
场景图像中文本区域字符提取方法研究*
2019-01-02 06:56李海浩顾滨兵刘艳平
计算机与数字工程 2018年12期
李海浩 顾滨兵 刘艳平
(91404部队 秦皇岛 066000)
1 引言
自然场景图像字符提取的目的是通过计算机技术在自然场景图像进行字符检测,确定字符在图像中的位置,将字符与背景进行剥离,通过特定算法从图像中提取出相应字符。自然场景图像中字符的识别可快速、有效地在海量图片中获取特定信息[1],对当前信息安全过滤、信息资料查询等具有重要意义[2],但自然场景具有较复杂的背景条件,如倾斜、曲变、曝光度等,因此在自然场景图像中字符的准确定位、识别技术仍处于研究阶段[3]。首先在文本区域提取技术的基础上提出了字符提取模型,基于一种局部重叠阈值的字符分割算法,通过图像的划分、判断、阈值计算和处理,以及字符边界计算和特征过滤等方法,提出了一种场景图像中文本区域字符提取方法。
2 字符提取模型
在自然场景不处理的情况下,直接进行字符提取,会大大降低字符提取效率,且准确率会大幅降低。因此,在字符提取前,可通过图、区域、区块、像素等属性将自然场景区分为文本区块和非文本区块[4],文本区块的提取方法详见参考文献[5]。由连续的多个文本区块组成文本区,通过构建字符提取模型,实现文本区内字符的提取,模型如下:
用W来表示一个自然场景图像,那么W=Wc∪Wb,且Wc∪Wb=Φ ,Wc代表文本区,Wb代表背景区。Wc可以用两个元素来表示:

其中,C表示文本区中的字符,Ci表示第i个字符,β表示字符的属性,βi表示第i个字符对应的属性,βi=((xi, yi) , hi, wi) ,(xi,yi) 为第 i个字符左上角坐标,hi第i个字符的高度,wi第i个字符的宽度。字符区域内单个字符的分割,最后的结果就是要得到集合C和集合β。
该模型是通过以下三步来实现字符的提取:
1)将自然场景的灰度图像作二值化,将文本区内的字符与背景分割;
2)在纵横方向上作投影,分析投影曲线的波峰及波谷从而确定出每个字符的边框位置;
3)制定过滤规则将非字符过滤掉。
3 基于局部重叠阈值的图像二值化
文本区的定位技术实现了文本区从背景图的剥离,但怎样实现字符的识别,还需要对字符进行精确定位,将每个字符的边界找出来,才能将字符输给识别模块进行识别。投影分割法是确定字符的边界的成熟技术,是将文本区的矩形框图像作Otsu二值化处理来实现[6]。但自然场景图像受曝光或光照的影响,字符可能会存在亮度不均匀的现象,应用Otsu算法作二值化处理会出现字符与背景粘连在一起,无法进行字符边界定位[7]。为解决这一问题,提出了基于局部重叠阈值的分割算法。
3.1 算法的总体设计
基于局部重叠阈值的图像二值化算法流程如下图所示。

图1 基于局部重叠阈值的图像二值化算法流程
该算法是对全局Otsu分割算法的改进,结合了局部阈值的分割算法,再加入图像的灰度平均方差这个统计特征,对子图像中是否包含了字符与背景这两个目标进行判断,如果是则运用Otsu算法计算该子图像的阈值,并将阈值存入阈值矩阵。对于未使用Otsu算法计算阈值的子图像,则通过一个阈值填充算法(3.5章节进行详细描述),对阈值矩阵中的空白处进行填充,这样就得到了针对每一个像素的阈值矩阵。最后根据这个阈值矩阵,就可以对原图像进行二值分割了。它的流程图如图1所示,分为五个步骤:
1)子图像划分;
2)计算子图像方差及方差阈值;
3)局部重叠阈值计算;
4)填充空白区域;
5)根据阈值作二值化。
3.2 子图像划分
1)子图像的大小
局部阈值分割是先将原图像划分成若干子图像后,再对子图像进行全局阈值分割。在划分子图像的时候,如果子图像的尺寸太大,子图像内字符与背景仍然存在较大的灰度差异,应用全局阈值分割算法将是低效率的;反之如果子图像的尺寸过于小,便会加剧计算量,大大加长计算时间,同时也会产生块状效应。因此,选取一个合适的划分尺寸将是关键的第一步。
子图像的尺寸大小与原图像中需要保留的最小细节大小有非常密切的关系,当两者相差不多的时候,原图像中需要保留的最小细节可以被划分到一个完整的子图像中,再在子图像中使用全局阈值分割算法对其进行分割,这样即分割了子图像又完整保存了原图像中的细节部分,分割效果可以达到最佳。
2)子图像划分方法
传统的局部阈值分割算法将原图像划分成互不重叠的子图像,图像中的每一个像素就只会被一个子图像所包含。这样划分的结果导致子图像的阈值发生突变,从而使处于不同子图像中的目标对象在跨越两个子图像之间的时候会发生像素灰度的突变,甚至同个子图像里的目标对象都可能被分割成截然不同的灰度。这是因为传统的划分方法忽略了像素之间的坐标关联。
为了解决这个问题,在将原图像划分成子图像的时候,采取了一种新的划分方法,使每个子图像与相邻的子图像之间有一半的像素重叠,从而使得原图像中的每个像素(除边缘像素)总会被四个子图像包含其中,可以在分割结果中便可充分考虑空间上相近的像素之间的关系。在划分到四个不同子图像后,利用全局阈值分割最多得到四个不同的阈值,将这四个阈值进行加权平均,得到的阈值就可以作为该像素点最终分割阈值。图2中填充块为四个子图像中的共有部分,其最终对应的阈值就是由这四个子图像的阈值加权平均后得到,边缘像素可通过两个或一个阀值进行计算。

