
基于深度学习的肺CT医学影像识别研究
2018-11-28 02:21李雪竹
宿州学院学报 2018年9期
张 锏,李雪竹
宿州学院信息工程学院,宿州,234000
传统的计算机视觉采用统计学的方法对目标进行分析,比如,图像信息处理的传统方法有Prewitt,Sobel, Canny,RobertsLaplace等算法[1],这些算法使用图像自身的纹理、颜色、边缘梯度信息等特征检测目标并进行分类识别,但是这种基于传统统计的计算理论泛化能力不强,识别的错误率较高,和计算机视觉识别要求有很大的距离。
2006年,Hinton 等首次提出了深度学习算法[2],其核心是通过多层卷积神经网建立更加有效的特征分类网络,自此深度学习理论不断被深入研究,该算法对目标的识别率以及识别泛化能力远远超过传统的算法。近年来,相关的研究成果被大量应用到人工智能的各个方面,如目标追踪、语音识别、运动姿势、表情识别以及医学影像研究等[2]。
本文基于深度学习的理论,对其学习的过程进行探索研究,并结合深度学习框架技术,探索了深度学习在人体肺结节病灶自动识别方面的应用。
1 卷积神经网络
基于卷积神经网络(convolutional neural network,CNN)的深度学习的算法被广泛应用于计算机视觉领域,该算法根据人类大脑工作模式建立流程,模拟人脑的数据表达分析,利用CNN 提取图像的识别特征,不断将多个神经元组织成神经网络,组合低层单一的特征来形成语义丰富的高层抽象特征[2]。AlexNet算法作为CNN的经典算法,在2012年ImageNet比赛中获得冠军。自此,基于CNN的深度学习算法在计算机视觉领域的应用得到了国内外相关研究的重视。
1.1 卷积神经网络的构成
在人工智能领域很早就开始了对神经网络(Artificial Neural Networks,ANN)模型的研究,该模型将大量的数据处理节点互相连接,待处理的数据流入网络并最终处理为输出结果[2]。ANN的处理架构主要分为输入单元、隐藏单元和输出单元。如图1所示。
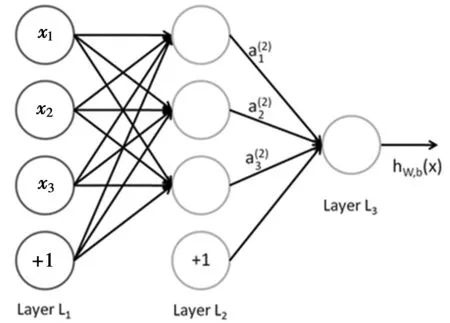
图1 ANN结构图
卷积神经网络CNN由ANN发展而来,其基本的节点称为神经元,多种不同的神经元不断互联构成一个多层的神经网络,每层都代表某种特征的组合,且越到高层这种组合语义越强[3]。
建模的过程是:CNN首先用卷积核作为特征抽取器,作用到原始的输入矩阵,形成第一层卷积层;然后在卷积层的基础上进行池化运算,形成池化层。随后不断迭代下去,建立多个卷积层和交叉的池化层,最后建立多个全连接层,构成一个完整的卷积神经网络。
在学习过程中,根据期望值和输出值之间的误差反向传播,并利用最小梯度算法不断修正每层特征抽取的卷积核[4],完成深度学习并且建立模型。
1.2 CNN训练过程
CNN训练分为前向传播和反向传播过程。在前向传播阶段,样本矩阵从第一层卷积网络输入,经过多层变换输出,最终输出为y′ 。假定该样本的期望输出为y,二者误差记为E,反向传播中按照误差最小原则微调卷积核矩阵[5,6]。
假设l层的第y个神经元的输出为:
(1)
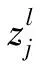
(2)
其中,σ为激活函数,Sigmiod函数或Rectified Linear Unit(ReLU) 函数均可以使用,可以根据实际计算的要求选择。
根据期望值与计算值的误差,可以设置误差函数为:
ζ=f(y,y')
(3)
f为二次代价函数。所以l层第j个神经元的误差为:
(4)
卷积神经网的最后一层的误差是:
δL=aLζΘσ'(zL)
(5)
Θ是Hadamard乘积运算符,aLζ表示最后一层的梯度值,其他各层的误差为:
(6)
所以权重梯度为:
(7)
偏值梯度为:
(8)
利用梯度下降法,可推出卷积核的更新公式:
wl=wl-η∑xδx,l(ax,l-1)T
(9)
bl=bl-η∑xδx,l
(10)
1.3 深度学习网络
基于卷积神经网络的深度学习算法,因为其良好分类的效果以及泛化能力,得到了广泛的研究与应用。因网络层次构造的不同,又产生了诸多不同的系统。比较有影响的有VGG、Alexnet、GoogleNet、Deep Residual Learning等。其中Alexnet网络的结构如图2所示。
图2中,Alexnet一共有8层,选用ReLU作为激活函数,经过卷积核下采样算法、上采样(插值)算法以及降采样等处理过程生成,其中有5个卷积层以及3个全连接层。
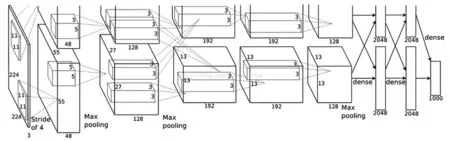
图2 Alexnet(双GPU)卷积神经网络的结构
2 算法实现
2.1 Caffe
