
基于RF和SGT算法的子区优先建模对绿洲尺度土壤盐度预测精度的影响
2018-12-27 01:59:38王飞杨胜天魏阳杨晓东丁建丽1
中国农业科学 2018年24期
王飞,杨胜天,魏阳,杨晓东,3,丁建丽1,,3
基于RF和SGT算法的子区优先建模对绿洲尺度土壤盐度预测精度的影响
王飞1,2,3,杨胜天2,魏阳2,杨晓东2,3,丁建丽1,2,3
(1新疆大学智慧城市与环境建模新疆普通高校重点实验室,乌鲁木齐 830046;2新疆大学资源与环境科学学院,乌鲁木齐 830046;3绿洲生态教育部重点实验室,乌鲁木齐 830046)
【目的】试图通过优先在干旱区绿洲的子区构建模型以提高绿洲全局土壤盐度的预测精度。同时量化全局模型和子区模型之间精度的差异性和不确定性。【方法】利用随机森林(Random Forest,RF)和随机梯度增进算法(Stochastic Gradient Treeboost,SGT)定量化上述不确定性,同时,对比本地尺度多个情景(景观)优先建立模型再合并预测值对于模拟全局土壤盐度的精度影响。基于驱动因子(土地利用和地貌),响应因子(Normalized Difference Vegetation Index, NDVI和土壤电导率,EC),研究设计了27个能够相对覆盖典型绿洲不同土壤盐度变异性的环境情景。【结果】70.37%(19/27)的情景证明SGT的预测精度高于RF。单独建模的10个情景的预测精度高于全局模型下10个再分类情景(根据情景设定规则将全局模型预测值再分类)的精度。特别是,EC≤4 ds·m-1和 2 dS·m-1< EC<16 dS·m-1两个情景应该单独进行建模预测。4个情景(两两合并)预测值合并后的精度高于全局模型再分类后的精度。需要指出的是,用于绿洲尺度子区情景构建的首选分割变量是EC,其次是地貌和土地利用。【结论】研究推荐基于SGT在绿洲内部不同景观尺度上优先建模,再将各景观尺度的预测值进行合并,以提高绿洲土壤盐度的推理精度。
土壤盐分;机器学习;干旱区;Landsat OLI;空间异质性;随机森林算法;随机梯度增进算法
0 引言
【研究意义】土壤盐渍化的精准预测是评估绿洲生态环境的适应性和提高资源利用效率的重要前提。【前人研究进展】已有诸多基于遥感信息识别不同区域土壤盐渍化影响程度和分布范围的研究[1-8]。以上研究基于不同传感器(IKONOS,Landsat, MODIS)获取的数据,计算与土壤盐度相关的指数,并建立全局土壤盐度模型,成功预测了各自研究区内盐渍化土壤的分布范围。【本研究切入点】然而,绿洲尺度下与土壤盐分呈现响应关系的环境变量是否可以在绿洲景观组分内(如土利用类型、地貌类型、不同植被覆盖度)持有同等显著性的空间变异解释力尚不明确。绿洲内影响陆气水热交换的因素(如地表粗糙度、反照率)随着自然生境向人工灌溉农业的转变发生改变[9],致使不同土地利用类型之间表面能量和净辐射量发生变化[10]。绿洲内环境建构组分如不同土地利用类型(农田、灌木、草地、盐碱地等)对水盐运移的驱动机制也各有不同[11-13]。若仅依靠全局尺度建构的土壤盐渍化-环境变量模型模拟组分内的土壤盐度空间变异性,可能存在值域被夸大或被低估,甚至被误判的现象(基于流域/绿洲尺度选择的环境变量可能无法充分解释组分内部相对均匀环境中的土壤盐度变化)[14-15]。组分尺度(农田、灌木、草地、盐碱地等)上对于土壤盐渍化-环境响应关系精确定量描述可能有助于提高绿洲尺度的土壤盐渍化制图精度。统计学方法是土壤盐渍化定量研究中的重要手段。机器学习被定义为基于现代统计方法挖掘目标和响应变量之间关系模式的过程[16]。通过查找文献,随机森林(Random Forest, RF)和随机梯度增进算法(Stochastic Gradient Treeboost, SGT)是目前土壤制图领域应用较为广泛的机器学习方法[17-20]。RF的优势在于具备非线性挖掘能力;数据分布不需要符合任何假设;同时处理类型和连续变量;防止过度拟合;有效抑制数据中存在的噪声;定量描述变量的贡献度;只需要率定少量参数[21]。SGT由CART改进而来,通常可以实现准确和稳健的预测,有效抑制过度拟合效应[22]。不需要变量的先验假设,比传统的广义线性或加权模型提供更大的灵活性。存在空间异质性和异常值时,SGT依然能获得较高的预测精度。在复杂关系定义的干旱区土壤生态系统,上述算法具备的优势显得尤为重要。然而,这两种优秀的现代统计学算法鲜有用于预测干旱区土壤盐度的先例。【拟解决的关键问题】本研究一是比较不同环境建构组分下RF和SGT的预测能力;二是定量化描述绿洲分区建模对绿洲尺度盐度预测精度的影响;三是获取不同环境建构组分条件下的敏感因子及其贡献度。
1 材料与方法
1.1 研究区
