
一种改进的垂直搜索引擎研究与设计
2018-12-28 06:41:10帅应罗文琪熊丽珍舒忠
现代计算机 2018年34期
帅应,罗文琪,熊丽珍,舒忠
(荆楚理工学院,荆门448000)
0 引言
国家提出的“互联网+”及“大数据”发展战略,使得传统的包装及印刷行业主动或被动地融入其中,为这个古老的加工产业带来了生机与希望。其优势主要体现在遥远的距离被拉近,且囊括了整个加工行业的方方面面。当然,实现“互联网+”及“大数据”战略转型的基础平台之一就是网络搜索引擎的应用。
1 垂直搜索引擎简介
在垂直搜索引擎应用理论研究方面,可谓成果丰硕。近几年来,有文献对五种流行的垂直搜索引擎进行了分析,总结出检测截止效应和检测溢出效应特性[1]。有文献提出了基于随机游走的节点排序方法,通过对异构图上的不同路径进行判别,从而得出具有不同语义的节点排序结果[2]。有文献提出了基于模型的协同过滤方法,应用图形聚类算法并考虑信任语句,最终获得合适的信息[3]。有文献提出了通过建立用户兴趣反馈图,经多轮随机游走(Random Walk)提取相似度算法实现信息索引[4]。有文献提出了通过深度神经网络建模[5-6],实现“特征识别与提取→自主学习(数据训练)→上下文影响关系→获取结果信息”的流程;还可以通过卷积神经网络建模[7-9],实现“特征提取(卷积方式)→非线性数值变换→语义特征向量→计算相似度→获取结果信息”的流程。在搜索引擎评估方面,现有的研究成果多以Perplexity 指标体系进行评估,通过设定前面的N 个词,计算出N+1 个词可能出现的概率分布[10]。有文献提出了反馈、问卷、收集、记录、标注等功能一体的准确性评估体系[11]。
在垂直搜索引擎应用方面,自上世纪90 年代以来,国外出现了不少优秀的垂直搜索引擎。1998 年9月,Google 搜索引擎创建[12-13],支撑其发展的主要包括分布式存储、分布式处理和分布式数据库三大核心技术。2005 年7 月,雅虎发布了Trip Planner 旅游搜索引擎。国内在垂直搜索领域也有所建树,2002 年百度就推出了百度MP3 搜索[14],阿里巴巴在2010 年成立了一淘网。国内垂直搜索引擎在技术层面与国外还有一定差距,而且行业认识和理解方面也有短板,因此国内垂直搜索还有很大的发展空间。
1.1 搜索引擎的结构
检索引擎是一种互联网页面软件,可依据用户输入的字、词、句内容获取所需的网页,大信息量数据交换必须以检索资料库作为重要的运行基础。检索引擎主要包括网络机器人采集程序(或网络爬虫)、索引及数据库等,其基本结构如图1 所示。其中,网络机器人是一种用于搜索Web 网站的程序,其核心是Socket 协议,该程序可以利用访问Web 网站得到该网站的文件目录和分层结构以及搜索出断开的超级链接和不正确的拼写等[15]。

图1 搜索引擎系统结构图
1.2 开源搜索引擎Nutch
自2000 年3 月Doug Cutting 开发了Lucene 搜索引擎以来,Lucene 就被广泛应用于网络全文索引领域。随着Java 技术的应用,在Lucene 的基础上又推出了Nutch 全文搜索引擎,Nutch 继承了Lucene 强大的逻辑性、条理性和严谨的模块化结构,其查询范围和存储功能都得到了较大提升[16]。图2 所示为Nutch 和Lucene 的关系。

图2 Nutch-Lucene关系图
