
LSTM在煤矿瓦斯预测预警系统中的应用与设计
2018-12-12 09:00李伟山
西安科技大学学报 2018年6期
李伟山,王 琳,卫 晨
(1.西安邮电大学 通信与信息工程学院,陕西 西安 710121;2.西安邮电大学 经济与管理学院,陕西 西安 710121)
0 引 言
能源是国家发展与经济腾飞的动力,在中国一次能源消费结构中,煤炭一直占据着非常重要的地位,因此保证国家战略地位的一个重要因素就是保证国家的能源安全。中国的煤炭矿井多为瓦斯矿井,瓦斯爆炸事故频发,对煤炭行业的安全生产造成了严重的威胁[1-2]。目前煤炭企业对于瓦斯事故的预防还停留在监测阶段,对危险的发现和预防能力不足。因此研究瓦斯变化的规律,利用瓦斯监测数据实现对未来时刻瓦斯浓度的预测,为安全管理人员提供辅助支持,在煤矿安全生产中显得尤为重要。
针对煤矿瓦斯浓度预测问题,国内外许多专家学者做了相关研究。如:张昭昭提出了一种动态瓦斯浓度预测模型[3];赵爱蓉提出了基于小波分析的瓦斯浓度预测方法[4];郝天轩等提出了一种利用灰色关联分析从影响因素中筛选主要因素,结合运用遗传算法(GA)与BP神经网络预测煤层瓦斯含量的方法[5];韩婷婷提出了一种基于马尔科夫残差修正的瓦斯浓度预测方法[6]。这些方法在瓦斯浓度预测研究中起到了一定的作用,但是瓦斯浓度变化受环境因素影响较大,如何挖掘影响瓦斯浓度数据之间的关联关系,建立模型来提高预测准确度与稳定性仍是一个亟待解决的问题[7]。
随着大数据时代的到来和计算机硬件设备的发展,近些年来,LSTM、递归神经网络、卷积神经网络等深度学习技术发展火热,在自然语言处理、语音识别、机器翻译、图像理解等领域都取得了突破性成果[8-12]。LSTM是一种递归神经网络,针对时间序列模型建模能力强,适合处理与时间序列高度相关的问题[13-14]。瓦斯浓度变化趋势与温度、湿度、风流、采煤机工作状态等环境因素相关,这些数据在时间上具有天然的连续性,在前后时间序列上具有很强的相关性和因果性。采用LSTM实现煤矿瓦斯浓度预测,不但可以利用数据在时间维度上的相关性,而且能够自动挖掘数据之间存在的潜在的关联关系,提高瓦斯变化预测的精度。
文中的主要工作如下:采用深度学习技术——LSTM实现了对瓦斯浓度的预测,并研究了不同时间步长、网络深度下的LSTM以及多信息融合对瓦斯预测性能的影响,在2.2.3节通过实验仿真进行了分析论证。结合深度学习服务器对瓦斯预测系统的部署进行了研究,提供了一个结合深度学习服务器来搭建瓦斯预测系统的方案。
1 方案介绍
基于LSTM煤矿瓦斯预测预警整套系统由分布在矿井下的传感器、局部数据采集网络、各种服务器共同组成。其中实时从传感器采集数据部分是依赖煤矿企业现有的瓦斯监测系统,本套系统只需要从煤矿的数据网络中获取到瓦斯、温度、CO浓度等实时数据即可,如图1所示。
系统从整体上将矿井下的工作环境分为若干个工作区域,例如分为302工作面风流、302工作面回风流、302工作面回风隅角、105高抽巷掘进工作面风流。每个区域布置一套传感器设备,系统定时从传感器采集数据到瓦斯预测系统,系统根据实时的环境信息及历史信息对下一时刻或者若干时刻的瓦斯浓度信息进行预测并且对预测结果进行判断,若超标则通过警报系统通知管理人员。

