
面向大数据挖掘的Hadoop框架K均值聚类算法
2018-12-22 08:04陈瑞瑞
计算机工程与设计 2018年12期
李 爽,陈瑞瑞,林 楠
(1.郑州工业应用技术学院 信息工程学院,河南 郑州 451199;2.郑州大学 软件与应用科技学院,河南 郑州 451199)
0 引 言
采用聚类等无监督方法挖掘大数据中的隐藏模式是数据挖掘的有效手段之一,在数据建模和数据预处理等任务中应用广泛[1]。聚类是一种无监督的学习方法,用于将数据划分成不同的簇,各个簇中的数据彼此相似,而不同簇中数据具有明显差异。当数据没有标记的情况下,采用聚类算法进行数据挖掘,可以构建独立的数据模型或为其它数据建模和分析奠定基础,广泛应用于社会网络、生物信息学和图像处理等众多研究领域[2,3]。K均值聚类算法是目前应用最为广泛的聚类算法之一,该算法采用划分的思想,使用均方误差最小准则将数据划分到不同的簇。其优点是聚类过程不需要监督,简单快捷,对于服从正态分布的数据能够达到较好的聚类效果。但在面向大数据挖掘应用时,K均值聚类算法的运算效率难以满足要求[4-6]。尽管目前也提出了许多改进的K均值聚类算法[7-9],如文献[9]针对经典K均值聚类算法随机选择的初始聚类中心可能不合理的问题,提出了一种改进的K均值聚类算法,结合底层数据结构的相关性改进初始聚类中心的选择策略,提高聚类的收敛速度,进而提高聚类效率。但是在大数据挖掘应用时,聚类效率仍然很低。本文结合大数据挖掘应用中常使用的Hadoop框架,设计一种Hadoop框架K均值聚类算法,采用分布式并行处理方式加速聚类过程。针对Hadoop框架的Map阶段和Reduce阶段的不同分工,对K均值算法进行修改,分别提出了权重K均值聚类算法和加权融合K均值聚类算法,在保持聚类准确率的前提下大幅提升大数据聚类时K均值聚类算法的运算效率。
1 本文算法
