
基于关联规则的海量重复数据消除系统设计
2018-11-30 05:37连雁平
现代电子技术 2018年23期
连雁平
(武夷学院,福建 武夷山 354300)
0 引 言
在应用系统处于正常运行状态时,电子数据的平均重复比率大约为60%,且随着系统运行时间的不断增加,电子数据的重复比率也逐渐增大。为避免因大量数据堆积而导致系统运行速度降低现象的发生,现阶段主要通过特定重复数据消除系统完成数据重复比率的降低处理[1]。这种普通的重复数据消除系统利用Deduplication技术手段,对重复数据进行多次消冗处理,通过整理数据的方式,确定电子数据中重复部分所占的物理存储空间,再设立特定网络占用带宽,对该部分物理存储空间内的电子数据进行无差消除处理。这种重复数据消除系统主要应用于HTML页面或小型网络处理系统[2]。这类应用对象普遍存在运行数据总量有限、对系统响应时间要求不高等特点,这也是导致传统系统出现重复数据吞吐量可控性较差、相似判断处理完成时间过长等现象的主要原因。为更好地解决传统系统存在的普遍问题,引入数据序列关联规则,对系统的软件模块进行改进设计,再通过增设冗余纠正模块等流程,对系统的硬件部分进行改进设计。通过模拟仿真实验数据对比的形式,突出新型重复数据消除系统的实用性价值。
1 基于关联规则海量重复数据消除系统硬件设计
新型海量重复数据消除系统的硬件部分设计主要包括总体框架设计、重复数据冗余纠正模块设计、模块通信接口设计三个方面,具体搭建流程可按如下步骤进行。
1.1 总体框架设计
基于关联规则海量重复数据消除系统的硬件总体框架包括重复数据检测模块、总吞吐量提升模块、消除可靠性保证模块、系统安全模块四个主要环节。其中,重复数据检测模块包括相同数据检测和相似数据检测两个方面,且两者所针对的检测对象也都不相同。总吞吐量提升模块具备提高差分压缩属性、增强相似数据搜索速度等多项功能[3-4]。消除可靠性保证模块可根据电子数据的重复情况,完成分块冗余数据的复制及纠错处理。系统安全模块可以保证电子通信数据的传输可靠性,并降低信息泄露事件的发生几率。详细硬件框架结构如图1所示。

