
基于TensorFlow的LSTM循环神经网络短期电力负荷预测
2019-01-02 13:01李松岭
上海节能 2018年12期
李松岭
0 引言
近年来,由于我国电力领域市场的建立、发展日趋完善,电力负荷的预测也逐步成为电力系统运行经济化以及构建智能电网的主要模块[1],同时也是电力领域里研究的重要课题。在如今的电力大数据环境下,电力工作者对电力负荷预测进行了大量的研究。目前常见的模型有:时间序列[2]、决策树[3]、支持向量机[4]、灰色理论[5]、模糊理论[6]和人工神经网络[7]等。但是,由于电力负荷的模糊性及非线性的特点,使这些方法在预测时已远远不能达到负荷预测的精度和实时性要求。因此,基于深度学习工具TensorFlow的深度学习LSTM循环神经网络的处理方法应运而生。从目前看来,深度学习方法随着计算机计算性能的提升,其方法在包括图像分析、自然语言处理等各个领域大放异彩。该算法应用于电力负荷预测领域,在提升短期电力负荷预测精度方面对比传统机器学习方法有较大提升。
1 短期电力负荷预测基本流程
1.1 相关影响因素分析
在短期电力负荷预测中,分析及获取影响短期负荷的特征因素极为重要。经过分析并参考大量的文献[8,9],选取以下特征作为衡量负荷的关键因素:
(1)时间因素(粒度精确到15分钟)。电力负荷的大小会随用电时间的峰谷而显著变化,因此,其属于时间序列数据,这也是使用LSTM算法可以高精度预测的原因,它在处理时间序列数据上有优秀的成绩。
(2)节假日因素。节假日对于用户以及企业用电都有很大的差别,我们在处理时将其离散化,0表示工作日,1表示节假日。
(3)温度因素。气温的变化也会显著的影响发电量的多少,选取每天的最高气温、最低气温作为关键特征。
(4)降水量。湿度在很大程度上会使电厂在发电量上做出调整。
(5)是否极端天气。当发生如雷暴等极端天气时,会影响电力的供应,因此也会作为一个重要指标纳入模型。
1.2 数据预处理
在进行电力负荷预测时,会获取海量的历史负荷数据,其中,往往会由于机器或人为的原因,使数据中出现一些偏差的离群数据以及缺失数据,这些“坏数据”的存在往往会极大地影响预测的精度,因此我们首先进行检测并加以处理。
针对异常的数据,采用如下方法进行处理:
(1)概率统计法对非异常数据进行统计,通过统计出的置信区间,识别处理异常数据。
(2)曲线替换法对一些明显异于正常负荷曲线的日负荷进行删除替换处理。
(3)经验修正法从经验角度出发,通过对比正常负荷曲线,找到某一时间段的数据值。
(4)平均值填补法针对缺失数据,取相邻数据的平均值代替。
此外,由于各项特征的量纲不同,如果将不同量纲的数据直接导入进行模型训练,很容易会出现模型不收敛的结果,因此要对数据进行归一化处理:
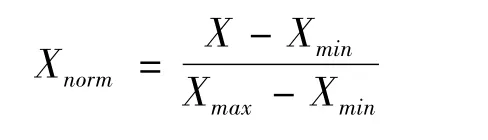
其中,Xnorm为归一化后数据,X为原始数据,Xmax、Xmin分别为原始数据的最大值及最小值。
1.3 基于TensorFlow的LSTM循环神经网络算法
1.3.1 TensorFlow深度学习工具
TensorFlow是谷歌研发的第二代人工智能学习系统,它是一个依靠数据流图进行数值计算的开源软件库。它可以用于包括机器学习和深度学习在内的各个方面的研究。由于其高度的灵活性、优良的可移植性以及多语言的支持,如今已成为最受欢迎的深度学习工具,本文的LSTM算法同样基于TensorFlow工具进行试验开发。