在大数据挖掘应用中使用K均值聚类算法进行数据聚类的计算成本很高。为了降低计算成本,本文提出一种面向大数据挖掘的Hadoop框架K均值聚类算法,目标是设计一种快速、精确的大数据聚类算法。下面首先介绍Hadoop框架和MapReduce模型,然后介绍经典的K均值聚类算法,最后详细介绍本文提出的Hadoop框架K均值聚类算法(为了便于描述,简记为HKM聚类算法)。
1.1 MapReduce模型和Hadoop框架
Hadoop是在大数据挖掘领域广泛使用的分布式处理框架之一,该框架使用的是MapReduce编程模型。在这个框架下,首先对数据集进行初始化,然后采用两个步骤来解决数据分析处理问题。首先,通过Hadoop分布式文件系统(hadoop distributed file system,HDFS)将大数据划分为多个数据块。在各个数据块上执行Map任务,并将结果发送到Reduce任务。Reduce任务对结果进行融合,并将融合后的最终结果写入HDFS。在一些MapReduce算法中,可以迭代地执行这些步骤。Hadoop框架可以应用于具有大量数据的分布式系统上。此外,该框架的容错能力很强,是大数据挖掘常用的数据处理框架之一[10]。本文采用Hadoop框架改进K均值聚类算法,解决经典K均值聚类算法在大数据挖掘应用中处理效率低的问题。
1.2 K均值聚类算法
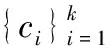

(1)
其中
(2)
其中,Si表示集合Si中样本的数量。
一般地,K均值聚类算法通常采用迭代策略求解目标函数的局部最优解。具体实现算法见表1。
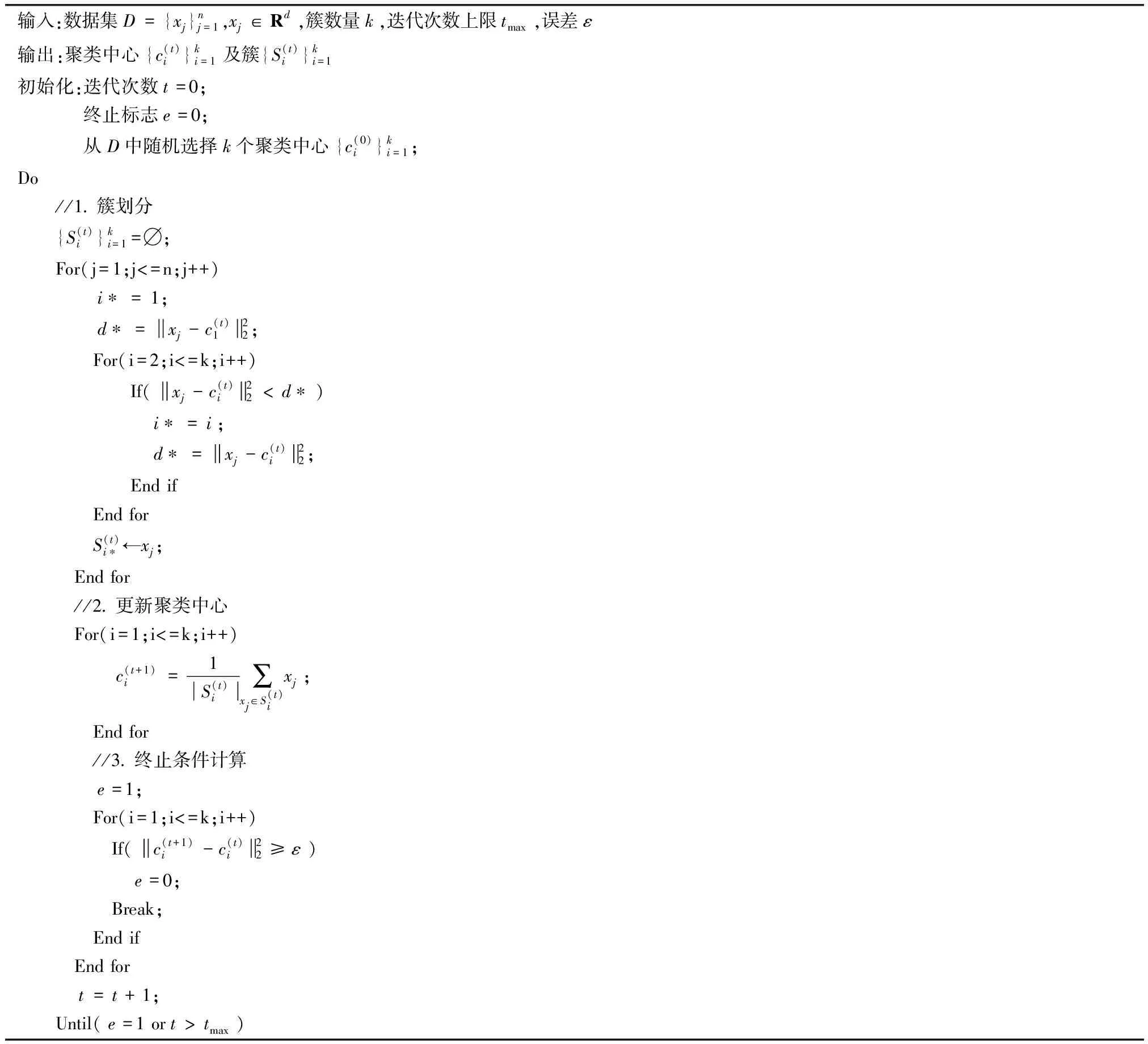
表1 K均值聚类算法
由表1可见,K均值聚类算法在迭代过程中反复划分簇和更新聚类中心,直至相邻两次迭代结果中聚类中心变化小于设定的误差ε或者迭代次数大于上限值tmax。
1.3 HKM聚类算法
