
基于CPU-GPU的多尺度视网膜增强算法
2018-12-22 08:04张卫东杜师帅路皓翔杨辉华
计算机工程与设计 2018年12期
张卫东,杜师帅,路皓翔,卓 永,杨辉华,+
(1.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004;2.北京邮电大学 自动化学院,北京 100876)
0 引 言
图像增强技术在图像处理领域受到广泛的关注,可以有效地提高图片的显像效果,如抑噪、改善清晰度等,并且成功地应用于多个领域[1,2]。其中带色彩恢复的多尺度视网膜增强算法是一种被广泛应用的图像增强算法[3,4]。
Land提出基于颜色恒常性的成像模型即Retinex理论。Retinex是由视网膜和皮层两个词合成[5]。在人类视觉的基础之上,Shi[6]对Retinex进行了改进,并且提出了带彩色的多尺度Retinex增强算法。该方法[7]不仅改进了单尺度算法中针对细节增强较弱的缺陷,还提高了多尺度算法的增强效果。针对初始Retinex算法随机选择路径时参数设置困难的缺点,以中心环绕为基础的改进算法得到了发展[8]。随着图像增强技术的不断发展,Yang等[9]指出了以中心环绕为基础的增强算法,可能存在过度增强和色彩失真的缺陷,结合人眼的视觉特点提出了一种基于保持色的彩图像增强算法。在随后的研究中,针对要处理不同的特定图像,研究者分别提出了结合双边滤波器的Retinex算法、结合伽柏变换的Retinex算法、结合IIR低通滤波的Retinex算法、结合引导滤波的Retinex算法。Petro等提出对亮度线性操作使得Retinex算法具有更好的色彩保持等等[10]。这些改进模型或者参数的提出,极大地丰富了Retinex理论。
尽管一系列的Retinex算法针对多种场景下图像处理获得令人满意的效果,但是仍然存在一些问题,如复杂的计算过程和过大的计算量使得对图像处理实时性效果较差。在图像增强领域,虽然有关于GPU[11]加速的报道,但是它们没有考虑到CPU资源的充分利用。本文考虑到通过3个CPU线程实现RGB三通道的并行,每个通道的增强过程通过GPU并行。在保证图像增强质量的情况下,不仅充分利用CPU和GPU各自的优势,还提高了算法的执行效率。
1 MSRCR图像增强算法原理介绍
Retinex的基本思想是反射光的强度不是物体的色彩的决定性因素,是毫不影响的。而是由物体对长中短波的光线反射能力决定的,即保留反映物体本质的反射属性,去掉照射光对原始图像的影响。一幅图像根据Retinex思想可以有如下的定义方式
S(x,y)=L(x,y)·R(x,y)
(1)
其中,S(x,y)表示现实中人观赏到的或者其它成像设备生成的图像;L(x,y)表示入射光,它决定图像中的像素能达到的动态范围;R(x,y)表示反射图像。
对式(1)两边取对数,将其转换到对数域
log(S(x,y))=log(L(x,y))+log(R(x,y))
(2)
由式(2)可得R(x,y),即
log(R(x,y))=log(S(x,y))-log(L(x,y))
(3)
入射光分量L(x,y)可以通过用高斯滤波方法从原始图像S(x,y)中估计出
L(x,y)=S(x,y)*G(x,y)
(4)
其中,*表示卷积运算,G(x,y)如下所示

(5)
其中:σ是高斯函数的标准差也称为尺度常量,λ是归一化常量,使得∬G(x,y)dxdy=1。
所以由式(3)~式(5)得
log(Ri(x,y))=log(Si(x,y))-log(Si(x,y)*G(x,y))
(6)
其中,i代表图像的某个通道,式(6)其实就是算法SSR的公式,为了弥补SSR的不足,MSR算法把多个不同尺度的色彩通道进行线性加权来改善增强效果

(7)
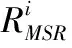
MSRCR算法在MSR基础上引入色彩恢复因子C,可以克服MSR增强后的图像色彩失真问题,C公式如下