图1 系统布局Fig.1 System layout
2 LSTM瓦斯预测算法
2.1 LSTM神经网络
1997年Hochreiter与Schmidhuber提出了长短时记忆网络(Long Short Term Memory,简称LSTM),通过刻意的设计去除梯度消失和梯度爆炸问题,解决了长期依赖的问题[15-16]。
图2中,Xt-1,Xt,Xt+1为输入序列;ht-1,ht,ht+1为隐藏层状态;圆圈为逐点计算;tanh为tanh函数(双曲函数);矩形框为神经网络层;δ为sigmoid函数。LSTM单元内“门”的结构是通过一个sigmoid神经网络层和一个逐点乘法操作实现的。LSTM网络外部具有RNN循环,内部还具有“LSTM cell”循环(自环)[17]。LSTM模型由一个个LSTM单元构成,如图2所示。LSTM单元上面的直线代表了LSTM的状态,这条直线穿过所有串联在一起的LSTM单元,按顺序依次从第一个LSTM单元流向最后一个LSTM单元,通过3种门(输入门、遗忘门、输出门)来控制和维护LSTM单元的状态信息。LSTM关键在于引入了单元状态(cell state),如图3中Ct-1,Ct所示,凭借对单元状态信息的修改和存储,可以对历史信息记忆,实现信息长期依赖与记忆。
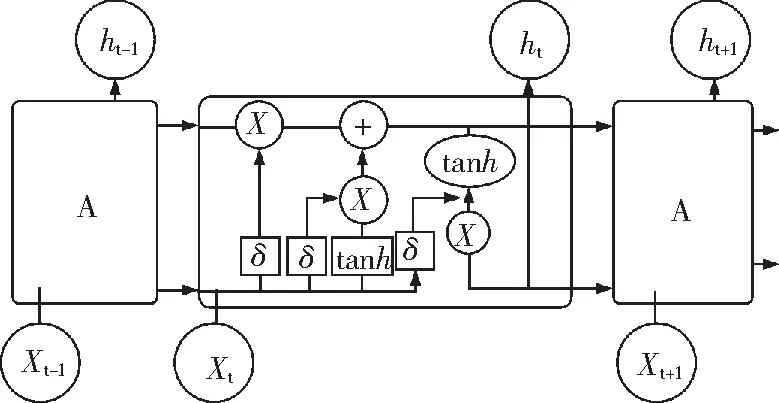
图2 LSTM结构示意Fig.2 LSTM structure
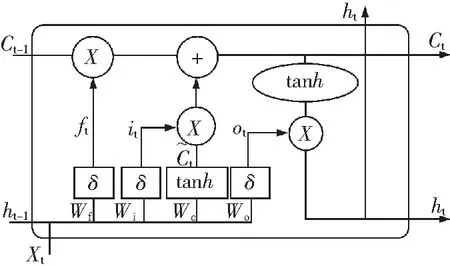
图3 LSTM单元结构Fig.3 LSTM cell structure
如图3所示,图中ft为遗忘门(forget gate);it为输入门(input gate);ot为输出门(output gate)。Ct-1,Ct表示t-1,t时刻的单元状态。每一个LSTM单元有3个输入:当前时刻的输入Xt,上一时刻LSTM的输出ht-1和上一时刻的单元状态Ct-1;2个输出:当前时刻的输出值ht和单元状态Ct.LSTM内部通过3个门控制单元状态,从而实现信息的丢弃、更新以及状态的更新。LSTM单元内部传输方式如下所示
第一步:通过忘记门(forget gate)实现从单元状态cell中保留和丢弃信息;
ft=δ(Wf·[ht-1,xt]+bf)
(1)
第二步:确定存放在单元状态cell中的信息。这里通过2步实现:首先,“输入门层”也就是sigmoid层决定要更新的值;其次,tanh层创建一个新的候选值加入到cell中。如公式(2)、(3)所示;
it=δ(Wi·[ht-1,xt]+bi)
(2)
(3)
第三步:通过输出门和单元状态cell,确定LSTM单元的输出值。如公式(4)、(5)所示。
ot=δ(Wo·[ht-1,xt]+bo)
(4)
ht=ot·tanh(Ct)
(5)
LSTM整个网络的训练采用梯度下降和反向传播算法。LSTM输入数据xt,网络前向计算每个神经元的输出值,即图3中的ft,it,ct,ht,ot每个向量的值,计算方法为公式1到5.输出的ht与标签进行比较得到误差,根据误差反向计算每个神经元的误差项σ的值;其中反向传播沿2个方向:一个沿时间方向,一个将误差项向上一层传播。根据响应的误差项,计算每个权重的梯度,使用梯度下降算法更新网络参数权重,即更新图3中Wf,Wi,Wc,Wo的权重。
