
基于人脸多模态的视频分类算法的设计与实现
2018-12-20 07:54李丹锦
电子设计工程 2018年24期
李丹锦
(北京工业大学信息学部,北京100000)
在图像识别领域中,人脸识别是主流的研究方向,从传统图像处理的人脸检测和人脸边缘特征提取,VGG-Face实现人脸识别的高维特征提取,以及近年国内seetaFace算法的提出,都标志着人脸识别领域算法的突飞猛进,广义的人脸识别主要包括四大人脸技术,分别为人脸检测、人脸对齐、人脸验证和狭义的人脸识别,分别实现了在自然场景中对人脸处理的各个流程,其中人脸识别的延伸领域也有了很大发展,如人的性别、年龄、表情等特征的识别,本文主要实现了人脸检测、人脸对齐、人脸多模态识别的算法和相关的改进,并将其与视频分类的算法相结合,实现在视频领域的智能化应用,为未来做视频分类提供思路、铺垫基础。
1 概述
本文主要具体针对人脸的表情识别进行研究,对基于视频片段的表情识别做出改进,以期提高基准算法的识别准确率和实时性。得出人脸多模态的分类标签后,继续研究视频关键片段的选取,确定一段短视频的数个关键序列,针对这些序列做多模态识别,对每个序列保留分类相似度前二的两个标签,随后利用这些关键序列的情感标签做数据分析,得到视频的情感分类标签。算法的整体流程图如图1所示:
2 自然场景的人脸多模态识别
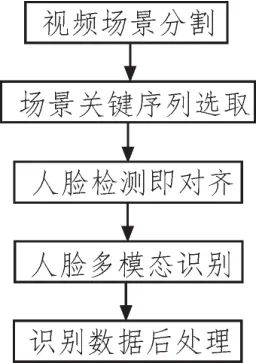
图1 算法基本流程
人脸多模态识别文中主要指人脸面部多表情识别,本文定义的表情种类有7种,分别为Angry、Disgust、Fear、Happy、Neutral、Sad、Surprise,本课题基于视频片段做研究,在表情识别的流程中主要包括人脸检测、人脸矫正(对齐)、人脸多模态识别三部分工作。本文在数据集AFEW上做最终训练,该数据集主要截取于电影中的经典场景,需要处理的原始数据是自然场景下的图像数据,而非规格化之后的标准数据,在算法处理上会有一些不同。
2.1 人脸检测及人脸矫正
首先对于人脸检测算法,并非本文重点研究内容,而且目前人脸检测算法趋于成熟,故而直接采用seetaFace实现人脸检测功能。
实现人脸检测后由于数据集是自然场景人脸数据,故而需要得到人脸矫正后的正脸图像才能用于人脸的表情识别的算法训练,矫正人脸首先到得到人脸的特征点或三维偏转角度,本文做人脸对齐的数据集同时标注了人脸68个特征点和基于正方位的三维偏转角,故设计卷积网络直接回归得到人脸的三维偏转角。模型上借鉴VGG-Face浅层网络的特点,设计5层卷积的简单模型。
模型首先接收124×124大小的灰度图像并标记人脸的偏转角度为网络的输入,随后通过卷积核较大(size分别为7和5)的两层网络将图像快速收缩,并提取低维边缘特征,同时在第一层网路后将其结果归一化,随后连接三层小卷积核(size为3)网络进一步细化人脸边缘特征,最后连接两层全连接层,做回归函数得到结果序列。模型结构如图2所示。
2.2 人脸多模态的识别
基于视频的人脸多模态识别的baseline算法为VGG+LSTM算法,基本思想为通过VGG模型提取特征,继而采用LSTM对视频片段做加强训练。
C3D模型主要改变了传统2D卷积的特点,创新性的引入了3D卷积的方式,2D卷积在映射特征的时候只能在单层featuremap上提取,而3D卷积网络可以在相邻的featuremap上映射特征。