(8)
其中,β为增益常数,α为受控制的非线性增强系数。所以MSRCR可以表示为

(9)
上述MSRCR方法中引入了色彩恢复因子,使得增强后的图像有较好的色彩保真性,但是利用以上公式得到的最终RGB的值会出现任意大小的值,为了将像素的值转化到[0,255]的范围,Moore等提出用三色带的最大值和最小值来调整每个像素点的值,如式(10)所示

(10)
Jobson则发现利用Retinex算法处理后的图像不论被处理的图像是什么类型,得到的直方图轮廓基本不变,因此,为了在log域和显示间的变化利用了一种附件常量参数的线性变换方式,称为“gain/offset”,如式(11)所示
RMSRCRi(x,y)=a[RMSRCRi(x,y)-b]
(11)
其中,a是gain,又称为增益系数;b是offset,又称为偏移量控制参数。
通过对GIMP中图像增强代码的研究,在调节色彩偏差的过程中使用了均值和均方差来得出通道上最大值和最小值,如式(12)和式(13)所示,同时引入了一个动态的参数D,使得在提高色彩保真度的同时对各种场景图像具有更好的自适应性,所以改进后的MSRCR可以定义如式(14)所示
Min=mean-D·var
(12)
Max=mean+D·var
(13)

(14)
2 基于CUDA的MSRCR图像增强算法并行设计
2.1 MSRCR算法并行性分析
在对基于CPU的MSRCR图像增强算法的并行分析,分为高斯滤波、对数域的计算、像素值的线性映射(包括计算最大值和最小值)等步骤。其中高斯滤波和对数域计算是最耗时的两步,两个步骤的耗时占了算法整体耗时的90%左右。通过分析这两个步骤可以细粒度的并行的运行在以SIMT为基础架构的GPU上,在均值和方差的计算以及像素值范围调整的步骤中,涉及到求和、乘除、分支判断等运算,将该步骤也利用CUDA核函数实现在GPU上的并行运行。将以上3个步骤分别设计为3个GPU核函数。这3个GPU核函数在使用时用到的CUDA存储体系中存储器是不相同的,需要根据不同核函数的计算特点选用不用存储器,以充分利用GPU的硬件资源,提高算法的执行效率。并且每个核函数在处理每个颜色通道数值时,将中间处理的数据存放在全局存储器中供另外的核函数调用,减少CPU和GPU间的通信。每个GPU核函数中用到CUDA存储器见表1。

表1 GPU核函数在运行时用到的存储器种类
2.2 MSRCR图像增强算法的并行设计
针对MSRCR算法的计算特点,可分为4个主要的计算任务,CPU线程处理函数和GPU核函数。其中,CPU线程处理函数用于并行R、G、B通道,GPU核函数用于并行MSRCR算法。重点在于GPU核函数的并行设计,GPU线程函数分别为高斯滤波核函数kernel_Conv、对数域计算核函数kernel_Log、像素值线性映射核函数kernel_Dyna(其中,均值核函数Kernel_Mean和标准差核函数Kernel_Std是Kernel_Dyna的输入)。详细的建模流程如图1所示,首先载入图像获取RGB、GPU等信息,然后在CPU中开启3个CPU线程分别对应R、G、B通道,之后分配GPU内存并且将数据拷贝到GPU内存中,通过GPU核函数完成MSRCR算法的并行过程,最后输出处理结果。