2.2 瓦斯预测模型
2.2.1 LSTM瓦斯预测
瓦斯预测可以理解为:根据已有的历史记录来计算将来的变化趋势而得到一种数学映射,通过m点历史数据预测未来q点的变化趋势。影响瓦斯浓度变化的因素多,变化趋势复杂,无法通过简单的线性关系实现预测。瓦斯浓度变化趋势与温度、湿度、风流、采煤机工作状态等环境因素相关,这些数据在时间上具有天然的连续性,在前后时间序列上具有很强的相关性和因果性。文中通过建立LSTM瓦斯预测模型自动挖掘瓦斯数据的变化趋势与这些影响因素之间潜在的、暗含的内在关联关系,来实现瓦斯浓度变化的预测。
文中将瓦斯历史监测数据和影响瓦斯变化相关因素的监测数据共同作为LSTM网络的输入,输出瓦斯浓度变化趋势的预测。同时这是一种基于多传感器监测信息融合的预测方法[18],能够更加准确预测其瓦斯变化趋势。以时间步长为50,隐藏层神经元数量为200,3层的LSTM网络结构为例,如图4所示。
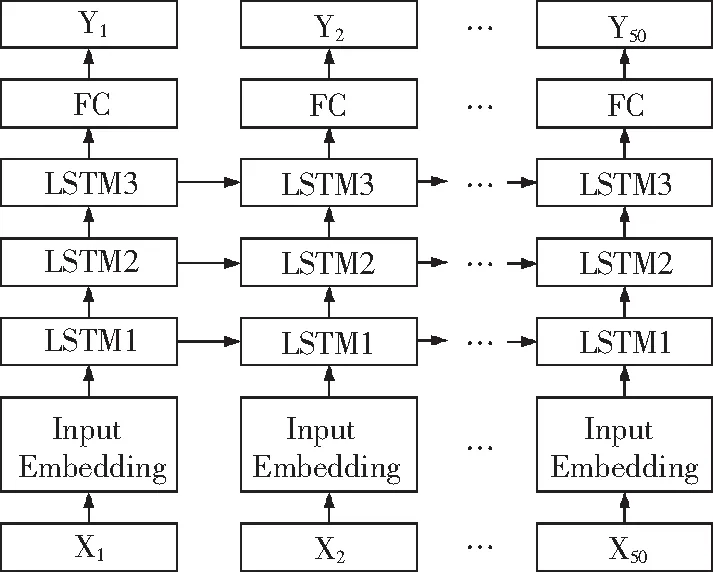
图4 时间步长为50,层数为3的LSTM网络结构Fig.4 LSTM network structure diagram with 50 timesteps and 3 layers
LSTM网络输入的数据首先经输入嵌入层(input embedding layer)映射为200维的向量,该向量作为LSTM单元的输入,每一层LSTM单元的输出作为下一层LSTM单元的输入,最后一层LSTM单元的输出经全连接层(FC)映射成一个一维的数据,即实现了瓦斯浓度的预测。

(6)
(7)
2.2.2 模型的训练与分析
实验数据来自淄矿集团亭南煤矿正常生产期间的302工作面监测数据,选取了2016年10月1日至2016年11月30日共计17 568条数据,其中包含了瓦斯浓度、CO浓度、温度、湿度、风流、采煤机工作状态、烟雾6个因素,采集的平均时间间隔为1次/5 min.瓦斯浓度按时间序列顺延一个时刻作为训练网络的标签,数据集共计17 567条数据。选取前16 000条为训练数据,后1 567条为测试数据。
模型将瓦斯浓度、CO浓度、温度、风流、采煤机工作状态、烟雾6个因素作为输入,下一时刻的瓦斯浓度作为输出。数据送入神经网络之前需要经过标准化处理,文中选择偏差标准化方法,如公式(8)所示。
(8)
文中模型训练的硬件配置如下:CPU型号:i5-6500;显卡型号:Nvidia-1070;内存:16 GB.采用TensorFlow深度学习框架进行模型的训练,输入时间步长为m的历史数据,预测下一时间点瓦斯浓度。网络训练中超参数的设置,选用深度学习中常用的训练策略:学习率的初始值设置为0.001,dropout设置为0.5用来抑制过拟合,batch size为20,训练次数2 000次,每500次调整一次学习率(在原有学习率基础上乘0.1),优化方法采用Adam[19]。
时间步长代表了LSTM能够利用的瓦斯序列长度,是数据关联长度的一个反应;为了研究时间步长对模型的影响,设置LSTM网络层数为2,隐藏层节点数量为200,对比了时间步长为5,50,100下的性能,实验结果如图5,6所示和见表1.