2 垂直搜索引擎的设计与实现
2.1 系统总体结构图
图3 所示为本文提出的搜索引擎,主要有以下几部分构成:
(1)信息采集模块。该模块主要完成对有效信息的采集,在主题爬虫中关键是设定一些网站的相关信息、有效信息的抓取方式和条件,并规划主题爬虫的搜索路径。
(2)页面除噪模块。该模块主要用于对抓取的信息进行进一步筛选,剔除获取页面中的无价值信息。由于主题爬虫选取的页面通常都带有一些辅助信息,如:网页界面或用户的交流信息、广告等附加图文信息、HTML 界面的CSS 代码等,删除这些不相关的信息,有利用价值信息的获取。
(3)索引模块。该模块主要用于对抓取和筛选后的信息进行整理,当然索引数据库的建立必不可少。索引在系统的组成中十分关键,是判断系统搜索速度和准确度的标准。从互联网获取的信息一定是杂乱的,不利用对有效信息进行查询,因此,需要对获取的数据信息进行重新排列,排序方式首先要考虑根据“文本和字段”的内容进行划分,还需要考虑加入“内容和主题”的区分条件。通过整理后的信息,也应按照相应的规则进行存储和管理。
(4)查询模块。该模块主要完成用户对的搜索内容的认别及对认别结果的反馈。分别制定以“内容”为主的查询规则(关键句查询)和以“主题”为主的查询规则(关键字、词查询),设定查询控制方式并与信息采集模块、索引模块的信息抓取和索引方式对应,通过对关键字、词、句进行精确解读,建立与索引文件的联系和信息比较,便于用户完成筛选和获取所需信息。

图3 系统总体结构图
2.2 改进的功能模块设计
(1)主题爬虫模块设计
垂直搜索引擎的核心是网络爬虫中的信息采集部分,当前,在智能爬虫模块设计中主要包括:主题相似度设计、反爬虫策略设计和精准的URL 定位设计三个部分。主题相似度计算通常采用的网页抓取评分算法实现。
网页抓取评分算法是主题爬虫模块中最主要的组成部分之一,是网页相似度比较的重要手段,是整个垂直搜索引擎的核心。主流的网页评分算法分为Lucene算法和Nutch 算法两类,其中又包含了众多的算法和一些改进算法。
本文提出的网页评分算法采用一种改进的Nutch算法实现,其核心是引入网页有效性得分算法,该算法分别制定内、外链接的有效性评分标准,并根据从不同角度获取的评分值,确定链接得分的权重生成评分因子。
主题爬虫模块设计的主要流程是:获取信息的条件设置→解析互联网传输协议实现远程连接→获取互联网资源地址→获取抓取数据并在本地存储→有效信息控制。
(2)消除页面噪音模块设计
本文的提出的页面去噪模块没有整合在主题爬虫模块的信息抓取部分,其主要原因是防止与主题爬虫模块中设定的信息抓取条件相互影响。另外,该模块只作用于本地计算机,基本不与互联网建立联系,可减轻主题爬虫在互联网中进行运算的强度,同时,设计对不需要的信息进行删除操作,减轻本地数据的存储压力。
页面去噪模块的算法实现可采用K-means 算法(聚类划分),其主体思想是:首先确定聚类常数K 的个数,K 的个数确定以“同一聚类中的信息相似度较高”为原则;将抓取目标信息集合分解为C 个类型,以C 个类为初始中心;在经过K 次迭代计算后,得出与C 个类之间的距离,以“距离最短”为原则,选出作为有效目标信息进行归类;采取均值法对中心距离进行更新,一直进行K 次迭代计算直到结束,从而筛选出全部有效信息。算法实现的关键是初始中心确定和引入的距离计算公式。在对无效信息进行判别时,剔除一些与营销类有关销售类的网页,例如:对价格等关键词定义特征值。其实现流程是:启动与网络资源库的联系→建立筛选模式(与互联网相同的树式结构模型)→分析网络资源库的网页信息并初始化为筛选模式结构→依据筛选模式对无效信息进行剔除→使用K-means 算法进行相似度运算进一步提取有交效信息→删除所有无效信息→将有效信息存入页面文档库。