图1 并行模型GPU核函数的设计与实现
2.3 GPU核函数的设计与实现
2.3.1 高斯滤波核函数
本文中的高斯滤波采用的是离散化的滑动窗口做卷积计算来实现的。在二维的卷积计算中,如果计算卷积P[m][n],需要高斯模板M[][]和待卷积的矩阵N1×N2中以[m][n]为中心的与M矩阵大小相同的二维子矩阵这些数据。在做卷积计算时,需要将M矩阵和待卷积矩阵中对应的子矩阵的数据相乘再累加即可得到结果,图2给出一个卷积计算的示意图。
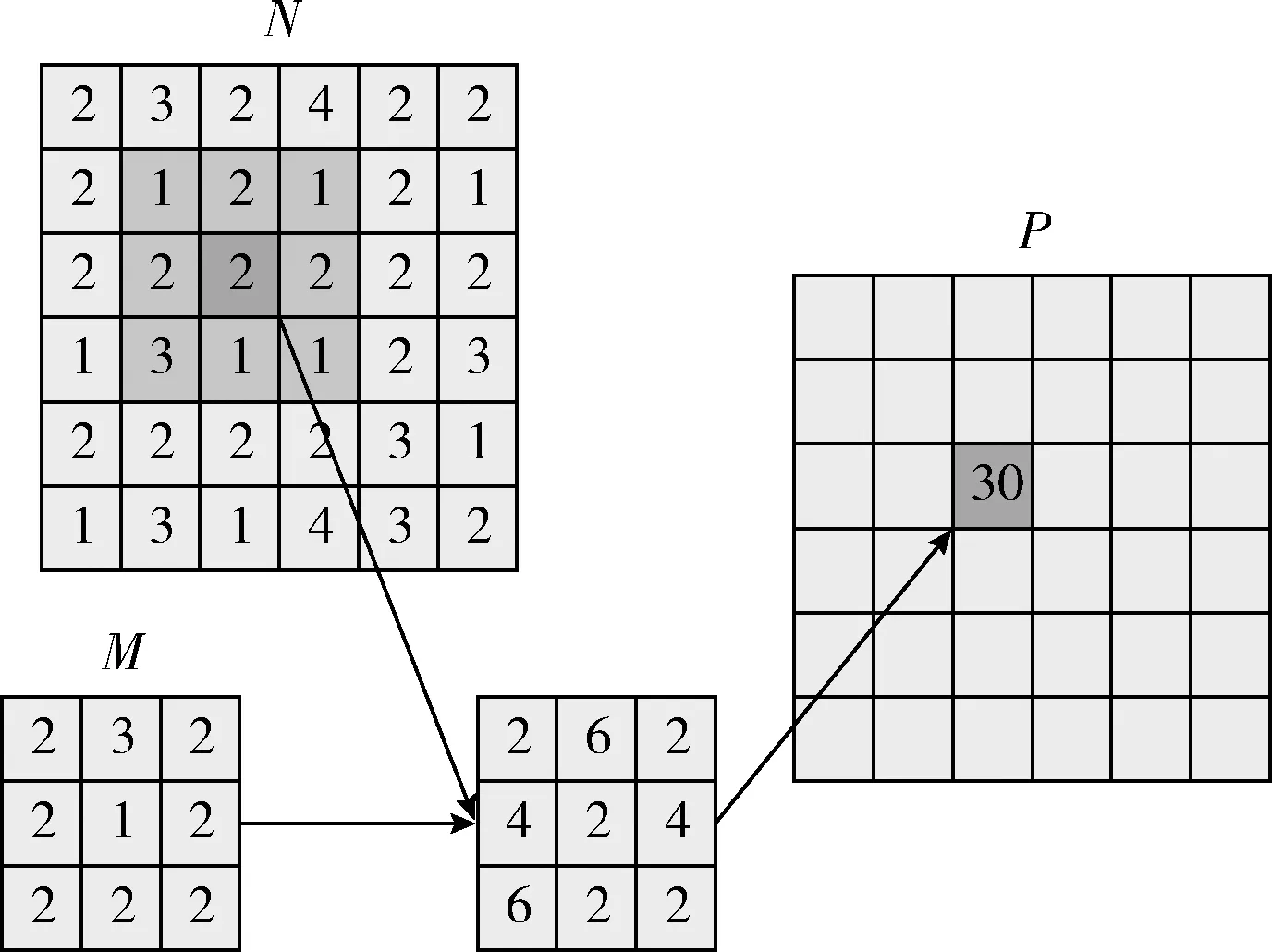
图2 二维卷积计算
通过对二维卷积的计算过程分析发现,在整个计算过程中有大量乘法和累加计算,并且数据是离散且独立的。但在边界处理时,需要判断该数据是属于边界还是非边界,其中涉及大量的判断分支指令。根据GPU的并行运行特点,在处理含有大量分支结构的程序时,会造成大量的线程空闲,只有少部分线程参与计算,造成计算资源浪费,严重影响程序的执行效率。在对卷积计算的并行化的研究中,有的研究者提出使用可分离滤波器来将二维卷积转换为两次一维卷积来实现并行化取得了良好的加速效果,是在计算过程中仍然有分支结构的存在,影响计算效率。本文采用一种新的方式将卷积计算过程并行化,彻底消除在卷积计算的过程中处理分支判断的结构,并且在计算过程中除了使用纹理存储器,还使用了常量存储器和共享存储器以优化并行程序的读写效率,充分发挥GPU的并行性能。为了可以将卷积计算过程改成完全适合GPU的架构特点以并行化运行以及充分使用GPU的各种具有各自优势的存储器。首先将待计算的矩阵行和列各补L/2行和L/2列的0,L为高斯模板的高度,如图3所示。