渭干河-库车河流域(渭库)是位于塔里木盆地北部的一个典型绿洲。该研究区的中心经纬度坐标为82.50°N,41.38°E,主要地貌类型有:低海拔冲积扇平原、低海拔冲积平原、中等高度冲积扇平原、低海拔固定草灌木区,以及低海拔半固定草灌木区(图1)。研究区海拔范围为892—1 100 m,从西北到东南逐渐降低。该区主要的土壤类型为:积土成土、盐碱土、石膏层/钙盐土、钙积变性土、钙成土和石灰性黑土。灌区外围受土壤盐渍化和土壤水分的影响,整体的植被覆盖度较低,自然植被主要包括:and[23]。该区为极端干旱荒漠气候,年平均降雨量为51.6 mm,年平均蒸散量为2 356 mm,年积温为(>10℃)为4 500℃。由于水库引水灌溉急剧增加(由于灌溉土地的扩张),该区地下水位和地下水矿化度显著增加。地下水位上升和地下水盐化是造成土壤盐渍化的主要因素[24]。耕地盐渍化面积超过50%,其中30%的耕地受到严重影响[25]。
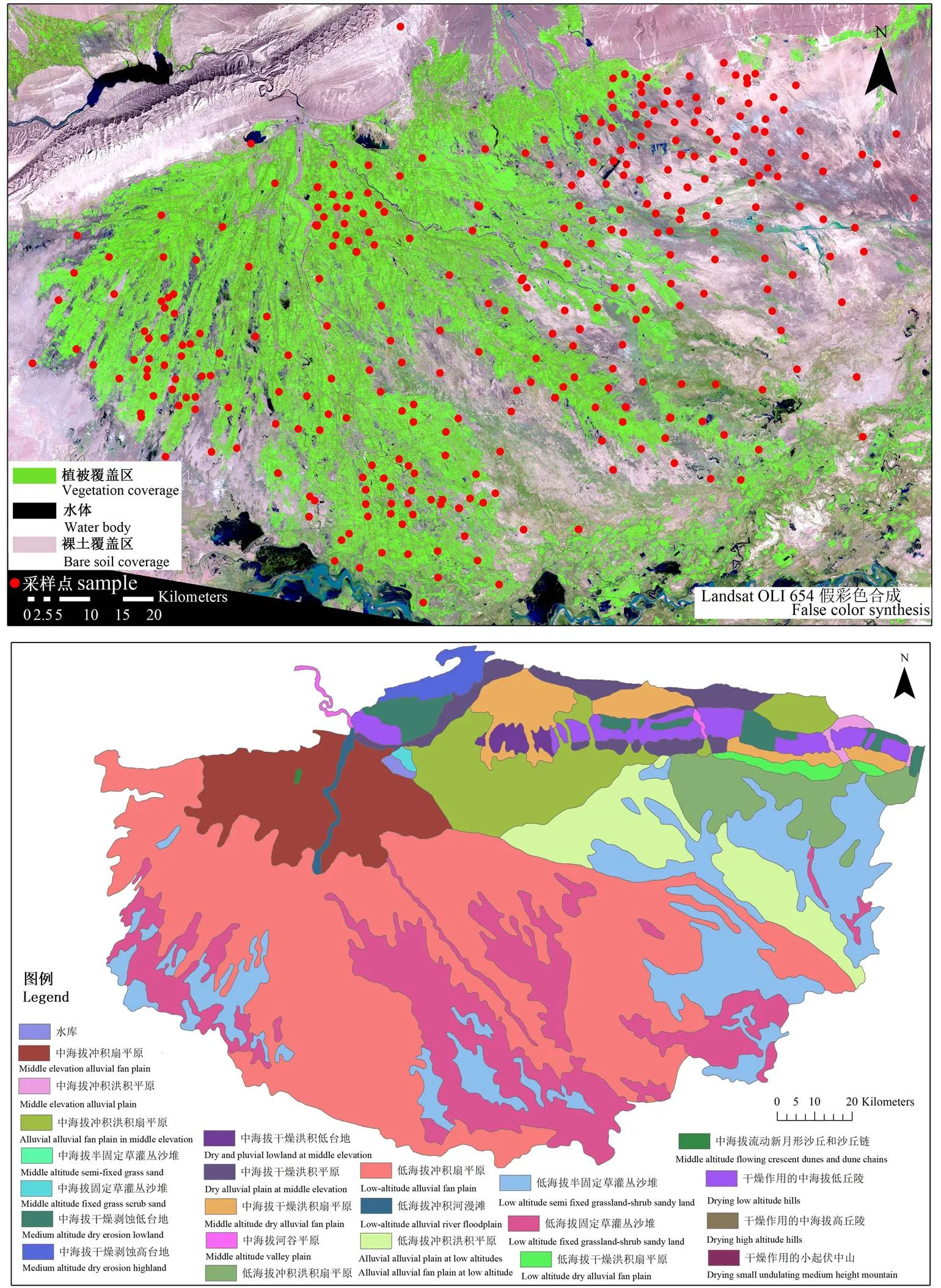
图1 渭干河-库车河流域景观地貌特征及绿洲采样点分布图
1.2 数据与方法
1.2.1 土壤样品采集与土壤盐分分析处理 为了进行土壤盐度分析和建模预测,本研究共计获得了371个样本。根据实际情况最终样点的布局采取两种不同的设计方式,采样点分布情况见图1。研究初步的样点布局是基于限制拉丁超立方体(Conditioned Latin Hypercube Method,cLHS)而设计[26]。该方法是在已确定采样数目的前提下抽取尽可能全面地覆盖由定性或定量变量构成的属性空间的样本。cLHS的程序和算法可在Minasny和McBratney(2006)文献中可以找到。然而,在实际采样中,由于各种原因(道路不通、植被过密或地形崎岖),3/5的位置未能被抵达。因此,我们随后采用了分层随机抽样的策略,样点的布局综合考虑了绿洲景观类型、水文特征、道路通达性和土壤盐渍化空间异质性、土地利用和地形等因素。数据收集时间为2016年9月9—30日。每个样点用五点梅花的方式取土,采样深度为0—10 cm,随后将测试的数据进行平均,作为本样点的实际观测值。
本研究中,土壤盐度(测定土水比1﹕5溶液电导率,EC1:5)在实验室内进行分析,参照《土壤和农业化学分析》,将土样风干后磨碎,过2 mm筛子,制备土壤溶液,比例为土水比1﹕5,温度设定为25℃,用以测定土壤样本的电导率(EC1:5)[27]。所有样点的电导率平均值作为采样点的基本值。此外,本研究区EC1:5和土壤盐分(g·kg-1)具有高度相关性(2= 0.95),所以EC1:5可用作评估研究区土壤盐分的替代参数。
1.2.2 Landsat OLI图像预处理 本研究所使用的卫星影像是Landsat OLI(145/31),获取时间为2016年9月18日。基于ENVI 5.3中的FLAASH(Fast line- of-slight Atmospheric Analysis of Spectral Hypercubes)模型纠正大气带来的影响。纠正后的反射率数据,其数值范围为0—1。该数据用于计算后续研究中使用的各类土壤或植被相关指数。
1.2.3 基于驱动和响应因子的场景设计 本研究基于驱动因子和环境响应因子,设定以下12个场景用以量化分区建模对于绿洲尺度土壤电导率预测精度的影响(图2)。将绿洲尺度的全部样本构建的模型设置为情景1。基于植被覆盖情况,将植被覆盖程度分为全覆盖(NDVI>0.22,情景2)和无植被覆盖(NDVI≤0.22,情景3)。NDVI阈值(0.22)的设定参考WU 等[5]和 SONG 等[28]的研究成果;基于土地利用:农业用地(情景4)、草地(情景5)和未利用土地(情景6);基于地貌:低海拔的冲积扇平原(情景7,LAAFP)和低海拔固定灌木(情景8,LAFGS);基于土壤电导率分级(EC)[29]:EC ≤ 4 dS·m-1(情景9),2 dS·m-1<EC<16 dS·m-1(情景10),EC>4 dS·m-1(情景11),EC>16 dS·m-1(情景12)。场景的设置同时考虑了土壤发生学和人类活动影响。此外,研究还想说明分层预测非均质地表土壤电导率的重要性。图3显示了每个场景的土地利用类型的组成。

图2 绿洲-沙漠水热和能量交换示意及情景覆盖范围(修改自LI等[10])

农田:Farm land (FL);灌木 Shrub Lang(SL);高草地:High Grass Coverage (HGC);湿地:Wetland;低草地:Low Grass Coverage (LGC);沙地:Sandy Land (SYD);居民区:Residential Area (RA);盐碱地:Salt-affected Land (SAL);中草地:Medium Grass Coverage (MGC);果园:Orchard;戈壁:Gobi;裸岩地:Bare Rock Land (BRL)
