
基于深度学习的诱捕器内红脂大小蠹检测模型
2019-01-05 07:44张冬月袁明帅任利利刘文萍王建新
农业机械学报 2018年12期
孙 钰 张冬月 袁明帅 任利利 刘文萍 王建新
(1.北京林业大学信息学院, 北京 100083; 2.北京林业大学林学院, 北京 100083)
0 引言
红脂大小蠹为小蠹科、大小蠹属的一种昆虫,是危害松科植物的蛀干害虫[1]。1998年山西省首次发现该虫后[2],危害面积迅速扩大。2004年红脂大小蠹扩散到陕西省、河北省、河南省多地,发生面积超过5×105hm2,枯死松树达600多万株[3]。2005年扩散到北京市门头沟区[4]。近年在辽宁省凌源市和建平县、内蒙古宁城县和喀喇沁旗发现该虫。
准确及时的虫情监测预警可指导早期防治,避免重大经济和生态损失。红脂大小蠹成虫迁移能力强、扬飞期长,对其数量和种群的动态监测是该虫防治工作的重要环节。在红脂大小蠹成虫扬飞期,工作人员根据松林分布情况悬挂诱捕器,并定期对林间诱捕器中的红脂大小蠹进行人工识别和计数,存在劳动强度大、费用高、效率低、主观性强等问题。

图1 数据采集与标注Fig.1 Data acquisition and label
随着计算机技术的不断发展,基于计算机视觉、图像处理及模式识别的害虫自动识别技术得到了广泛研究。目前国内外的害虫识别研究工作主要为以下两个方向:①基于计算机视觉的害虫特征提取。识别方法多采用害虫图像的全局特征,如颜色特征[5-10]、形态特征[5-6,8-14]、纹理特征[5-6,9,12]等。由于基于全局特征的描述能力具有局限性,近年出现了许多局部特征与全局特征相结合的特征表达方式[12-13]。随后,FENG等[15]提出了使用文字描述的语义相关视觉(Semantically related visual,SRV)属性描述蛾类翅膀特征,谢成军等[16]提出了稀疏编码与空间金字塔模型相结合的图像表示方式。②选择和优化基于机器学习的分类模型。使用的分类器主要有支持向量机(Support vector machine,SVM)[6-9,17-20]分类器、人工神经网络[7,11,21]、K-nearest neighbor[22]算法、主成分分析(Principal component analysis,PCA)[23]方法。
上述方法虽然取得了一定的进展,但仍无法满足林业害虫全自动监测的需求。上述特征本质上仍由人工预先设定,具有局限性。
相比传统方法,深度学习模型是直接由数据驱动的特征及其表达关系的自我学习[24]。研究人员已开始探索使用深度学习进行害虫识别和检测。DING等[25]使用深度学习对粘板诱捕器上的苹果蛾进行计数,但仅将深度卷积神经网络作为滑动窗口方法的分类器,导致可检测目标尺寸单一且运算量巨大。杨国国等[24]使用基于AlexNet[26]网络识别自然背景中的茶园害虫,尽管AlexNet分类的平均准确率达91.5%,但依赖交互式图像分割算法人工定位害虫位置,导致无法实现自动统计害虫数量。近年来,深度学习在目标检测领域表现突出,可以同时实现目标的定位与识别。当前比较成功的深度学习目标检测网络包括Faster R-CNN[27]、SSD[28]、RetinaNet[29]、Mask R-CNN[30]等,但模型都是针对PASCOL VOC[31]、COCO[32]等通用大数据集设计,目标的类内变化小且类间差异大。
为实现红脂大小蠹虫情自动监测,本文在传统信息素诱捕器中集成摄像头,使用K-means[33]算法改进基于深度学习的Faster R-CNN目标检测模型,检测诱捕器背景中任意姿态的6种小蠹,克服虫体破损、酒精蒸发、液面反光等困难,自动化地定位、识别并计数危害最大的红脂大小蠹。
1 数据材料
1.1 诱捕器内图像采集
本文采用与文献[34]中的实用新型诱捕器相似的漏斗形信息素诱捕器,如图1所示。以信息素诱捕器捕获的小蠹科害虫为检测对象,选取可被信息素吸引的6种小蠹作为实验样本。通过诱捕器与林间捕捉方式在辽宁省凌源市和建平县获取寄主为油松的红脂大小蠹样本,其余5种小蠹主要通过木段饲养、树干解析或诱捕器方式在内蒙古自治区、陕西省、北京市等地获取。小蠹样本数量如表1所示。
原始图像由嵌入诱捕器收集杯中的图像传感器采集。图1a为通过改造诱捕器收集杯实现图像数据采集。首先在传统诱捕器收集杯杯壁水平嵌入摄像头。摄像头感光元件尺寸为1/2.5″,分辨率为2 048像素×1 536像素,搭配2.1 mm定焦镜头,与杯底距离为6.6 cm。杯壁附有LED补光灯。
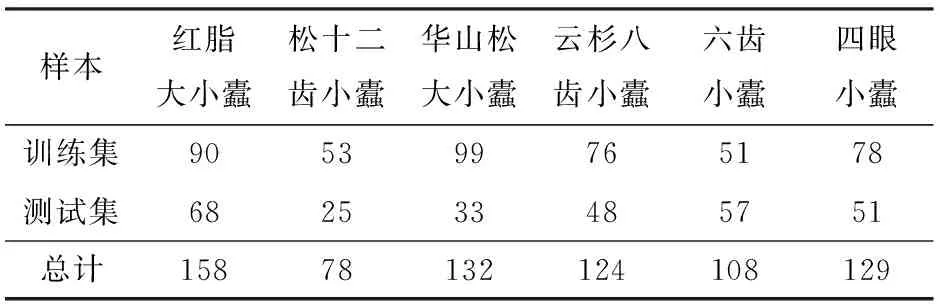
表1 小蠹样本数量Tab.1 Number of scolytidae specimens
诱捕器收集杯中含酒精,酒精最多占收集杯容积的1/5。随机投入1~6种可被信息素诱芯吸引的小蠹,共采集2 593幅图像。因杯壁部分没有检测意义,采集后直接将其排除。首先对原始图像进行高斯降噪处理,然后进行灰度处理,并对产生的灰度图像进行霍夫圆检测[35],定位圆形杯底,最后根据检测出的圆形杯底对原图像进行裁剪。图1b为拍摄原图,图1c为裁剪后图像,裁剪后分辨率为1 295像素×1 295像素。
图像标注由采集人员完成并经昆虫学家确认,标注包括边界框坐标和类别两类信息。图1d是对图1c的标注,边界框为包围小蠹的最小长方形,红色代表红脂大小蠹。
1.2 数据集建立
为了验证模型的有效性,训练集和测试集分别使用不同的小蠹样本。划分1 913幅图像作为训练集,680幅图像作为测试集。小蠹样本使用情况如表1所示。模型训练集和测试集均包含多种姿态和不同破损程度的小蠹图像,部分图像出现小蠹身体接触或遮挡。拍摄过程中,小蠹多数沉至杯底,少数漂浮在酒精液面,且多数图像的拍摄过程受到倒影、反光等环境影响。本文根据小蠹图像识别的难易程度把测试集分为简单测试集和困难测试集,分别为490幅和190幅。困难测试集中的图像多为虫体残破、小蠹数量多且拥挤的图像,同时加入了诱捕器收集杯中酒精挥发后的小蠹图像(训练集中不包括此类图像),采集图像时在诱捕器收集杯中加入了松针、树皮、少量其他昆虫(蚂蚁、小灰长角天牛)作为复杂背景。图2a~2d为简单测试集,图2e~2h为困难测试集。