图2 子图像划分示意图
3.3 子图像判断
对于每个子图像,需要将其进行单独地分割,最后将所有子图像的分割结果组合到一起,得到原图像的分割结果。但并不是所有的子图像中都同时存在有目标与背景两类像素,如果强行将其运用全局分割算法进行分割,会将只存在目标或只存在背景的一类像素分割成为两类,无法达到分割效果。
为解决这个问题,可在子图像应用全局分割算法进行分割之前,判断该子图像中是否同时包含两类像素,若是则应用全局分割算法对其进行分割,否则不进行分割。本算法的判断条件是将子图像的灰度方差s2与方差阈值T_s2进行比较,若s2≥T_s2,则对子图像应用全局分割算法进行分割,否则不分割。计算原图像中所有像素的梯度值并取绝对值,梯度值中的最大值与平均值的乘积作为方差阈值T_s2。方差s2的计算公式如下:
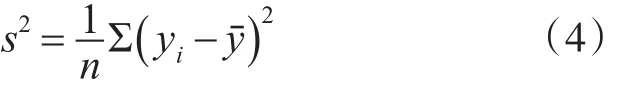
其中:y为子图像的灰度值,yˉ为所有子图像灰度均值。
方差阈值T_s2的具体算法如下:
1)读入原图像,设图像的尺寸为M×N,那么遍历图像,求出每个像素点的灰度梯度值并取绝对值(梯度值的计算方法详见参考文献[5]),遍历结束,求出梯度值中的最大值G_max与平均值G_mean,那么方差阈值:T_s2=G_mean×G_mean s。
2)将原图像划分为尺寸大小为m×n相互间重叠的子图像,那么将得到像。
3)以窗口大小m×n对图像进行扫描,横向步长为m/2,纵向步长为n/2,每个子图像又以“田”字形式分为4分格,对每个子图像的分格计算其灰度方差s2,再将方差s2与方差阈值T_s2进行比较,若大于方差阈值则利用Otsu算法计算该子图像的分割阈值,否则不计算。
4)所有子图像判断完毕,则结束。
3.4 分割阈值的计算
在对划分得到的所有子图像进行方差判断后,对需要进行分割的子图像采用Otsu算法获取得其分割阈值,并且将分割阈值存入到阈值矩阵中。设图像的尺寸为M×N,子图像的尺寸为m×n,子图像间有二分之一部分是重叠的,即在横向上前一子图像与后一子图像间有m/2部分重叠,在纵向上有n/2部分重叠,那么可以将原图像划分为个子图像,每个子图像又以“田”字形式分为4分格,故形成阈值矩阵为
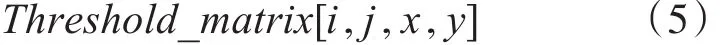
其中:0 ≤ i<2*M∕m,0 ≤ j<2*N∕n,x为0或 m/2 ,y为0或n/2。分割阈值矩阵Threshold_matrix的计算方法如下:Threshold_matrix值表示第i行第j列的子图像中各分格的灰度阈值。
1)以窗口大小m×n对图像进行扫描,横向步长为m/2,纵向步长为n/2扫描图像,根据子图像判断结果,选择是否应用全局阈值分割算法Otsu计算其分割阈值。
2)若需要使用Otsu算法计算阈值,则将子图像的灰度信息送入计算阈值的模块,将返回的阈值结果赋值给阈值矩阵Threshold_matrix[i,j,x,y];若不需要由Otsu算法计算阈值,则将赋0值给阈值矩阵Threshold_matrix[i,j]。
3)遍历图像结束后,对重复扫描区域进行阈值均值计算,按照以下原则进行比较:
i从0开始,步长为 m/2,i<2*M/m;
j从0开始,步长为 n/2 ,j<2*N/n;
x遍历0和m/2;
y遍历0和n/2。
在阈值矩阵中,将i+x相等且j+y相等的阈值进行均值计算,并将均值赋给原阈值矩阵;如:横向步长为=3,纵向步长为=2时,