1.2.4 环境变量 基于土壤方程选择用于预测土壤电导率的环境变量:气候因子(地表温度)、生物因子(植被指数)、DEM(数字高程模型)衍生变量集(30、60、90、120、150、180、210和240 m等8个分辨率)、母质(地貌类型)、人类活动(土地利用)、土壤相关因子(波段、土壤相关指数、土壤湿度指数)。具体变量详见表1。
1.2.5 RF & SGT RF模型是基于决策树发展而来的一种集成学习方法,通过多次 bootstrap抽样获得多个随机样本,并通过这些样本分别建立相对应的决策树,从而构成随机森林。用于回归的 RF,取所有决策树预测结果的均值作为最终的预测结果[21]。RF算法主要涉及两个关键参数:一是对于每个参与模型的分支树,即模型运算中的分裂次数mtry的设定。参与预测的变量个数不同,mtry的设定也不同,需要根据实际情况调整。本文针对设置的12个情景分别定义mtry。研究根据RF模型预测过程中(63%的样本用于建模)产生的袋外误差(37% 的样本用于验证)对mtry的值再做具体的调整。每个情景的mtry值由1到30分别进行测试,取袋外误差最小的mtry值作为本情景最适宜的分裂次数。另一个是树模型运算中每次生成的树的数量,ntree,模型的计算量与 ntree的值成正比,在 ntree增加并不能显著提高模型预测能力的情况下,ntree的设定要尽可能小(一般>500),本文设定为1 000。RF模型的预测通过R语言的random forest工具包(randomForest)实现[35]。

表1 基于Landsat OLI(30 m)和DEM(8个空间分辨率)衍生的环境变量
SGT是回归树和Boosting的集成。Boosting的核心思想是:初始状态下为每个训练样本赋予一样的权重值,每次迭代训练提高错分样本的权重,降低分对样本的权重。迭代N次之后,得到N个弱分类器,最终通过权重加和的方式集合成强分类器[36]。SGT是Boosting算法框架的分支,该算法为了减少上次结果的残差,在减少残差梯度方向上不断建立新的模型,直到误差不在降低为止。该算法需要设置以下四个参数:学习速率,抽样比例,树的最大化子节点个数和每次生成的树的数量。学习速度越低,迭代次数越多,一般小于0.1,此研究中设置为0.01[36]。抽样比例为1时,每次迭代的样本集相同,小于1时,抽取的训练样本集都不同,有助于抑制过拟合,取值范围0.5—0.8[17],为了和RF进行对比,这里设置为0.63。树的最大化子节点个数需要根据实际情况设定,测试值的范围1—15,取RMSE最小的值为最佳最大化子节点个数(图6)。每次生成的树的数量设置为1000。
1.2.6 变量筛选与最佳组合的选择 研究表明通过去除潜在不相关的环境变量会提升模型的鲁棒性。原因在于筛选过程可不断降低不相关性的变量对模型精度的负向扰动,以提高预测的准确性。本研究会在以上12种情景下分别进行最佳变量组合的测试。筛选步骤主要参考SVETNIK等[37]和HEUNG等[18]的研究成果。(1)基于RF和SGT,对变量的重要性进行排序。(2)依次删除排在末尾最不重要的变量,并再进行迭代运算,验证采用5-fold交叉验证获取RMSE。根据RMSE最低值确定最佳变量组合。(3)在各个设定的情景中重复步骤1和步骤2,确定每个场景的最优变量组合。
1.2.7 情景对比方案 研究采用以下两种方法比较情景(子区)重组对绿洲尺度盐度预测的影响。方案一基于全样本构建绿洲尺度预测模型,之后将预测值依据12个情景的设定规则重新组合(Regroup Scenarios,RS)(图4-b)。另外,为了对比,如图4-a所示,在12个情景中单独建立预测模型(Independent Scenarios,IS)。将上述两种模式生成的情景验证结果进行对比。方案二则组合不同场景的预测值,即NDVI>0.22 & NDVI≤0.22,EC≤4 dS·m-1& EC>4 dS·m-1,农用地,草地&未使用的土地, LAAFP & LAFGS,然后比较上述组合方案(Combined Scenarios,CS)(图5-a)与全样本预测值根据上述组合方式形成对应组合(Reclassified Scenarios from Oasis Scale Model,RSOSM )的精度差异性(图5-b)。

图4 独立情景建模与全样本建模下预测值根据情景重分类之间的精度对比方案

图5 情景预测值的合并对于绿洲尺度土壤盐度预测影响的对比方案
1.3 模型评估
研究基于5折交叉验证(5-fold cross validation)获取各情景下最优模型并进行验证。此验证测试过程相对于简单的训练-验证比例而言需要花费更多的计算工作量,并适用于较小的数据集,结果可靠且具备无偏性[17]。训练数据集被随机分成5个子集, 即4/5 的训练数据被用于模型训练,剩下的1/5用于模型验证。每个抽样过程重复20次,取其平均值。图6和图7显示了每个情景下经过4/5训练数据获取的RF算法中mtry的最优值(黑色放框)和 SGT算法中的最大化子节点个数的最优值(黑色放框)。研究采用相关系数(2)、均方根误差(Root Mean Square Error,RMSE)和预测偏差比(Residual Predictive Deviation,RPD)作为误差评价指标。RMSE 越接近零,RPD 值越大,预测精度越高。
