
基于深度学习的图片问答系统设计研究
2018-12-13 09:07周远侠
计算机应用与软件 2018年12期
周远侠 于 津
(汕头大学工学院计算机科学与技术系 广东 汕头 515000)
0 引 言
近年来,包括深度学习在内的机器学习理论有了巨大进展,人类见证了人工智能在众多领域的研究及应用成果。2015年,学术界提出的自由形式和开放式视觉问答VQA任务[1],逐步成为人工智能研究的热门方向。VQA系统将图像与自由形式和开放式的自然语言表述问题作为输入,产生的自然语言表述答案作为输出。VQA任务需要具有精准识别、物体检测、活动识别、知识库推理和常识推理等功能的问答系统来完成,而这些功能所涉及的计算机视觉、自然语言处理和知识推理等领域在过去10年中取得了显著的进步。
图片问答聊天机器人涉及的领域主要有视觉问答、文本问答和图像处理。
计算机视觉问答的研究始于2014年,一开始的研究,其设定和数据集都比较有限[2-3]。例如,文献[2]只考虑答案来自16个基本颜色或894个对象类别的预先设计的闭合问题。文献[3]考虑从对象、属性、对象之间的关系来构建固定词汇表的模板进而生成的问题。相比之下,文献[1]在一年后提出的任务涉及人类的开放式,自由形式的问题和答案,增加了提供正确答案所需的知识的多样性和推理的种类[1]。从数据集上看,后者[1]的数据集(问答对36万,图片12万)比前两者[2-3](分别为2 591和1 449图像)大两个数量级,这对在视觉问答这个更为困难和无约束的任务上取得成功很重要。视觉问答的问题是开放式的,然而,了解问题的类型和哪些类型的算法能更好地回答问题也很有必要。为此,后者[1]还分析所提问题的类型和提供的答案类型,通过几种可视化展示了所提问题的惊人的多样性,并探讨问题的信息内容和答案与图像说明的区别。他们设计出一个将处理问题的LSTM与处理图像的卷积神经网络相结合以产生答案的模型[1],并以几种使用文本和最先进的视觉特征相结合的方法作为基准,对类似的模型进行了评估。除此以外,其他相关工作有:文献[4]最早设计出一个将处理问题的LSTM(Long short-term memory)网络与处理图像的卷积神经网络相结合以产生答案的模型。文献[5]引入了10 k图像的数据集,并提出了描述场景的特定方面的说明。百度的Gao等[6]收集了COCO图像的中文问题和答案。文献[7]使用微软的COCO数据集说明自动生成对象、计数、颜色、位置四种类型的问题。
从最新(2016年、2017年)发表的文献上看,有些学者已经开始尝试将“带有注意力”的模型加入到现有的视觉问答研究中,例如,文献[8-11]使用了基于视觉注意的模型,其中注意机制通常产生突出显示与回答问题相关的图像区域。这几篇文献都专注于识别“往哪里看”或“视觉注意区域”的问题。文献[12]认为,除了建模“往哪里看”或“视觉注意区域”之外,同样重要的是要模拟“听问题的重点”或“提问注意”。因此他们提出了一个新颖的VQA的共同关注模式,同时关注问题和图像的“重点区域”。主要通过新颖的一维卷积神经网络(CNN)以分层方式进行改进。然而,在引入了“带有注意力”的机制后,模型的复杂度会提高不少。