通过上述实验结果可知,随着时间步长的增大,模型的预测能力不断的提升;但是当增加到一定程度之后,模型精度反而降低了。时间步长代表了数据在时间序列上的关联长度,由图6可直观看出当时间步长设置过短时会因为数据之间关联信息不足而导致模型拟合效果较差;当过长时,数据冗余造成数据之间关联性下降而导致模型的精度下降,同时也容易导致过拟合,降低模型的泛化能力。因此时间步长的选择尤为重要。
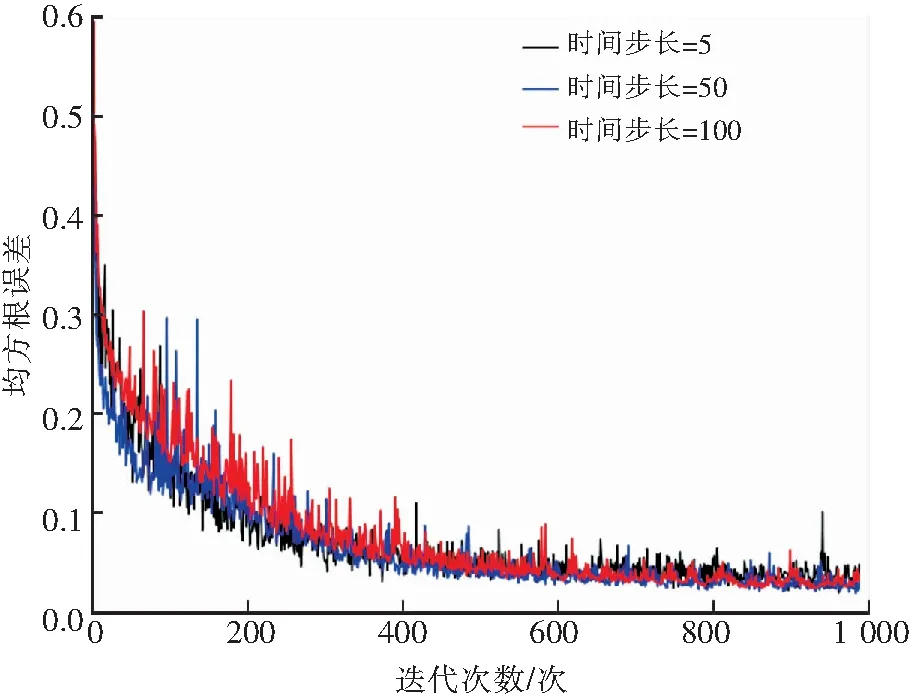
图5 不同时间步长下的损失函数下降曲线Fig.5 Loss function curve at different time steps

图6 不同时间步长瓦斯预测模型性能对比Fig.6 Performance comparison of gas forecast models at different time steps
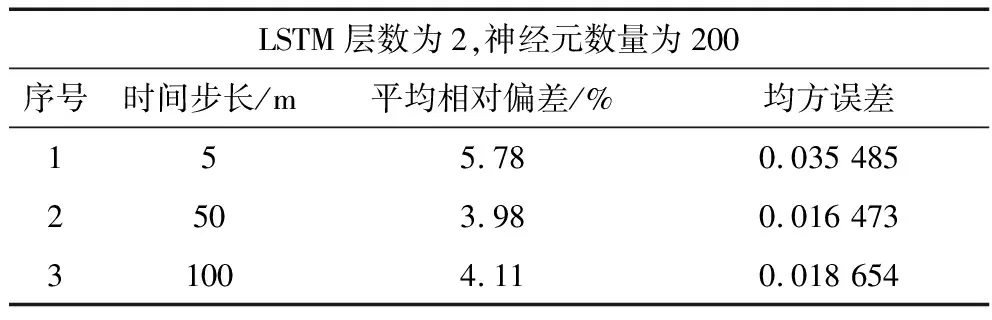
LSTM层数为2,神经元数量为200序号时间步长/m平均相对偏差/%均方误差155.780.035 4852503.980.016 47331004.110.018 654
LSTM网络前一层的输出作为后一层的输入,理论上层数越深,学习能力越强,但是模型越深,会导致模型复杂度变高,难以收敛,训练起来比较困难、耗时等。为此对比了2、3、4层LSTM瓦斯预测模型的性能、训练时长和训练好的模型预测100组数据所耗费的时间,结果见表2和如图7所示。
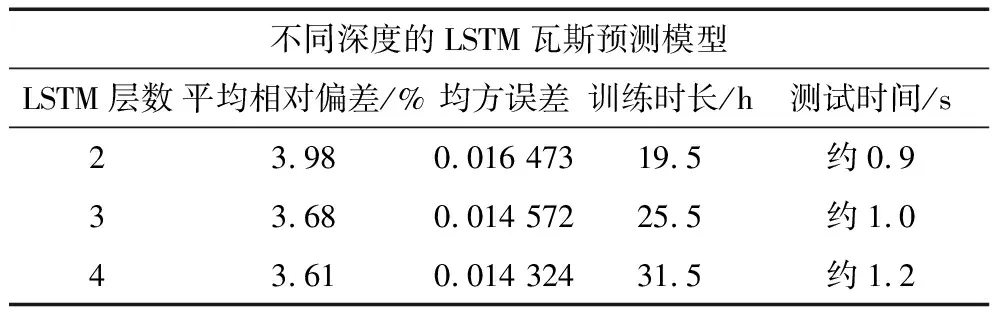