2 结果
2.1 土壤盐度变异性
表2显示了不同情况下土壤盐分的基本统计信息。情景1的统计分析表明, 该区土壤电导率最大值为 184.5 dS·m-1,最小为 0.14 dS·m-1,平均为 31.32 dS·m-1。根据美国盐度实验室的盐度分类标准(0—2 dS·m-1为非盐渍化;2—4 dS·m-1为轻度盐渍化;4—8 dS·m-1为中度盐渍化;8—16 dS·m-1为重度盐渍化;>16 dS·m-1为极端盐渍化),约67% 的样品(EC>4 dS·m-1)受到土壤盐渍化的影响。整体而言,不同情景的变异系数(coefficient of variation,CV)表明,该区0—10 cm土层的土壤盐度呈现中度或高度空间变异性。(CV<0.1为低变异性,0.1<CV<1.0为中度变异性,CV>1.0为高度变异性)。
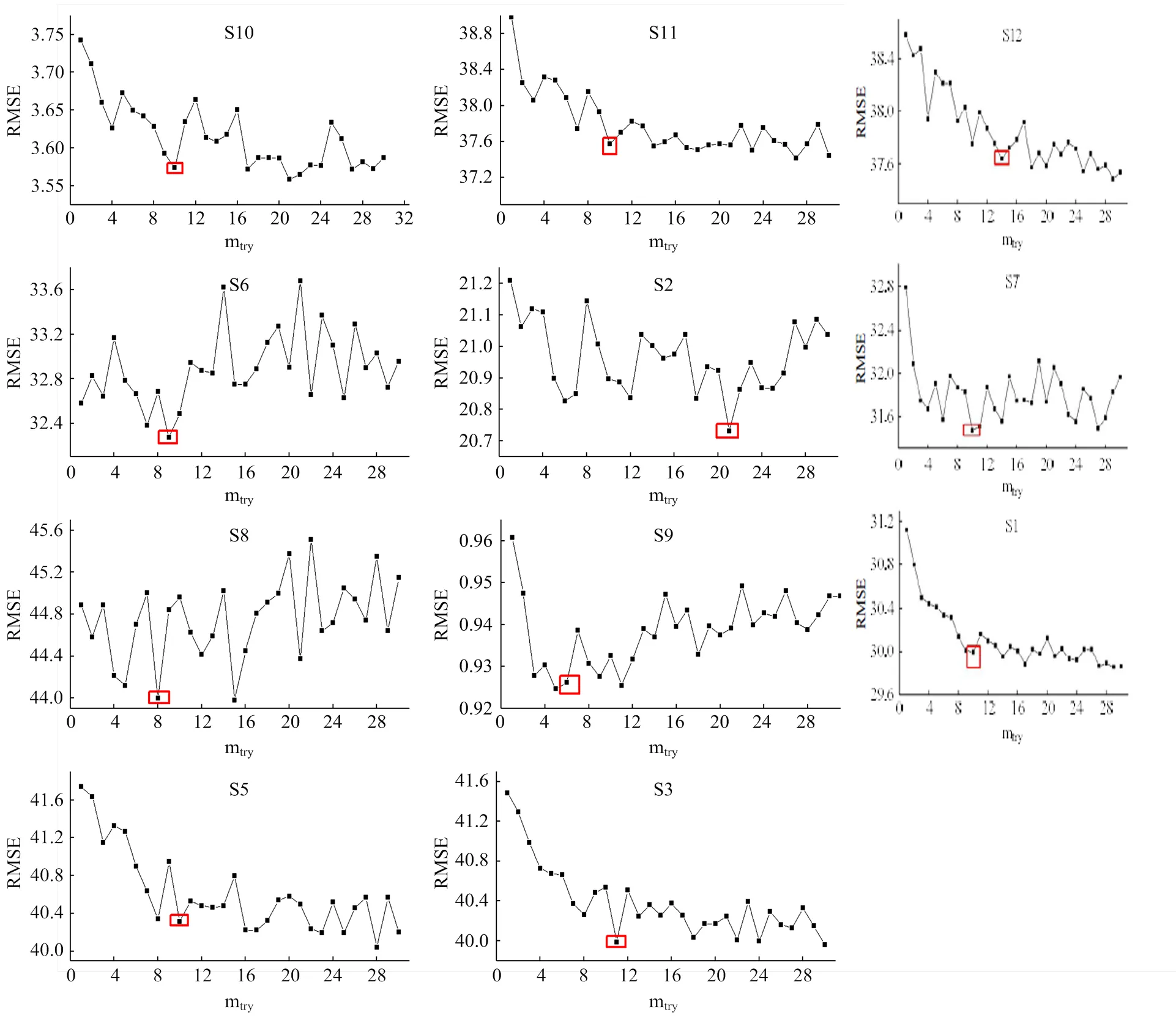
图6 不同情景RF算法中mtry的最优值

图7 不同情景下SGT算法中最大化节点(node)的最优值

表2 12个情景的土壤电导率(dS·m-1)统计特征
2.2 RF和SGT在土壤盐度预测中的表现
表3和表4分别显示了RS和IS模式下基于RF和SGT计算获取的误差水平。根据2,RMSE 和 RPD的统计结果:(1)RF和SGT在情景2、3和5中的预测水平相似。(2)70%的情景中(情景2、3、5、6、7、8、11和12),SGT的预测精度高于RF。2依次增加了6.06%、0、5.13%、23.40%、-4.00%、51.52%、18.75% 和 16.67%。RMSE依次降低了2.21%、0.005%、1.47%、11.73%、16.14%、12.49%、3.79%和3.20%。RPD值依次增加了0.44%、0、1.56%、13.67%、18.80%、13.82%、4.10%、3.33%。RF在情景9和10的预测精度高于SGT,2值提高了26.09%和34.21%。RMSE的值降低了4.82%和11.18%。RPD值增加了5.26%和12.50%。(3)所有情景的预测精度水平<0.01。表4的结果显示:(1)除了情景2,其余情景的RF和SGT的预测精度水平相似。情景2中,相对于RF,SGT的R2值增加了46.67%,RMSE降低了11.61%,RPD值增加了13.56%。(2)50%的情景显示SGT的预测精度高于RF。全样本模式下,SGT的预测精度高于RF。另外,由于农田样本的高变异性,RF和SGT都无法完成预测。
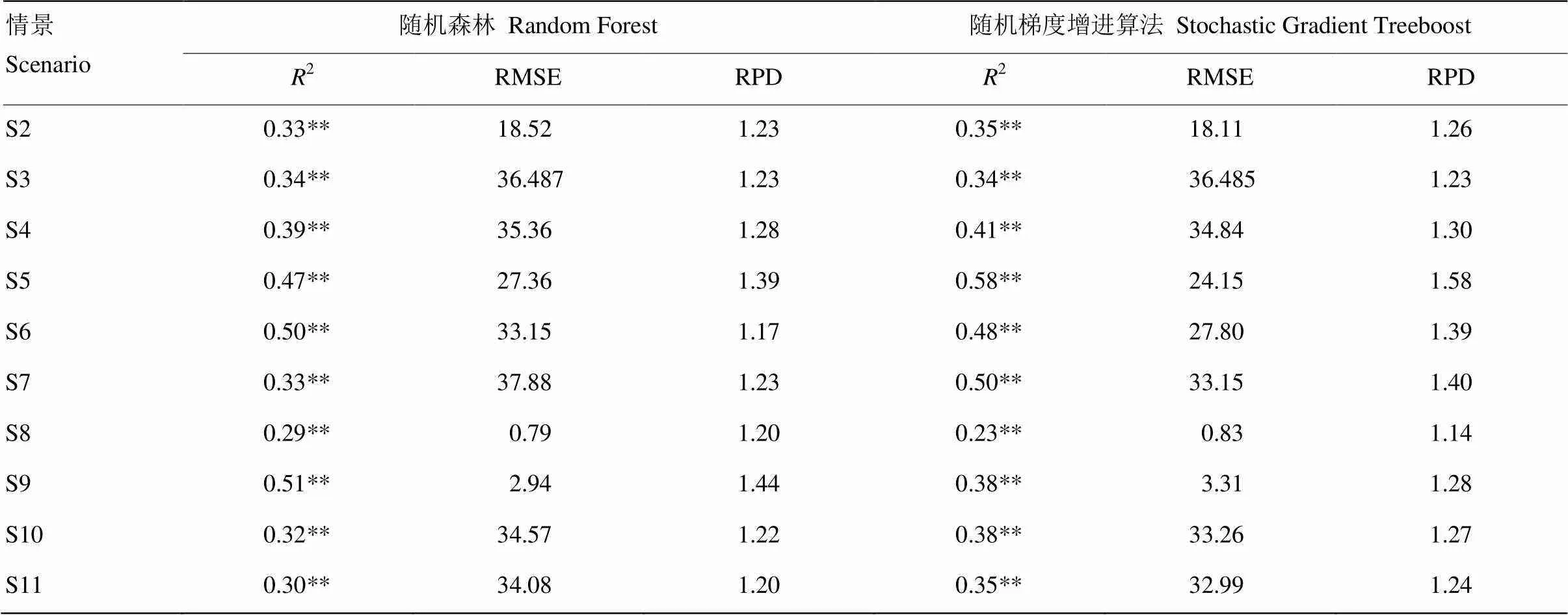
表3 独立情景下(IS模式)基于随机森林和随机增进算法的精度验证
**:<0.01

表4 RS模式基于随机森林和随机增进算法的精度验证(根据情景划定规则重分类)
ns:没有显著性No significance
表5显示了1.2.7节中方案二的对比结果。4个合并的情景显示SGT的预测精度高于RF,情景2 和情景3的RF预测精度高于SGT。相比于全样本(绿洲尺度)预测值的再分配情景(RSOSM)而言,上述情景预测值合并后,后者较前者而言,2值提升的最大值为0.08,最小提升了0.01。RMSE值降低的幅度最大值为0.08,最小值为0.01。RPD值提升的最大值为0.11,最小值为0.01。
与观测值相比,RF和SGT的预测值都存在低值区高估和高值区低估的现象,导致残差出现线性趋势(图8和图9)。上述现象出现在各情景中。被高估的值出现于有人类管理活动的绿洲内部地区(用低含盐水灌溉),而被低估的值分布于绿洲的外围(盐分来自于上游灌区),即灌溉区盐分在绿洲-荒漠交错带的聚集区,以及渭库绿洲的东北角。

表5 情景合并模式(CS模式与RSOSM模式)对土壤盐度预测的精度影响
**:<0.01
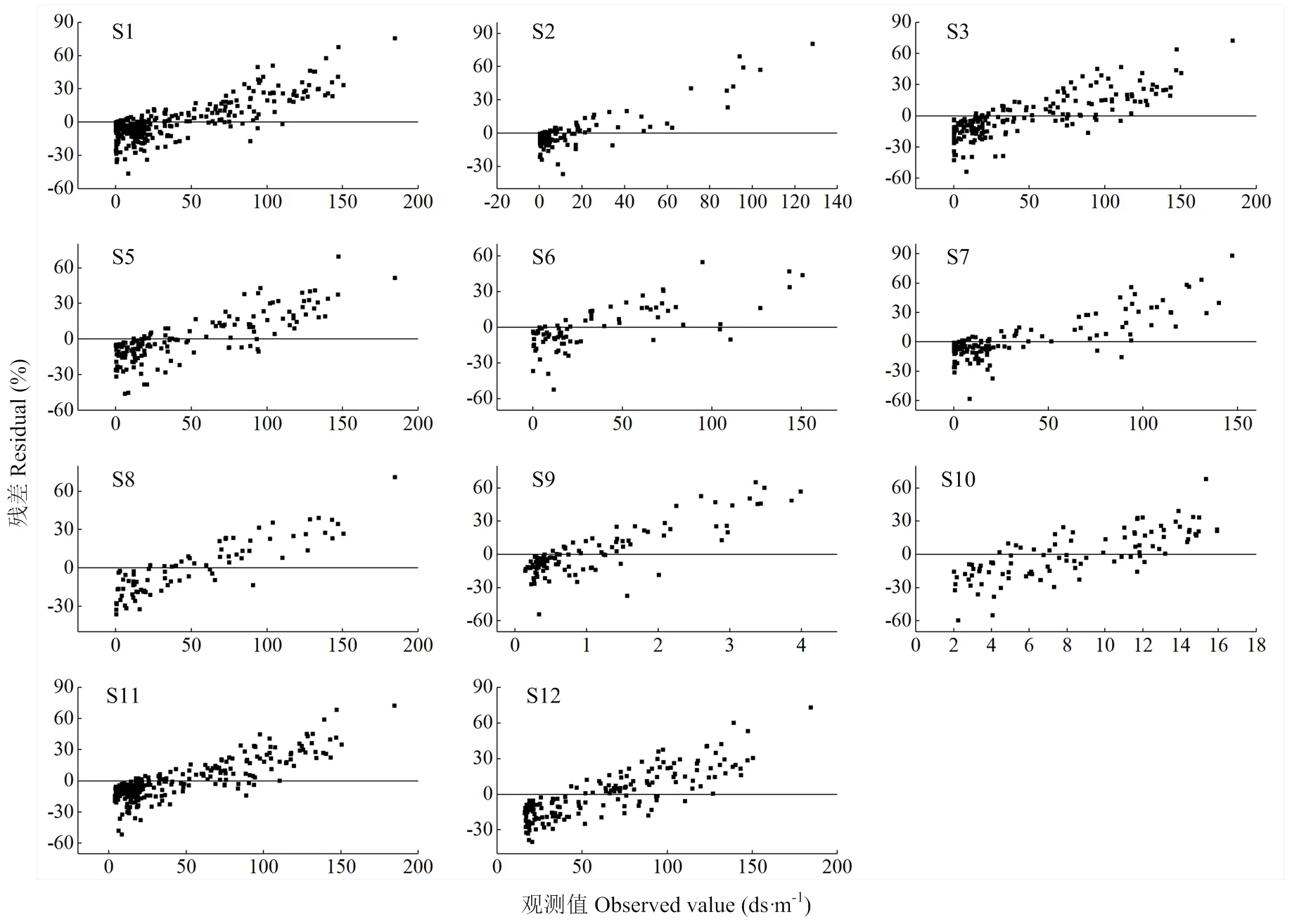
图8 不同情景下基于RF预测的残差与观测值的对比

图9 不同情景下基于SGT预测的残差与观测值的对比
2.3 情景分区建模的预测精度
表3和表4显示了1.2.7节中方案一获得的统计结果:(1)对于RF来说, 以下6个情景IS模式(表 3)的预测精确高于RS模式(表 4):情景2,5,6,9,10,12。以 RPD 值为例,上述方案的精度分别提升了4.23%、3.23%、2.21%、1900%、620% 和11.11%。其余4个情景的RS模式(表3)的预测精确高于IS模式:情景3、11、7、8。RPD 值增加了3.14%、2.4%、13.97% 和2.38%。(2)对于SGT来说,以下6个情景IS模式(表3)的预测精确高于RS模式(表4):情景5、6、8、9、10、12。RPD 值分别增加了4.84%、8.22%、2180%、540%、12.73% 和12.00%。反之,RS模式(表3)的预测精确高于IS模式的情景为:情景2、3、7。RPD 值增加5.97%、2.38% 和2.11%。