基于文本的问答在自然语言处理和文本处理领域是一个很好的研究问题。文献[13]中让机器回答阅读理解多项选择问题,试图解决开放域的机器理解问题;文献[14]合成了文本描述和QA(问答)对。这些方法为视觉问答的研究提供了灵感。视觉问答的自然基础是图像,即需要理解文本(问题)和视觉(图像)。由于关于图片提出的问题是由人类产生的,因此常识知识和复杂推理也显得很有必要。
图像处理的相关技术为视觉问答提供一定的支持和借鉴,比如图像标记[15-16]与图像说明[17-18]。和视觉问答相比,这些任务虽然需要视觉和语义知识,但是说明通常不具有针对性[18]。相比之下,视觉问答中的问题往往需要详细的有针对性的图像信息,所以和一般的图像标记与图像说明不一样。
我们在对数据集统计分析的基础上提出数据预处理方法仿聚类法,建立合适的LcVMS模型,并以此设计出图片问答系统。这个图片问答系统需要精准识别、物体检测、活动识别、知识库推理和常识推理等多种AI功能,对人工智能的学术研究有积极意义;从工业角度上看,一个成熟的图片问答系统,能协助视觉障碍用户积极获取视觉信息。因此,以VQA这个目标驱动型任务为导向,以深度学习为基础,研究图片问答聊天机器人的系统设计,既有理论研究意义,也有实际应用价值。
1 框架设计
1.1 任务描述
最近几年,计算机视觉CV(Computer Vision)、自然语言处理NLP(Natural Language Processing)和知识表示与推理KR(Knowledge Representation & Reasoning)快速发展,越来越多的学者投入到上述学科的交叉任务研究中。2015年,Aishwarya等提出了自由形式和开放式视觉问答VQA的任务:给定图像和相应的以自然语言表述的自由形式的、开放式的问题,智能系统响应以自然语言表述的准确的问题答案。这里最需要强调的一点就是,问题和答案都是开放式的,不加任何限制,视觉问题可以选择性地针对图像的不同区域,包括背景细节等。因此,一个理想的系统通常需要具备比生成通用图像标题的系统更详细地理解图像和进行复杂推理的能力。我们也是基于这样的任务目标设计图片问答系统。
1.2 图片特征提取模块
在2015年ICLR(International Conference on Learning Representations)会议上,Karen Simonyan和Andrew Zisserman提出了VGG16和VGG19两个非常好的深层卷积神经网络DCNN(Deep Convolutional Neural Network)[19]。我们模型的图片特征提取模块选择的网络是VGG16。网络所有卷积层有相同的配置,卷积核大小均为3×3,步长为1,填充为1;共有5个最大池化(max pooling)层,大小都为2×2,步长为2;卷积层的通道数目,或者称为宽度从64开始,每次经过一个最大池化层翻倍,一直到512为止;共有三个全连接层,前两层都有4 096通道,第三层共1 000路及代表1 000个标签类别;除了最后全连接的softmax层外,其他层都需要使用整流线性单元(ReLU)非线性激活函数。由于我们只用这个VGG网络来提取图片的特征,而不是做图像分类任务,因此最后的softmax层就要删除,这样修改后的VGG网络如图1所示。
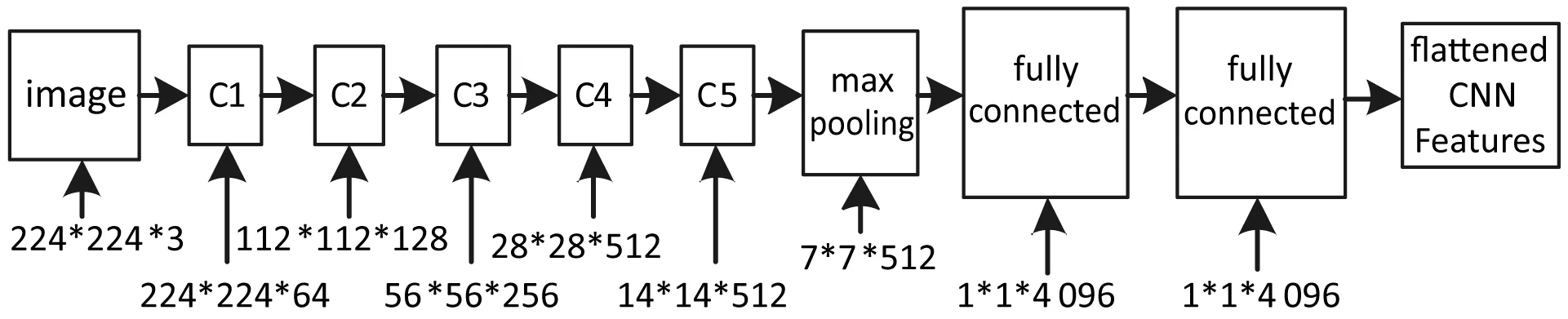