图1 新型数据消除系统硬件框架结构图Fig.1 Hardware framework diagram of the new data elimination system
1.2 重复数据冗余纠正模块设计
新型消除系统的重复数据冗余纠正模块利用网络协议的Chunk功能,完成海量数据中重复部分的吞吐量确定。通常情况下,应用系统的总存储空间有限,而随着系统运行时间的逐渐延长,电子数据发生重复现象的几率也随之增大,这也是导致系统运行速度逐渐减慢的主要原因[5]。为避免上述情况的发生,将重复数据冗余纠正模块与系统消除可靠性保证模块直接相连,通过改变OceanStore连接状态的方式,使模块与模块间始终保持高效连通状态。新型海量重复数据消除系统在传统系统的基础上,增设重复数据冗余纠正模块,并利用该模块对海量数据的限制作用,解决重复数据吞吐量可控性较差的问题[6-7]。具体模块设计原理如图2所示。
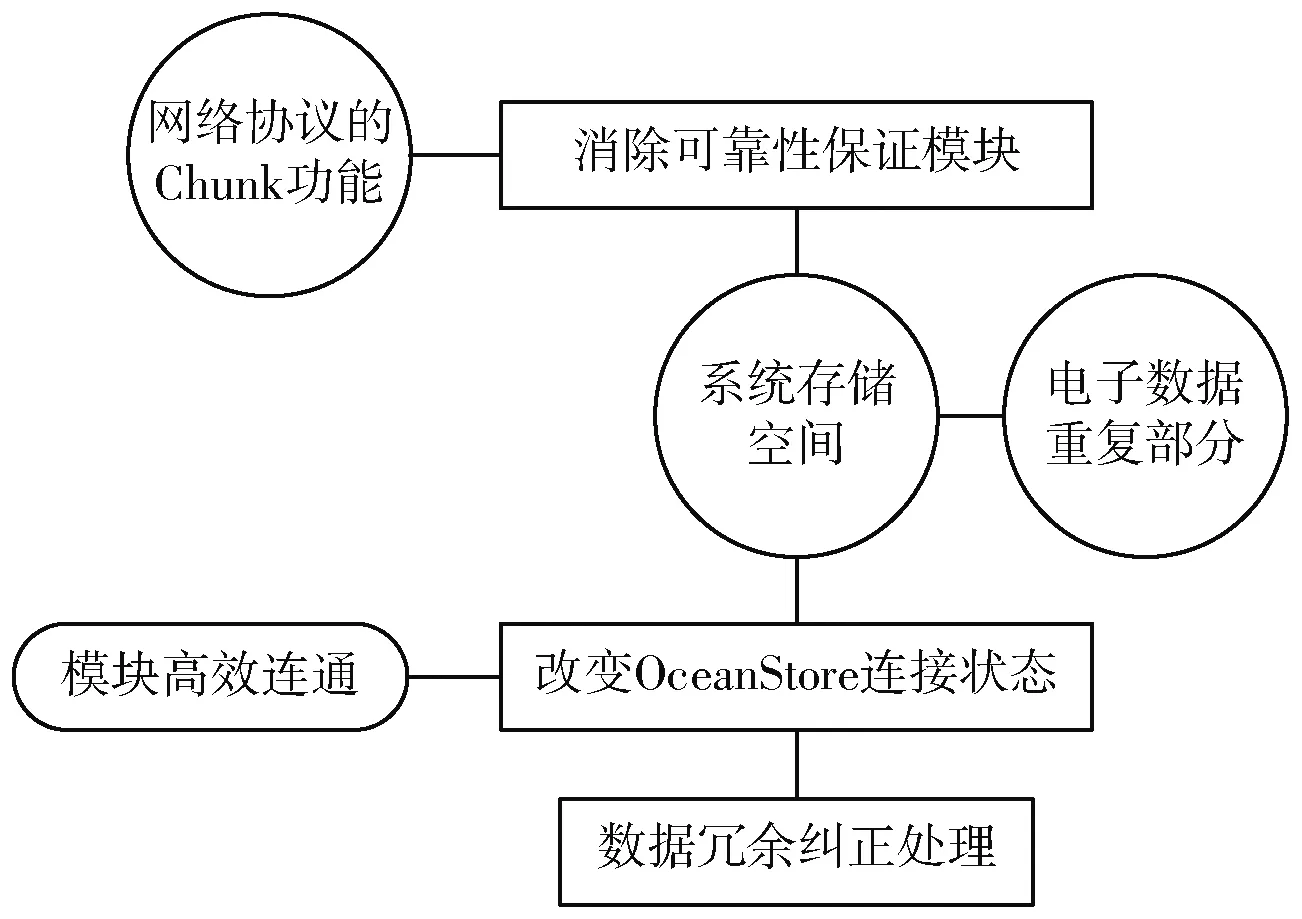
图2 重复数据冗余纠正模块设计原理图Fig.2 Design principle of redundancy correction module for repeating data
1.3 模块通信接口设计
新型海量重复数据消除系统的模块通信接口可实现重复数据冗余纠正与软件数据库的实时连接。为保证通信接口长时间维持连通状态,外接继电模块为接口直接提供220 V的直流电压。为保证模块通信接口的运行稳定性,离子生成装置持续提供带电量为5 C的正负电子,保证通信连接线周围在具有带电粒子的同时,也始终维持总电荷量[8]为0。新型模块通信接口以ZGA20RS79.6设备作为核心搭建环节。ZGA20RS79.6设备是一种具有急速连接属性的硬件核心装置,这也是新型系统能够保持较快相似判断完成速度的主要原因。具体接口设计原理如图3所示。

图3 模块通信接口设计原理图Fig.3 Design principle of module communication interface
2 基于关联规则海量重复数据消除系统软件设计
新型消除系统的软件模块由数据序列关联规则设计、重复数据检测编码设计、海量重复数据消除流程设计三部分组成,具体搭建流程可按如下步骤进行。
2.1 数据序列关联规则设计
数据序列关联规则是新型海量重复数据消除系统建立的软件基础。传统数据消除系统以NetBEUI传输协议作为核心运行基础。NetBEUI(NetBios Enhanced User Interface)数据基础传输保障协议具备通信传输效率高、网络邻居间距小等优势。但随着系统运行时间的增加,这种短小精悍的传输协议不能在短时间内完成数据间的相似性判断,并根据判断结果确定电子数据中的重复部分在总物理存储空间中所占比重,进而导致相似判断完成时间过长现象的发生[9-10]。为解决此问题,新型海量重复数据消除系统应用TCP/IP,NetBEUI,IPX/SPX三种协议相结合的方式,完成基础数据序列关联规则的建立[11]。这种新型关联规则不仅能够充分发挥NetBEUI协议传输效率较高的优势,也能结合TCP/IP协议局域稳定性强、IPX/SPX协议连接响应水平稳定等属性,使新型海量重复数据消除系统的相似判断完成时间始终维持在较低水平。上述三种传输协议的具体应用优势如表1所示。