表5显示了2.2.7节中方案二中的统计结果(图5)。首先,将情景9和11的预测值合并,CS与RSOSM模式结果对比:基于SGT,2和 RPD 分别提升了14.59% 和6.47%,基于RF,分别提升了10.87% 和4.38%。其次,当情景2和3的预测值合并后,CS与RSOSM模式结果相比:基于SGT,2和 RPD 分别降低了2.17%和2.90%,基于RF,二者分别降低了2.08%和1.46%。地貌分组当中的情景7和8合并后,CS与RSOSM模式结果相比:SGT的预测结果显示,前者模式中2值上升了8.51%,RPD下降了3.62%,RF预测结果显示,2下降了 7.00%,RPD 值下降了3.03%。当草地和未用土地的预测值组合时,CS与RSOSM模式结果对比,对于SGT,前者相比后者,预测精度增加17.50%(2)和5.38%(RPD),基于RF,预测精度提高了7.50%(2)和2.32%(RPD)。
2.4 不同情景分区指示土壤盐度变化的重要变量
图10显示了10个情景模式下各自最优变量集。RF和SGT都可产生变量的贡献度,这里只显示精度相对较高的算法获取的变量及其贡献度。将变量的贡献度进行归一化处理后经对比发现,由于外部环境或者所处地理位置的影响,各情景的关键变量组有一定的差异性。同时,研究根据变量计算的数据来源,重新核算了影响盐渍化空间差异性的贡献度。结果显示,基于地形衍生的变量组(多空间分辨率)的贡献度最高,平均值为52.98%,其次为Landsat衍生变量组,平均值为36.22%,地貌类型的平均贡献度为11.29%,土地利用的平均贡献度为10.51%。对比所有情景发现,仅从变量出现的频次考虑,地表温度,EVI2,EVI,ENDVI,FSEN依次出现了7次、6次、6次、4次、4次。另外,地貌和土地利用在下列情景中的贡献度位居前列:情景1、2、3、11、12。

图10 不同情景下基于1.2.6节中介绍的方法迭代获取的重要变量
2.5 土壤盐度的空间分布特征
根据第1.2.6节的方法,获取RF和SGT两种算法迭代产生的模型,并绘制了研究区土壤盐渍化的空间分布图(图11)。图11中的a和b图显示了全样本模型的预测结果,c和d,e和f,g和h分别对应情景7和8,情景3和2,情景5和6。地貌的2个类型与土地利用中2个类型各自合并后,并不能覆盖全绿洲,合并后外围的数据则由全样本模型的预测值进行填充。整体而言,从定性层面来看,上述结果与DING等[23]与WANG等[25]结果相近。绿洲内部,灌区农业种植区的土壤盐度相对较低,由于地形地势的引导,盐分都积聚在绿洲-荒漠过渡带地区。
3 讨论
3.1 RF和SGT的精度评价
观察表3、4和5后发现,27个情景中的18个(接近70%)都显示 SGT的预测精度高于RF。此结果暗示,SGT相对更适合预测干旱区土壤盐度空间变异性。然而,上述两种算法在盐渍化研究中并无比较的先例,在此仅引用其他研究加以说明。NAGHIBI等基于SGT,CART和RF研究阿富汗地区地下水喷泉潜在分布区,结果显示,SGT的预测效果最佳,其次为CART和RF[38]。YOUSSEF等[39]基于广义线性模型(Generalized Linear Models,GLM),CART,SGT和RF评价沙特阿拉伯地区滑坡灾害危险性,AUC(Area Under the Curve ) 曲线结果显示,SGT的值最高,为0.958,其次为GLM,为0.821,CART为0.816,最后为RF,0.783。值越大代表精度越高。YANG等[40]比较SGT与RF预测青藏高原东北部高植被覆盖区土壤有机质的空间分布,结果显示,SGT的预测精度稍高于RF,二者预测的结果在空间分布上较为相似。

a和b:全样本模型;c和d是情景7和情景8合并的结果;e和f是情景2和情景3合并的结果;g和h是情景5和情景6合并的结果
基于上述两种算法的模拟值出现低值高估和高值低估的现象已出现在其他研究中[41-42]。主要的原因在于小数据集样本的代表性不足。本研究的样本设计起初是以绿洲尺度为前提而定,并不是完全基于小尺度而定。聚焦至不同情景下,样点的代表性可能有所下降,致使该模式(全样本建模)下并不是每个情景的预测精度都可以达到绿洲尺度的水平。上述现象可能无法完全避免,在于研究区土壤盐度空间变异性较强。样本的设计依据来自于环境变量,这些变量在空间分布上并不能完全与土壤属性呈高度一致性变化。对此,面对复杂的变异环境需要加入更多不同类型且更为普及的高空间分辨率传感器进行相互校正或能提高样本的代表性,以及满足大尺度制图的需求。