图1 修改后的VGG网络
VGG网络在最后一个隐藏层加入L2正则化,修改后的VGG网络输入是一个图片,输出则是一个该图片的“数字化表达形式”:为了与后边模型衔接,其后再加一层平整化(flatten)得到一个包含4 096个元素的一维的数组,我们以后将这个数组称之为卷积神经网络提取的图片特征,简称CNN Features。
1.3 问题特征提取模块
由于文字不能直接作为神经网络的输入,这里需要选择一种文字的数字化表达形式。我们选用的word2vec词向量表示,是一种适合机器学习、特别是深度学习的输入和表示空间的语言模型。这里可以简单地把word2vec当成一种把词语变成向量表示的方法,具体原理不做深入讨论。
对于问题的处理,我们尝试两种不同的方式:
模型1:普通的词袋模型(Continuous Bag of Words Model):首先利用自然语言处理NLP(Natural Language Processing)的word2vec技术,将问题中的每个单词先转化为一个300维的向量(vector),然后将所有词语的向量相加。此处将获得一个300维的向量作为Question的数字化表达。
模型2:LSTM模型:首先利用word2vec技术,将问题中的每个单词先转化为一个300维的向量(vector),这一步和模型1一样。然后按照句子中单词排列的顺序将每个单词依次输入带有一个隐藏层的LSTM网络,将网络输出的512维向量作为问句的数字化表达。
模型1和模型2的主要区别在于:模型1直接将各词的词向量表示加和,作为整个问句的向量表示,是一种平均化的方法。这种方法完全不考虑词在句子中出现的顺序,类似于“把词扔进一个袋子里”,所以叫词袋模型。模型2用的LSTM模型是RNN的一种,词语在问句中的顺序会直接影响输入的顺序,进而影响问句的特征表达。
1.4 训练模块结构
神经网络设计的一个关键是确定结构。结构(architecture),是指网络作为一个整体,包含多少单元,以及这些单元之间是如何连接的。
1989年,通用近似定理(universal approximation theorem)提出,一个前馈神经网络如果具有线性输出层和至少一层具有任何一种“挤压”性质的激活函数的隐含层,只要给予网络足够数量的隐含单元,就可以任意的精度来近似任何从一个有限维空间到另一个有限维空间的Borel可测函数[20]。这里不展开讨论这个定理的具体内容,只引用一个结论:通用近似定理表明,无论需要神经网络学习什么函数,一个足够大的多层感知机MLP(multilayer perceptron)一定能够表示这个函数。
结构设计除了考虑网络的神经元数量以外,还需要考虑层与层之间如何连接。默认的神经网络层会采用矩阵描述的线性变换,每个输入单元连接到每个输出单元,这就是所谓的全连接。也有某些网络不使用全连接,通常,学术界无法对通用神经网络的结构给出更具体的建议,需要具体问题具体分析。这里只简单阐述模型1与模型2的结构,如图2、图3所示。

图2 模型1结构图

图3 模型2的结构图
1.5 分类模块
