
一种基于属性值分布的异构数据对象的相似度计算方法
2018-12-08 06:23:34◆陈姗
网络安全技术与应用 2018年12期
◆陈 姗
一种基于属性值分布的异构数据对象的相似度计算方法
◆陈 姗
(北京天广汇通科技有限公司 北京 100097)
现有的算法无法计算不同类型的对象之间的相似度,本文提出一种基于属性值分布的异构数据对象的相似度计算方法,通过计算异构数据的属性值分布之间的相关度,作为相关属性的权值,再对两个对象逐对计算其属性之间的相似度,使用相关属性的权值进行加权后取和,作为对象之间的相关度。实验证明,本算法在通用性、健壮性,召回率方面都优于现有的方法
异构数据;相似度
0 引言
在机器学习领域,对象相似度作为一个重要课题,被广泛应用在链接预测、欺诈检测等众多实际问题中。随着大数据技术的发展,数据的构成越来越复杂,在比较不同类型的对象时,现有的判断对象之间相似度的方法往往受到对象的属性结构的限制,只能判断属性类型相同或者相近的对象之间的相似度,不能判断异构类型的对象之间的相似度。因此,研究如何对不同类型的对象进行比较,计算其相似度,从而为各种诸如聚类、分类等后续工作提供基础,有着重要的意义。
1 相关工作
目前计算对象相似度的算法主要有以下几种:明可夫斯基距离[1],包含特例欧几里得距离、曼哈顿距离、以及切比雪夫距离,cosine相似度[2],Jaccard相似度[3]。这些方法都是针对相同类型的对象,需要2个对象的属性构成相同,不能计算那些无属性信息的对象之间的相似度。因此,对于由不同属性构成的异构对象,如何计算其相似度,是一个值得研究的课题。
2 算法描述
本算法包含以下4个步骤:
2.1 计算属性的SimHash值
(1)将对象的所有属性转换为文本格式;
(2)用词向量的形式表示属性值
对属性转换得到的文本进行词元化和分词处理。如对象x的属性a取值为v,经过词干化和分词处理后,得到n个词t1,t2,...,tn,那么v可表示为词向量
(3)将词转换成64位长整数
选择一个哈希函数f,将词t转换成64位长整数型的哈希值h:

那么使用(1)可以将v的词向量表示
(4)计算每个哈希值的权重
设数据集中的对象数量为n,哈希值h在m个对象中出现过,则哈希值h的权重wh的计算方法如下:

(5)计算属性值的SimHash值
①设属性值v表示为哈希值的向量

②修改每个数组中的每个元素值,如果为1,修改为其对应的哈希值的权重,如果为0,修改为其对应的哈希值的权重的负值
③对于属性值v创建另一个64位的整数数组s,其每个元素等于所有数组a的相应位置的元素的加和:

2.2 计算两个属性之间的相关度
(1)计算某个属性中的某个属性值的出现概率
设对象类型X包含N个对象,X的属性类型A出现了N个不相同的属性值,第i个属性值v的SimHash值在对象类型X的属性类型A中出现了n次,那么属性值v在对象类型X的属性类型A中的出现概率的计算方法如下:
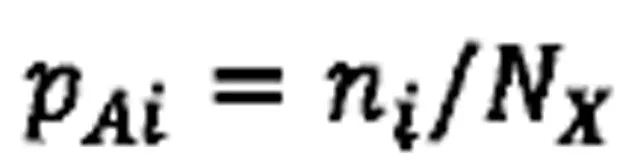
(2)计算两个属性的分布的散度


(3)计算两个属性的相关度
属性类型A和B的相关度计算方法如下:

2.3 计算两个属性之间关系的权重
设对象类型X包含N个对象,对象类型Y包含N个对象,X的属性类型A和对象类型Y的属性类型B中出现了N个不相同的属性值,第i个属性值v的SimHash值SimHash在X的属性类型A和对象类型Y的属性类型B中共出现了n次,那么属性值v在对象类型X的属性类型A以及对象类型Y的属性类型B中的出现概率p的计算方法如下:
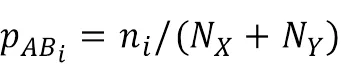
2.4 计算两个对象之间的相似度

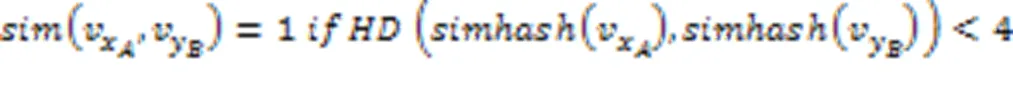


3 实验
为了验证本方法地有效性,我们从某信息系统的数据库中抽取了描述对象“人物”的关于“基本信息”、“教育”、“职业”、“社团”等方面信息的4张表,从每张表中随机抽取了1000行记录,首先使用人工的方式标记出相同人物,再使用本方法计算“基本信息”表中的每行数据和其他3个表中每行数据的相似度,选择“基本信息”表中的某行和其他表中与其相似度最大的行做为候选项,如果相似度大于某阈值,则判度是同一人物。同时,我们也使用欧几里得距离、cosine相似度,Jaccard相似度按照上述方式判断是否为同一人物,以验证本方法的性能。
由于欧几里得距离、cosine距离,Jaccard相似度均需要识别相同维度,我们采用的方法是:如果2个表中列名相同则认为是相同属性,否则认为是不同属性,另外,由于很多属性均是文本类型,我们判断属性值相同的方法是,在去掉停用词之后,如果2个字符串所包含的词相同,则认为这2个属性值相同,否则认为是不同的。
我们统计所发现的同一人物的查准率P和召回率R,其计算公式如下,其中TP表示识别出的样本数,FP表示未识别出的样本数,FN表示识别出的错误样本数:
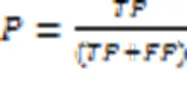
实验结果如表1。
表1 实验结果

对于基本信息表-教育表,基本信息表-职业表,基本信息表-社交表等3种类型的人物匹配,由于其他3种对照方法错误使用了description属性进行判断,导致了查准率和召回率较低,本文提出的方法对各种属性综合考虑,如地址,活动社团等,查准率和召回率都较高。
4 结论
本文提出了一种基于属性值分布的异构数据对象的相似度计算方法,通过计算异构数据的属性值分布之间的相关度,作为相关属性的权值,再对两个对象逐对计算其属性之间的相似度,使用相关属性的权值进行加权后取和,作为对象之间的相关度。在与目前已有的相似度计算方法相比,本方法在通用性、健壮性,召回率方面都有显著地提高
[1]吴丽娟,李阳,梁京章.一种基于明可夫斯基距离的加壳PE文件识别方法[J].现代电子技术,2016.
[2]刘妍.基于Lucene的余弦距离检测文档相似度方法的研究[J].信息系统工程,2014.
[3]潘磊,雷钰丽,王崇骏,谢俊元.基于权重的Jaccard相似度度量的实体识别方法[J].北京交通大学学报,2009
猜你喜欢
中学生数理化·八年级物理人教版(2022年5期)2022-06-05 06:57:38
小学教学研究(2022年5期)2022-04-28 21:29:36
电信科学(2016年11期)2016-11-23 05:07:56
现代工业经济和信息化(2016年2期)2016-05-17 05:34:16
通信电源技术(2016年6期)2016-04-20 06:21:36
工业设计(2016年8期)2016-04-16 02:43:34
中国医学影像学杂志(2015年9期)2015-12-15 11:03:26
计算机工程(2015年8期)2015-07-03 12:20:04
汽车零部件(2014年10期)2014-11-11 12:25:04
导航定位与授时(2014年2期)2014-04-27 13:41:09