本文设计Hadoop框架K均值聚类算法的目标是提供一种可以在Hadoop平台上应用的快速K均值聚类算法,在保证聚类精度的前提下实现高效的大数据聚类。基本设计思路是:首先,将大数据切分成许多数据块;然后,每一个数据块独立进行聚类;最后,对各个数据块的聚类结果进行融合,得到最终的聚类结果。为了提高各个数据块的聚类收敛速度,本文在初始化阶段先进行一次K均值聚类,得到初始的聚类中心,后续各个数据块在这些初始聚类中心的基础上进行迭代聚类,提高收敛速度。基于这一思路,本文的HKM算法主要分为3个阶段:①初始聚类中心提取;②数据块聚类;③融合聚类。
按照MapReduce编程模型,数据块聚类对应于Map阶段,融合聚类对应于Reduce阶段。首先,HKM算法使用HDFS选项从主节点的数据集中随机选择一些数据,并采用经典的K均值聚类算法进行聚类,提取初始聚类中心并发送到Hadoop缓存文件。在每一次迭代过程中使用这些初始的聚类中心提高算法的收敛速度。然后,在各个分布式节点,使用K均值聚类算法对节点所分配的数据块进行聚类,得到各个数据块的聚类中心。为了便于实现后续Reduce阶段的聚类融合,本文提出一种权重K均值聚类算法,在每个数据块聚类时根据聚类簇的紧凑性生成一个权重项,用于评价该聚类中心的重要程度。最后在Reduce阶段提出一种加权融合K均值聚类算法,对各个数据块的聚类中心和权重项进行融合,得到最终的聚类中心。详细描述如下。
(1)初始聚类中心提取
为了提高数据块聚类的收敛速度,本文先采用K均值聚类算法在随机选择的一个数据子集上提取初始化的聚类中心,将其存储在Hadoop的分布式缓存文件中。分布式缓存文件是Hadoop的一个基本特征,可由各个节点独立访问。这样,各个节点在对数据块进行K均值聚类之前,可以先读取分布式缓存文件中的初始聚类中心,替换表1所示算法中初始化阶段随机选择的初始聚类中心。因为本文提取的初始聚类中心是由大数据的一个子集聚类而来的,而不是随机选取的,因此更能反映大数据实际的数据分布。因此用其作为初始聚类中心,可以降低聚类迭代次数,提高收敛速度。快速收敛在大数据领域至关重要,因为分析大量数据是非常耗时的。