输出单元的选择与损失函数的选择紧密相关,通常损失函数使用数据分布和模型分布的交叉熵,而表示输出的形式决定了交叉熵函数的形式。输出层的作用是将隐藏层提供的特征进行变换以完成整个网络的任务,模型的任务是,把“看到一个图片回答开放式问题”转化成“从K个最有可能的回答中,找到最符合图片的答案”,这样就把一个开放的AI问题,转化成了multi-class的分类问题。softmax函数是一个用来表示一个具有多个可能取值的离散型随机变量分布的函数,常用来作为分类器的输出,因此这里选择softmax作为分类器,以获得出现频率最高的K个答案的分布。整个模型最后会以交叉熵作为损失函数实现端对端学习。
2 实验分析
2.1 数据集统计分析
2.1.1 数据来源
用于模型训练和分析的数据,来自VQA(Visual Question Answering)组织公布的数据集,具体下载地址在http://www.visualqa.org/vqa_v1_download.html。我们使用V1版本的数据集,这个数据集包括:微软的COCO(MSCOCO)数据集,123 287张图片,其中训练集图片82 783张,测试集图片40 504张;图片对应的Question共369 861个,其中训练集248 349个,测试集121 512个;每个Question对应的Answer有10个,经过数据预处理后[1],训练集和测试集的数量与Question相同(一个Question可能对应多个Answer,这不会影响数据集个数),即训练集248 349个,测试集121 512个。
2.1.2 统计与分析
1) Question部分的统计:
(1) 设阈值word_count_threshold=1 000,出现次数超过1 000次的单词,认为是高频词;其余为低频词。其中前20个高频词出现次数如表1所示。高低频词个数、个数比例、出现次数、出现次数占所有词出现次数比例如表2所示。
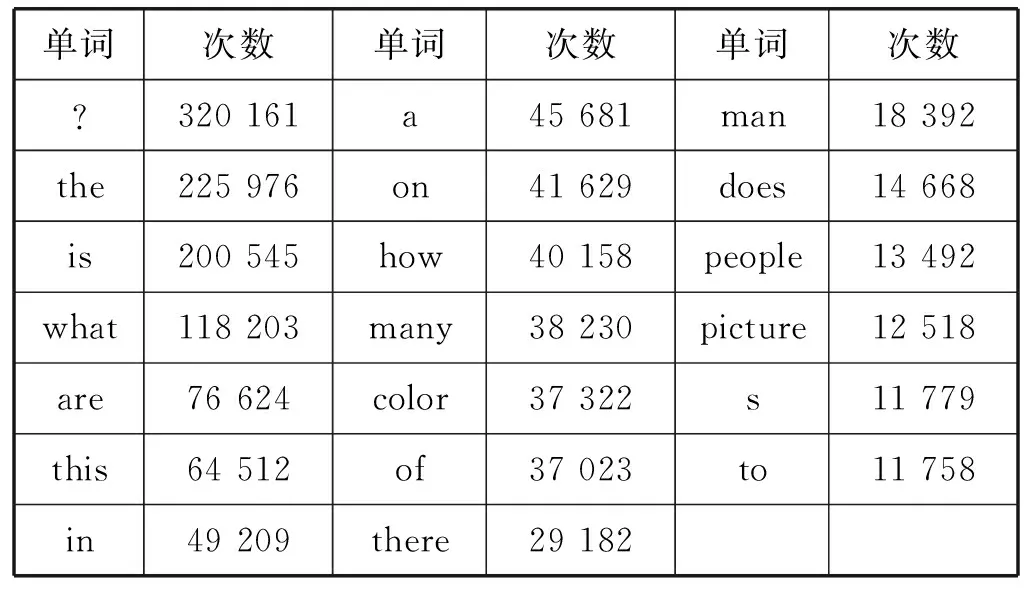
表1 前20个高频词出现次数

表2 高低频词个数与词频统计
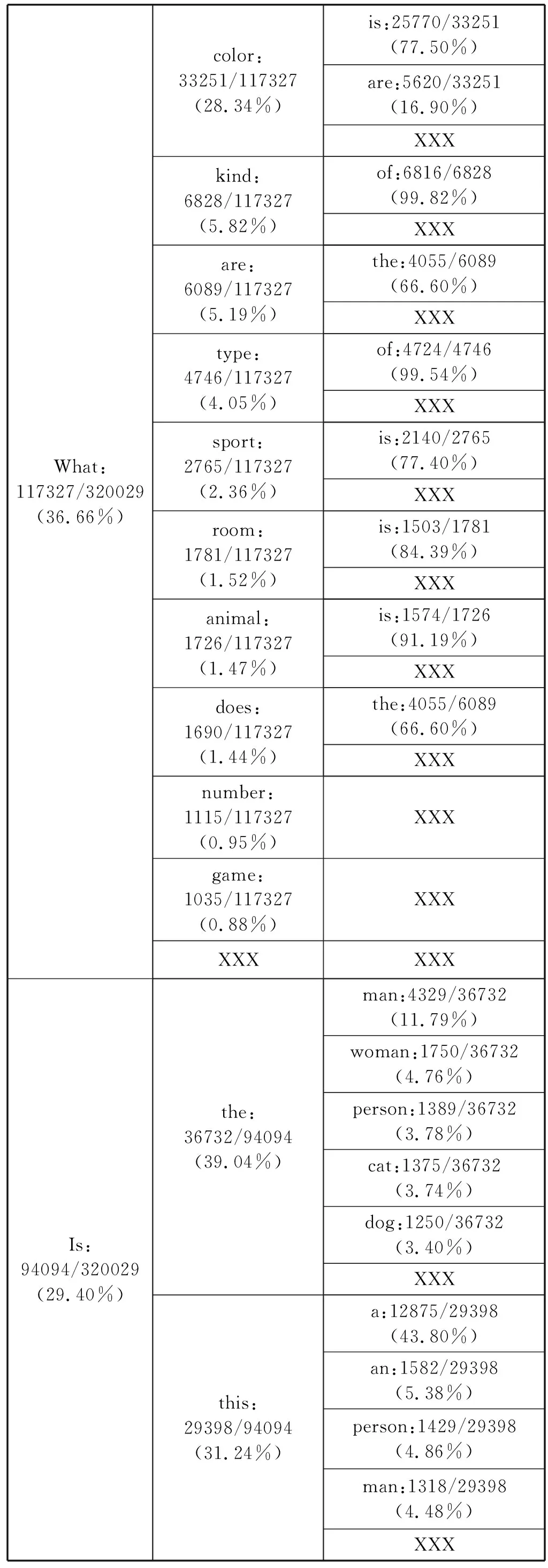
(2) 对每个Question,在前k个词出现的前提下第k+1个词出现的比例进行统计,其中XXX为低频词标记;统计结果如表3所示。
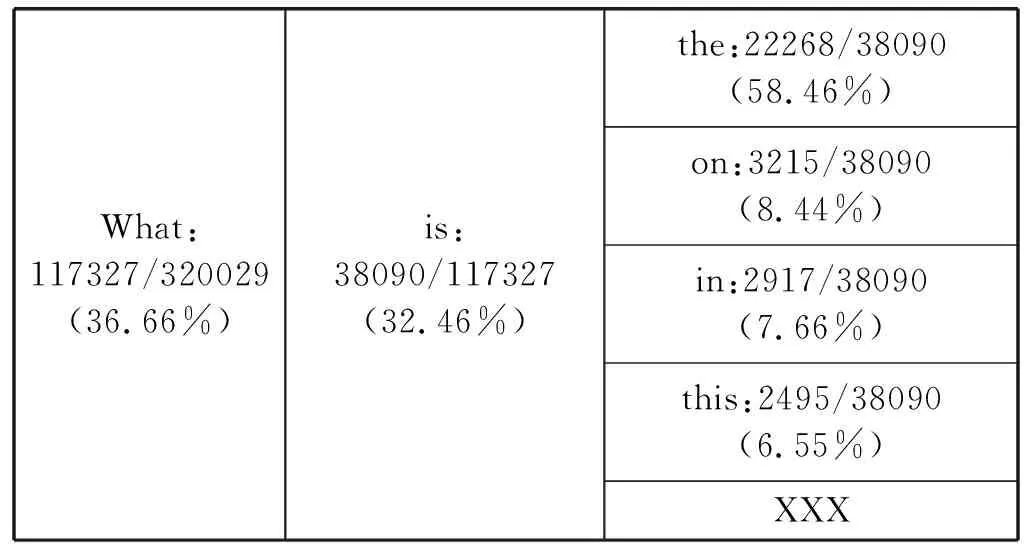
表3 Question前k个词出现的前提下第k+1个词出现的比例
续表3
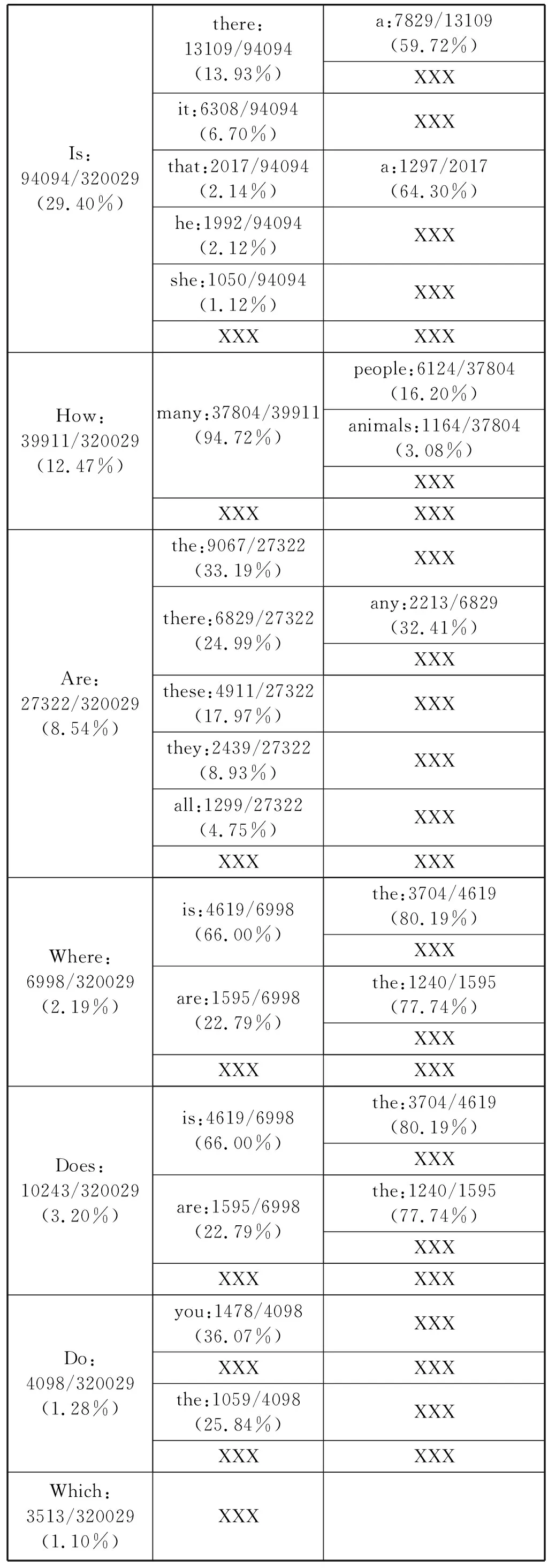
续表3
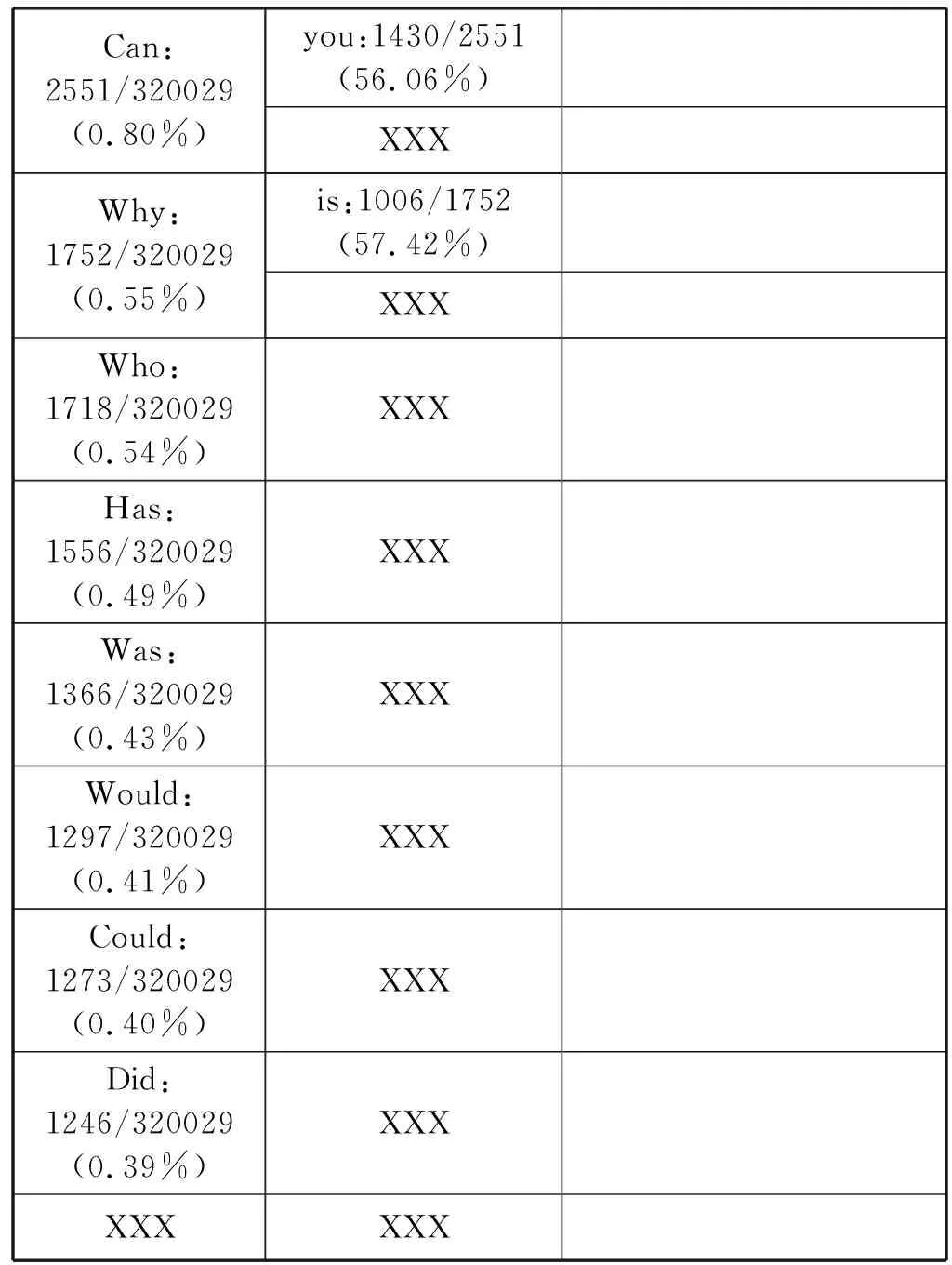
续表3
2) Question部分的分析:
(1) 由表1-表2可以看出,出现次数大于1 000次的高频词只有208个,所占比例非常小,只有1.44%,超过98%的单词出现的次数不足1 000;高频词出现次数占所有词出现次数的比例为82.75%,即出现频率超过80%的单词不到1.5%。
(2) 由表3可以看出,Question的分布非常不均匀,比例非常小的一部分Question问的次数非常多,而大部分Question出现的频率都比较低。
3) Answer部分的统计:
(1) 对Answer的词频进行统计,出现最多的前20个Answer及其次数如表4所示。

表4 出现最多的前20个Answer及其次数
