
基于Python的常用数值排序算法比较分析
2018-11-26 09:33杜虎彬生龙
电脑知识与技术 2018年23期
杜虎彬 生龙
摘要:排序是计算机学科领域研究的重要课题之一,良好性能的算法,性能良好的排序算法可以对大规模无序数据进行高效的排序,便于数据的进一步分析处理。由此基于Python的数值排序算法比较分析,通过对冒泡排序,选择排序,插入排序,快速排序,希尔排序进行多组实验数据的从而得到各排序算法在特定数据环境下的性能优劣分析,从而得到各排序算法在特定数据环境下的性能优劣。
关键词:数值排序;Python;时间复杂度;排序算法
中图分类号:TP301.5 文献标识码:A 文章编号:1009-3044(2018)23-0055-05
1 引言
排序是计算机内经常要进行的一种操作,就是将一组对象按照某种逻辑顺序重新排列的过程。现在计算机的广泛使用使得数据无处不在,而整理数据第一步通常就是进行排序。排序在商业数据处理和现代科学计算中都有着重要的地位,能够应用于多种事务处理、组合优化、天体物理学、分子动力学、语言学、天气预报等领域。排序算法的性能对现代计算机发展的有着重要的意义。[2]而排序算法的性能比较通常从三个方面进行评价,分别是时间复杂度,空间复杂度和稳定性。
在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间。这是一个关于代表算法输入值的字符串的长度的函数。时间复杂度常用大О符号表述,不包括这个函数的低阶项和首项系数。而算法的运行时间的长短也直观地反映了算法的效率,在相同计算环境下通过运行时间可以直观的比较排序算法的性能。[3]
Python语言,是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,由于Python语言的简洁性、易读性以及可扩展性,在国外用Python做科学计算的研究机构日益增多,一些知名大学已经采用Python来教授程序设计课程,2017年7月20日,IEEE发布2017年编程语言排行榜,Python高居首位。[3]但是目前大多数排序算法性能实验数据大多基于C,C++,等语言,虽然Python语言所编写的代码简单易懂,效率极高,且具有高度融合性,而很少有基于python语言的排序算法的性能比较,本文利用python实现数值排序算法并通过比较各算法性能进行分析。
2 算法分析
2.1冒泡排序
冒泡排序的设计思想,是比较相邻的元素,如果第一个元素比第二个元素大,就交换他们两个;然后对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对;最后的元素是最大的数;针对所有的元素重复以上的步骤,除最后一个元素;然后持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较,即完成排序。[4]
有上述算法可知,若文件的初始状态是正序的,一趟扫描即可完成排序。所需的关键字比较次数[C]和记录移动次数[M]均达到最小值:[Cmin=n-1],[Mmin=0]。所以,冒泡排序最好的时间复杂度为[On]。若初始文件是反序的,需要进行[n-1]趟排序。每趟排序要进行[n-i]次关键字的比较(1≤i≤n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值,[Cmax=n(n-1)2=On2],[Mmax=3n(n-1)2=On2]。冒泡排序的最坏时间复杂度为[On2]。[4]
综上,因此冒泡排序总的平均时间复杂度为[On2]。
2.2选择排序