图3 待卷积矩阵扩展补0
将待卷积计算的矩阵补0扩展后,把在整个卷积计算过程中数据不会变化的高斯模板数据存入常量存储器。而在计算过程中待卷积的矩阵数据会多次重复用到,而共享存储器具有高出全局存储器一个数量级的读写速度。因此,将预先存入纹理存储器或者全局中的数据先读入到共享存储器中再参与计算,共享存储数据的加载过程是卷积计算并行化中的难点之一。如果在加载数据时没有有效组织线程以及没有注意同步问题,容易造成数据加载错误,得到意想不到的计算结果。共享数据的加载过程如图4所示。

图4 共享存储器数据加载
将数据加载共享内存时,其中每个线程块中共享存储器大小的设置为(block_width+m-1)×(block_width+m-1),其中block_width为线程块的宽度,m为高斯模板的宽度。
2.3.2 对数域计算核函数
该核函数主要用来对数域上的线性加权计算。(t_n,t_n)、((w+t_n-1)/t_n,(h+t_n-1)/t_n)分别设计为block和grid中线程和线程块的数量,其中h、w分别为读入图像的高度和宽度,t_n为线程块在一个维度上包含的线程数量。当t_n取值为16时,则每个线程块中线程数量为256。式(7)中的计算主要是对数值的相减以及求差结果带权值的相加,参与计算的数值之间是互相独立完全符合GPU线程并行的特点。将每个数据块中数据映射到每个线程上,则一个数据块被映射到一个线程块上,在启动GPU核函数时,流处理器就会调入若干个线程块并行执行。
2.3.3 线性映射计算的核函数
在对每一个颜色通道处理的最后,由kernel_Dyna核函数实现色彩调整以及最后像素值范围的调整等计算任务。在式(14)中调整图像色彩时需要先计算该通道上全部像素的均值和方差,在计算均值和方差时都需要执行累加和的指令。对大规模数据加和时,使用并行规约求和方法可以大大降低执行时间。因此,基于GPU的并行规约求和在核函数中扮演了重要的角色。在式(14)计算完成后,需要对求得的计算结果过滤,也就是判断像素值是否溢出,即如果大于255取255,如果小于0,则取0。最终的处理结果由GPU传送到CPU,并且在CPU上面将R、G、B通道上的数据合并。该GPU核函数的执行步骤如下:①按线程索引号从存储全局内存中加载数据。②通过并行规约的当时得到累加和,得到均值和方差的计算结果。③按照式(14),将每个数据映射到一个线程上,同时启动所有的线程进行线性映射计算。④对第③步求得的结果作溢出判断后,CPU把结果取回。
3 实验结果
3.1 实验数据与环境
实验环境为:操作系统为WIN10,64位,处理器为Intel Core i7-6700,内存大小为16 G,显卡GTX730,编程平台为VS2015,图像处理库Opencv2.49,以及GPU并行库CUDA8.0。本次实验中,我们选择5种场景下不同比例大小的图像进行了速度的测试,并且与相应的CPU-MSRCR和GPU-MSRCR算法的执行速度进行了对比,其中所有的图像均来自于网络以及NASA官网。
3.2 实验平台搭建
本实验是基于Windows平台进行设计,其中平台环境的搭建是实验成功的关键,本平台的搭建主要分为3个步骤:①首先安装VS2015,该软件来源于微软官网。②然后安装CUDA8.0,该库来源于英伟达官网。安装之后需要在系统的环境变量中添加CUDA8.0对应的库。③最后安装Opencv2.49,该库来源于Opencv官网。该库直接解压,解压之后放在D盘的根目录,然后在系统环境变量中添加Opencv对应的库。
3.3 实验步骤设计
本实验的设计主要分为CPU并行、GPU并行以及CPU-GPU并行。其中,CPU并行是基于MATLAB设计的,GPU和CPU-GPU并行是基于VS2015设计的。3种并行设计都遵循图像的读入、图像的增强以及图像的合并。其中重点在于图像的增强过程的并行设计,具体的并行步骤如下:①高斯滤波计算的并行设计。②对数域计算的并行设计。③均在计算的并行设计。④标准差计算的并行设计。⑤线性映射计算的并行设计。
其中在CPU-GPU并行设计时,需要在CPU内存中创建3个CPU线程同时并行R、G、B通道。
3.4 实验结果与分析
为了方便展示算法并行后对图像的增强效果以及对GPU加速效果的分析,在实验中采用了5类图像作为实验对象且将同一类的图像处理为相同大小,分别为夜间场景图像,大小为256×191;水下场景图像,大小为512×426;医疗诊断图像,大小为1024×750;雾霾场景图像,大小为2048×1445;月球表面探测图像,3052×4096。这5类图像的大小是在不断增加的,如图5所示,其中上面5幅为原始图像,下面5幅为GPU并行增强处理后的效果图。

