
基于语义的主题网络舆情挖掘系统模型研究
2018-11-29 02:33余宏
现代计算机 2018年31期
余宏
(豫章师范学院数学与计算机学院,南昌 330103)
0 引言
随着网络技术的进步,特别是移动互联网应用的普及,使得社会生活得各个方面都与互联网息息相关。中国互联网络信息中心(CNNIC)2018年1月发布的统计信息显示:截至2017年12月,中国网民规模达7.72亿,其中移动手机用户人数达7.53亿,互联网应用普及率达到55.8%。与传统媒体相比,新闻网站、博客、论坛、微信等网络媒介交互性特征突出,特别是随着移动互联网应用的迅速普及,社会民众参与网络言论传播变得前所未有的便利,互联网成为当今社会重要的舆情载体。只有及时把握住舆情信息,了解和掌握民众的诉求和意见,对初露端倪的不良舆论苗头进行有效抑制,才能发挥前瞻性,掌握网络舆论引导的主动权。而传统对舆情的人工处理方法对于网络上海量增长的舆情信息来说是不适用的,必须借助信息技术手段对网络上的舆情信息进行快速而有效的采集、分析并生成辅助决策的知识。
舆情信息挖掘的任务主要包括舆情热点话题检测、话题追踪、舆情观点分析,这些任务主要通过舆情信息聚类和分类来实现。舆情信息聚类和分类的效率和准确程度,对舆情热点话题检测和追踪有着重要的影响。现有的舆情监测系统在进行舆情分析时大多采用基于统计和特征关键词的方法,由于未考虑舆情文本中的语义信息往往导致分析结果不够准确。本文将本体论和语义计算技术引入网络舆情挖掘以提高舆情挖掘系统的性能。
1 基于语义的网络舆情挖掘系统模型
基于语义的主题网络舆情挖掘系统主要包括网络舆情数据采集、领域本体库的构建、舆情数据预处理、语义特征抽取转换、舆情挖掘等关键功能。
(1)网络舆情信息采集模块
网络舆情信息的来源主要包括:网络论坛、新闻网站、博客与微博等,网络舆情信息在表现形式上包括文字、图片、音视频,其中以文字信息为主。
由于网络舆情管理者往往只关注某一领域的舆情信息,因此,在对网络舆情进行采集时,根据用户定制的某个主题利用聚焦爬虫有针对性的爬取主题相关的网页信息。
(2)领域本体库的构建模块
本体是领域概念模型的显式表示。本体通过它的概念集及其所处的上下文来刻画概念的内涵。本体的目标是获取、描述和表示相关领域的知识,提供对该领域知识的共同理解。
在舆情分析中,本体的最终目标是精确地表示那些隐含的或者不明确的信息。通过应用本体来消除同词异义、多词一义及词义模糊等现象,从而完成对领域知识清晰、准确、完整的定义与描述。
在对主题网络舆情分析中,所涉及的知识包括通用知识和主题相关的领域知识。目前在国内外已有许多现成的本体库可以免费获取,如国内的知网库(HowNet),国外的常识知识本体OpenCye等。我们在做主题网络舆情分析的本体应用时,通用知识本体可以通过复用现有的知识库如HowNet来获得,而与舆情主题密切相关的领域本体通过本体构建工具Protégé进行构建。
(3)数据预处理与语义特征转换模块
传统上通过网络爬虫获得的网络舆情信息经过分词处理后,依据词袋模型生成文本特征向量,该方法忽略了文本特征项之间的语义关系、存在同义词和一词多义等问题。将文本关键词映射到本体中的类、属性、实例等相关项上,将被映射到的不同层次的概念作为主题网络舆情文本信息的语义特征,可以解决上述问题并提高相似度计算的准确程度。