(3)索引功能模块设计
本文设计的索引模块使用基于Java 的全文索引工具包——Lucene 完成,其应用与实现都非常简单,图4所示为设计流程。
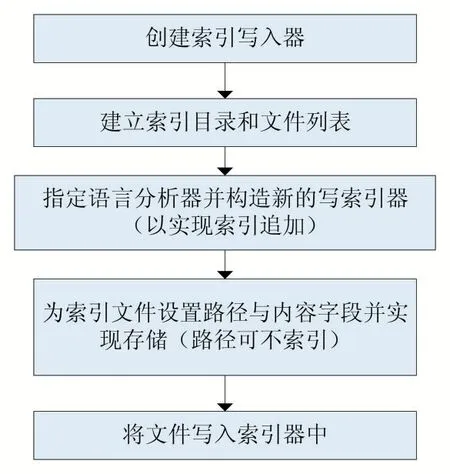
图4 索引建立流程图
(4)查询功能模块设计
实现查询功能的基础是对待查询的全部目标进行排序(可按字、词、句的特征信息进行区分并定量确定值的大小,此步操作通常在索引功能模块中已完成),并将查询目标集合定义为数组。查询方式通常有两种:一种是线性查询,另一种是二分查询。线性查询通过定义数组的初始值α[0]后,按排序顺序依次进行比较直至找到目标值。二分查询也被称为折半查询,首先定义目标值为α[i],将数组中的中间元素定义为初始值α[j],如果α[i]=α[j],则查询目标已找到;如果α[i]<α[j],则查询目标确定在α[j]的前半部分,查询时可按线性查询完成(也可倒序查询);如果α[i]>α[j],则查询目标确定在α[j]的后半部分,同样,查询时可按线性查询完成。本文提出的查询功能模块将按递归二分查询方式完成设计。其查询的主要步骤如图5 所示。

图5 查询模块
3 结果测试及分析
本文采用比较分析的方法对提出的垂直搜索引擎性能进行测试,主要测试指标为查全率、查准率、响应时间参数等,重点针对主题爬虫模块。实验将雅虎(中国)、百度、搜狗、大学搜4 个中文垂直搜索引擎作为比较对象,其中,大学搜是通过百度搜索推荐的一款优秀垂直搜索引擎,原本想将谷歌搜索引擎列为重要的实验分析对象,因谷歌退出中国,难于实现中文环节下的真实查询结果显示,因此放弃。
3.1 结果测试
本文采用主观与客观结合的机制对系统的性能进行评估。主观评价直接对搜索查询的准确性和范围进行比较,准确性评价以输出的关键词“包装、印刷、网站”同时出现作为标准,范围评价以出现的有效网页数为标准,可依据搜索查询结果显示的关键词和一些知名的包装及印刷网站的搜索查询结果进行统计实现,还可以通过对实验中所使用的垂直搜索引擎的“爬取网页总数量”和“发现率”进行统计实现。客观评价则以查全率、查准率和响应时间为主要评估依据。相关统计数据见表1 和表2 所示。
其中:设爬取的网页总个数为a,与主题相关网页个数为b,关键词同时出现的网页个数为c,有效网页个数为d。发现率的计算应同时考虑“与主题相关网页个数”和“包装、印刷、网站三个关键词同时出现的网页个数”这两个因素;有效网页个数应该真实反映包装及印刷网站的数量,将全部无效网页个数剔除,特别是一些营销类的网页,这些网类应该已被在网站中;查准率则就考虑“有效网页个数”和“三个关键词同时出现的网页个数”两个因素;在数据统计中加入“4 个老牌包装及印刷网站出现的个数”的原因是:在一些网站中同时存在当前已被用户忽略和还非常被重视两种情况,被忽略的网站访问量少,不易被抓取,被重视的网站访问量大,易被抓取;将响应时间列为评价参数的原因是:当响应时间超过3s 后,将有大量的网站会被放弃抓取。