图5 GPU并行增强处理效果
在实验中5组图像的大小各不相同,并行后的MSRCR计算在CPU和GPU上面的运行时间,图像处理的耗时统计见表2。
表2中给出了在实验中5类图像在CPU-MSRCR、GPU-MSRCR和CPU-GPU-MSRCR上面的耗时,在GPU上分别统计了GPU-MSRCR模型和CPU-GPU-MSRCR模型的耗时情况,折线图可以更清晰表示在CPU-MSRCR、GPU-MSRCR和CPU-GPU-MSRCR的耗时对比,如图6所示。

表2 不同分辨率图像总耗时统计/ms
其中左图原始走势,右图是缩小10倍的走势,随着图像的不断增加,CPU-MSRCR耗时急剧增高;GPU-MSRCR耗时区线小幅度增高;CPU-GPU-MSRCR耗时区线的变化不是太明显。以上结果表明GPU并行MSRCR可以显著提高算法的执行速度,并且充分利用CPU线程的并行思想不仅可以提供GPU的并行速度,还能提高CPU和GPU资源的利用率。可以看出采用CPU-GPU的并行设计的处理能力优于GPU的并行设计处理能力。为了更好的量化GPU对CPU对程序执行速度有着巨大的优势,在图7中给出了CPU和GPU的加速比。
利用在GPU上执行的总时间来衡量加速比,但这个总时间是不包含CPU与GPU的数据传输时所花费的时间。如图7所示:对于GPU-MSRCR算法,当图像大小小于1124*750时,加速度稳定在一个范围内并且幅度不大,随着图像大小的增大加速比有明显的提高,当图像大小达到3052*4096时,加速比最高达到72.2。在GPU-MSRCR基础上,本文对该方法进行了改进,考虑到图像本身具有3个通道,并且GPU-MSRCR是顺序执行R、G、B通道的GPU并行过程,而多CPU线程可以并行执行R、G、B通道的GPU并行过程。