
基于Spark平台的离群数据并行挖掘算法∗
2018-11-28 09:46李俊丽
计算机与数字工程 2018年11期
李俊丽
(晋中学院信息技术与工程学院 晋中 030619)
1 引言
在过去的几十年中,数据挖掘任务中使用的数据集的维度显著增加。对于这些领域的研究人员来说,这是一个前所未有的挑战,因为现有的算法在处理这些新的非常高的维度时,并不总是有足够的响应时间。在20世纪90年代,数据的最大维度大约是6000000;在21世纪头十年,这个数字增加到超过1600万;在2010年,它又进一步发展。随着上面提到的高维数据集的出现,现有的离群挖掘方法[1~6]在处理大数据时,其效率可能显著下降甚至不适用,因此预计不会很好地扩展。在过去的十年中,可扩展的分布式编程框架[7~8]已经出现,用以管理大数据。第一个编程模型是 MapReduce[9~10]和它的开源实现 Apache Hadoop[11~12]。近几年来出现了一个新的分布式框架,Apache Spark[13~14],这是一个快速和通用地进行大规模数据处理的平台。
随着大数据技术的发展,离群数据挖掘也面临着很大的挑战,传统分布式文件系统由于自身的限制,实现分布式数据挖掘算法非常耗时和消耗磁盘容量,很难满足大数据处理和分析的需要。基于内存计算的Spark平台,天然地适应于大数据处理和分析。本文的主要目的是在Spark大数据平台中设计实现一个离群挖掘算法STCS[15]的并行化,从而提高算法性能。
2 Spark平台
Apache Hadoop是MapReduce的开源实现,用于可靠、可伸缩、分布式计算。尽管Hadoop是Ma⁃pReduce最受欢迎的开源实现,但它在很多情况下并不适用,比如在线和迭代计算、高进程间通信模式或内存计算等。
近年来,Apache Spark在Hadoop生态系统中被引入。这个框架的目的是通过使用内存原语来实现对大数据的更快的分布式计算,这使得它能够比Hadoop在某些应用程序上运行速度快100倍。这个平台允许用户程序将数据加载到内存中并反复计算,使其成为在线和迭代处理(特别是机器学习算法)的一个非常合适的工具,从而简化了编程任务。
Spark对应用非常广泛的MapReduce计算模型在速度方面进行了扩展,并有效地对更多计算模式包括交互式查询和流处理进行支持。Spark是基于一种称为弹性分布式数据集(RDDs)的分布式数据结构。RDD是Spark的核心概念,Spark中的RDD是分布式对象的不可变集合。每个RDD被划分为在集群中的不同节点上运行的分区。通过使用RDDs,我们可以实现像Pregel或MapReduce这样的分布式编程模型,这要归功于它们的通用性。这些并行数据结构还允许程序员在内存中保存中间结果,并管理分区以优化数据放置。
在分布式环境中,Spark集群使用主/从结构。在Spark集群中,有一个节点负责分布式工作节点的中央协调和调度。这个中心协调节点称为驱动节点,相应的工作节点称为executor节点。驱动节点可以与大量的executor节点通信,这些节点也作为独立的Java进程运行。驱动节点与所有执行器节点一起被称为Spark应用程序。Spark应用程序通过一个名为Cluster Manager的外部服务在集群中的机器上启动。Spark附带的集群管理器称为独立集群管理器。Spark还可以运行在两个大型开源集群管理器YARN和Mesos上。
Spark集群基本工作流程如图1所示。
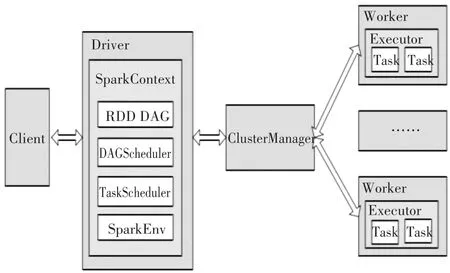
图1 Spark基本工作流程图
