
基于MapReduce的HDFS数据窃取随机检测算法
2018-11-30 05:57高元照李炳龙陈性元
通信学报 2018年10期
高元照,李炳龙,陈性元
基于MapReduce的HDFS数据窃取随机检测算法
高元照1,2,李炳龙1,陈性元1,2
(1. 信息工程大学三院,河南 郑州 450001;2. 密码科学技术国家重点实验室,北京 100094)
为了解决分布式云计算存储的数据窃取检测中,出现数据量大、内部窃取难以检测的问题,以hadoop分布式文件系统(HDFS, hadoop distributed file system)为检测对象,提出了一种基于MapReduce的数据窃取随机检测算法。分析HDFS文件夹复制产生的MAC时间戳特性,确立复制行为的检测与度量方法,确保能够检测包括内部窃取的所有窃取模式。设计适合于MapReduce任意的任务划分,同时记录HDFS层次关系的输入数据集,实现海量时间戳数据的高效分析。实验结果表明,该算法能够通过分段检测策略很好地控制漏检率和误检文件夹数量,并且具有较高的执行效率和良好的可扩展性。
随机检测算法;HDFS;MapReduce;MAC时间戳;云计算存储
1 引言
云计算巨大的优越性使其在全球范围内高速发展[1-2]。其中,“存储即服务(StaaS, storage as a service)”的云计算服务模式是当前被广泛认可的大数据存储方法[3],许多云计算服务提供商如Google、Amazon和Microsoft都提供了云存储服务[4-5]。
云计算存储快速发展的同时,新的安全威胁随之而来。云安全联盟2013年和2016年发布的云计算顶级威胁报告提出数据泄露是云安全面临的最大威胁[6-7]。《中国云计算安全政策与法律蓝皮书(2016)》也披露,近年来云平台的大规模数据泄露事件不绝于耳[8]。数据窃取是造成数据泄露的主要原因之一,并且相比于外部窃取,内部人员往往具有数据访问特权,当前的加密或访问控制等机制不能完全防止内部窃取[9-11],因而给云计算和用户造成的危害更大[12-13],并且难以检测。因此,本文主要研究云存储数据的内部窃取检测方法。
现有的内部窃取检测方法主要分为2类。
1) 基于用户或系统行为的异常进行检测。Stolfo等[9]通过识别系统中入侵用户不同于合法用户的异常数据访问行为模式检测内部数据窃取。Nikolai等[11]依据系统中异常的活动用户数量和传输数据量,检测内部人员对目标机的登录和数据窃取。Pitropakis等[14]基于Smith&Waterman算法识别虚拟机的异常行为,进而检测针对虚拟机的内部攻击。然而,云存储多采用分布式文件系统(DFS,distributed file system)作为主要的文件系统[15],一个完整文件分散存储在多个物理或虚拟节点中,从单个节点窃取数据是不可行的;另一方面,上述方法能够检测的攻击模式需要内部人员登录到目标系统,然而在DFS中内部管理人员能够通过控制节点直接访问存储节点的数据而不需要登录系统。因此,上述方法针对的窃取模式以及对应检测方法不适用于DFS。
2) 基于文件系统元数据,通过检测文件的批量复制遗留的时间戳痕迹,判断数据窃取的发生。这类方法从根本上反映文件系统活动,能够检测包括内部窃取和外部窃取的所有窃取模式。Grier[16]首次提出了通过识别文件时间戳在文件批量复制中的显著特征,检测NTFS数据窃取的方法。但其他文件操作也可能批量更新文件时间戳,造成误报,因而Patel等[17]采用人工神经网络、分类和回归树等方法,对文件复制之外的操作产生的误报进行过滤,提升数据窃取检测的准确率。上述方法面向单磁盘文件系统,而DFS中文件操作的管理和记录方式与单磁盘文件系统差异较大,此类方法无法直接应用,并且云环境下用户量和数据量大,上述方法没有考虑海量时间戳数据的高效分析问题。
为解决上述问题,本文针对HDFS中数据的批量窃取行为,提出一种基于MapReduce的数据窃取随机检测算法。主要工作如下所示。
1) 分析HDFS文件夹复制产生的时间戳特性,建立HDFS行为随机模型,提出HDFS文件夹复制行为的检测与度量方法,即时检测数据窃取活动,并确定被窃取用户的信息。
2) 设计适合于MapReduce分布式处理、同时记录HDFS层次关系的数据集和以文件为数据单元、以文件夹为检测单元的算法执行过程,实现对海量时间戳数据的高效、正确分析。