(2) 选取出现次数最多的1 000个Answer,统计对应的Question数量,为320 029个,占Question总数量的320 029/369 861=86.53%。
4) Answer部分的分析:
出现次数前5个Answer占所有Answer出现次数的(86 619+54 664+11 941+6 991+6 756)/369 861=45.14%;出现次数最多的1 000个Answer占所有Answer出现次数的86.53%:可见Answer的分布是十分不均衡的,而且分布很像一个长尾分布,但是只需要1 000个Answer就可以覆盖超过85%的Question。
2.2 数据预处理
通过前一章的数据分析,我们提出一个数据预处理方法:仿聚类法。
首先统计Question里出现的单词词频,得到“高频词”和“低频词”;然后模仿聚类和分类算法的思想,以词频为密度、以问句起始词为类目对问句进行“聚类”和“分类”,在每个类里又使用相同的方式,以词频为密度、以问句第二个词为类目再次进行归类,以此类推,最后会将样本从原空间映射到新空间,直接合并低频样本。
例如:一个经过处理后的样本,低频词汇被xxx替代,样本会变成:question=[′why′,′does′,′the′,′player′,′have′,′one′,′xxx′,′xxx′,′up′,′?′],这是从改变样本着手提高模型准确率的方法,简称为“仿聚类法”。
2.3 模型搭建
模型搭建如下:
1) CcVMS模型:
• 图像通道:VGGNet去除最后的softmax层,将输出的4 096维矩阵展开成4 096维向量,简称CNN Features;VGGNet参数被固定为ImageNet分类而学习的参数,并且在图像通道中不作调整。
• 问题通道:普通的词袋模型:首先利用自然语言处理NLP(Natural Language Processing)的word2vec技术,将问题中的每个单词先转化为一个300维的向量,然后直接将各词的词向量表示加和,作为整个问句的向量表示。此处将获得一个300维的向量作为问句的数字化表达。
• MLP层:将图像通道的4 096维向量和问题通道的300维向量拼接得到4 396维向量,作为多层前馈神经网络(MLP)的输入。多层前馈神经网络包括三个全连接层,每个全连接层包含一个全连接级、一个激活函数级和一个Dropout级,然后连接一个全连接级,将输出的1 024维转化为1 000维,最后作为softmax分类器的输入。
• 输出层:softmax分类器,输出维度同样是1 000。整个模型以交叉熵作为损失函数实现端对端学习。
2) LcVMS模型:
• 图像通道:VGGNet去除最后的softmax层,将输出的4 096维矩阵展开成4 096维向量,简称CNN Features;VGGNet参数被固定为ImageNet分类而学习的参数,并且在图像通道中不作调整。
• 问题通道:同样使用word2vec技术,将问题中的每个单词先转化为一个300维的向量,然后按照句子中单词排列的顺序将每个单词依次输入带有一个隐藏层的LSTM网络,将网络输出的512维向量作为问句的数字化表达。