基于Landsat 数据建立土壤盐度模型的案例已有报道(表1)。涉及的深度包括0—10、0—20和0—30 cm,部分研究未列出深度。参与建模的样本量残次不齐。选择的变量或为单一变量或为变量组。相关性有高有低(2= 0.874,2= 0.564,2= 0.483,2= 0.78,2= 0.45,2= 0.71,2= 0.93,等)。选择的方法各有优缺点(线性、多元线性方程、神经网络、支持向量机、指数模型等)。验证模型包括设定训练样本/验证样本的比例和十字交叉验证。同时,各自的地理环境也有明显的差异性。由于上述多维信息的差异性,不能直接对比。但本研究认为所得结果进一步丰富了该领域关于环境-土壤盐渍化关系知识库。
3.2 情景分区建模对绿洲土壤盐度预测精度的影响
表3和表4中情景2、5、6、8、9、10、12,共计7个情景(占70%)的结果显示了分区建模的有效性。其中EC≤4 dS·m-1和2 dS·m-1<EC<16 dS·m-1两个情景的IS模式精度显著高于RS模式。原因可能归结于用于绿洲尺度建模的盐度变异性与上述范围的变异性相差太大,二者数据的值域范围重叠度较低。此外,低盐度区域如农田,其土壤中盐度的空间变异性与外界环境的变化同步性较其他地区并不明显,控制该区植被生长的关键变量以土壤水分为主。同时,用于测试低盐度的仪器在该区的测试精度并不稳定。因此上述结果给我们的启示在于绿洲尺度的模型并不适用于灌溉区,需要在此情景下单独建立相应的预测模型。
表5中的组合场景再次验证了样本数据分割(根据地理特征)对提高土壤盐度预测精度的重要性。场景9和场景11组合可以有效地提高预测精度,这是所有4种组合中精度提高最明显的。对表5结果的综合比较表明,当有历史土壤电导率数据时,它们是首选子区分割参考媒介。RF结果显示了场景2和3被组合在一起时提高了预测精度。这表明植被覆盖对土壤盐度预测有一定的影响。然而,由于植被类型多样,精度的提高范围有限,因为一定程度的概率表明,同为植被覆盖下有着相似NDVI值的单一或多种植被类型有着不同的土壤电导率值。利用地貌单元作为相对均匀区域的划分基础结果表明可以有效提高预测精度。这些结果的优势是分区范围相对稳定,极少随时间变化。这与与母质有关,后者与土壤盐渍化的发生和发展有间接关系[4,43]。土地利用数据的重要性(它整合了人类活动信息用以提高土壤盐度预测的准确性)排在情景9和11(参考2和RPD)的组合之后。这一发现也反映在各场景的重要变量排序中。值得注意的是,上述的基于地形和土地利用分区子区域,只覆盖了整个绿洲的两种类型,在下最终结论之前,我们还需要收集一定数量的样本进一步验证。
3.3 不确定性分析
全面分析上述结果后,未来的研究可能需要考虑以下几个方面:(1)绿洲尺度下采样点设计不仅要考虑整个研究区,还要考虑子区域,并将道路可达性和采样成本考虑在内。虽然该研究在每个子区测试了模拟结果,预测误差降低,如果在该区中收集更多代表性样本,预测的准确性将得到显著改善。(2)由于混合像元问题,现存遥感或数字档案数据与地理现象无法实现精确匹配。这个过程需要使用更高的空间分辨率数据。(3)在一定土壤盐度值范围内,植被物种多样性和土壤的复杂性加剧了不确定性。(4)当土壤中的盐含量低于15%时,响应变化不能从外界观察得到,这就增加了两种情况下的探查难度:一种是在农业作物区,另一种是深层地下水已经停止积盐。(5)遥感数据,即使经过了大气校正和地形校正,在后续流程仍有一定的错误积累。
4 结论
在本研究中模拟的27个场景中(12个原始和15个衍生),70.37%的情景证明SGT比RF有更高的预测精度。因此,相对而言,在干旱区SGT比RF更适合于预测复杂环境下土壤盐度的空间变异性。
将绿洲划分为若干子区,然后结合子区的预测值,能有效地提高绿洲尺度的预测精度。此结论特别适用于EC≤4 dS·m-1和2 dS·m-1<EC<16 dS·m-1两个情景,需要单独预测。首选分区媒介是土壤电导率(前提是数据能够反映当前土壤盐度变异性),其次是地形和土地利用。
通过对多个情景优化数据集的比较,以下变量对于指示子区或绿洲尺度的土壤盐度预测具有重要的作用:土地利用、地貌、EVI、EVI2、FSEN、TEM、ENDVI以及多种空间分辨率的地形变量。
研究建议为了达到全组分景观单元都保持较高的属性预测精度,应该在样本设计上着手,并经过反复测试找到最为合适的景观分区变量,分区媒介的选择可以从驱动或者响应变量入手。
[1] ALLBED A, KUMAR L, ALDAKHEEL Y Y. Assessing soil salinity using soil salinity and vegetation indices derived from IKONOS high-spatial resolution imageries: Applications in a date palm dominated region.2014, 230:1-8.