图2 测试集中典型图像Fig.2 Typical images of test sets
2 检测方法
诱捕器内小蠹检测的难点主要有:①类间差异小。被信息素诱芯吸引的6种小蠹均为小蠹科,其中华山松大小蠹与红脂大小蠹同属大小蠹属。②类内变化大。小蠹落入收集杯后不仅姿态、位置各异,并且包含不同个体大小及肢体破损。③背景不一致。收集杯内可能落入松针、树皮等杂质,酒精会反光,并因蒸发导致液面高度变化。针对上述问题,本文改进基于深度学习的Faster R-CNN目标检测模型,以实现诱捕器内的全自动红脂大小蠹检测。
2.1 Faster R-CNN目标检测模型
REN等[27]提出了Faster R-CNN目标检测模型,由区域建议网络(Region proposal network,RPN)和Fast R-CNN[36]组成。RPN和Fast R-CNN共享卷积特征,可有效地缩短检测时间。Faster R-CNN在第1阶段最后卷积层输出的特征图上添加全卷积RPN,以密集分布的不同宽高比和尺寸的默认框为基准,生成高质量候选区域;在第2阶段,Fast R-CNN负责学习候选区域特征并对其进行目标分类和检测框回归。Faster R-CNN通过交替运行梯度下降方法,轮流优化RPN和Fast R-CNN,实现共享参数的快速目标检测。RPN训练阶段,仅将与标注框交并比(Intersection over union,IoU)超过70%的默认框记做正默认框,将与标注框IoU不超过30%的默认框记做负默认框,舍弃其余的默认框。模型使用的损失函数由目标分类损失Lcls和检测框回归损失Lreg组成。Lcls是判断是否为目标的对数损失,Lcls、Lreg的计算公式为
(1)
(2)
式中i——默认框序号
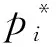
ti——检测框的4个参数位置,表示检测框相对于默认框的偏移量