用户通过客户端提交作业给集群,驱动器节点将开始初始化操作执行环境(包括任务调度,作业阶段调度,等等),作业被分为多个任务,然后主节点向集群管理器Cluster Manager申请资源,集群管理器根据报告的资源使用情况分配资源,Executor负责执行具体的任务,最后释放集群资源直到任务执行完成。
3 基于Spark平台的并行化框架分析
Hadoop平台上实现的算法计算任务需要考虑具体的功能划分和合并运算结果。算法会根据需要分成小任务,每个任务的实现都要使用Map函数或Reduce函数,算法实现的时候,可能会有多个Map任务和Reduce任务,该任务从磁盘读取数据或中间结果,然后在磁盘中保存处理结果,多个Map-Reduce的形式有可能就会形成。以内存计算为核心的Spark平台,其数据处理对象为RDD弹性分布式数据集,处理数据的时候会根据算法设计动作操作和转换操作来完成任务。
本文除了基于Spark平台实现算法,还重新设计了算法的框架,为经典方法的性能添加了一些新的重要改进,但同时也保留了一些特性。
RDD存储:当调用RDD的persist()或cache()方法时,这个RDD的分区会被存储到缓存区中。Spark会根据spark.storage.memoryFraction限制用来缓存的内存占整个JVM堆空间的比例大小。如果超出限制,旧的分区数据会被移出内存。
Broadcast:此操作允许在每个节点上保留给定变量的只读副本,而不是将副本发送到每个任务。这通常用于大型永久变量(例如大哈希表)。
我们还从Spark API中使用了一些复杂的操作,如下所示。Spark源码扩展了MapReduce的思想,以提供更复杂的操作来简化代码的并行化。在这里,我们概述那些与方法更相关的内容:
mapPartitions:类似于Map,它在每个分区上独立运行一个函数。对于每个分区,将获取一个元组的迭代器,并生成另一个相同类型的迭代器。
groupByKey:该操作将这些元组在一个值向量(使用shuffle操作)中使用相同的键。
sortByKey:合并排序的分布式版本。
4 基于Spark平台的离群数据挖掘算法S-STCS
我们采取sc.textFile从外部存储中读取数据集来创建RDD。读取数据源采用的是map转换操作,并且使用split实现了数据的分割,然后使用persist将RDD持久化。具体实现代码:map(lines=>lines.split(‘,’)).persist(StorageLevel.MEMORY_AND_DISK)。读取数据集时,map操作将按行进行,然后使用split方法将每行的数据用特定分隔符‘,’并且用persist操作进行数据集的缓存,最终通过几种操作结合起来就把原来的数据集转变为RDD数据集。
基于Spark平台的S-STCS算法的实现步骤主要为
步骤一:弹性分布式数据集RDD的转换。基于RDD的Spark的并行计算首先要将原始数据集转换成RDD,但是数据集原来是保存在磁盘里的。所以,第一步首先应该通过sc.textFile将原始数据集转换为RDD,并命名为dataRDD。
步骤二:通过map,split和persist对dataRDD进行转换并持久化,命名为datapreRDD。
步骤三:并行计算属性的信息熵和互信息。信息熵可以反映属性的冗余程度,互信息反映属性之间的相关关系。计算属性的信息熵和互信息是在datapreRDD基础上计算的,主要使用了map操作。这个操作在算法开始时执行一次,然后缓存。这也有助于通过在所有节点中广播避免冗余计算。
步骤四:并行计算数据对象的离群程度。计算数据对象的离群程度是在datapreRDD基础上计算的,通过map和countBykey操作计算,将结果RDD此命名为scoreRDD。
步骤五:通过sortBy排序最终确定得分最高的离群点。
5 实验结果及分析