3) 搭建完全分布式的hadoop框架,测试检测阈值对算法准确性的影响以及数据量和计算节点数量对算法效率的影响,检验了算法的准确率、执行效率和可扩展性。
2 文件系统行为随机模型
Grier提出一种基于文件系统行为随机模型(the stochastic model of file system behavior)的数据窃取检测方法[16]。Grier发现,当文件系统发生文件的批量复制时,被复制文件夹的MAC时间戳统计特性与常规文件访问产生的MAC时间戳变化特性明显不同,并分别用应急模式和常规模式表示。在Grier提出的模型中,MAC时间戳代表文件(或文件夹)的最近修改时间(mtime)、最近访问时间(atime)和创建时间(ctime)。
在常规模式下,文件访问通常是选择性的,只有被访问文件(或文件夹)的发生改变。在应急模式下,文件夹的复制表现为一种一致性行为,该文件夹内所有子文件夹和文件都被复制,引起文件的全部更新(或只更新所有子文件夹的,不同文件系统的更新规则不同)。
不考虑时间戳的恶意篡改,MAC时间戳总是单调递增的。如果一个文件夹被复制,即使在几个月以后,它的MAC时间戳仍将表现出以下特性。
1) 被复制的文件夹和所有子文件夹的都不小于复制发生时间。
2) 大量上述文件夹的近似等于复制发生时间。
3) 在Windows下,文件夹复制不更新文件的。很多文件的通常小于被复制文件夹的。
基于上述特性,Grier提出在NTFS文件系统中,对于一个文件夹和某一特定时刻,若任何子文件夹的都不小于该时刻,并且一定比例的子文件夹的等于该时刻,则称创建了一个“截止簇(cutoff cluster)”。等于该时刻的子文件夹属于截止簇。Grier对一个文件夹中属于截止簇的子文件夹数量及其占总文件夹数的比例进行量化分析,以判断该文件夹是否被复制过。
基于文件系统行为随机模型提出的数据窃取检测算法能够适用于NTFS、Ext4等多种单磁盘文件系统和HDFS、GFS、Gluster等通过MAC时间戳记录文件系统活动的DFS。但不同文件系统的MAC时间戳含义和更新规则不同,量化分析的过程不是通用的。并且,除文件夹复制外,文件搜索和“ls -r”等操作也可能造成文件(或文件夹)的批量更新,对检测准确性造成影响。因此,量化分析过程和数据窃取检测方法需要依据特定文件系统的MAC时间戳特性进行设计。
3 基于MapReduce的数据窃取检测算法
3.1 HDFS时间戳特性量化分析
3.1.1 HDFS时间戳特性分析
HDFS采用一种主从式的架构,一个HDFS集群包含一个NameNode、一个二级NameNode和众多的DataNode[18]。NameNode管理HDFS命名空间,集中存储HDFS的元数据。DataNode用于存储实际的数据。二级NameNode用于执行周期性的检查点机制。HDFS元数据文件有两种形式:FsImage和EditLog。FsImage维护着完整的HDFS元数据映像,记录着文件的MAC时间戳。EditLog是HDFS的事务日志,记录了每个MAC时间戳的变化。
HDFS的检查点机制是在hadoop启动时或每经过固定周期,HDFS将最近更新的FsImage与之后所记录的事务进行合并,创建一个新的FsImage,并删除过期的FsImage。虽然FsImage的数据来源于EditLog,但由于EditLog只能记录两检查点间HDFS的变化情况,它无法反映HDFS中时间戳未发生变化的文件,不能体现某文件夹下文件的整体状态。此外,日志中的事务按照时间顺序记录,密集的时间戳变化可能由多用户同时访问HDFS引起,不能作为文件复制的依据。因此,本文以FsImage作为MAC时间戳的主要来源,进行数据窃取的检测。
与NTFS、Ext4等不同,HDFS只记录文件夹的和以及文件的和。由于在NTFS中对文件夹复制不更新文件的[16],Grier基于文件夹的和对截止簇进行量化分析。在HDFS中,经过实验验证,文件夹的复制会引起该文件夹下所有文件的更新。因此,本文通过文件的时间戳进行截止簇的量化分析。
对于文件的,分析EditLog发现,HDFS在创建文件时,会记录两次时间戳的变化。第一次是创建空文件时,此时的值等于。第二次是当文件创建完后关闭时,发生更新而保持不变。因此,本文假设文件的等于文件创建时的。
3.1.2 截止簇量化分析
首先对文件夹做如下定义