• MLP层:将问题通道的300维向量作为LSTM的输入,得到512维向量的输出,和图片通道的4 096维向量拼接得到4 068维向量,作为多层前馈神经网络的输入。这里采取拼接而不是点乘或者其他融合,是为了能保持相对原始的信息。多层前馈神经网络的结构设计和模型1相同,只是第一个全连接层的输入维度不一样。
• 输出层:softmax分类器,输出维度同样是1 000。整个模型以交叉熵作为损失函数实现端对端学习。
2.4 结果分析
衡量不同模型性能的指标为准确率,表5为实验对比结果。

表5 不同模型仿聚类法处理前后准确率对比
由于原始数据集的不同Answer数目超过10 000个,这里我们选取出现次数最多的K=1 000个作为最后分类输出;大部分Answer的出现频率极低,如果K太大,低频样本训练不充分,不容易分对,而且可能对高频样本产生干扰,导致高频样本分错;去除这部分低频样本,效果会更好。前边数据集分析提到,Answer的分布是十分不均衡的,而且分布很像一个长尾分布,但是只需要1 000个Answer就可以覆盖超过85%的Question,因此softmax的输出设计为1 000维是合理的。
仿聚类法在样本端对低频样本的输入进行改变,让某些低频样本合并;仿聚类法可以认为是对样本映射到另一个空间,高频的样本从原空间映射到新空间,基本保持不变,而低频样本会进行合并,多个低频样本会映射到新空间的同一个位置;映射到新空间同一个位置的这些低频样本的类标往往不一样,它们的类标最后可能变成一个高频样本的类标,也有可能维持原状;对于前者,这些低频样本会合并到新空间中相近的高频样本;后者则会直接被剔除。
另外,在经过仿聚类法处理的LcVMS模型中,真正率TPR(True Positive Rate)或称为灵敏度(sensitivity)为57.38%。
如前文所述,出现次数最多的1 000个Answer占所有Answer出现次数的86.53%,准确率最高的模型选取了K=1 000,覆盖了86.53%的问题答案,另外还有13.47%的问题是没有答案的,也就是说,这些低频问题的无论选择1 000个答案里边的哪一个,都不是正确的。
真正率的计算公式是:

(1)
真正率计算的是,在属于出现次数最多的K=1 000个Answer里边的样本中,分类正确的比例。
3 图片问答系统
通过对数据集进行分析,搭建模型,我们训练出了LcVMS模型,在测试集上准确率达到44.5%。这里将以模型LcVMS为系统应答逻辑构建了图片问答系统。
3.1 系统设计
系统分为输入端、应答逻辑、存储器后端和输出端四大模块,这样满足功能模块化,并且架构清晰,模块之间解耦;每个模块可以选择不同的部件,这些部件都是可插拔的,可以随时更换。具体如图4所示。

图4 系统模块设计
输入端:输入端可以使用合适的API,比如网页前端上传图片,或者语音API输入Question;这里我们使用简单的终端输入,输入包括图片名在内的图片文件本地存放路径与人工提问的Question,系统会读取图片与Question。
应答逻辑:应答逻辑功能同样可以设计不同的部件来承担。