表2 不同深度的LSTM瓦斯预测结果Table 2 Results of LSTM model with different depth

图7 不同深度的LSTM模型损失函数对比Fig.7 Loss function comparison of LSTM models with different depth
由表2和图7可知,网络越深模型收敛的越好,但带来的代价是训练和测试所耗费的时间越长,当模型增加至4层时对性能的提升不太明显,且训练和测试耗费时间太长,为了权衡检测速度和精度同时为了满足工程需要,选择3层的LSTM模型作为文中瓦斯预测系统的模型。
上述的模型采用多变量的输入来预测瓦斯浓度,为了进一步研究多信息融合对瓦斯预测准确率的影响,进一步做了对比试验:网络模型选择3层LSTM网络,神经元数量固定为200个/层,只将瓦斯浓度作为模型的输入和将瓦斯浓度、温度、CO浓度3个监测数据作为输入训练瓦斯预测模型。将训练好的模型在测试集上测试,并与前面训练好的6变量输入瓦斯模型对比,实验结果如图8~10所示。
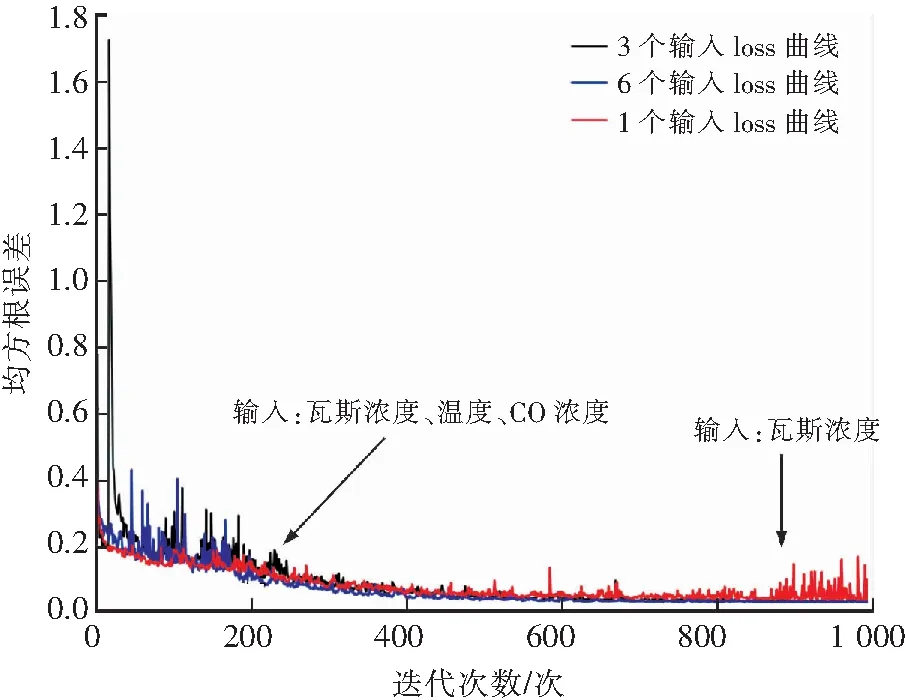
图8 不同输入变量下损失函数变化曲线Fig.8 Loss function curves under different input variables
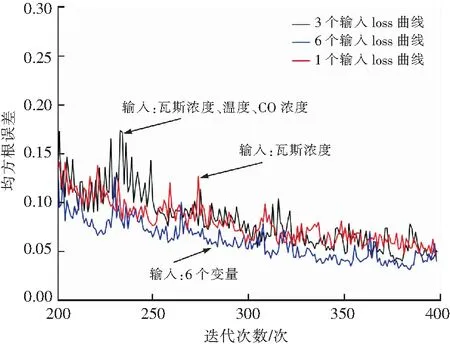
图9 图8局部放大的损失函数曲线Fig.9 Locally enlarged loss function curve
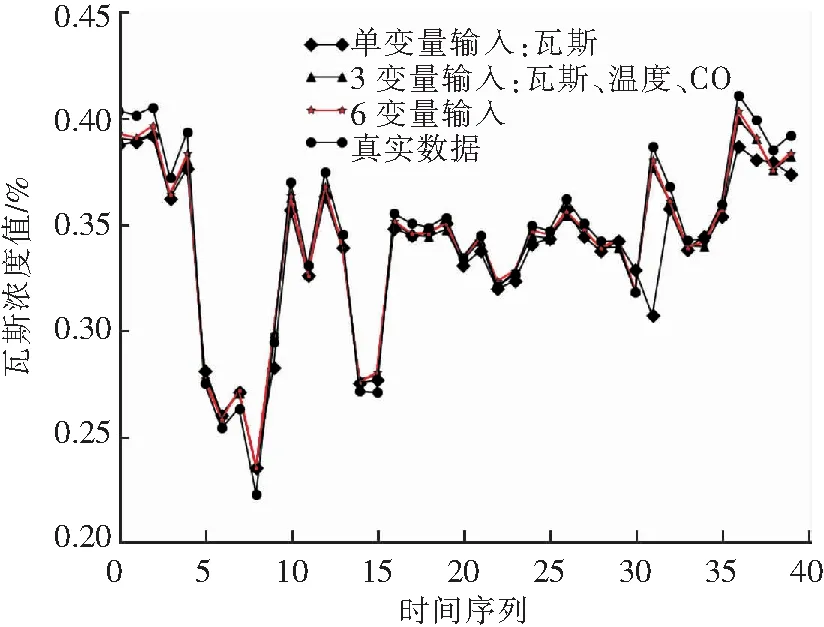