(4)舆情挖掘模块
在前面将文本特征项映射为概念之后,该模块涉及如何计算两个概念之间的语义相似度,并以此为基础利用分类和聚类算法进行网络舆情挖掘处理。
通过对系统各个模块的分析,本文将基于语义的网络舆情挖掘系统模型构建如图1所示:
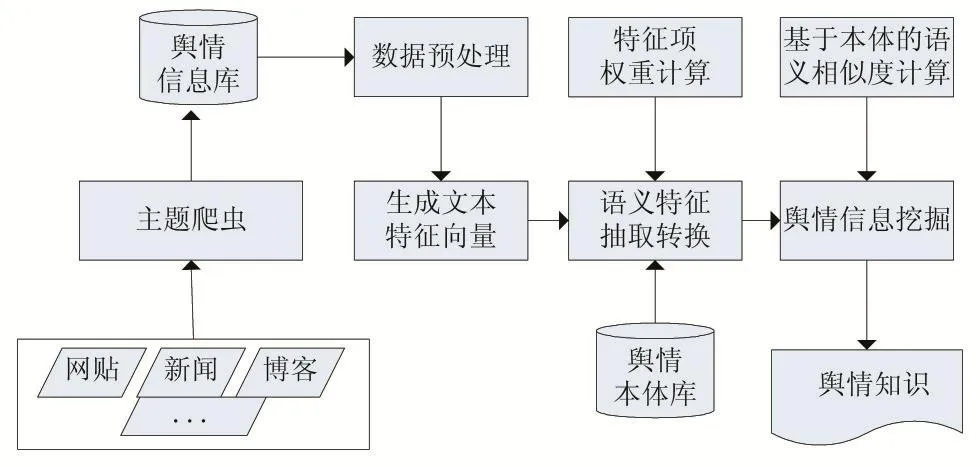
图1 基于语义的主题网络舆情挖掘系统模型框架
2 基于本体的网络舆情挖掘关键技术
2.1 网络舆情信息的语义特征建模
主题网络舆情分析主要是对当前互联网上主题方面的热点话题进行内容分析,主要采用文本聚类和分类技术进行话题的检测和跟踪。传统的文本聚类和分类方法通常将文档用关键词特征向量来表示,文档D1和文档D2之间的内容相关度通常用表示文档的两向量之间夹角的余弦值表示。该方法没有考虑深层次的语义信息,例如不同关键词表示相同的概念、相关的关键词共现表示同一个主题等,导致聚类和分类结果的准确性大大降低。因此,将基于本体的主题网络舆情模型引入聚类和分类过程中,以概念语义相似度为核心进行主题网络舆情信息的聚类和分类,能够提高舆情挖掘的效率和挖掘结果的精确度。
(1)语义特征抽取
语义(Semantic)即数据的含义,是对数据符号的解释。语义特征,就是指能够在语义层面上解释文本内容且定义规范的术语词汇。本体中的类、属性、实例以及关系等概念可以作为网络舆情信息文本的概念特征,通过这些概念代替文本关键词来描述文本,进而根据概念之间的相关度来计算概念所描述的文本之间的相似度,该方法可用于解决“一词多义”、“异词同义”等问题,有利于提高文档相似度计算的准确度。
主题网络舆情语义特征抽取分成两个步骤:第一步是基于关键词的舆情信息特征项选择,主要是根据TF-IDF方法选取文档中权重较大的N个特征词形成一个N维特征向量来表示文档;第二步是在关键词特征项选择的基础上利用本体和语义词典进行语义特征转换,其基本思想是:采用相应的匹配算法将文本特征关键词与本体和语义词典中的概念进行匹配,如果匹配成功则用概念代替关键词特征项,并将其加入概念特征集合中,如果匹配不成功则保留该关键词特征项另行处理,最后将算法匹配出的概念特征集合中的相同项进行合并,将权值较高的概念特征项保留作为网络舆情文本的语义特征。其中的核心是将文本关键词特征项映射为概念特征项,匹配算法为算法1的描述。
算法1文本关键词映射为本体概念算法
输入:文档关键词特征项集K={k1,k2,k3,…kn};领域本体和Hownet通用本体;
输出:文档的概念特征项集C={c1,c2,c3,…cm}及未匹配的关键词特征向量K'={k1,k2,k3,…kt}
Begin:
1.读取关键词ki,将其与领域本体和通用本体HowNet中的概念、属性或实例进行匹配;
2.ifki与本体库中的类ci匹配,则将ci加入概念特征项集合C;
3.else ifki与本体库中的属性aj匹配,则将aj所属的概念ci加入概念特征项集合C;
4.else ifki与本体库中的实例Ik匹配,则将实例Ik的最低下位概念ci加入概念特征项集合C;
5.else将未能匹配的ki加入未匹配的关键词特征集合K';
6.将概念特征集合C中的相同项进行合并,去除权值较低的概念特征项,保留权值较高的概念特征项。
End.