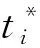
(3)
式中Ncls——每幅图像随机采样的默认框的数量
Nreg——默认框中心点数量
λ——平衡权重
使用Ncls、Nreg和平衡权重λ对两种损失进行标准化。
2.2 基于K-means的默认框改进
Faster R-CNN输出各默认框内的目标类别及位置调整值。Faster R-CNN使用3×3窗口在第1阶段最后卷积层输出的特征图上滑动,每个窗口的中心点映射到原始图像,根据映射的中心点在原始图像上生成不同比例和尺寸的默认框。原始的Faster R-CNN是人为指定如表2所示的原始默认框,以256像素×256像素的框为基础框,生成默认框宽高比分别为0.5、1、2,与基础框面积比为0.062 5、0.25、1、4的12个默认框。RPN训练阶段,只有正默认框才能生成两种损失。受镜头焦距、拍摄距离和小蠹体型的约束,小蠹数据集的目标大小和通用数据集存在较大差异,本文使用K-means方法对小蠹数据集中的标注框进行聚类分析,选取适合检测诱捕器内红脂大小蠹的默认框,聚类过程中默认框与标注框之间距离的计算公式为
(4)
式中bground——训练集标注框
bdefault——默认框
聚类前后模型采用的默认框尺寸如表2所示。

表2 默认框优化前后尺寸对比Tab.2 Comparison of size of default boxes before and after optimization 像素
图3中图像分辨率为600像素×600像素,是模型的输入分辨率,图像中绿框为一组原始的默认框,红框为聚类后的一组默认框,相比之下聚类后的默认框与红脂大小蠹重合度更高,有效减少了消耗计算资源但不生成训练误差的默认框数量,更加有利于梯度的生成。

图3 原始默认框和聚类后默认框对比Fig.3 Comparison between original default boxes and clustered default boxes
2.3 红脂大小蠹检测流程
红脂大小蠹的检测流程如图4所示,首先将从诱捕器中采集的小蠹图像进行预处理。预处理包括将图像缩放至600像素×600像素,RGB各通道归一化至正态分布。然后将预处理后的图像输入模型进行检测,使用非极大值抑制(Non-maximum suppression,NMS)方法去除同类之间IoU大于50%的检测框,按分类信心排序后,最多输出100个检测结果。图4中的红色方框为检测结果,图像左上角标注出红脂大小蠹的数量。

图4 红脂大小蠹检测流程图Fig.4 Flow chart of red turpentine beetle detection
3 实验与结果分析
3.1 模型训练
本文中检测模型采用ResNet50[37]为特征提取器,训练阶段采用动量为0.9的随机梯度下降算法(Stochastic gradient descent,SGD)进行优化,初始学习速率为3×10-4。软件实现基于TensorFlow深度学习框架,硬件平台采用AMD Ryzen 1700X CPU(64 GB内存)加Nvidia TITAN Xp GPU(12 GB显存)。
为了更加详尽地评价本文检测模型,本文使用面向个体的定量评价指标和面向诱捕器的定性评价指标[25]。面向个体的评价指标主要针对红脂大小蠹个体检测效果进行评价,面向诱捕器的评价指标主要针对检测图像中是否存在红脂大小蠹的效果进行评价。

图5 测试集的个体精确率-召回率曲线Fig.5 Curves of object precision-recall on test set
3.2 面向个体的定量评价
面向个体的精确率和召回率的计算公式为
(5)
(6)
式中p——面向个体的精确率
r——面向个体的召回率
Tpositive——正确类数量
Ndetected——检测框数量
Nground——红脂大小蠹标注框数量
检测框和标注框类别相同且IoU大于50%为真正类。面向个体的精确率和召回率的调和平均值计算公式为
(7)
式中β——调和参数,设为2
本文采用面向个体的精确率-召回率的曲线下面积(Area under the curve,AUC)[31]作为定量评价指标,简称个体AUC,曲线如图5所示。实验结果表明使用K-means算法进行参数优化后的红脂大小蠹检测模型在困难测试集上个体AUC达到了0.862 7,在简单测试集上个体AUC达到了0.985 9,在整体测试集上个体AUC达到了0.935 0。改进后的模型相对于未改进模型在困难测试集上个体AUC提高了4.33%。基于SSD的红脂大小蠹检测模型SSD300和SSD512在困难测试集上个体AUC分别为0.529 1和0.428 3,在整体测试集上个体AUC分别为0.708 2和0.678 8。
3.3 面向诱捕器的定性评价
面向诱捕器的精确率和召回率的计算公式为
(8)
(9)
式中p′——面向诱捕器的精确率
r′——面向诱捕器的召回率
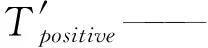

