
应用近红外光谱技术检测木材含水率的方法1)
2018-12-21 08:19:38汪紫阳李耀翔尹世逵
东北林业大学学报 2018年12期
汪紫阳 李耀翔 尹世逵
(东北林业大学,哈尔滨,150040)
对木材进行恰当的干燥处理,使木材的含水率降低并维持在一定的程度,可以延长木材及木制品的储存时间和使用寿命。木材的含水率在纤维饱和点(30%)范围内变化时会发生干裂、湿胀等现象,使木材出现裂痕,发生形变[1]。对木材含水率的控制是木制品生产企业比较重视的一个环节,同时也是木制品生产加工最重要的一个因素。在木材的切削和储存、木制品的生产和加工过程中,对木材含水率的实时监测显得尤为重要。如果不能及时控制木材的含水率,即使原本合格的木制品也会出现开裂、变形等问题[2]。随着天然林全面禁伐的逐步推进,国内木资源供给紧张,对高效、合理地保存和使用木材提出了更高地要求。在木材的流通与加工过程中需要能够快速、精准、无损地得到木材的含水率数据,以判断木材干燥的程度。
木材含水率的检测方法有很多,近几年有通过无损检测技术预测木材含水率的研究[3-6]。近红外光谱技术可以用于含氢基团的定性定量检测,对物质中水分的信息比较敏感,可以用于含水率的检测。近红外检测用时很短,光谱的采集过程可以在几秒之内完成[7]。并且近红外光的传输性能好,可以通过光纤传输,实现远程检测和在线检测[8]。又因为该谱区的吸收强度低、发热小,可以达到无损检测的目的而被广泛应用。但是目前绝大部分的研究都是使用近红外光谱技术对一个树种木材的含水率进行预测[9-13],对使用近红外光谱技术同时预测多个树种木材含水率的研究比较少。笔者使用近红外光谱技术建立单一树种的含水率预测模型,并利用两种木材的混合样本光谱建立含水率预测模型,可以对使用多个树种混合近红外光谱建立含水率模型提供参考。
1 材料与方法
1.1 材料
本试验所用样品均采自黑龙江省方正县林业局星火林场(N45°43′5.73″,E129°13′34.37″)。样品由生长锥钻取,钻孔方位为由南向北穿过树心,高度为距离地面1.3 m胸高处。本次采样采得2个树种,分别是胡桃楸(JuglansmandshuricaMaxim.)和榆树(UlmuspumilaL.),其中胡桃楸采样42棵,榆树采样32颗,共74根样品。样品的三分之二作为校正集用于建立模型,三分之一作为验证集用于验证模型。样品直径约为5.15 mm,长度略大于采样树木胸径的一半,100~350 mm不等。本次含水率测定按照GB/T 1931—2009《木材含水率测定方法》进行。两个树种样本的含水率统计信息见表1。

表1 样品含水率统计信息
1.2 近红外光谱采集
使用美国ASD公司生产的LabSpec便携式快速扫描光谱仪采集样品近红外光谱。本试验采用两分叉光纤,将探头固定在光纤端部2 mm处。将木条木样嵌入直径为5 mm的探头口中,如图1所示。光斑直径为5 mm。将样品从中部截断,每个断面采集1次光谱后旋转一定角度采集第2次光谱,共采集3次光谱。每次全光谱数据采集时间为1.5 s。在1.5 s内,光谱仪会连续扫描30次,并自动取其平均光谱。采集完成后立即称质量,由于采集时间比较短,认为样品在采集光谱的时间内含水率没有改变。筛除异常光谱后取平均光谱用于分析。用光谱仪配套的软件采集光谱并转换成由2 151个数据点组成的数据文件。
1.3 数据处理
样品的近红外光谱为表观光谱,由能够表征样品的真实光谱和不确定的背景组成[14]。由于木材是复杂的天然物,属于散射介质,采集光谱时需要用漫反射光谱分析样品,相对于透射光谱测量方式要更加复杂[15]。

图1 生长锥样品近红外光谱采集