(2)特征项权值计算
典型的权值计算方法为由Salton提出的词频-逆文档频率(TF-IDF)计算法,其基本思想为:一个词的重要性与它在该文档中出现的频率成正比,与它在整个文档集中包含该词汇的文档数目成反比。TF-IDF计算方法为:

其中,w(i,j)为文本特征项ti在文档Dj中的权重值,tfij表示文本特征项ti在文档Dj中出现的频率,idfj表示特征项ti的逆文档频率。
逆文档频率的计算方法为:

其中,N为文档集中的文档总数,nj表示包含特征项ti的文档数。
因此,综合上述两式,词频-逆文档频率(TF-IDF)典型的计算公式为:

我们在进行主题网络舆情分析时,属于某个主题领域内的典型词应该给予更高的权值。本文的特征项权值计算以TF-IDF为基础,对文本关键词特征项ki,如果ki未能与领域本体进行匹配的特征项,其权重值w(ki)按上述公式(3)计算。如果文本关键词特征项kj能与主题领域内本体库中的概念ck进行匹配,关键词特征项kj则转换为概念特征项ck,ck的权重值w(ck)将在kj的TF-IDF计算方法得出的结果的基础进行适当增加权重。由于各个关键词特征项的tfidf值的大小波动比较大,因此,对关键词特征项kj所转换成的概念特征项ck的权值增加采用相对值,而非绝对值。实验显示,关键词特征项kj转换成概念特征项ck后,ck的权值w(ck)在 kj的权值w(ki)基础上提升50%左右效果较好,这样既能突出领域本体范围内的特征词,同时又不会大幅度影响数据的平衡。为区分关键词特征项kj与本体库中的类、属性、实例等不同层次的项进行匹配产生的概念特征项ck重要性,ck的权值w(ck)在kj的权值w(ki)基础上提升幅度不同,如表1所示。

表1 概念特征项的权值计算
(3)文本表示
在基于本体的主题网络舆情信息语义特征抽取过程中,由于受本体知识覆盖范围等因素的限制,导致部分关键词特征项不能转化为概念特征,但这部分特征项对舆情信息的聚类和分类结果的准确度也有一定影响,因此,本文将舆情文本D表示为概念特征向量VC和未匹配的关键词特征向量VK'。
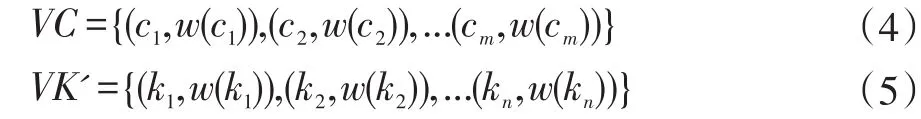
其中,ki是第i个关键词特征项,w(ki)是关键词特征项ki的权重;cj是第j个概念特征项,w(cj)是概念特征项cj的权重。
2.2 相似度的计算