3.2 基于MapReduce的检测算法实现方法
3.2.1 数据预处理
由于FsImage不记录文件的,本文首先基于“文件等于其初始创建时的”的假设,生成文件的。HDFS两个检查点间的文件系统变化存储在单独的EditLog中。在FsImage中,文件(或文件夹)以“”表示,每个具有唯一且单调递增的编号。FsImage记录了本文件内的最大编号。对比最近更新的FsImage和前一个检查点的FsImage,能够得出两个检查点间的新增文件。在最近的已完成EditLog中检索这些文件,能够得出它们的。
另一方面,MapReduce将数据集划分成相互独立的子集(或分片)进行并行处理。为确保作业在数据集上是可以任意划分的,数据集的各数据项之间通常没有内在关联。而HDFS是一个多层次的树形结构,数据窃取的检测也正依赖于文件间的父子关系。由于文件的元数据并不包含其父文件夹的信息,若按照MapReduce默认方式分割任务很可能破坏目录树的完整性,导致分析检测的错误;若按照目录树的分支结构分割任务,不但目录树的遍历会产生额外开销,数据的均衡分割也将带来新的问题。本文设计如下数据项作为MapReduce的输入,以满足MapReduce任意的任务分割。

本文基于文件的时间戳进行窃取检测,每个输入数据项与文件一一对应。_表示文件的编号。将文件所有上层文件夹的编号保存在该文件的数据项中,以inode_表示,表示上层文件夹的个数。每次检查点后,对最新的EditLog和FsImage进行预处理,并把更新的数据集存储在“.csv”文件中。FsImage按照Google protocol buffers的格式对数据进行编码,然后以分隔的方式进行序列化后存储,其解析过程可参考文献[19]。
3.2.2 基于MapReduce的算法过程
MapReduce将复杂的并行计算抽象为2个函数:map和reduce。作业分片由map任务以并行的方式处理,map输出的中间结果由reduce任务进行合并。但集群上的可用带宽限制了MapReduce作业的数量。为减少map和reduce节点间的数据传输,hadoop引入combiner函数。combiner对map的输出在本地节点做进一步简化,但使用combiner需要保证reduce函数的输出不变。本文即采用map、combiner和reduce这3个函数进行数据处理,它们均以键/值对(/)作为输入输出。

算法1 map过程
输入 原始数据集,数据格式为<,>,具体函数中为<_,>。表示数据项中除_外的其他元数据信息。
输出 数据格式为<,>,具体函数中为<_,_>。_是文件上层文件夹的编号,_存储了基于文件、得出的判断结果。
1) map ( const& key, const& value ) {
2)= value.,= value.;
3) 创建数组folder_b[ ]; //存储<文件的上层文件夹的
4) if (>)
5) 跳过,读取下一项;
6) else{

8) for (Pin value.P[ ]) {
9) if not (Pin folder_b[ ]) {
10) 将P添加到folder_b[ ];
11)= inode;
12)__=0; //表示该文件夹没有被复制
13)_._=0; }}} //不关心该文件夹下总的文件数量
14) else if ( (>) && (<+) ) { //文件属于截止簇
15) for (Pin value.inode[]) {
16) if not (Pin folder_b[ ]) {
17)= inode;
18)_=1,=1; }}} //表示该文件被复制
20) for (Pin value.inode[]) {
21) if not (in folder_b[ ]) {
22)=inode;
23)=0,=1; }}} //不确定该文件是否被复制
24) }
25) 输出 (,) ;
26) }
map函数的输出按照值进行排序,即具有相同值的数据项是连续存储的[20],这为combiner函数的执行提供了便利。combiner函数以map函数的输出作为输入,对时刻之前存在访问行为的文件夹进行特殊处理,并统计其余文件夹中属于截止簇的文件数量和时刻存在的总文件数量。具体算法如下所示。
算法2 combiner函数
输入 map函数输出,数据格式为<,>
输出 数据格式为<,>,具体函数中为<,>。是文件上层文件夹的编号,存储了对于相同值(即编号)的值汇总结果。
1) combiner ( const& key, const& value ) {
2) For each key { // 指编号互不相同的
3)=key;
4)= value._,_= value._;
5) if 存在((==0) && (==0)){
6)=0,= 0; }
7) else {
8)= 所有key值相同的项的_的和;
9)= 所有key值相同的项的的和; }
10) 输出 (,) ;}
11) }
combiner函数执行后,map节点将数据传输到reduce节点,并确保具有相同值的数据项被同一个reduce节点处理。在执行reduce函数之前,数据项按值进行排序。