图10 多输入变量瓦斯模型性能对比Fig.10 Multi-input variable gas model performance comparison
由实验结果分析可得,多输入变量的瓦斯预测模型能够通过信息的融合显著提升瓦斯预测的准确率,模型收敛的更好。由图8,9可知,随着输入变量的增多,模型收敛的越来越好;从图10可以直观的看到,单变量瓦斯预测模型性能较差,在某些时间节点的预测出现了严重的滞后性;多变量的瓦斯预测模型能够很好的拟合出瓦斯变化的趋势,其中输入变量越多模型的性能拟合更好。因此多信息融合能够提升瓦斯预测的准确率。
2.2.3 实验结果
如2.2.2节实验所述,分别对比了时间步长、网络层数、输入变量对于瓦斯预测性能的比较,合理的参数设置对模型的预测性能至关重要。时间步长的设置决定了LSTM可以利用的时间序列数据间的关联信息量;网络层数会影响模型的学习能力、训练时间、测试时间;多输入变量信息融合能够提升模型的性能。因此,选择输入变量分别为:瓦斯浓度、CO浓度、温度、风流、采煤机工作状态、烟雾,时间步长为50,3层的LSTM网络模型作为文中瓦斯预测预警系统的算法模块。采用该模型对100条数据进行模型预测,结果如图11所示。
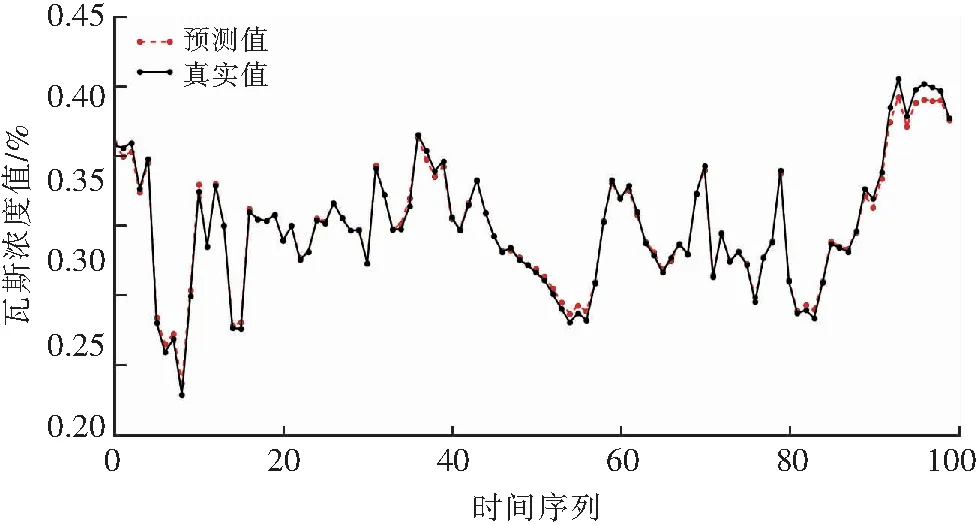
图11 LSTM瓦斯模型预测结果Fig.11 Prediction results of the LSTM gas model
从11图中可直观看出,3层多输入的LSTM瓦斯预测模型能够预测瓦斯浓度变化趋势,拟合效果较好,可作为煤矿瓦斯安全监测预警系统的算法支撑,在文中实验所用设备平台上预测该100条数据时间花费了大约1 s.