将四个阀值计算均值为1.1,并将上述四个阈值都修改为1.1。
这样得到的阈值矩阵Threshold_matrix将作为把原图像进行二值化分割的标准。
3.5 空白区域的填充
在对子图像进行完全局阈值分割后,会产生一个阈值矩阵Threshold_matrix,这个矩阵就将作为最后把原图像二值化的标准。但是还存在一个问题,就在于当对子图像计算灰度方差,并对子图像进行比较判断是否需要对该子图像进行全局阈值分割时,若方差值小于计算得到的方差阈值,意味着该子图像不需要进行分割处理,也就没有产生分割阈值。那么在得到的阈值矩阵中,该子图像所对应的阈值为零。就算是通过重叠的子图像划分方法,也依然会出现这样的问题。所以为了解决这个问题,就需要对阈值矩阵进行填充空白的操作。填充阈值矩阵中空白处的方法是根据区域增长法进行的,具体的填充算法如下:
1)遍历阈值矩阵Threshold_matrix,若矩阵中的点 Threshold_matrix[i,j,x,y]值不为 0,即该处不是空,不处理;若矩阵中的点 Threshold_matrix[i,j,x,y]值为0,则进入下一步。
2)检查矩阵中的点 Threshold_matrix[i,j,x,y]其8个领域点内是否存在值不为空的点,若存在则求8领域内值不为空的点的平均值,将平均值赋给Threshold_matrix[i,j,x,y],如果不存在则跳入下一个点继续检查。
3)遍历阈值矩阵Threshold_matrix结束后,检查Threshold_matrix中是否还存在阈值为空的点,若存在则返回到第一步;若不存在空白点则填充结束,新的阈值矩阵Threshold_matrix作为图像二值化分割的标准。
3.6 二值化处理
利用得到的阈值矩阵Threshold_matrix对原始图像进行二值化分割。首先遍历原始图像中的每一个像素点,根据像素点的下标找到该点所对应的阈值矩阵中的阈值,再将该像素点的灰度值与对应阈值矩阵中的阈值相比较,若像素的灰度值大于阈值那么将该点的灰度值取值为255,不然将该点的灰度值取值为0,遍历结束后将得到一幅只有两个灰度级的二值图像,字符像素的灰度值为0(黑色),背景像素的灰度值为255(白色)。
4 单个字符的边界计算
为了提取出每个字符,先将其在水平方向上进行投影,根据投影曲线确定每个字符行的上下边界[8~9]。计算方法如下:遍历字符区域的二值图像,统计每一行上字符像素的个数,再以二值图像的纵坐标为横坐标,对应每一行上的字符像素个数为纵坐标,就可以得到字符区域在水平方向上的投影曲线了。字符行与字符行之间有个明显的波谷,这个波谷就是两个字符行之间的空白部分,可作为两行字符的分割标志。
其次,将字符行的二值图像在垂直方向上作投影,由投影曲线确定字符行中每个字符的左右边界。方法如下:遍历每个字符行的二值图像,统计第一列上字符像素的个数,再以字符行二值图像的横坐标为投影曲线的横坐标,每一列上的字符个数为纵坐标,就可以获得字符行在纵向上的投影曲线。同样,字符行中字符间的存在明显的波谷,为每个字符的左右边界。
最后,将单个字符的二值图像再在水平方向上作投影,确定字符的上下边界,方法与字符区域在水平方向上作投影类似。
5 根据字符特征过滤非字符
在到了每个字符的上下左右边界,往往会存在些虚假的字符区域,因此在定位单个字符边界时仍然会产生一些虚假字符,可根据单个字符的特征将非字符过滤掉[10]。
1)设二值图像中连通分量的个数为num,如果它的值大于阈值char_num,则认为其为非字符。在比较常见的字符中,每个字符一般都只是由几个连通分量构成,如数字或者英文字母一般只有1或2个连通分量,而汉字相对多一些,但一般也不会达到十几个。因此,可以利用这一特征来区别文字与非文字。如图3所示,它的连通分量多达17个,因此断定它为由背景产生的虚假字符。

图3 虚假字符
2)根据字符的长宽之比判别文字与非文字。通常字符的高与宽的比值h_w_rate都在1:1到2:1之间,除了个别的字符如数字“1”和汉字“一”比例不在这个区间,大部分字符的比例都是落在这区间内的,因此可以利用这一特征来过滤虚假字符。
3)字符像素的面积与包含字符的矩形框的面积之比,通常字符像素面积与包含它的矩形框的面积之比都达到30%以上,所以如果得到的结果中有Coverage低于30%的,则认为该结果是因背景产生的,而不是真正的字符。
通过以上规则过滤之后,基本实现了字符的提取,可应用字符识别技术对提取后的字符进行进一步识别,最终实现字符的识别。
6 结语
国内外许多学者致力于场景图像中字符识别技术的研究,而字符提取技术是其中一项关键技术。在文本区块划分技术的基础上,提出了场景图像中字符提取模型,详细介绍了基于局部重叠阈值的图像二值化方法,通过投影法来对字符区域内的单个字符进行分割,解决了字符区域内字符分割和边界的划分问题,并根据字符的特征对分割结果进行过滤,最终实现单个字符的提取。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
集装箱化(2021年1期)2021-04-12
天津医科大学学报(2021年1期)2021-01-26
汉字汉语研究(2020年2期)2020-08-13
中国信息技术教育(2020年2期)2020-02-02
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
初中生世界·九年级(2017年10期)2017-11-08