图2 人脸对齐卷积模型
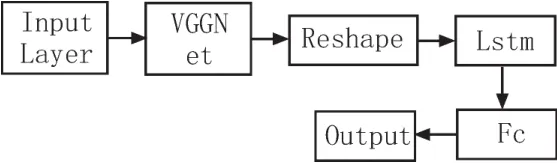
图3 多模态baseline模型
HoloNet模型算法则是采用另外一种改进方式进行算法的改进,即引入残差的思想。整个模型体现了残差设计的思想,在将提取的特征图和上层样本同时作为下一层的输入,以减少模型提取过程中特征的损失提高识别的准确率。
2.3 人脸多模态的算法改进
在研究经典多模态算法的基础,借鉴其中经典思想,本文提出了一种基于VGG模型改进的新的模型结构,用于本文人脸多模态识别的应用。
首先在预处理阶段采用灰度图、meanLBP图、basicLBP图组合而成的三通道图像数据代替传统的RGB 3色图像,而适当减少VGG网络浅层网络,保留其浅层网络收敛图像的作用,并适当弱化浅层网络边缘特征提取的作用。LBP算法是一种传统的人脸边缘特征提取的算法,以此方式可以在预处理阶段先对人脸边缘特征做针对化的简单处理,以提高卷积网路运算的速度和特征提取的这针对性,有效提高模型准确率。
其次,对于VGGFace算法而言,高层网络卷积核主要实现的是高维特征的提取,在此提出的模型上的改进思路为,将VGG模型高层网络卷积单元适当替换为残差网络单元。其中残差网络的模型特点是将原始数据和经过卷积映射处理后的数据一同作为下一层卷积的输入。模型图为图5和6。
以此适当保留卷积映射之前特征,有效提高的模型的准确率。图4为处理结果:

图4 LBP处理后的样本
3 视频关键场景的定位
在对场景进行多模态识别之前,我们需要对短视频截取关键场景,本文定义的关键场景是有人物,且帧清晰同时可以代表一个长场景的一段序列,这段序列一般由十几到数十帧组成,需要设计算法用于实现对一个视频进行关键场景的选取。
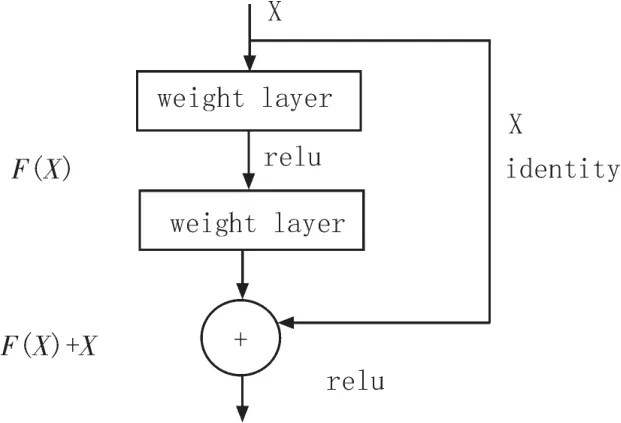
图5 残差网络单元
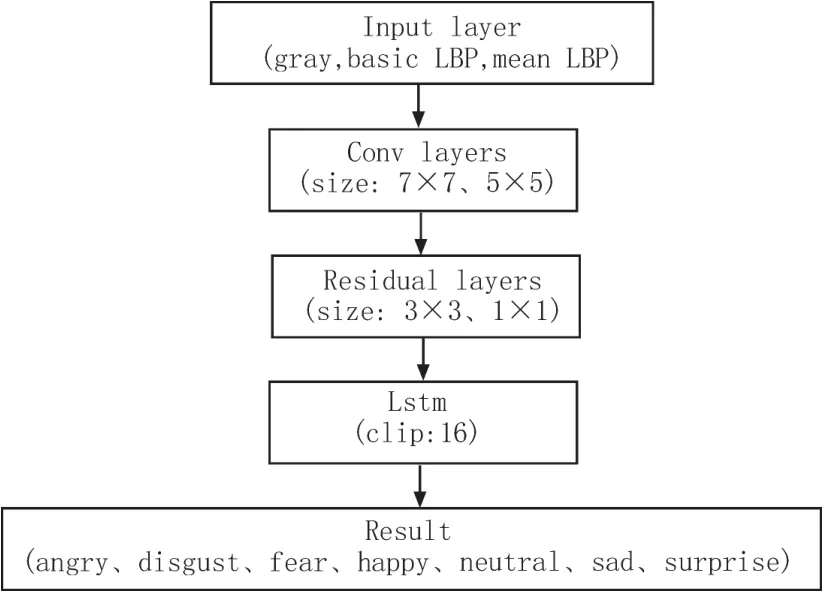
图6 表情识别卷积模型
首先本文采用关键帧定位算法,即对一个转场镜头的视频序列确定关键帧,选取关键帧前后X帧(不超过该场景的始、终位置)组成关键场景,在此规定一个转场镜头有且仅有一个关键帧。具体算法描述为:
第一步,对视频进行场景切割。将待分类视频分割为数个场景片段,即根据检测到的转场处切割视频,得到数个场景视频,此处场景转换检测算法采用dHash算法。
第二步,确定场景关键帧。关键帧确定算法采用图像熵最大化。
第三步,选取关键帧前X帧(临界值为场景起始)和后X帧(临界值为场景结束)组合为截取的该场景的关键场景。
第四步,对于每个场景都采用上述算法,得到一个视频的若开关键场景。
其中图像熵的定义为:对一副图像来说,直方图可被认为是一种概率密度函数,设hk表示整幅图像中像素值为k的像素所占的比例,考虑到当hk=0的实际情况,加上约束条件:当hk=0,则loghk=0。因此,图像熵表示为:

其中将图像由rgb格式转化为hsv:格式,h、s、v 3个分量加权系数为0.9、0.3、0.1,得图像综合熵为:

图像熵最大化关键帧定位即为计算一段帧序列中每帧图像的熵,选取最大值作为这段序列的关键帧。
4 数据分析和视频分类
本文首先构建一个情感与视频类别的简单三分类映射,以验证上述算法的可行性。其中为各个情感设置标志位,其中相邻情感有一定的相似度和渐变性,将 sad、fear、angry归类为消极情感,将 disgust、surprise归类为介于消极情感和积极情感之间的过渡情感,将neutral、happy归类为积极情感。
在上述表情识别结果中,每个标签保留可能性前两位的标签数据。
1)如果t1与t2同属一个大分类,则直接选取t1作为其最终标签。
2)如果t1与t2分属两个不同的分类时,该标签为

一段视频分为了n个场景,每个场景都有一个关键序列,上述实现了每个场景的标签选取,每个场景的权重为Wn,Wn由该场景占总视频的比重确定。最终视频标签:
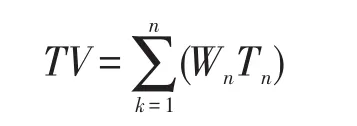
5 结果及分析
人脸表情识别整个算法最终在AFEW公开数据集上得出53.8%的准确率,高于baseline的准确率(49.3%),仍有待继续优化卷积模型。
对于整个视频分类的算法效果而言,整体可以实现对视频大致归类的效果,部分实验结果如表1所示。

表1 实验结果表
结果可见对于消极情感的准确率最高,而待测视频最易被误识别为过渡情感。
6 结论
通过上述人脸多模态和视频解析分类算法,将人脸识别与视频处理和分类综合应用相结合,得到了理想的实验效果。通过实验也得出人脸多模态技术能够用于对视频进行情感层面的分类。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
电子制作(2019年11期)2019-07-04
动漫星空(2018年9期)2018-10-26
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
发明与创新(2015年33期)2015-02-27