3 系统设计
TensorFlow Serving[20]是一种用C++编写的高性能开源服务系统,专为生产环境而设计,能够简化并加速模型,它能实现在服务器架构和API保持不变的情况下,安全地部署新模型并运行[21];使用训练好的模型来实施应用——基于客户端呈现数据的预测,同时引入的开销非常的小。文中,训练好的LSTM瓦斯预测模型部署在TensorFlow Sering服务器中运行,当需要进行预测的时候客户端只需要将历史数据发送到TensorFlow Serving服务器并接收返回的结果,如图12所示。在本系统中客户端即是瓦斯预测预警服务器。
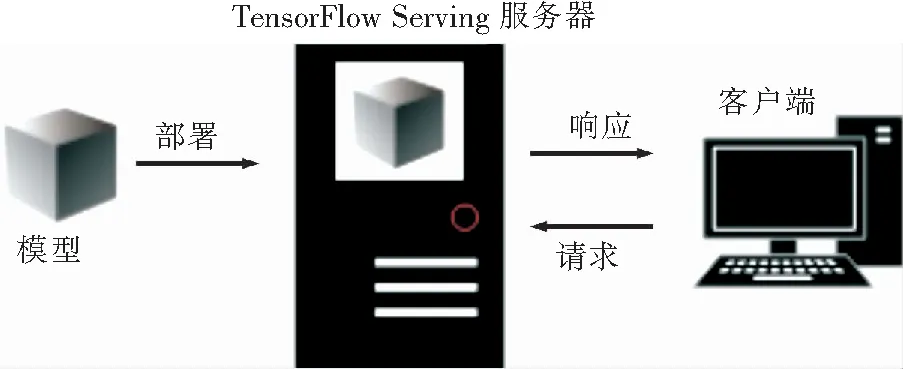
图12 TensorFlow Serving交互模型Fig.12 TensorFlow Serving Interaction model
3.1 系统拓扑结构
如图13所示,该系统是煤矿原有瓦斯监测监控系统的拓展,将原有系统抽象成一个瓦斯数据库,并在该系统上添加多台服务器进行协同工作。添加的服务器分别是瓦斯预测预警服务器、TensorFlow Serving服务器、消息队列服务器,其中瓦斯预测预警服务器是整个系统的核心,采用Spring[22],SpringMVC[23-24],Hibernate[25]搭建,负责获取数据、预测、并控制报警设备;消息队列服务器采用阿里云ONS服务,负责进行警报消息的转发;TensorFlow Serving服务器使用LSTM模型进行瓦斯数据的预测,数据的传输与发送采用的是谷歌远程调用协议(Google Remote Procedure Call,简称GRPC)。
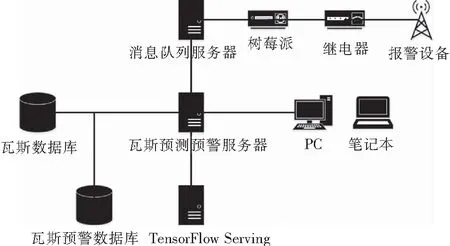
图13 系统拓扑结构Fig.13 System topology
3.2 系统总体架构
煤矿瓦斯预测预警系统结合了多种技术层次和多种功能系统,这些系统通过共享矿井的数据中心协同工作,为煤矿的安全生产提供保障[14]。根据系统总体架构将系统分为3层,如图14所示。
3.2.1 基础层
基础层主要指的是基础设施。包括网络连接,硬件设备等。
3.2.2 支撑层
主要指应用支撑平台,直接为应用层提供服务[15]。整个支撑层从结构上主要分为:瓦斯预测预警服务器、消息队列服务器、TensorFlow Serving服务器3个部分。
3.2.3 应用层
该层直接面向用户,是系统与用户的中间接口。用户可在这一层进行数据查询,瓦斯实时监测,手动报警等操作。
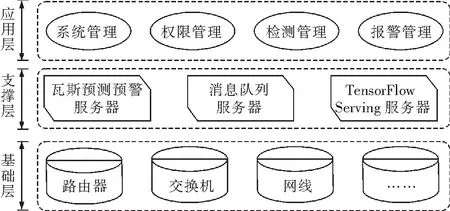
图14 系统总体架构Fig.14 Overall system architecture