二十一世纪网络科学技术飞速发展,移动互联网更是融入到人们的日常生活当中,因此,传统的媒介都已经通过网络技术向新媒体发展与融合。传统媒介传播方式单一,宣传成本高,技术不足,再加上传统媒介的本身的制约,很难取得很大的发展。
为了提取初始聚类中心,需要从大数据中选取一个数据子集。本文采用随机选取的方式选择大数据中的部分数据构成数据子集。该数据子集的尺寸越大,得到的初始聚类中心的精度越高,但运算效率越低。给定错误率α,数据子集的尺寸可以近似表示为[11]
(3)
其中,r表示大数据中各类别占比的相对差异,vα是与α相关的一个经验值。在本文中,取α=0.05、vα=1.27359、r=0.10。
对于所选择的尺寸为N的数据子集,本文采用表1所示的K均值聚类算法进行聚类,得到初始的聚类中心,并将其存储在Hadoop的分布式缓存文件中。
(2)数据块聚类

(4)
事实上,上式中的分母项为各簇中每一个样本与聚类中心之间的欧氏距离的平均值。很明显,该值越小,说明各簇中的样本离聚类中心的距离越近,数据越紧凑。因此,对应的权重应当越大。

表2 权重K均值聚类算法
(3)融合聚类

(1)初始聚类中心不采用随机选择方式生成,而是从Map阶段生成的聚类中心中选出权重最大的那一组作为初始聚类中心。
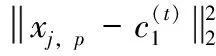

表3 加权融合K均值聚类算法
2 实验与分析
本文算法的设计目标是提升大数据挖掘应用场合K均值聚类算法的运算效率,因此实验时主要测量算法的聚类耗时指标。另外,在提升K均值聚类算法运算效率的同时还要关注聚类是否正确,因此实验时还要测量算法的聚类准确率指标。