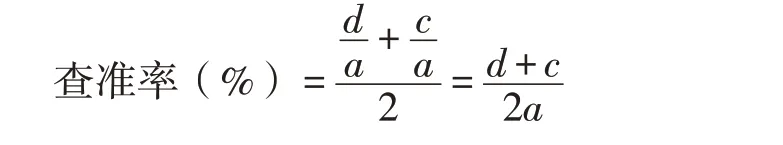
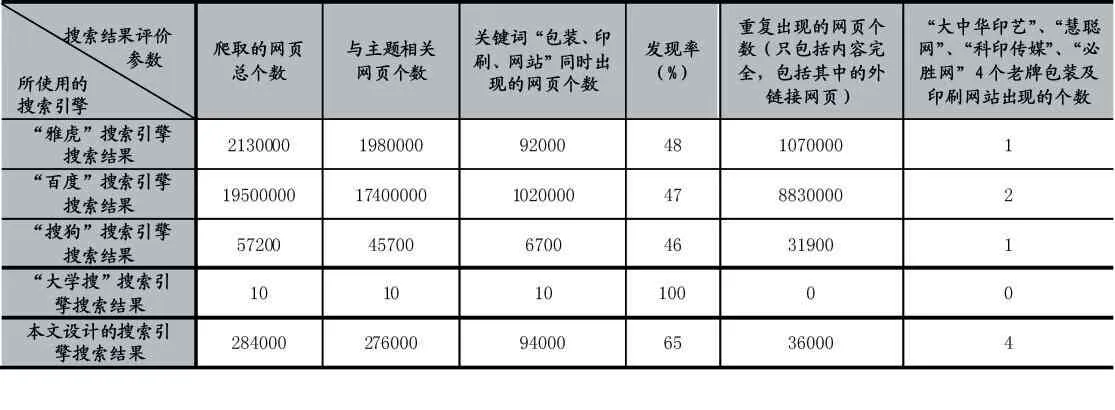
表1 五种垂直搜索引擎主观评价参数统计
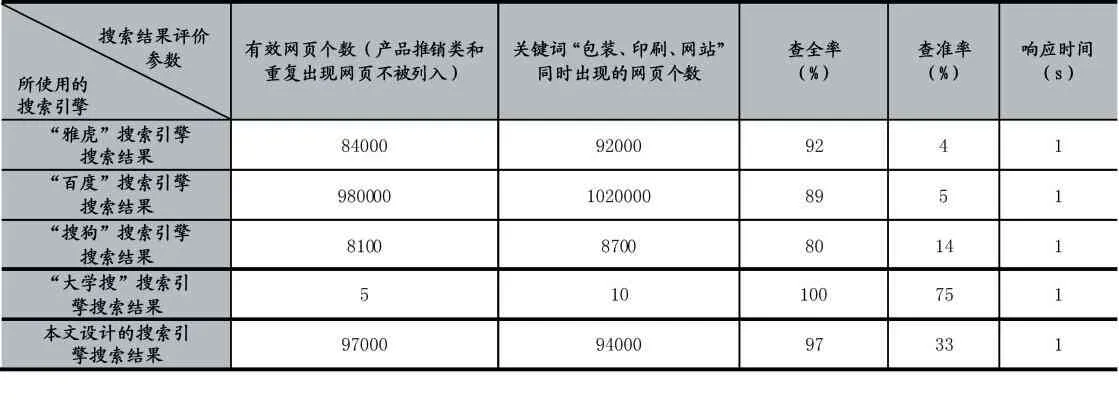
表2 五种垂直搜索引擎客观评价参数统计

3.2 结果分析
通过对表1 和表2 中的数据分析可知,五个中文垂直搜索引擎的爬取能力都非常好,特别是雅虎、百度和本文设计的搜索引擎抓取范围非常广,基本不会漏过需要抓取的主题,而对于关键词的抓取则本文设计的搜索引擎抓取范围最广。雅虎和百度的查准率不高关键是对有效网页和重复出现的网页个数过多所致。以下对雅虎、百度、搜狗、大学搜4 个中文垂直搜索引擎的理论分析,也可以证明结果的准确性。
“雅虎”搜索引擎的核心是Anthelion 爬虫技术,使用Nutch 算法实现。Anthelion 爬虫的评分机制可同时为每个链接网页评分,将结果提供给分类器进行分析,分类器可调整优化,理论上能够获取较高的查准率;其信息解析机制可针对网页内容提取语义数据,从网页中获取数据、格式和注释信息,并存储于内容字段中,将其置为特征信息量;可存储新字段加入索引以扩大查询范围。实验中使用雅虎搜索引擎在互联网中搜索结果并不理想,其主要原因在于爬虫中分类器的优化策略与专业关键词的匹配度存在差距,其整体设计目标适应的范围更广。
“百度”搜索引擎的核心是深度和权重优先抓取相相结合的策略。深度优先抓取策略首先指定一个初始站点将其定义为源点,再指定一个结束点将其定义为顶点;搜索从源点开始并被记录,接下来依次无向对相邻站点进行搜索并记录,在到达顶点并记录后,第一个顶点被重新定义为源点,同时,定义第二个顶点,再次开始按依次无向原则对相邻站点进行搜索记录,直至全部结束。该策略的应用,最终形成一个树型搜索路径,其搜索范围非常广。权重优先抓取策略则是通过比较分析相似度的方式,对相似度高的站点首先进行分类搜索记录,通过定义最低权重值设定顶点,该策略的应用有助于提高搜索的准确性,同时,可完成对搜索结果的排序。实验中成功抓取了一些被忽略的老牌网站,但没有优先显示出来,其主要原因是多个源点至顶点的排序方式采用的了顺序排序,而不是并列排序,影响了对查询结果的显示。
“搜狗”搜索引擎的核心是使用了OPIC 算法,其算法以Cash 值为重要的评分标准。“Cash”可以表示某一个网页的价值量,网页每被抓取一次都有C[n]值存在,在整个网络中(互联网)某一个网页有一个Cash 固定的总值C[z]。“History”用于表示某一个网页被抓取(包括被重复抓取)后的Cash 总值H[z]。在OPIC 算法中,某一个网页的是否重要,就看的结果是否更接近1。OPIC 算法使用C[1,…,n]、H[1,…,n]两个向量表示一个网页的C[n]和H[n],其中,设定Cash的初始值(n 为网页的总个数),History 的初始值H[i]=0;为了进一步提高网页抓取的相似度,OPIC 算法中加入了一个变量G 作为比较参量,G 值的取值依据为History 值,设定实验中发现OPIC 算法存在以下问题:①采用重复抓取作为重要性的评判标准,难免出现“漏网之鱼”;②在重复抓取非目标页面时可能会增加其重要性;③对新增页面采用必抓策略不仅运算量大,还可能降低对没有被重复抓取页面的关注度;④外链接网页的Cash 值可能被忽略。