算法3 reduce函数
输入 combiner函数输出,数据格式为<,>;C和M。

1) reduce ( const& key, const& value, floatC, intM) {
2) For each key { //指编号互不相同的
3)= value._,= value._;
4) if存在((==0) && (==0)){
6) else {
7)=所有key值相同项的_的和;
8)=所有key值相同项的_的和;
10) if((_>C) && (>M)){
11)=key;
12) 输出(_, (,,_));}}}
}
除文件复制外,文件系统的其他操作也可能批量更新文件的,产生应急模式,对复制操作的判定造成影响。本文考虑以下5类操作:文件夹加密和压缩、文件搜索和计数以及“ls”命令。HDFS支持文件加密,但加密过程在用户端完成,上传到HDFS中的数据是经过加密的[20]。HDFS能够处理多种文件压缩格式,但压缩操作同样在数据存储前完成,HDFS不提供文件压缩命令。对于搜索、计数和“ls”命令,经实际验证,EditLog不记录这3种操作的发生时间,因此FsImage不会更新文件的。此外,在HDFS中(尤其在云环境下),不同于个人控制的操作系统,用户能够执行的操作较少,本文不考虑由杀毒软件或文件压缩工具等额外工具实现的上述操作。因此可以认为只有正常文件访问和复制对HDFS文件的进行更新。

图1 基于Xen的实验环境架构
4 实验结果与分析
4.1 集群环境
hadoop分布式集群由一个NameNode节点、一个二级NameNode节点和8个DataNode节点组成。集群环境基于Xen虚拟化平台[21]搭建,所有节点是Xen管理下的虚拟机。Xen平台建立在一台浪潮服务器上,如图1所示。服务器、集群节点、Xen和hadoop的配置如下。
服务器配置:型号为NF5280M4;CPU为E5-2620v3共2个;内存为96 GB;硬盘为3 TB;操作系统为Ubuntu 12.04 LTS 64位;IP为192.168.122.1。
集群节点配置:Intel Core I5双核CPU@2.6 GHz;4 GB内存;200 GB硬盘;操作系统为CentOS 6.5 x86_64;域1~域10 IP地址为192.168.122.10~ 192.168.122.19。所有节点配置到其他各节点的SSH无密码登录,以便于命令与数据的自动化交互。
Xen配置:版本为4.1;hypervisor为64位。
hadoop配置:版本为2.6.0稳定版;数据块大小为128 MB;复制因子为3。在HDFS中创建10个用户:hadoop(在NameNode上创建),sec-hadoop(在二级NameNode上创建),user1~user8(在8个DataNode上创建)。其中,hadoop为超级用户。
4.2 数据集
本文采用人工生成的数据集进行测试。生成过程如下:在2017年3月1日,10个hadoop用户分别上传文件到HDFS,每个用户的文件数量超过100万个,总文件量超过1 500万。文件类型主要为txt、jpg、doc等小文件。在实验室条件下,为仿真云平台中大的用户量和频繁的数据访问,在创建文件后,将数据的访问过程持续30天,以增加文件操作的数量。文件访问行为遵循帕累托分布[22](即大多数的文件访问集中于少量文件,大多数文件在被上传后没有被访问)。在此期间,随机选择10个时刻对部分文件夹进行复制,以产生截止簇。
访问过程结束后,从二级NameNode中获取存储有测试文件信息的EditLog和最近更新的FsImage。由于用户的数据访问请求提交给NameNode,从二级NameNode上获取元数据,能够减轻数据传输给hadoop的正常运行造成的影响。将提取的文件信息按照式(8)的格式生成数据集,存储在“.csv”文件中。本实验中,数据集中的数据条目达15 008 320条,数据量为953 MB。
4.3 截止簇检测阈值的影响