[2] SCUDIERO E, SKAGGS T H, CORWIN D L. Regional scale soil salinity evaluation using Landsat 7, western San Joaquin Valley, California, USA.2014(2/3): 82-90.
[3] SCUDIERO E, SKAGGS T H, CORWIN D L. Regional-scale soil salinity assessment using Landsat ETM + canopy reflectance.2015, 169: 335-343.
[4] TAGHIZADEH-MEHRJARDI R, MINASNY B, SARMADIAN F, MALONE B P. Digital mapping of soil salinity in Ardakan region, central Iran.2014, 213: 15-28.
[5] WU W, MHAIMEED A S, AL-SHAFIE W M, ZIADAT F, DHEHIBI B, NANGIA V, PAUW E D. Mapping soil salinity changes using remote sensing in Central Iraq.2014(2/3): 21-31.
[6] YAHIAOUI I, DOUAOUI A, QIANG Z, ZIANE A. Soil salinity prediction in the Lower Cheliff plain(Algeria) based on remote sensing and topographic feature analysis.2015, 7(6): 794-805.
[7] ZHANG T T, QI J G, GAO Y, OUYANG Z T, ZENG S L, ZHAO B. Detecting soil salinity with MODIS time series VI data.2015, 52: 480-489.
[8] ZHANG T-T, ZENG S-L, GAO Y, OUYANG Z-T, LI B, FANG C-M, ZHAO B. Using hyperspectral vegetation indices as a proxy to monitor soil salinity.2011, 11(6): 1552-1562.
[9] GARCíA M, OYONARTE C, VILLAGARCíA L, CONTRERAS S, DOMINGO F, PUIGDEFáBREGAS J. Monitoring land degradation risk using ASTER data: The non-evaporative fraction as an indicator of ecosystem function.2008, 112(9): 3720-3736.
[10] LI X, YANG K, ZHOU Y. Progress in the study of oasis-desert interactions.2016, 230-231:1-7. DOI: 10.1016/j.agrformet.2016.08.022
[11] GONG L, RAN Q, HE G, TIYIP T. A soil quality assessment under different land use types in Keriya river basin, Southern Xinjiang, China.2015, 146: 223-229.
[12] TUTEJA N K, BEALE G, DAWES W, VAZE J. Predicting the effects of landuse change on water and salt balance-a case study of a catchment affected by dryland salinity in NSW, Australia.2003, 283(1): 67-90.
[13] WANG Y, LI Y. Land exploitation resulting in soil salinization in a desert–oasis ecotone.2013, 100: 50-56.
[14] HENGL T, MENDES D J J, HEUVELINK G B, RUIPEREZ G M, KILIBARDA M, BLAGOTIĆ A, SHANGGUAN W, WRIGHT M N, GENG X, BAUERMARSCHALLINGER B. SoilGrids250m: Global gridded soil information based on machine learning.2017, 12(2): e0169748.
[15] SCHILLACI C, LOMBARDO L, SAIA S, FANTAPPIè M, MäRKER M, ACUTIS M. Modelling the topsoil carbon stock of agricultural lands with the Stochastic Gradient Treeboost in a semi-arid Mediterranean region.2017, 286: 35-45.
[16] HASTIE T, TIBSHIRANI R, FRIEDMAN J H, FRANKLIN J. The elements of statistical learning, second edition: data mining, inference, and prediction.2009, 27(2): 83-85.
[17] ANGILERI S E, CONOSCENTI C, HOCHSCHILD V, MäRKER M, ROTIGLIANO E, AGNESI V. Water erosion susceptibility mapping by applying Stochastic Gradient Treeboost to the Imera Meridionale River Basin (Sicily, Italy).2016, 262: 61-76.
[18] HEUNG B, BULMER C E, SCHMIDT M G. Predictive soil parent material mapping at a regional-scale: A Random Forest approach.2014, 214: 141-154.
[19] HEUNG B, HO H C, ZHANG J, KNUDBY A, BULMER C E, SCHMIDT M G. An overview and comparison of machine-learning techniques for classification purposes in digital soil mapping.2016, 265: 62-77.
[20] LIEß M, GLASER B, HUWE B. Uncertainty in the spatial prediction of soil texture: Comparison of regression tree and Random Forest models.2012, 170: 70-79.
[21] BREIMAN L. Random Forests.2001, 45(1): 5-32.
[22] FRIEDMAN J H. Stochastic Gradient Boosting.2002, 38(4): 367-378.
[23] DING J, YU D. Monitoring and evaluating spatial variability of soil salinity in dry and wet seasons in the Werigan–Kuqa Oasis, China, using remote sensing and electromagnetic induction instruments.2014, 235-236: 316-322.
[24] BENNETT S J, BARRETTLENNARD E G, COLMER T D. Salinity and waterlogging as constraints to saltland pasture production: a review.2009, 129(4): 349-360.
[25] WANG F, CHEN X, LUO G, HAN Q. Mapping of regional soil salinities in xinjiang and strategies for amelioration and management.2015, 25(3): 321-336.
[26] MINASNY B, MCBRATNEY A B. A conditioned Latin hypercube method for sampling in the presence of ancillary information2006, 32(9): 1378-1388.
[27] 鲁如坤. 土壤农业化学分析方法. 北京: 中国农业科技出版社, 1999.LU R K.Beijing: China Agricultural Science and Technology Press, 1999. (in Chinese).