本文选择经典K均值聚类算法(简记为KM)[6]和文献[9]改进的K均值聚类算法(简记为MKM)进行对比实验。实验所用的大数据集选择HIGGS数据集,该数据集包含1100万条记录,每条记录有28个属性特征。
实验平台包括1个主节点和8个从节点,主节点的硬件配置为:Intel Core i7-2600 CPU,16GB RAM,1TB硬盘。从节点的硬件配置为:Intel Core i5-4460 CPU,16 GB RAM,1TB硬盘。操作系统都是CentOS 7,Hadoop版本都为2.7.1,各节点通过100 Mbps的本地网络进行连接。
3种对比算法中的公共参数设置相同,具体为:簇数量k=2,迭代次数上限tmax=1000。针对不同的误差ε,测试不同算法的聚类耗时和聚类准确率的变化情况,结果分别如图1和图2所示。
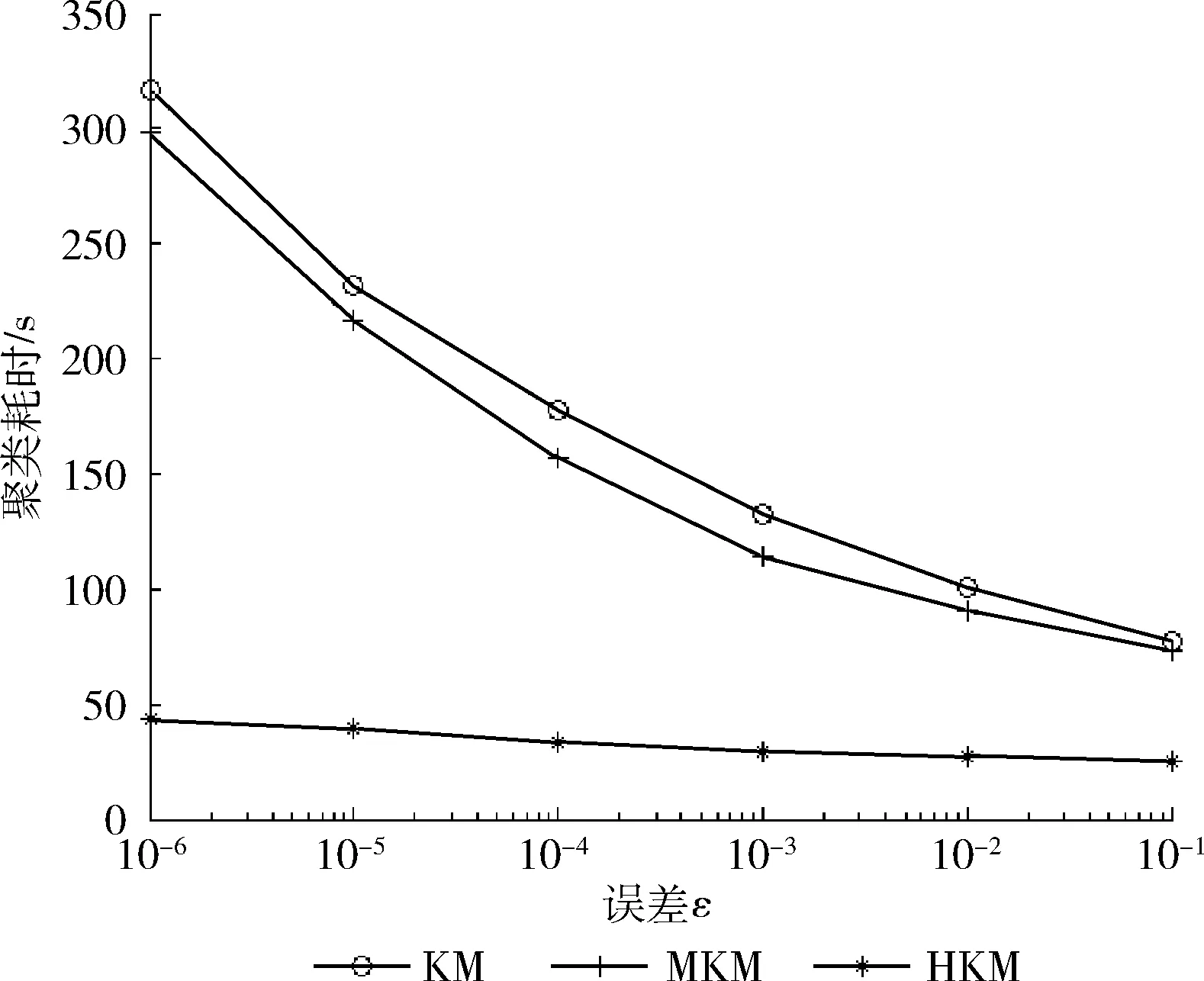
图1 聚类耗时随误差的变化曲线(横坐标无单位)
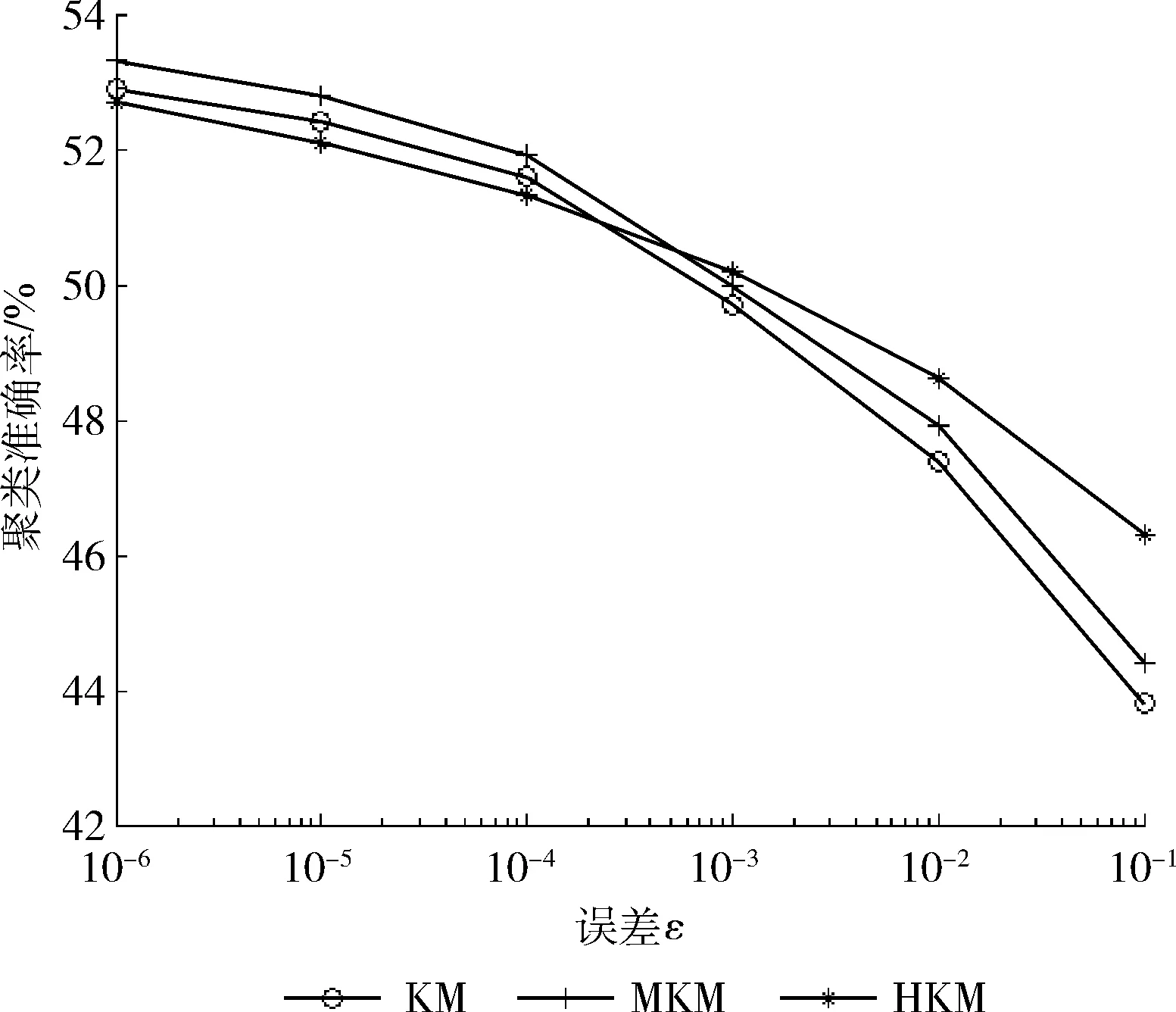
图2 聚类准确率随误差的变化曲线(横坐标无单位)
由图1和图2可见,随着误差ε的增加,3种算法的聚类耗时都会降低,而聚类准确率也有所下降。因为误差ε越大,聚类算法的收敛速度越快,聚类耗时随之下降。但是,快速收敛也可能引起迭代搜索的解并不是最优解,因此,聚类准确率可能会下降。
对比图1中3种算法的聚类耗时曲线,MKM算法的聚类耗时与KM算法相比有所降低,但是还是明显高于本文算法。以误差ε=1e-6为例,本文算法的聚类耗时为MKM算法的13.6%、为KM算法的14.4%。可见,本文算法对于KM算法的运算效率提升是非常明显的。这是因为本文算法将大数据的聚类分配到多个节点上进行,从而降低了聚类的耗时,而且,本文算法的聚类耗时受误差ε的影响也比较小,因此曲线比较平缓。