理论上采用CPU-GPU-MSRCR的处理速度是GPU-MSRCR的3倍,而实际结果取决于并行R、G、B通道时运行时间最长的通道。当图像大小是256*191的时加速比为30多倍,随着图像的增加,加速比的效果逐渐明显,当图片大小为3052*4096时加速比达到267倍左右。实现结果表明CPU-GPU-MSRCR具有较好的提速能力。
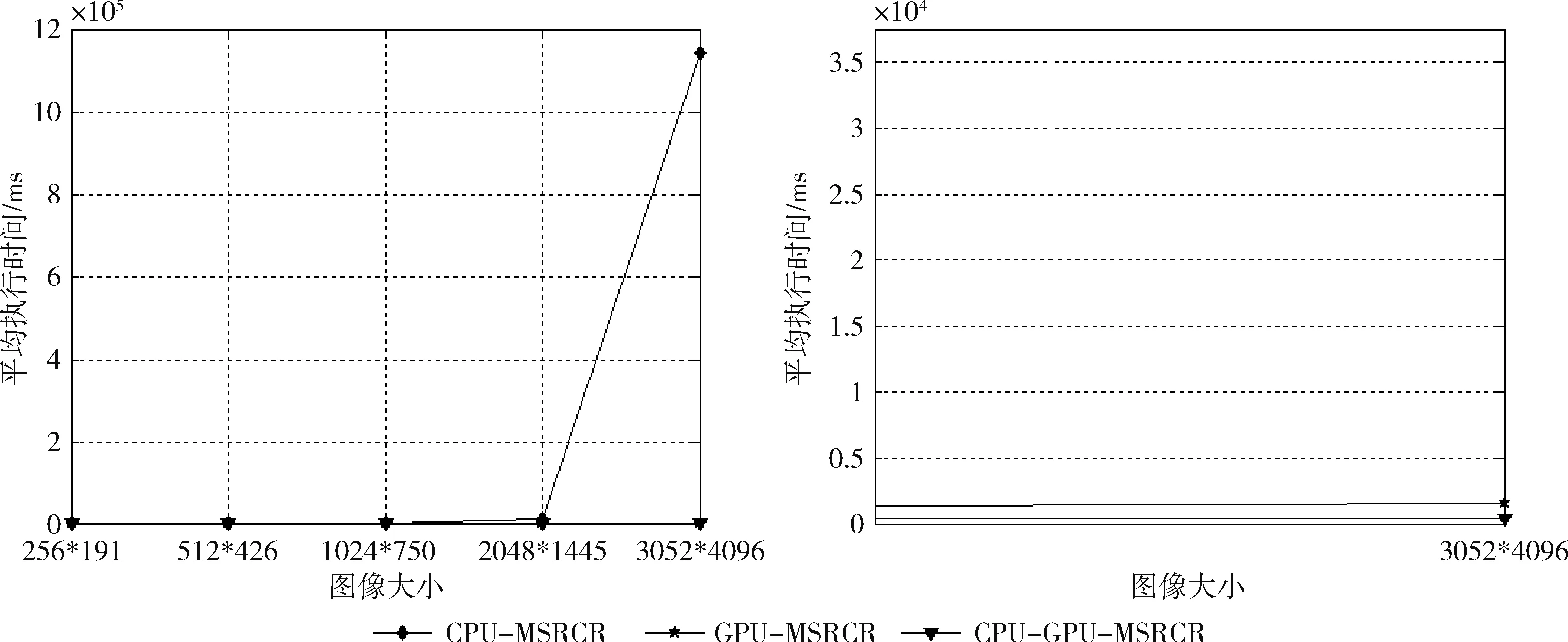
图6 CPU-MSRCR、GPU-MSRCR和CPU-GPU-MSRCR耗时对比
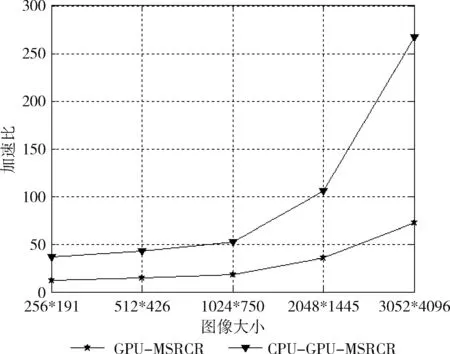
图7 5组图片对应的并行模型的加速比
4 结束语
多尺度视网膜图像增强算法可以对光照不均匀、雾霾天气、水下等场景下图像处理获得较好的显像效果,但是由于其复杂的计算过程以及较大的计算量,导致算法的实时性效果较差。本文提出了一种结合CPU和GPU并行MSRCR的加速数据并行计算的并行化方案。通过CPU并行R、G、B通道,并且每个通道的MSRCR过程在GPU资源中并行。该方案在保证图片质量的情况下,不仅提高了算法的执行效率,还提高了CPU和GPU的资源利用率。
猜你喜欢
燃气涡轮试验与研究(2021年6期)2021-08-01
山西电子技术(2021年3期)2021-06-28
海洋信息技术与应用(2020年4期)2021-01-18
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
中国生物医学工程学报(2019年5期)2019-07-16
北京航空航天大学学报(2017年3期)2017-11-23
电影故事(2015年16期)2015-07-14