自从以CNN为主流的深度学习算法在计算机视觉领域取得突破以来,该领域出现了很多 CNN 相关的开源框架,有影响的有Caffe、MatConvNet和Theano等。Caffe由伯克利视觉和学习中心开发,采用C++/CUDA/Python实现卷积神经网络,可实现多种CNN算法,比如上文提到的Alexnet、Deep Residual Learning、VGG等均可在该框架下运行。Caffe将卷积神经网络的构造过程变得简单,类似于积木搭建,其底层采用C++、CUDA编写,代码结构清晰良好、可扩展性强,允许使用者二次开发来提高计算效率,使用者也可以灵活地配置各个卷积神经网络的构造层,从而实现更高的识别效率[7]。
2.2 Caffe存储结构Blob
在Caffe框架中,按照上面的分析,有海量的多维数组数据要在算法中处理,这些数据包括原始的输入数据,例如训练图片,也包括网络结构中每层的中间数据。Caffe采用Blob包装类对数据进行处理和传输,Blob类可以在CPU和GPU之间同步数据,从而大大提高数据计算的效率。Blob类近似N维的数组,以C语言的风格进行存储。Blob类可存储交换图片、卷积核和网络优化中的偏导数等,可以高效使用存储空间。
2.3 Caffe基本计算单元layer
Caffe框架的基本计算单元称为layer。Caffe中的layer分为普通卷积层和降维的池化层。针对每一层Caffe采用激励函数等非线性变换,计算loss(代价损失),并对数据正则化,相关的计算有:setup、forward和backward,forward(前向传播)从输入计算输出,backward(反向传播)获取输出的梯度。Net把每一层的backward组合起来,从loss中计算梯度来学习,并按照梯度最小的策略不断调整参数。
2.4 在Caffe下实现Alexnet网络
Alexnet是以CNN为主的8层深度学习网络,其中5个是卷积层,3个是全连接层。激励函数选择RELU,池化降采样采用max-pooling,同时进行局部响应归一化(LRN)处理。通过在Caffe框架中定义其每一层的setup、forward、backword参数,即可以构建Alexnet网络系统,从而开始深度学习的相关实验。比如第1层卷积层的Alexnet配置输入224×224×3(RGB图像),然后使用96个大小规格为11×11的卷积核,进行特征提取。
3 医学影像的处理
医学图片识别是探索计算机视觉在医学影像领域应用的学科,其发展依赖于医学影像、计算机视觉、数学建模学科的突破[8]。基于CNN的深度学习算法在该领域不断应用,比如恶性肿瘤检测、间质性肺病分类、白内障检测、乳腺病变识别等[9]。下面应用Caffe框架下的Alexnet卷积神经网络对病人常见的肺CT图像进行识别判断,找出病人肺部结节病变的图像。
3.1 学习与训练
样本集选择LIDC-IDRI(Lung Lmage Database Consortium),该数据由美国国家癌症学会发布,总计收录了1 018个实例。每个实例包括病灶标注以及病人肺部CT切片。该数据非常严谨,具有代表性,数据标注由4位知名胸部放射科医师采用标准程序诊断并复诊完成。
实验中对该数据库进行数据预处理,得到关于肺部有结节的图片10 000张,以及健康肺部切片10 000张作为训练样本。通过对上文配置后的Alexnet 网络进行学习并微调,最后生成预测模型。然后,取剩余的图片预处理为300张待测试的样本进行深度学习诊断。
3.2 实验结果及分析
实验结果如表1。
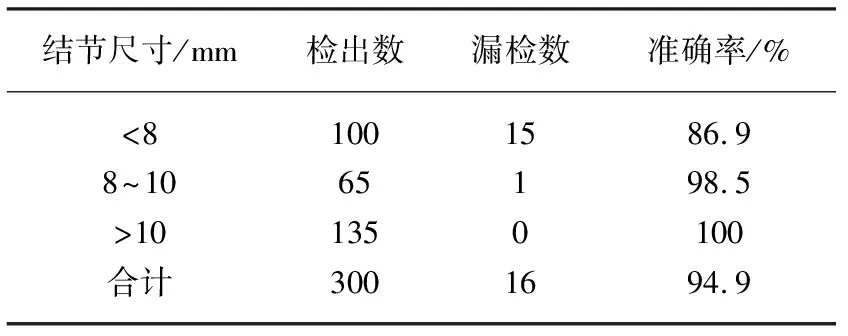
表1 肺部结节检测结果
由表1可知,对尺寸超过8 mm的结节预测模型准确率较高,对超过10 mm的结节识别准确率达到100%,该结果接近临床应用的要求。该识别结果是传统图片处理方法无法达到的,因此,基于卷积神经网络的深度学习可提高医学影像识别的准确率,相关研究对于人工智能在医学领域的应用是十分有必要的[10]。
4 结 论
基于CNN的深度学习技术的研究在人工智能方面取得了较好的效果。利用该技术对医学影像进行识别,对人类的疾病诊断具有重要意义,并在一些领域已经取得相关的成果。基于Caffe框架的CNN配置灵活,可扩展性强[11],未来必将在医学影像智能处理领域发挥更大的作用。本文利用该架构探索了其对于肺部医学影像处理的效果,今后的研究中将通过对卷积神经网络的扩展,提高其医学影像的识别准确率和灵敏度,推动该技术的临床应用。
猜你喜欢
中国药学药品知识仓库(2022年8期)2022-05-09
数学物理学报(2021年6期)2021-12-21
中国临床医学影像杂志(2021年10期)2021-11-22
北京航空航天大学学报(2021年9期)2021-11-02
中国医学影像学杂志(2021年6期)2021-08-13
应用数学(2020年2期)2020-06-24
电子制作(2019年11期)2019-07-04
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
数学年刊A辑(中文版)(2018年2期)2019-01-08
北京航空航天大学学报(2018年1期)2018-04-20