表2 测试文件夹构成信息

由于FsImage默认1小时更新1次,从文件创建完成时开始,待检时刻以1小时为间隔递增,检测30天中出现的所有文件复制行为,并对正确检测的文件夹个数、漏检个数、误检个数进行统计。被复制的文件夹从A~J依次编号。其中,user2的文件夹下包含20个子文件夹,选择其中的2个进行复制,分别用D-1和D-2表示。表2表示A~J中大于对应M的子文件夹的个数(包括自己)。
依据各文件夹在不同M()段的子文件夹数量,选取A、C、G和H,展示不同C和M组合下的算法准确率,如图2~图5所示。综合全部测试文件夹的检测结果,针对不同C,各个M()段的整体漏检率如表3所示。由于在实验过程中没有进行其他文件复制,算法检测到的其他复制行为全部属于误检。针对不同C,各个M()段的文件夹错误检测个数如表4所示。

图2 A文件夹在不同Cf和Mf条件下的算法准确率

图3 C文件夹在不同Cf和Mf条件下的算法准确率

图4 G文件夹在不同Cf和Mf条件下的算法准确率

图5 H文件夹在不同Cf和Mf条件下的算法准确率
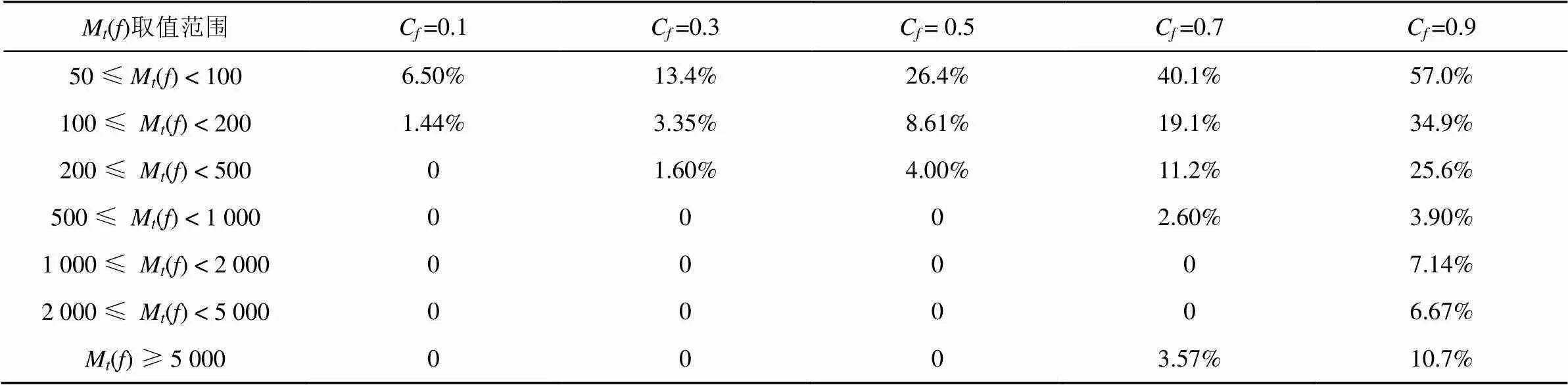
表3 各Mt( f )段不同Cf条件下的整体漏检率

表4 各Mt( f )段不同Cf条件下的误检文件夹个数
分析测试文件夹的检测结果和算法的错误检测结果,得出以下结论。


基于分段检测策略,为控制漏检率和错误检测数量,随着M()的增大,C的上、下限变化如图6所示。

图6 不同Mt( f )段Cf的上、下限范围
被检测出复制行为的文件夹,可通过其编号确定相关联的用户信息。基于相关用户的行为规律和复制发生时间等,能够进一步判断是否发生数据窃取。例如,若截止簇产生在某工作日的上午,可能是由于工作人员在一段时间内对这些文件进行的正常复制;若截止簇产生在凌晨时分,则发生数据窃取的可能性较高,进一步分析执行复制操作的用户(或云内部人员)的行为规律,若发现他之前没有在凌晨访问被复制文件的记录,则可将该人员视为可疑人员,对其本地终端或移动终端进行取证分析,获取更深层次的证据,证实是否发生了数据窃取。
4.4 数据集数据量及计算节点数据的影响
本节测试数据量和计算节点数量对算法执行时间的影响,以检验该算法的可扩展性。原始数据集设为,数据量为953 MB。测试数据量以表示,分别取的1倍、2倍、4倍和8倍。多倍数据量通过对复制生成。测试节点数以表示,取值1、2、4和8。针对每个、组合,进行10次实验,计算算法的平均执行时间,测试结果如表5所示。
从表5中可以看出,当=时,除=1外,节点数越多,执行时间反而越长。这是由于一个分片通常对应一个HDFS数据块(本文设为128 MB),一个map或reduce任务分配的内存默认为1 024 MB,因此一个节点最多能同时处理4个任务。当数据量相对于节点数量过小时,计算资源无法充分利用,而数据在4或8个节点上存储相对于2个节点更加分散,任务的调度花费更多的额外开销。当计算节点数量刚好满足需处理的数据量时,任务调度开销最小。