1.3.2 LSTM循环神经网络
循环神经网络(Recurrent neural networds,RNN)是一种处理和预测序列数据的神经网络,可以充分地分析挖掘数据中的时序信息和语义信息。RNN将上几个时刻隐藏层的输出数据作为自身层的输入,从而使时间维度信息得到保留。RNN的结构如图1所示。模块A输入Xi,并输出一个值Hi,循环使信息从当前步传递到下一步。
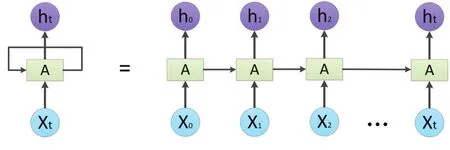
图1 RNN结构图
长 短 时 记 忆(Long short term memory,LSTM)型RNN模型是传统RNN的改进。它主要解决了RNN模型的梯度爆炸和梯度弥散的问题。如图2所示。LSTM接受上一时刻输出,当前时刻系统状态以及当前系统输入,通过输入门,遗忘门和输出门更新系统状态并输出最终结果。
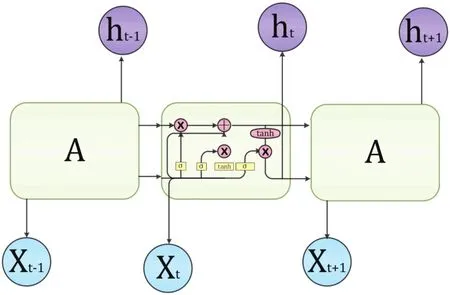
图2 LSTM结构图
如以下公式所示,输入门为it,遗忘门为ft,输出门为ot,输入门决定当前时刻系统输入,遗忘门决定遗忘的信息,输出门决定最终数据输出的部分。
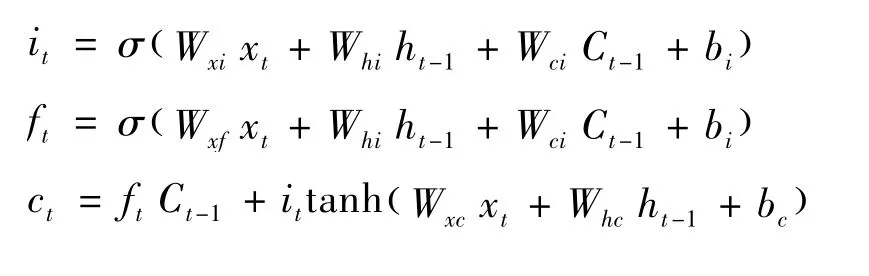
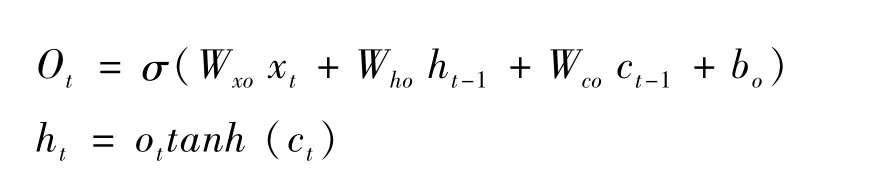
1.1.4 模型评价指标
在评价回归预测模型时,采用通用的平均误差(mean absolute percentage error,MAPE)和均方根误差(root-mean-square error,RMSE)来描述,计算的公式如下:
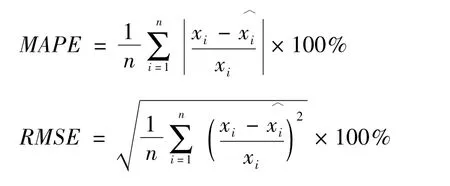
其中,xi为第i时刻负荷的实际值为对应的预测值。
2 实验过程
我们对算法的实际效果进行评估,实验在Ubuntu 16.04系统下利用TensorFlow 1.3.0开发完成。实际电脑配置为:英特尔酷睿i7-3770@3.40 GHz处理器,DDR3 800 M Hz,8GB内存。实验数据为某市某发电厂一段时间内的发电负荷。
为了便于比较,我们同样使用相同的数据,采用目前高精度传统学习随机森林算法和逻辑回归算法对负荷进行预测,便于形成对比,以检验本文算法的优势。

表1 相同数据量时不同算法的预测误差百分比

表2 不同数据量时LSTM算法的误差百分比
从表1和表2可以看出,本文提出的LSTM算法相对于传统的随机森林算法以及逻辑回归算法具有更高的预测精度。由于深度学习算法在训练海量数据的过程中,可以自主学习数据中隐藏的信息,并使其对于错误和离群点更加具有鲁棒性。随着数据量的增加,LSTM算法的预测精度会有进一步的提升。由此通过多次的迭代,最终训练出高精度预测模型。
3 结语
通过使用TensorFlow智能工具,结合目前最先进的深度学习LSTM算法对电力负荷进行预测,预测结果相对于传统机器学习方法有显著提升。同时,随着数据化时代的到来,LSTM算法会在未来广阔的空间发挥更大的作用。
猜你喜欢
纺织标准与质量(2022年2期)2022-07-12
现代电力(2022年2期)2022-05-23
煤气与热力(2022年4期)2022-05-23
长江大学学报(自科版)(2021年6期)2021-02-16
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