方案1使用字符串与图片的模糊匹配:当输入图片时,使用修改的VGGNet提取CNN Features,并与数据集所有图片提取出来的CNN Features作比较,用4 096维的向量距离计算匹配度;当输入Question时,数据集的所有Question用编辑距离(Edit Distance)计算匹配度;图片和Question计算出来的匹配度与设定的匹配度阈值作比较,大于阈值,使用最接近的图片和Question对应的回答,小于匹配度,则返回一个“安全的回答”,比如“I don’t know”。
方案2使用2.3节搭建的LcVMS模型,输入的图片使用修改的VGGNet提取CNN Features;输入的Question由word2vec转化为数字化表达,并通过LSTM提取序列特征;两个特征拼接后通过MLP,最后由softmax返回Answer。
方案1需要事先将所有数据集的图片特征提取出来并保存,当输入一个新图片时,提取的新图片特征必须与所有数据集的图片特征进行一次匹配度计算,同时输入的Question也必须与数据集的每个Question计算一次编辑距离,然后计算匹配度。数据集每个图片与Question的匹配度相加后,还要找出最符合的那一个图片和Question,返回相应的Answer。如果数据集每个图片与Question的匹配度相加后都没有超过阈值,那么应答逻辑返回一个“I don’t know”。很明显,第一种方案的计算量非常大,返回Answer的速度非常慢。并且实验表明,准确率比较低。这是因为高频问题匹配度高的样本,往往也是某一类Question对应Answer概率最大的样本。比如,当Question是“How many”一类的问题时,由于数据集样本中“2”这个Answer出现频率大于其他数字,这就导致Answer为“2”的样本匹配度高的概率最大,因此每次提问“How many”这类问题时应答逻辑都会回答“2”。对于低频的问题,由于数据集中所有样本的匹配度都小于阈值,这会使应答逻辑返回“I don’t know”这样一个没有任何意义的Answer。
方案2,LcVMS模型提取输入的图片特征与Question序列特征后,只需要通过神经网络的计算就可以返回Answer。由于LcVMS模型的全连接层少,结构也不复杂,因此应答逻辑的响应比较快,并且有较高的准确率。这里我们选用LcVMS作为应答逻辑的部件。当然,假如以后有更合适的模型,我们可以替换这个部件,不影响其他模块。
存储器后端:存储器后端也可以选用不同的部件。比如,当希望系统有学习能力时,我们可以选用数据库模式,每次输入图片与Question,应答逻辑返回Answer后,我们人工给系统一个反馈,告诉系统Answer是否正确,如果不正确,人工输入一个正确的Answer。数据库模式可以把图片、Question与正确的Answer一起记录下来,扩展原来的数据集。当应答逻辑选用字符串与图片模糊匹配的方式时,也需要数据库模式来存储数据集的样本,才能计算匹配度。我们搭建的模型LcVMS是预先训练好的,所以已经不需要数据集,因此我们这里只选用最简单的只读模式作为存储器后端,即存储器后端不做任何操作。
输出端:输出端我们选用简单的终端输出,即把应答逻辑产生的Answer通过终端输出;如果有合适的API,比如语音合成API等,以后也可以替换。
这样一个完整的图片问答系统,就搭建完成了,具体模块与选用部件如表6所示。

表6 具体模块与选用部件
3.2 系统展示评述