表5 算法执行时间/s
随着的增大,MapReduce的多节点并行处理特性逐渐显示出优势。针对相同的数据量,本文将多节点相对单节点执行效率的加速比作为衡量可扩展性的指标,图7展示了=4和=8时的加速比,此时8个计算节点都能得到充分运用。其中,当=4且=8时,MapReduce平均每秒处理超过113万条数据,加速比值为7.39,表现出良好的可扩展性。云存储的用户量和数据量巨大,并且随着云计算的发展不断增大,由HDFS元数据生成的数据集的存储和处理将产生巨大的开销,利用MapReduce以分布并行的方式实现数据窃取的检测算法能够显著提高检测效率。

图7 Q=4S和Q=8S时的算法执行加速比
5 结束语
面对云存储的大数据量,内部人员窃取难以高效检测是云存储数据窃取检测的难点问题。本文以HDFS为检测对象,提出了一种基于MapReduce的数据窃取随机检测算法。量化分析HDFS文件夹复制产生的独特时间戳特性,确保能够检测恶意内部人员以合法权限发起的数据窃取,及时发现被窃取的数据范围及其所属用户。依据文件夹包含的文件数量采用分段检测的策略,通过合理设定检测阈值,能够有效控制漏检率和误检文件夹数量。利用MapReduce的并行处理能力,通过设计适合于MapReduce任务划分的数据集和算法执行过程,算法具有较高的效率,并且在MapReduce框架下具有良好的可扩展性。
[1] 中国信息通信研究院. 云计算白皮书[R]. 北京: 中国信息通信研究院, 2016. China Academy of Information and Communication Technology. White Papers of Cloud Computing[R]. Beijing: China Academy of Information and Communication Technology, 2016.
[2] 张玉清, 王晓菲, 刘雪峰, 等. 云计算环境安全综述[J]. 软件学报, 2016, 27(6): 1328-1348. ZHANG Y Q, WANG X F, LIU X F, et al. Survey on cloud computing security [J]. Journal of Software, 2016, 27(6): 1328-1348.
[3] CHANG V, RAMACHANDRAN M. Towards achieving data security with the cloud computing adoption framework[J]. IEEE Trans Services Computing, 2016, 9(1): 138-151.
[4] MARTINI B, CHOO K K R. Cloud storage forensics: owncloud as a case study[J]. Digital Investigation, 2013, 10(4): 287-299.
[5] LI Y, GAI K, QIU L, et al. Intelligent cryptography approach for secure distributed big data storage in cloud computing[J]. Information Sciences, 2017, 387: 103-115.
[6] ALVA A, CALEFF O, ELKINS G, et al. The Notorious nine: cloud computing top threats in 2013[R]. Cloud Security Alliance, 2013.
[7] BROOK J M, FIELD S, SHACKLEFORD D, et al. The treacherous 12 - cloud computing top threats in 2016[R]. Seattle: Cloud Security Alliance, 2016.
[8] 中国云计算安全政策与法律工作组. 中国云计算安全政策与法律蓝皮书(2016)[R]. 上海: 中国云计算安全政策与法律工作组, 2016.Cloud Computing Security Policies and Laws Group. Cloud computing security policies and laws blue book (2016)[R]. Shanghai: Cloud Computing Security Policies and Laws Group, 2016.
[9] STOLFO S J, SALEM M B, KEROMYTIS A D. Fog computing: mitigating insider data theft attacks in the cloud[C]// IEEE Symposium on Security and Privacy Workshops. 2012: 125-128.
[10] SRIRAM M, PATEL V, HARISHMA D, et al. A hybrid protocol to secure the cloud from insider threats[C]// IEEE International Conference on Cloud Computing in Emerging Markets. 2014: 1-5.
[11] NIKOLAI J, WANG Y. A system for detecting malicious insider data theft in IaaS cloud environments[C]// 2016 IEEE Global Communications Conference (GLOBECOM). 2016: 1-6.
[12] SUBASHINI S, KAVITHA V. A survey on security issues in service delivery models of cloud computing[J]. Journal of Network & Computer Applications, 2011, 34(1): 1-11.
[13] ROCHA F, CORREIA M. Lucy in the sky without diamonds: Stealing confidential data in the cloud[C]// IEEE/IFIP International Conference on Dependable Systems and Networks Workshops. 2011: 129-134.
[14] PITROPAKIS N, LYVAS C, LAMBRINOUDAKIS C. The greater the power, the more dangerous the abuse: facing malicious insiders in the cloud[J]. Cloud Computing 2017, 2017: 156-161.