实验所使用集群配备了24个计算节点,每个节点配置为Intel E5系列3.7GHz的4核处理器、16G主存,2T硬盘。集群中的所有计算节点使用SSH协议通信。集群的软件配置环境如表1所示。
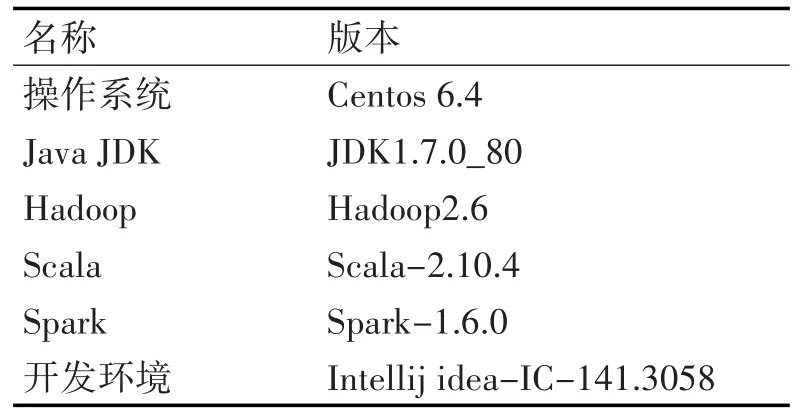
表1 集群软件配置
实验数据集采用UCI机器学习库中的connect4数据集作为测试数据集。我们使用这个真实的数据集来验证S-STCS算法。Connect-4数据集包含了67557个数据对象和42个属性。下面的实验将不同的数据大小以及不同的节点数来设计实验对比和测试算法性能。
1)可扩展性
本实验通过在一定数量的节点情况下(该实验节点数设定为4个)增加数据集的规模来验证串行算法STCS和并行算法S-STCS两种算法的可扩展性。实验在Connect-4数据集的基础上又构建了3组较大的数据集 Connect-4(1)、Connect-4(2)、Connect-4(3),分别为 Connect-4数据集的 2、4、6倍,实验结果如图2所示。
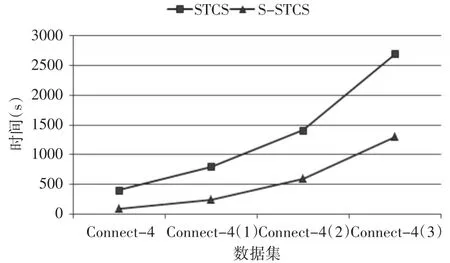
图2 不同数据集运行时间
由图2可知,随着数据对象的增加,S-STCS与STCS算法的时间消耗均有所增加,主要原因是数据集数据对象的增加使得扫描数据的时间更长。但与STCS算法相比,基于Spark平台的S-STCS算法增加的时间并不明显。随着数据对象的增加,集群上每个计算节点所分配的数据块也会增加,导致执行时间有所增加。但S-STCS算法比STCS算法表现出了更好的可扩展性。
2)加速比
加速比指的是当处理的数据集规模大小相同的时候,通过增加计算节点的数量,对并行算法性能的影响。这组实验数据集选择Connect-4数据集,通过将Spark集群中的节点数量从4个增加到24个评价并行算法S-STCS的执行性能。
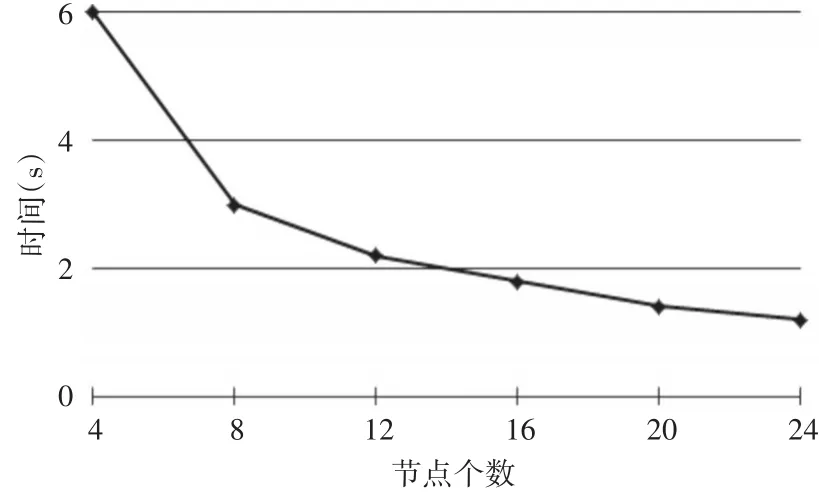
图3 节点个数对挖掘效率的影响
由图3可以看出,当数据集固定不变的时候,S-STCS离群挖掘算法的效率会随着计算节点数量的增加有所提高。这就说明Spark集群的计算节点影响了S-STCS算法的挖掘效率。这主要是因为增加了计算节点的个数,更多的节点可以参与到并行挖掘计算中,即集群中用于存储RDD数据集的内存空间不断增大,从而提高了算法的运行效率。但是,由于节点数量的增加会增加集群I/O的传输消耗,因此挖掘时间并没有成比例缩短。
6 结语
本文充分利用Spark平台对内存计算的支持,提出了一种基于Spark平台的并行离群数据挖掘算法S-STCS,用于高维属性数据集的离群挖掘。与大多数现有的算法不同,该算法基于Spark平台,其最大的优势在于其将中间结果保存至内存,而不再需要读写HDFS分布式文件系统,这样有效地降低I/O成本,并能提高数据分析和处理的效率。为了进行性能评价,通过UCI数据集对S-STCS算法进行了实验验证。结果表明,本文算法在高维属性数据集上发现离群数据的能力和效率都有所提高。
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
计算技术与自动化(2022年1期)2022-04-15
计算机与网络(2021年22期)2021-01-13
电脑爱好者(2020年10期)2020-07-28
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
数码世界(2018年2期)2018-12-21
诗选刊(2018年7期)2018-07-09
阅读(中年级)(2016年4期)2016-11-19
电脑爱好者(2015年21期)2015-09-10