[28] SONG W, MU X, RUAN G, GAO Z, LI L, YAN G. Estimating fractional vegetation cover and the vegetation index of bare soil and highly dense vegetation with a physically based method.2017, 58: 168-176.
[29] RICHARDS L A. Diagnosis and Improvement of Saline and Alkali Soils.1954, 60(3): 290.
[30] MONDAL P. Quantifying surface gradients with a 2-band Enhanced Vegetation Index (EVI2).2011, 11(3): 918-924.
[31] 陈红艳, 赵庚星, 陈敬春, 王瑞燕, 高明秀. 基于改进植被指数的黄河口区盐渍土盐分遥感反演. 农业工程学报, 2015, 31(5): 107-114.CHEN H Y, ZHAO G X, CHEN J C, WANG R Y, GAO M X. Remote sensing inversion of saline soil salinity based on modified vegetation index in estuary area of Yellow River.2015, 31(5): 107-114. (in Chinese)
[32] METTERNICHT G I, ZINCK J A. Remote sensing of soil salinity: potentials and constraints.2003, 85(1): 1-20.
[33] YU R, LIU T, XU Y, ZHU C, ZHANG Q, QU Z, LIU X, LI C. Analysis of salinization dynamics by remote sensing in Hetao Irrigation District of North China.2010, 97(12): 1952-1960.
[34] CECCATO P, GOBRON N, FLASSE S, PINTY B, TARANTOLA S. Designing a spectral index to estimate vegetation water content from remote sensing data: Part 1: Theoretical approach.2002, 82(2): 188-197.
[35] LIAW A, WIENER M. Classification and Regression by randomForest.2002(2/3): 18-22.
[36] ELITH J, LEATHWICK J R, HASTIE T. A working guide to boosted regression trees.2008, 77(4): 802-813.
[37] SVETNIK V, LIAW A, TONG C, CULBERSON J C, SHERIDAN R P, FEUSTON B P. Random Forest: A Classification and Regression Tool for Compound Classification and QSAR Modeling.2003, 43(6): 1947-1958.
[38] NAGHIBI S A, POURGHASEMI H R, DIXON B. GIS-based groundwater potential mapping using boosted regression tree, classification and regression tree, and random forest machine learning models in Iran.2016, 188(1): 44.
[39] YOUSSEF A M, POURGHASEMI H R, POURTAGHI Z S, AL-KATHEERI M M. Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at Wadi Tayyah Basin, Asir Region, Saudi Arabia.2016, 13(5): 839-856.
[40] YANG R M, ZHANG G L, LIU F, LU Y Y, YANG F, YANG F, YANG M, ZHAO Y G, LI D C. Comparison of boosted regression tree and random forest models for mapping topsoil organic carbon concentration in an alpine ecosystem.2016, 60: 870-878.
[41] BLANCO C M G, GOMEZ V M B, CRESPO P, LIEß M. Spatial prediction of soil water retention in a Páramo landscape: Methodological insight into machine learning using random forest.2018, 316: 100-114.
[42] MULDER V L, LACOSTE M, RICHER-DE-FORGES A C, MARTIN M P, ARROUAYS D. National versus global modelling the 3D distribution of soil organic carbon in mainland France.2016, 263:16-34.
[43] 王玉刚, 李彦, 肖笃宁. 土地利用对天山北麓土壤盐渍化的影响. 水土保持学报, 2009, 23(5): 179-183.WANG Y G, LI Y, XIAO D N. Effects of land use type on soil salinization at Northern Slope of Tianshan Mountain.2009, 23(5): 179-183. (in Chinese)
Influence of Sub-Region Priority Modeling Constructed by Random Forest and Stochastic Gradient Treeboost on the Accuracy of Soil Salinity Prediction in Oasis Scale
WANG Fei1,2,3, YANG ShengTian2, WEI Yang2, YANG XiaoDong2,3, DING JianLi1,2,3
(1Xinjiang Common University Key Laboratory of Smart City and Environmental Stimulation, Xinjiang University, Urumqi 830046;2College of Resource and Environmental Sciences, Xinjiang University, Urumqi 830046;3Laboratory for Oasis Ecosystem, Ministry of Education, Urumqi 830046)
【Objective】This study attempts to improve the prediction accuracy of soil salinity in arid oasis by building models preferentially in the sub-area of oasis. At the same time, the difference and uncertainty of accuracy between global model and sub-region model are quantified. 【Method】Therefore, to investigate the above differences, this study used two machine learning methods (Random Forest, RF and Stochastic Gradient Treeboost, SGT) to quantify the above effects and to prove the necessity of the building model in the sub-region compared with the full-sample model with respect to the simulation precision under the complex background of an arid region. Twenty-seven environmental scenarios (twelve original and fifteen derivatives) were designed based on the driving factors (land use and landform) and response factors (Normalized Difference Vegetation Index, NDVI and electrical conductivity, EC), which reflected variety of variabilities in soil salinity. After analyzing the results, the following preliminary conclusions were drawn. 【Result】The simulation results from 70.37% (19/27) of the scenarios showed that the predicted value of soil salinity from SGT was closer to the observed value from RF. Ten original sub-regions were modeled individually and compared with the full-sample model under the oasis scale (according to the 10 partition rules to reclassify the simulated values), and the result showed that the prediction accuracy of the former 70% scenario was higher than that of the latter. In particular, the regions of EC≤4 dS·m-1and 2 ddS·m-1<EC<16 dS·m-1should be modeled separately to predict the spatial variability of regional salinity. By combining the predictions of sub-regions and comparing them with the predicted values of the full-sample model, the former (all four different combination modes) showed a higher prediction accuracy than the latter. In addition, this result also indicated that the preferred medium for partitioning the sub-regions was soil electrical conductivity, followed by landform and land use. 【Conclusion】 The study proposes to establish a soil salinity model based on SGT preferentially on different landscape scales within the oasis, and then combine the predicted values of each landscape scale to improve the prediction accuracy of oasis soil salinity.
soil salinity; machine learning; arid regions; Landsat OLI; spatial heterogeneity; Random Forest; Stochastic Gradient Treeboost
2018-05-14;
2018-07-20
国家自然科学基金(U1603241、41661046、41771470、41261090、U1303381)、新疆大学博士研究基金(BS150246)
王飞,E-mail:volitation610@163.com。
丁建丽,E-mail:dingjianlixjdx@126.com
10.3864/j.issn.0578-1752.2018.24.007
(责任编辑 李云霞)
猜你喜欢
农业知识(2022年9期)2022-10-13 08:25:58
资源信息与工程(2021年5期)2022-01-15 05:37:50
今日农业(2021年15期)2021-10-14 08:20:36
矿产勘查(2020年11期)2020-12-25 02:56:14
学生天地(2020年19期)2020-06-01 02:11:36
水土保持研究(2016年1期)2016-10-26 03:45:52
广东海洋大学学报(2015年3期)2015-12-22 10:05:30
湿地科学与管理(2015年3期)2015-12-07 09:58:15
华南农业大学学报(2015年5期)2015-12-04 03:04:38
中国火炬(2015年7期)2015-07-31 17:40:00