表1 数据序列关联规则组成情况Table 1 Composition of data sequence association rules
2.2 重复数据检测编码设计
新型消除系统的重复数据检测编码可针对完全相似数据、部分相似数据、完全不相似数据进行区别操作。在对系统中的数据进行检测编码处理时,相应的编码模块认定完全相似数据为重复数据,部分相似数据为疑似重复数据,完全不相似数据为普通电子数据[12-13]。针对重复数据进行的检测编码处理以Delta原理作为主要的代码编写依据,这类的编码过程与霍夫曼编码不同,其操作流程的主要对象为数据的引脚,对其他数据成分不进行规范限制,具体编程代码如下:

针对疑似重复数据进行的检测编码处理以Bloom Filter原理作为主要的代码编写依据。Bloom Filter原理认为,在疑似重复数据中,与目的检测项目完全重复部分所占比重过低,因此该类型数据不满足消除要求。针对普通电子数据进行的检测编码处理依然沿用霍夫曼编码过程,且这类编码操作自动默认普通电子数据不满足系统消除要求。
2.3 海量重复数据消除流程设计
新型系统的海量重复数据消除流程设计完全遵循三种网络通信协议相结合的数据关联规则,并利用重复数据检测编码,保证流程的顺利运行。该流程以重复数据整理作为起始环节,且所有经过整理的数据结果直接以数据包的形式传送至消除引擎[14],再由消除引擎按照关联规则对重复数据进行重新排列,消除数据与数据间的通信联系。完成上述操作的重复数据,已经初步满足清除规则,再由特定消除模块对这些数据进行深度对比分析,将其中残存的疑似重复数据或普通电子数据全部分离出去,并暂存剩余数据[15]。完成上述操作后,该模块会自动运行Delete指令,完成新型系统的重复数据消除处理,具体运行流程如图4所示。