下面对图片问答系统的智能程度进行展示与评估,输入的图片是随机从互联网下载的图片。测试结果如图5-图9所示,“Ask a question”后的字体为人工输入的提问,方括号内的字符是系统的输出,详细QA对正确与否如表7所示。

图5 一个穿红衣白裤的男人在玩飞盘
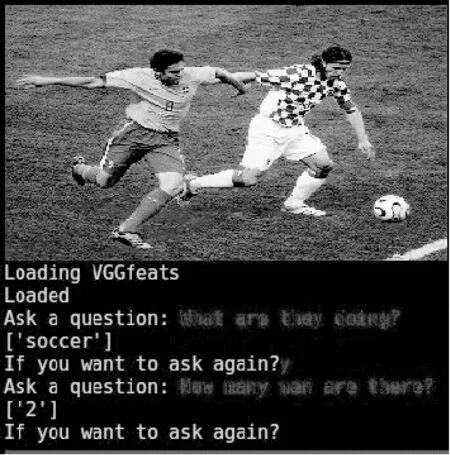
图6 两个男人在踢足球

图7 一张桌子上边放着书和台灯

图8 一个穿白背心的女人在打网球

图9 四个网球

图片QuestionAnswer是否正确图5What is he doing?frisbee正确What color is his clothing?white大致正确Is he playing football?no正确图6What are they doing?soccer正确How many men are there?2正确图7Where is the lamp?on desk正确图8What is she doing?tennis正确What color is her shirt?white正确图9What is this?orange错误How many balls are there?4正确
从以上5个简单测试可以看出,图片问答系统具有一定智能,在一定程度上达到了幼儿智商。首先,问答系统可以识别出应该回答什么:是回答“Yes”或者“No”,还是回答数量、颜色、位置;其次,问答系统回答的准确率看起来要高于44.45%,这是因为上边人工提问的这些Question没有特别古怪或者特别难的问题,只是询问物体、数量、颜色或者位置,而数据集里边的Question,会更多样化一些,详情可以参照2.1节的数据统计与分析。
另外可以看出,系统的回答都很简短,一般都是一个词,少数会用到两个词,这是因为训练集里边的Answer非常简短。对于图片问答,Question一般都是具体询问图片的某一区域,而不是整个图片的所有信息,因此Answer可以用简短的1到3个词回答出来。
4 结 语
我们在对VQA数据集进行统计分析的基础上,提出仿聚类法的数据预处理方法,建立合适的LcVMS模型。LcVMS模型充分考虑模型训练与响应的时间,尽可能提高模型的特征提取和分类速度,更适合作为后台快速响应智能对话。与前人只考虑模型准确率相比,我们兼顾模型与系统,以LcVMS为应答逻辑设计了可应用的图片问答系统。我们随机从互联网下载图片,与人工提出的Question,一起作为图片问答系统的输入,获取Answer,从应用实验角度来评估图片问答系统的智能程度。实验结果表明,图片问答系统能较好地分辨物体、数量、颜色和位置等信息,具有媲美幼儿的智商,具备一定的实用价值。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
商用汽车(2021年4期)2021-10-13
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
作文周刊·小学一年级版(2021年36期)2021-01-14
阅读与作文(小学高年级版)(2020年8期)2020-09-12
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
西南学林(2011年0期)2011-11-12