3.3 核心业务流程
在本系统中瓦斯预测预警是核心业务流程,如图15所示,瓦斯预测预警流程可总结为:瓦斯预测预警服务器将从瓦斯监测系统的数据库中读取的瓦斯浓度进行格式化处理后发送到TensorFlow Serving服务器;TensorFlow Serving服务器使用LSTM模型对收到的数据进行预测,并将结果返回;瓦斯预测预警服务器将返回的预测值存到数据库并进行判断,若结果显示瓦斯浓度超标,则将警报信息通过消息队列服务器发送到相关工作区域的树莓派,树莓派控制继电器的开关打开,警铃通电开始报警。
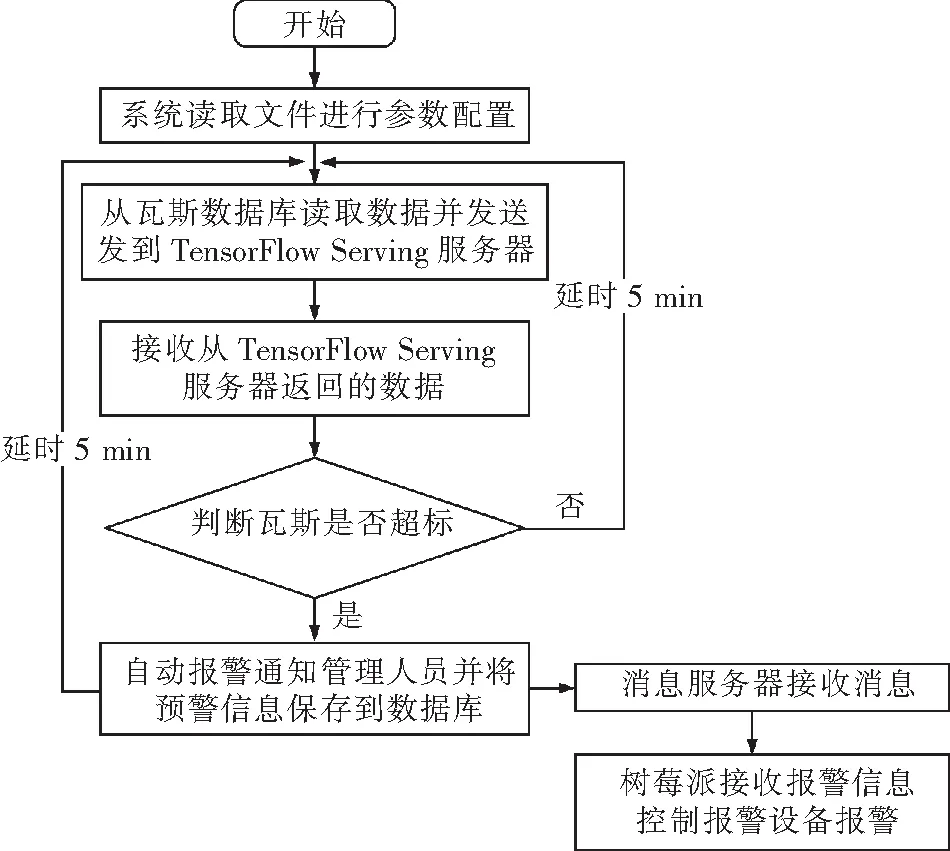
图15 瓦斯预测预警流程Fig.15 Gas forecasting and early warning flowchart
4 误警、虚警处理及时间复杂度分析
由于瓦斯预警算法存在误差,因此系统中存在误警及虚警的现象。针对误警现象:控制区域设计解除警报的按钮。针对虚警现象:系统自动比对上一次的预测结果,若发生虚警现象则保存到数据库,虚警率达到较高的水平的时候则通知工作人员修正模型,提高系统的稳定性和准确性。
该系统主要应用于煤炭企业内部,采用专用网络进行通信,因此系统延迟主要来自瓦斯预测预警服务器及TensorFlow Serving服务器。通过实验统计TensorFlow Serving服务器在并行100组预测任务时延时约为1 s,瓦斯预测预警服务器在(ThinkServer TS250)同时500用户登录可以保持低于5 s的延时,因此可以看出在小于500用户、100个预测任务的情况下,能够保持低于6 s的延时。
5 结 论
1)基于LSTM的瓦斯预测模型构造简单,能够自动挖掘数据间的关联关系,构建出一个最优的模型;LSTM网络的时间步长、深度会影响模型的准确性和速度,需要反复地训练来进行调参;
2)多输入变量的瓦斯预测模型能够通过信息的融合显著提升瓦斯预测的准确率,且模型收敛的更好;
3)该系统是在煤矿原有瓦斯监测系统上的扩展,可提高煤矿安全的预知能力,同时最大化节约企业的成本。
猜你喜欢
肇庆学院学报(2022年5期)2022-09-29
成都信息工程大学学报(2021年5期)2021-12-30
网络安全和信息化(2020年9期)2020-12-31
中国惯性技术学报(2020年2期)2020-07-24
铁道通信信号(2019年9期)2019-11-25
建材发展导向(2019年5期)2019-09-09
网络安全和信息化(2019年8期)2019-08-28
山东工业技术(2016年15期)2016-12-01
网络空间安全(2016年3期)2016-06-15
北京航空航天大学学报(2016年12期)2016-02-27