“大学搜”搜索引擎的核心是使用了PageRank 算法,其数学运算流程相当于“投票”过程,网站的重要程度以获得的“票数”作为评判标准,PR 值是主要的评判指标。PR 值可用检测用户在整个互联网中点击进入某个网站的概率,假设整个网络中的PR 值是均分的,那么PR 值在某个网站的占比就是为网站的网页总数。该算法的主要问题是没有加入特殊链接处理机制,假设使用有向图来表示PR 值,那么该图Z=(X,Y)的构造主要是以X 为节点(即页面),E 为边(显示条件为W 可以通过T 进行跳转)。在计算PR 值时可能会出现图6 所示的特殊网页链接关系,在当前网页直接跳转到其他网页后,可能出现不能返回当前网页的情况,致使运算出现死循环,从而影响PR 值的精准性,引导查询结果不完整。

图6 特殊的网页链接关系图
另外,在“大学搜”的网络爬虫算法中引入了Shark Search 算法(以内容评价为基础的重要垂直搜索引擎网络爬虫算法),由于其原算法对搜索主题和搜索内容没有进行明确界定,降低对两者之间关联度的关注,导致数据准确度不高。“大学搜”在Shark Search 算法中引入向量空间模型,通过对搜索页面和搜索内容之间的关联程度进行分析,大幅提高了搜索的准确性。但是,没有考虑扩大搜索范围方面的因素,放弃了外链接网页,这也是引导查询结果不完整的因素之一。“大学搜”的索引模块和查询模块设计只提供了10 个搜索查询结果的显示。
4 结语
通过理论及实验比较分析表明,参与实验过程的4个垂直搜索引擎都是非常优秀的,且各具特色。有些搜索引擎对某个专业领域的搜索、查询结果不一定能获得最佳的效果,问题主要出在专用与通用的处理机制方面;有些搜索引擎搜索、查询结果范围不广,主要是没有建立的效的外链接机制。同时,也验证了本文设计的垂直搜索引擎在优化系统结构的同时,抓住了主题爬虫这个主要环节,确保了搜索的精确度,在应用方面更具针对性。
本文设计的垂直搜索引擎具有以下特点:
(1)在网络爬虫设计中,以建立关键词特征值为基础,针对包装及印刷信息搜索需求制定高效的特征值评分规则,确保了抓取重点,评分机制同时作用于内链接和外链接,确保了抓取范围。
(2)网络爬虫抓取机制考虑到了专用与通用结合,在确保包装及印刷领域信息搜索的同时,尽量满足了包装及印刷各工序中多方面的信息查询需求。
(3)将页面去噪模块从网络爬虫中分离出来,并营销类网页(当前此类网页非常多)和重复网页实现隔离。
(4)对索引功能模块中的抓取结果排序设计进行改进,根据查询内容的重要性制定排序规则。
(5)在查询功能模块中有效解决了额外排序等问题。
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:03:52
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
现代信息科技(2021年21期)2021-05-07 02:54:12
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年9期)2017-04-17 03:00:46
中国卫生(2015年12期)2015-11-10 05:13:38
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
