力。此外,文中采用的预处理和数据增强方法也可显著地防止网络训练过程中的过拟合现象,通过在公共数据集和真实场景数据集进行实验,验证了所提算法优于多数传统算法以及三维卷积同类型的方法,显著地提高了视频行为识别任务的准确率。
本文的研究也存在一定的不足,所提算法在模型的输入方面依然采用传统的视频短时程时序信息,即每次输入是一个连续16帧的视频clip,这样带来的问题是网络只能处理短期(short-term)运动,同时训练有较大的计算开销,在未来的研究工作中可以引入文献[28]所提TSN中采用的稀疏时间采样方法来学习视频长时程的时序结构,增加网络对长期(long-range)运动的时间结构理解。由于计算资源有限,本文针对UCF-101和KTH等数据集的实验都是从头开始训练,为了得到更好的识别效果,可以让模型在Kinetics和Sports-1M等行为识别大型数据集上进行预训练,然后进行迁移学习到其他的数据集上。同时,网络的基础架构也很重要,为了得到更强识别效果的模型,一种思路是可以借鉴文献[31]所提的I3D网络思想,即在经典的双流网络中引入3D-ResNet网络架构,将有助于有效地提高模型的识别率。另外,还可以探索三维卷积神经网络与长短时记忆网络的融合架构,从而将显著的时间信息加入到网络中,进一步提升模型的表达能力。最后,将传统的特征描述符与深度学习方法相结合也是一种有效提高模型识别率的途径。
参考文献 (References)
[1]ZHU F, SHA L, XIE J, et al. From handcrafted to learned representations for human action recognition: a survey [J]. Image and Vision Computing, 2016, 55: 42-52.
[2]GUANGLE Y, TAO L, JIANDAN Z. A review of convolutional-neural-network-based action recognition [J]. Pattern Recognition Letters, 2019, 118: 14-22.
[3]李瑞峰,王亮亮,王珂.人体动作行为识别研究综述[J].模式识别与人工智能,2014,27(1):35-48.(LI R F, WANG L L, WANG K. A survey of human body action recognition [J]. Pattern Recognition and Artificial Intelligence, 2014, 27(1): 35-48.
[17]JI S, XU W, YANG M, et al. 3D convolutional neural networks for human action recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 221-231.
[18]TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 4489-4497.
[19]TRAN D, RAY J, SHOU Z, et al. ConvNet architecture search for spatiotemporal feature learning [J]. Computer Vision and Pattern Recognition, 2017, 17 (8): 65-77.https://arxiv.org/pdf/1708.05038.pdf.
[20]HARA K, KATAOKA H, SATOH Y. Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and ImageNet? [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6546-6555.
[21]TRAN D, WANG H, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6450-6459.
[22]CHEN Y, KALANTIDIS Y, LI J, et al. Multi-fiber networks for video recognition [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11205. Berlin: Springer, 2018: 364-380.
[23]YANG H, YUAN C, LI B, et al. Asymmetric 3D convolutional neural networks for action recognition [J]. Pattern Recognition, 2019, 85: 1-12.
[24]DIBA A, FAYYAZ M, SHARMA V, et al. Spatio-temporal channel correlation networks for action classification [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11208. Cham: Springer: 284-299.
[25]HUSSEIN N, GAVVES E, SMEULDERS A W M, et al. Timeception for complex action recognition [C]// Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 254-263.https://arxiv.org/pdf/1812.01289v1.pdf.
[26]SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos [C]// Proceedings of the 2014 International Conference on Neural Information Processing Systems. New York: Curran Associates Inc., 2014: 568-576.
[27]WANG L, XIONG Y, WANG Z, et al. Towards good practices for very deep two-stream convents [EB/OL]. [2019-03-31]. https://arxiv.org/pdf/1507.02159.pdf.
[28]WANG L, XIONG Y, WANG Z, et al. Temporal segment networks: towards good practices for deep action recognition [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9912. Cham: Springer, 2016: 20-36.
[29]FEICHTENHOFER C, PINZ A, WILDES R P. Spatiotemporal residual networks for video action recognition [C]// Proceedings of the 2016 International Conference on Neural Information Processing Systems. New York: Curran Associates Inc., 2016: 3468-3476.
[30]FEICHTENHOFER C, PINZ A, ZISSERMAN A. Convolutional two-stream network fusion for video action recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1933-1941.
[31]CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? A new model and the kinetics dataset [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4724-4733.
[32]MA S, SIGAL L, SCLAROFF S. Learning activity progression in LSTMs for activity detection and early detection [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1942-1950.
[33]DONAHUE J, HENDRICKS L A, GUADARRAMA S, et al. Long-term recurrent convolutional networks for visual recognition and description [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 2625-2634.
[34]NG J Y H, HAUSKNECHT M, VIJAYANARASIMHAN S, et al. Beyond short snippets: deep networks for video classification [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 4694-4702.
[35]WU Z, WANG X, JIANG Y, et al. Modeling spatial-temporal clues in a hybrid deep learning framework for video classification [C]// Proceedings of the 23rd ACM International Conference on Multimedia. New York: ACM, 2015: 461-470.
[36]SCHULDT C, LAPTEV I, CAPUTO B. Recognizing human actions: A local SVM approach [C]// Proceedings of the 17th International Conference on Pattern Recognition. Piscataway: IEEE, 2004: 32-36.
[37]DOLLAR P, RABAUD V, COTTRELL G, et al. Behavior recognition via sparse spatio-temporal features [C]// Proceedings of the 2005 IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance. Piscataway: IEEE, 2005: 65-72.
[38]TAYLOR G W, FERGUS R, LECUN Y, et al. Convolutional learning of spatio-temporal features [C]// Proceedings of the 2010 European Conference on Computer Vision, LNCS 6316. Berlin: Springer, 2010: 140-153.
This work is partially supported by the National Key Research and Development Program of China (2017YFC0806504), the Science and Technology Strong Police Project of Anhui Province (201904d07020007).
GUO Mingxiang, born in 1995, M. S. candidate. His research interests include computer vision, intelligent robot.
SONG Quanjun, born in 1974, Ph. D., professor. His research interests include service robot, intelligent human computer interaction.
XU Zhannan, born in 1987, M. S., assistant research fellow. His research interests include robot intelligent control, human-computer interaction.
DONG Jun, born in 1973, Ph. D., associate research fellow. His research interests include computer vision, artificial intelligence.
XIE Chengjun, born in 1979, Ph. D., associate research fellow. His research interests include computer vision, pattern recognition, machine learning.
收稿日期:2019-06-21;修回日期:2019-09-14;錄用日期:2019-09-18。
基金项目:国家重点研发计划项目(2017YFC0806504);安徽省科技强警项目(201904d07020007)。
作者简介:郭明祥(1995—),男,四川达州人,硕士研究生,主要研究方向:计算机视觉、智能机器人; 宋全军(1974—),男,安徽宿州人,教授,博士,主要研究方向:服务机器人、智能人机交互; 徐湛楠(1987—),男,河南南阳人,助理研究员,硕士,主要研究方向:机器人智能控制、人机交互; 董俊(1973—),男,安徽合肥人,副研究员,博士,CCF会员,主要研究方向:计算机视觉、人工智能; 谢成军(1979—),男,安徽全椒人,副研究员,博士,主要研究方向:计算机视觉、模式识别、机器学习。
文章编号:1001-9081(2019)12-3482-08DOI:10.11772/j.issn.1001-9081.2019061056
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
中国远程教育(2016年11期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