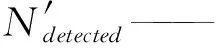
如果模型在一幅诱捕器图像中至少正确检测出一只红脂大小蠹,则认为是真正类。面向诱捕器的精确率和召回率的调和平均值的计算公式为
(10)
本文采用面向诱捕器的精确率-召回率AUC作为定性评价指标,简称诱捕器AUC,曲线如图6所示。实验结果表明:使用K-means算法进行默认框优化后,模型在困难测试集上诱捕器AUC达到了0.944 7,在简单测试集上诱捕器AUC达到了0.983 4,在整体测试集上诱捕器AUC达到了0.972 2。改进后的模型相对于原始模型在困难测试集上诱捕器AUC提高了3.28%。基于SSD的红脂大小蠹检测模型SSD300和SSD512在困难测试集上诱捕器AUC分别为0.854 1和0.870 2,在整体测试集上诱捕器AUC分别为0.855 9和0.921 1。
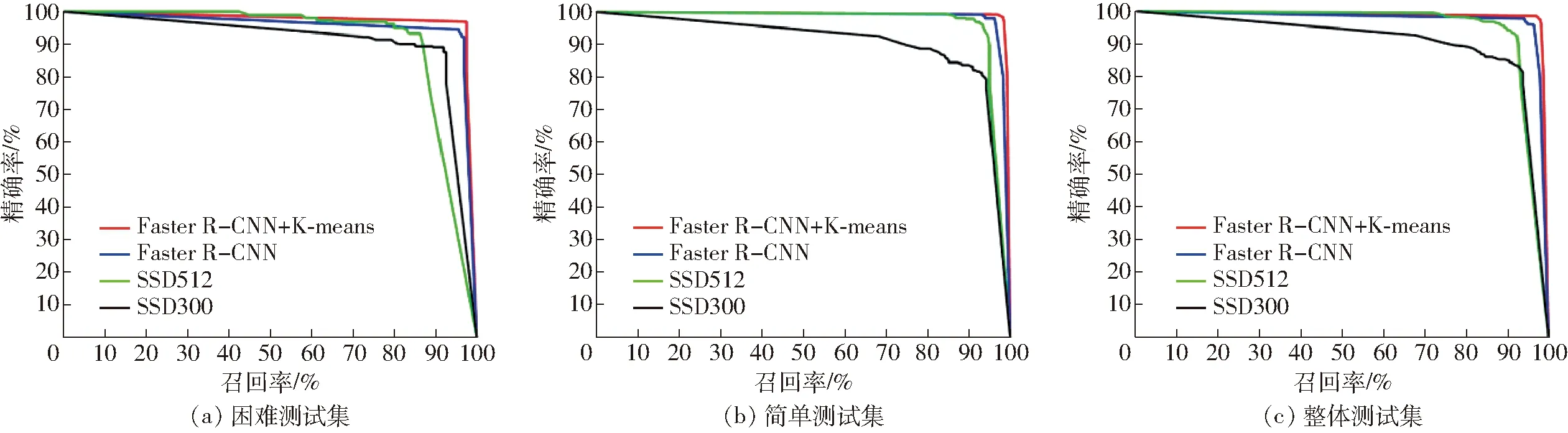
图6 测试集的面向诱捕器的精确率-召回率曲线Fig.6 Curves of trap precision-recall on test sets
3.4 结果分析


图7 典型错误示例Fig.7 Typical false detections
4 结束语
改进的深度学习目标检测模型Faster R-CNN符合大多数研究对于小蠹样本及拍摄条件严格的要求,避免了预处理及特征提取阶段的人工干预。使用K-means聚类方法对模型的默认框进行改进后,有效减少了消耗计算资源但不生成训练误差的默认框数量。改进后的模型在困难测试集上的个体AUC、诱捕器AUC分别提高了4.33%、3.28%,整体测试集上的个体AUC、诱捕器AUC分别达到了0.935 0、0.972 2,实验证明,该模型可有效定位、识别和计数信息素诱捕器内危害最大的红脂大小蠹。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
四川大学学报(自然科学版)(2021年6期)2021-12-27
计算机应用(2020年12期)2020-12-31
红领巾·萌芽(2019年8期)2019-08-27
劳动保护(2019年7期)2019-08-27
福建基础教育研究(2019年11期)2019-05-28
CHIP新电脑(2016年3期)2016-03-10
文苑(2015年9期)2015-09-10
中学科技(2015年1期)2015-04-28
新课程学习·中(2013年3期)2013-06-14