对用向量空间模型(Vector Space Model,VSM)表示的文档,可通过计算向量之间的相似性来度量文档间的相似性,将空间上的相似度转化为语义上的相似度。VSM模型中度量两个文本间的相似度,常常通过计算两个文本向量间的余弦夹角来表示。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,计算公式如下:
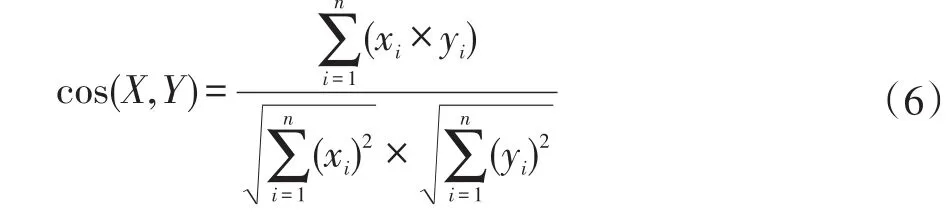
其中,X,Y为两个文本向量,xi和yi分别为向量X,Y的分量。
本文将一个舆情文档D由概念特征向量VC和未匹配的关键词特征向量VK'表示。即D={VC,VK'},其中:VC和VK'分别如公式(4)和公式(5)所示。为了体现关键词向量和本体概念向量对舆情文档相似性的贡献度不同,在计算时,我们将这两个向量分开进行计算。对两个舆情文档 D1和 D2,其概念相似度CSim(D1,D2)和关键词相似度KSim(D1,D2)分别为:
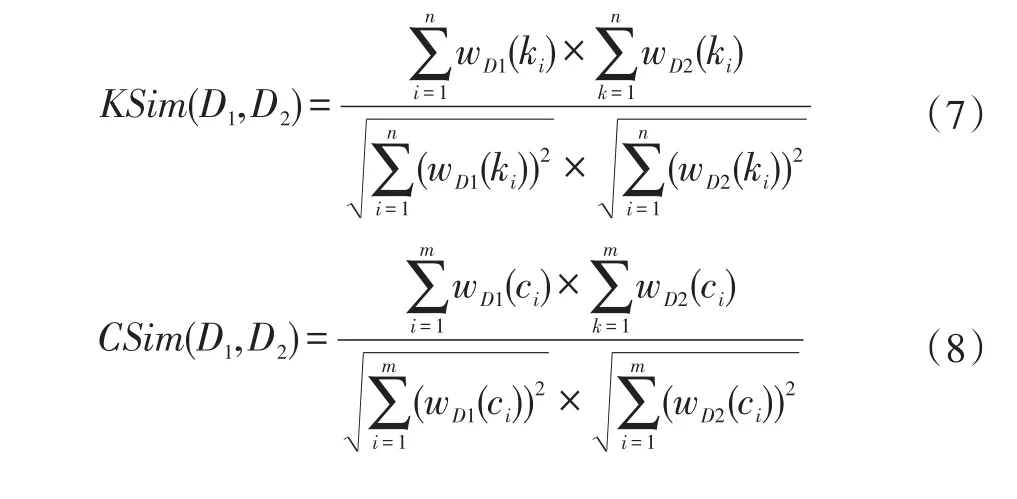
其中,wD1(ki)和wD2(ki)分别表示文档D1和D2未匹配本体的关键词向量第i个分量关键词特征项的权值;wD1(ci)和wD2(ci)分别表示文档D1和D2本体概念向量第i个分量概念特征项的权值;n和m分别表示未匹配本体的关键词向量和本体概念向量的维度。
舆情文档D1和D2的总相似度TSim(D1,D2)的计算公式为:
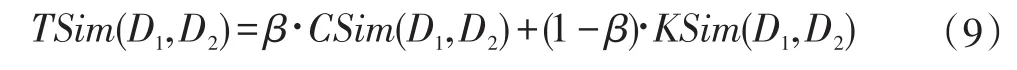
其中,β为调节因子,用于调节舆情文档概念语义特征相似度和未匹配的关键词特征相似度对文档相似度的影响。
3 结语
本文在分析现有的网络舆情挖掘系统存在的不足的基础上,将本体语义引入网络舆情挖掘系统,通过引入本体,构建了基于语义的主题网络舆情挖掘系统模型;重点研究了通过本体语义信息对网络舆情文本进行语义特征抽取和转换、对网络舆情文本融合语义信息建模并进行混合相似性计算。但是当前对网络舆情信息的挖掘研究主要集中在舆情文本信息上,对图像、视频等媒体所包含的网络舆情信息的挖掘有待进一步研究。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
哈哈画报(2021年10期)2021-02-28
小型微型计算机系统(2019年6期)2019-06-06
领导决策信息(2017年13期)2017-06-21
电脑爱好者(2017年7期)2017-05-06
领导决策信息(2017年9期)2017-05-04
消费电子(2016年12期)2017-01-19
图书与情报(2013年1期)2013-11-16