近红外光谱预处理常用的方式就是数字滤波和导数处理。目前常用的数字滤波为平滑处理,光谱平滑可以降低噪音,一定程度上提升信噪比,但过度平滑会使光谱失真。背景中的基线偏移和光谱旋转可以通过对光谱求导处理进行校正,但是求导的过程中会放大光谱的噪音。本研究采用中心化、标准化和导数处理3种预处理方式。
近红外光谱技术用于定量分析需要借助于化学计量学方法。常见的与光谱学相关的化学计量学分析方法有比尔定律法(Beer’s law)、经典最小二乘法(CLS)、逐步多元线性回归法(SMLR)、主成分分析法(PCA)、偏最小二乘法(PLS)、人工神经元网络(ANN)等方法。偏最小二乘法=主成份分析+典型相关分析+多元线性回归,常用于近红外光谱分析中。本研究采用偏最小二乘法建立木材含水率的预测模型。评价模型优劣的指标为校正集均方根误差、预测均方根误差和相关系数。相关系数越大,说明模型线性拟合效果越好。校正集均方根误差和预测均方根误差越小表示模型的预测效果越好,若两者的差异较小,说明校正集样本具有代表性,模型拟合恰当。
2 结果与分析
2.1 单一树种预测
42个胡桃楸样本的近红外光谱和32个榆树样本的近红外光谱如图2所示。所有光谱在1 415、1 884 nm处有吸收,则两个波长点在H2O和H—O键的二倍频吸收带附近[16]。所以可以判定此强吸收带主要由样本中的水分引起。两个树种木材的近红外光谱波形比较相似,这有利于混合树种木材的近红外含水率模型的建立。
由表2可以看出,使用原始光谱进行建模的含水率模型验证集预测效果不好,胡桃楸和榆树的相关系数仅为0.630 6和0.684。但是经过中心化和标准化处理之后的模型预测效果得到提升,胡桃楸和榆树的相关系数分别为0.867 5和0.821 2。可见对光谱数据进行中心化和标准化能够提升模型的预测精度。在此基础之上,对光谱分别进行了一阶导数和二阶导数处理,预测模型的精度继续得到提升。其中胡桃楸NIR光谱经中心化、标准化和二阶导数处理之后所建立的模型效果最好,校正集相关系数为0.991 1,验证集相关系数为0.928 3。榆树NIR光谱经中心化、标准化和一阶导数处理之后所建立的模型效果最好,模型的因子数为2,预测模型的相关系数为0.952 9。但榆树NIR光谱经中心化、标准化和二阶导数处理之后所建立的模型的校正集相关系数最高,为0.989 2。这说明对于不同的样本,导数处理能够提高模型的准确率,但是对于最优模型效果下的导数阶数的选取,需要对不同的样本做具体分析。
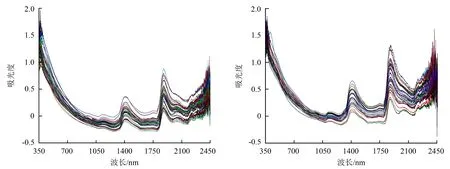
图2 样品近红外光谱
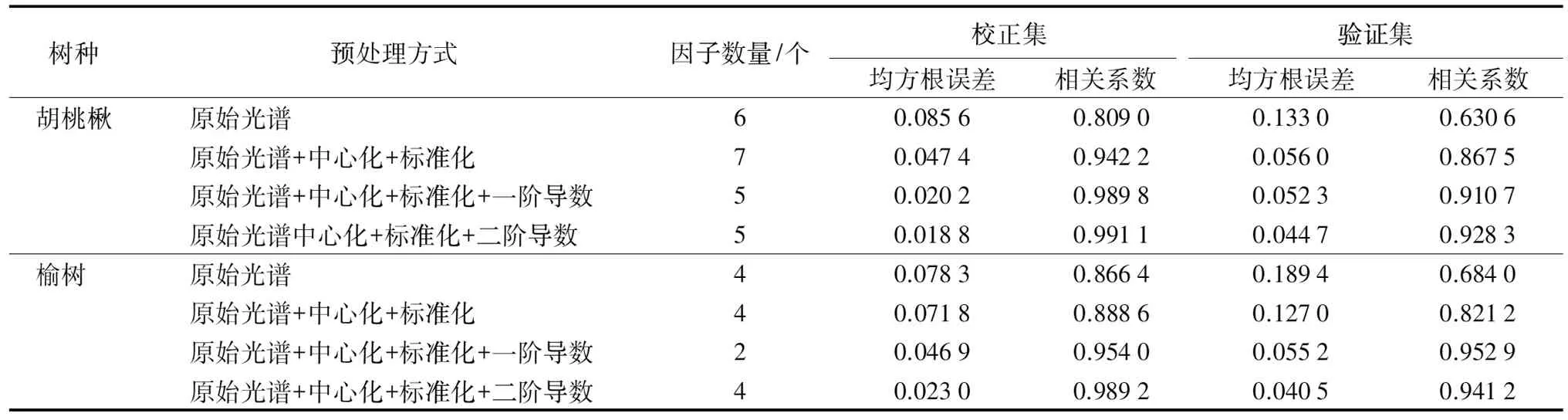
树种预处理方式因子数量/个校正集均方根误差相关系数验证集均方根误差相关系数胡桃楸原始光谱60.08560.80900.13300.6306原始光谱+中心化+标准化70.04740.94220.05600.8675原始光谱+中心化+标准化+一阶导数50.02020.98980.05230.9107原始光谱中心化+标准化+二阶导数50.01880.99110.04470.9283榆树原始光谱40.07830.86640.18940.6840原始光谱+中心化+标准化40.07180.88860.12700.8212原始光谱+中心化+标准化+一阶导数20.04690.95400.05520.9529原始光谱+中心化+标准化+二阶导数40.02300.98920.04050.9412
2.2 混合树种预测