[15] MARTINI B, CHOO K K R. Distributed filesystem forensics: XtreemFS as a case study[J]. Digital Investigation, 2014, 11(4): 295-313.
[16] GRIER J. Detecting data theft using stochastic forensics[J]. Digital Investigation, 2011, 8(8): 71-77.
[17] PATEL P C, SINGH U. A novel classification model for data theft detection using advanced pattern mining[J]. Digital Investigation, 2013, 10(4): 385-397.
[18] SHVACHKO K, KUANG H, RADIA S, et al. The hadoop distributed file system[C]// 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST). 2010: 1-10.
[19] GAO Y, LI B. A forensic method of efficient file extraction in HDFS based on three-level mapping[J]. Wuhan University Journal of Natural Sciences, 2017, 22(2): 114-126.
[20] WHITE T. hadoop: The definitive guide (3th Edition) [M]. Sebastopol: O'Reilly Media, Inc, 2015.
[21] BARHAM P, DRAGOVIC B, FRASER K, et al. Xen and the art of virtualization[C]// ACM SIGOPS Operating Systems Review. 2003: 164-177.
[22] MACKAY E B, CHALLENOR P G, BAHAJ A S. A comparison of estimators for the generalised Pareto distribution[J]. Ocean Engineering, 2011, 38(11): 1338-1346.
Stochastic algorithm for HDFS data theft detection based on MapReduce
GAO Yuanzhao1,2, LI Binglong1, CHEN Xingyuan1,2
1. Third Academy, Information Engineering University, Zhengzhou 450001, China 2. State Key Laboratory of Cryptology, Beijing 100094, China
To address the problems of big data efficient analysis and insider theft detection in the data theft detection of distributed cloud computing storage, taking HDFS (hadoop distributed file system) as a case study, a stochastic algorithm for HDFS data theft detection based on MapReduce was proposed. By analyzing the MAC timestamp features of HDFS generated by folder replication, the replication behavior’s detection and measurement method was established to detect all data theft modes including insider theft. The data set which is suitable for MapReduce task partition and maintains the HDFS hierarchy was designed to achieve efficient analysis of large-volume timestamps. The experimental results show that the missed rate and the number of mislabeled folders could be kept at a low level by adopting segment detection strategy. The algorithm was proved to be efficient and had good scalability under the MapReduce framework.
stochastic detection algorithm, HDFS, MapReduce, MAC timestamp, cloud computing storage
TP311.1
A
10.11959/j.issn.1000−436x.2018222
高元照(1992−),男,河北衡水人,信息工程大学博士生,主要研究方向为云计算取证、大数据安全。

李炳龙(1974−),男,河南卫辉人,博士,信息工程大学副教授、硕士生导师,主要研究方向为数字取证。
陈性元(1963−),男,安徽无为人,博士,信息工程大学教授、博士生导师,主要研究方向为网络与信息安全。

2017−09−27;
2018−07−03
国家高科技研究发展计划(“863”计划)基金资助项目(No.2015AA016006);国家自然科学基金资助项目(No.61702550)
The National High Technology Research and Development Program of China (863 Program) (No.2015AA016006), The National Natural Science Foundation of China (No.61702550)
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
北京大学学报(自然科学版)(2021年3期)2021-07-16
装备制造技术(2020年2期)2020-12-14
电脑爱好者(2020年19期)2020-10-20
电脑报(2020年35期)2020-09-17
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
电子制作(2019年13期)2020-01-14
电脑爱好者(2017年21期)2017-12-04
电脑爱好者(2017年15期)2017-08-31
中国卫生(2015年12期)2015-11-10