对比图2中3种算法的聚类准确率曲线,可见3种算法的聚类准确率相差不大,且误差ε较大时本文算法的聚类准确率略高于其它两种算法,这是因为本文算法将大数据划分成分块聚类,各数据块聚类时采用权重K均值和加权融合K均值算法提高聚类精度,弱化了误差参数对整体聚类准确率的影响。
综上所述,本文算法在保持聚类准确率的前提下大幅提升了大数据聚类时K均值聚类算法的运算效率。
3 结束语
本文提出了一种面向大数据挖掘应用的Hadoop框架K均值聚类算法。该算法结合Hadoop框架和MapReduce模型,设计大数据的K均值聚类算法,与经典K均值聚类算法相比,主要是在Map阶段提出了权重K均值聚类算法,用于提取各个节点上数据块的聚类中心和权重。另外在Reduce阶段提出了加权融合K均值聚类算法,用于对Map阶段得到的聚类中心和权重进行融合,得到最终的聚类结果。本文算法的主要特色是将大数据聚类的耗时分摊到各个节点上,从而提高大数据聚类效率。通过在HIGGS数据集上进行聚类对比实验与分析,验证了本文算法的聚类准确率与经典K均值聚类算法和改进的MKM聚类算法相当,但聚类耗时远低于所对比的两种聚类算法。
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2021年1期)2021-03-29
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
数学物理学报(2020年3期)2020-07-27
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
燕山大学学报(2015年4期)2015-12-25
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
郑州大学学报(理学版)(2014年4期)2014-03-01