本试验将取得的74个胡桃楸和榆树混合木材样同时用于建立木材含水率的模型,其中50个样本用于校正集(胡桃楸28个,榆树22个),24个样本用于验证集(胡桃楸14个,榆树10个)。在不同预处理方法下建立的混合木材含水率模型的预测结果见表3。可以看出,能够使用不同种类木材的NIR光谱建立混合木材含水率模型。但是使用原始光谱建立的模型预测效果不好,相关系数仅为0.745 3。光谱经过中心化和标准化处理之后所建立的混合木材含水率模型的相关系数提升了17.59%,均方根误差下降了34.81%。结果表明在对光谱进行中心化和标准化的基础之上使用导数处理可以提升模型的预测精度。其中混合光谱经过中心化、标准化和二阶导数处理之后的校正集内部交互验证效果最好,校正集相关系数为0.981 5,均方根误差为0.035 2;混合光谱经过中心化、标准化和一阶导数处理之后的验证集预测效果最优,校正集相关系数为0.930 9,均方根误差为0.061 1,因子数量为3个。

表3 不同预处理方法的胡桃楸和榆树混合模型含水率预测结果
不同预处理方式下的模型线性拟合情况如图3所示,从原始光谱到经过中心化、标准化和二阶导数预处理的光谱所建立的模型线性拟合效果越好,校正集和验证集的含水率预测值与测量值的散点趋于线性分布。原始光谱经过中心化+标准化+二阶导数预处理后所建立模型的整体效果最好,但是预测的相关系数没有中心化+标准化+一阶导数的处理效果好,表现为二阶导数的验证集相关系数(0.915 0)低于一阶导数(0.930 9),可能是验证集样本数量不够大造成的。
混合树种木材的含水率预测模型的精度会低于其中精度最高的单一树种木材的含水率模型,略高于精度最低的单一树种木材的含水率模型。

图3 不同预处理方式的混合模型PLS预测结果散点图
3 结论与展望
近红外光谱技术不仅可以用于单一树种木材含水率预测,也可以用于混合树种木材含水率预测,所使用的样品可以为生长锥取样样本。
对光谱进行中心化、标准化和导数处理能够提升预测模型的精度。通过比较发现,经过中心化、标准化和二阶导数处理的胡桃楸样本光谱所建立的模型预测效果最好,验证集相关系数为0.928 3;经过中心化、标准化和一阶导数处理的榆树样本光谱所建立的模型预测效果最好,验证集相关系数为0.952 9;在使用混合树种木材的光谱进行识别时,使用中心化+标准化+一阶导数进行预处理的预测效果最好,验证集相关系数为0.930 9。
但是混合树种木材的含水率预测模型的精度会低于其中精度最高的单一树种木材的含水率模型。在实际使用过程中,可以使用定性分析+定量分析的方法预测木材的含水率。首先通过定性分析识别树种,再根据树种不同选择不同的含水率预测模型。相比之下,选择混合树种木材的含水率模型会相对便捷。使用混合树种建立含水率的识别模型更适合实际推广和使用。
本试验混合模型所使用的校正集同时包含了三分之二的胡桃楸光谱和三分之二的榆树光谱,即在本次混合模型的校正集和验证集中胡桃楸NIR光谱和榆树NIR光谱的权重比为1∶1。在今后的试验中,可以测试校正集所使用的光谱中不同树种木材光谱数量的配比对含水率预测模型精度的影响。
猜你喜欢
建筑与预算(2024年2期)2024-03-22 06:51:36
大自然探索(2024年1期)2024-02-29 09:10:32
军事文摘(2021年16期)2021-11-05 08:49:06
中学生数理化(高中版.高二数学)(2021年4期)2021-07-20 07:18:48
扬子江(2019年3期)2019-05-24 14:23:10
读友·少年文学(清雅版)(2019年12期)2019-04-20 09:08:30
现代园艺(2017年22期)2018-01-19 05:07:14
数学大世界·中旬刊(2017年3期)2017-05-14 17:41:25
高中生学习·高三版(2016年9期)2016-05-14 14:05:08
读写算(下)(2015年11期)2015-11-07 07:21:10