图4 海量重复数据消除流程图Fig.4 Flow chart of massive repeating data elimination
3 实验结果与分析
上述过程完成基于关联规则海量重复数据消除系统的搭建。为验证该系统的应用价值,以2台配置X95软件的计算机作为实验对象。随机挑选出一台计算机作为实验组,搭载基于关联规则海量重复数据消除系统;另一台作为对照组,搭载传统消除系统,分别记录两组计算机的相关实验参数。
3.1 重复数据吞吐量可控性对比
系统的重复数据吞吐量可控性与WQP指标间始终保持反比关系。随着WQP指标的升高,系统的重复数据吞吐量可控性逐渐降低。图5,图6分别反映了实验组、对照组WQP指标的变化情况。
分析图5可知,随着系统运行时间的增加,实验组WQP指标的最大值始终不能达到40%。分析图6可知,随着系统运行时间的增加,对照组WQP指标的最大值可以超过70%。由此可得,实验组系统的WQP指标恒小于对照组,即实验组系统的重复数据吞吐量可控性恒大于对照组。
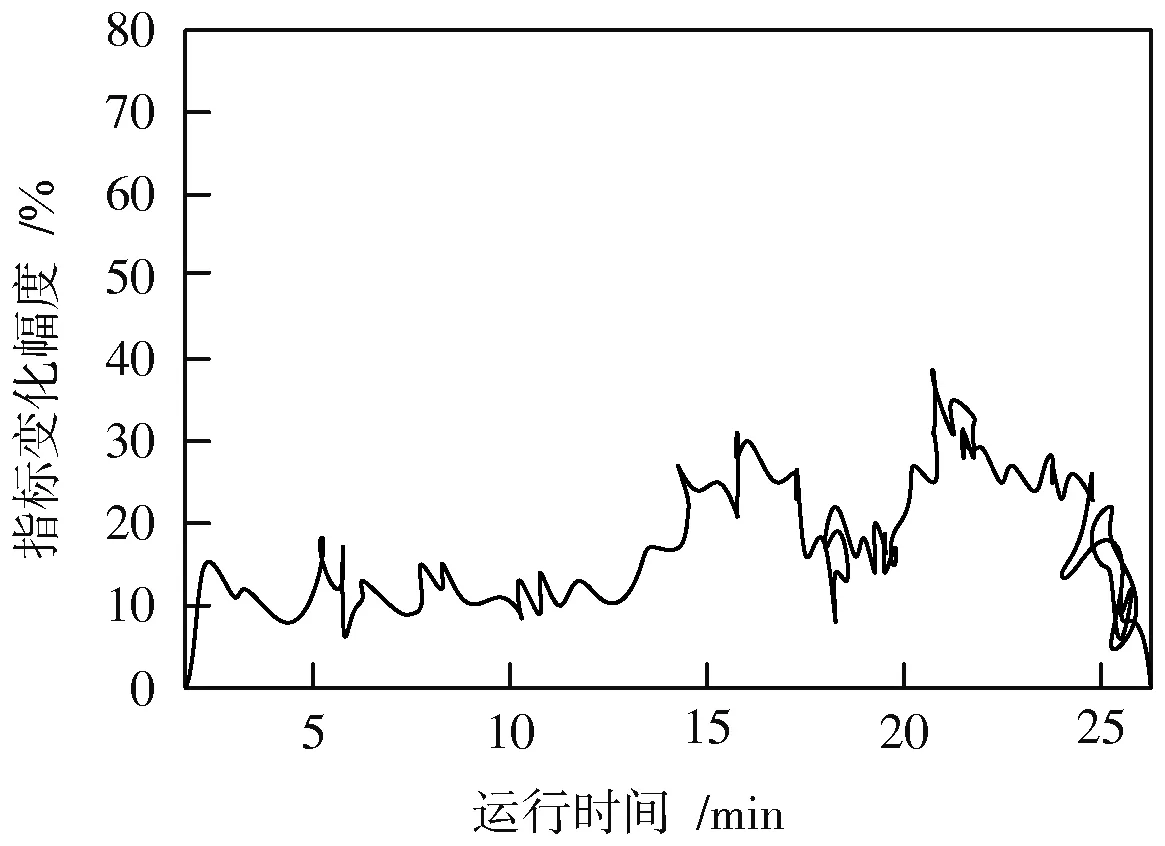
图5 重复数据吞吐量可控性对比图(实验组)Fig.5 Comparison chart of controllability of repeating data throughput(experimental group)

图6 重复数据吞吐量可控性对比图(对照组)Fig.6 Comparison chart of controllability of repeating data throughput(contrast group)
3.2 相似判断完成时间对比
完成系统重复数据吞吐量可控性对比后,令实验组、对照组计算机同时处理总量为5.0×104KB的重复数据,分别记录两组相似判断处理的完成时间。具体实验情况如图7,图8所示。
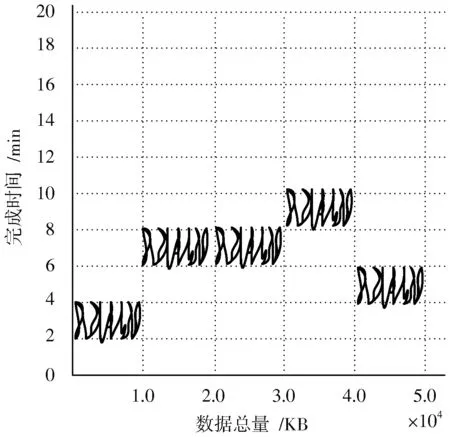
图7 相似判断完成时间对比图(实验组)Fig.7 Comparison chart of completion time of similarity judgment(experimental group)

图8 相似判断完成时间对比图(对照组)Fig.8 Comparison chart of completion time of similarity judgment(contrast group)
分析图7可知,实验组相似判断处理的完成时间最大值出现在重复数据总量为4.0×104KB的时刻,该值的变化范围保持在8~10 min之间。分析图8可知,对照组相似判断处理的完成时间最大值出现在重复数据总量为4.0×104KB和5.0×104KB的时刻,该值的变化范围保持在16~18 min之间。由此可得,实验组系统相似判断的完成时间恒小于对照组。
4 结 语
基于关联规则海量重复数据消除系统在保持传统系统优势的情况下,针对存在的问题进行有效改进设计。对比实验数据显示,新型系统确实比传统系统具备更强的实用性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新世纪智能(数学备考)(2021年9期)2021-11-24
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
当代陕西(2019年15期)2019-09-02
当代陕西(2019年14期)2019-08-26
疯狂英语·新读写(2018年3期)2018-11-29
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