选择排序算法的设计思想:每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。n个记录的文件的直接选择排序可经过n-1趟直接选择排序得到有序结果:①初始状态:无序区为R[1…n],有序区为空。②第1趟排序,在无序区R[1..n]中选出关键字最小的记录R[k],将它与无序区的第1个记录R[1]交换,使R[1]和R[2..n]分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区。③第i趟排序,第i趟排序开始时,当前有序区和无序区分别为R[1…i-1]和R(i…n)。[5]该趟排序从当前无序区中选出关键字最小的记录 R[k],将它与无序区的第1个记录R交换,使R[1…i]和R分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区。
由上可得,在直接选择排序中所记录的移动次数最少的次数是0,最大值为3(n-1)。但是,无论初始排序如何,都不会影响数据得比较次数,均为n(n-1)/2,算法的时间复杂度为[O(n2)]。
2.3插入排序
插入排序算法的思想是,每步将一个待排序的纪录,按其关键码值的大小插入前面已经排序的文件中适当位置上,直到全部插入完为止。从第一个元素开始,该元素可以认为已经被排序;取出下一个元素,在已经排序的元素序列中从后向前扫描;如果该元素(已排序)大于新元素,将该元素移到下一位置;重復上步,直到找到已排序的元素小于或者等于新元素的位置;将新元素插入到该位置后;重复以上步骤,直至比较完文件中的所有数据。
有上述可得,如果文件中的数据为正序排列,在这种情况下,需要进行的比较操作需(n-1)次即可。最坏情况就是,序列是降序排列,那么此时需要进行的比较共有n(n-1)/2次。插入排序的赋值操作是比较操作的次数加上 (n-1)次,因此时间复杂度为[O(n2)]。
2.4快速排序
快速排序算法的思想是,快速排序算法是对冒泡排序的一种改进,通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。一趟快速排序算法,设置两个变量i、j,排序开始的以第一个数组元素作为关键数据,赋值给base,即base=arr[0]时候:i=0,j=N-1;以第一个数组元素作为关键数据,赋值给base,即base=arr[0];从j开始向前搜索,即由后开始向前搜索(j--),找到第一个小于key的值arr[j],将arr[j]和arr[i]互换;从i开始向后搜索,即由前开始向后搜索(i++),找到第一个大于base的arr[i],将arr[i]和arr[j]互换;[4]重复上述步骤,直至i=j。
快速排序算法需要通过两种情况讨论;第一种情况,当需要排序的文件中数据为有序时, 此时为最优情况,最优的情况就是每一次取到的元素都刚好平分整个数组此时的时间复杂度公式则为:T[n] = 2T[n/2] + F(n);T[n/2]为平分后的子数组的时间复杂度,F[n] 为平分这个数组时所花的时间;快速排序最优的情况下时间复杂度为:O( nlogn )。[5]
最差的情况就是每一次取到的元素就是数组中最小/最大的,这种情况其实就是冒泡排序了(每一次都排好一个元素的顺序) 这种情况时间复杂度就好计算了,就是冒泡排序的时间复杂度:T[n] = n * (n-1) = n2+ n;综上所述:快速排序最差的情况下时间复杂度为:O(n2)。
快速排序的平均时间复杂度也是:[Onlog2n]。
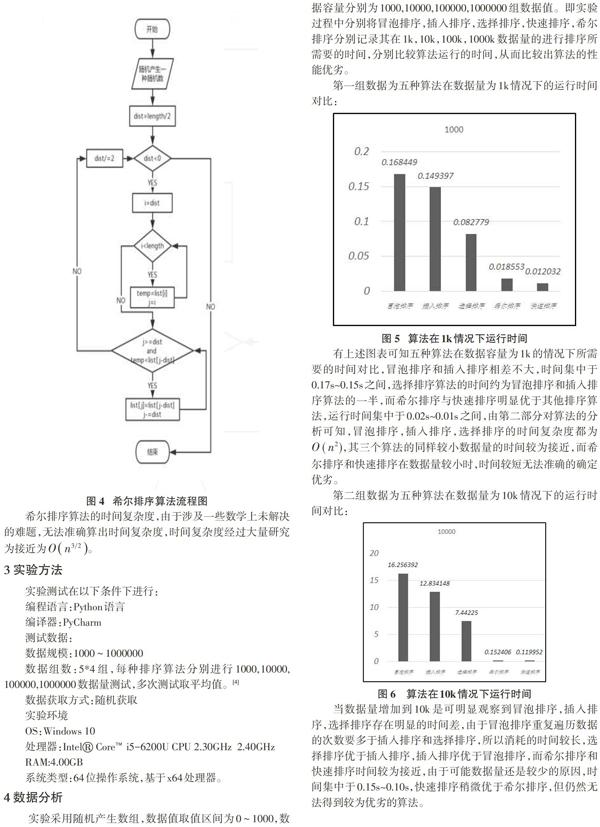
2.5希尔排序
希尔排序算法的基本设计思想先取一个小于n的整数d1作为第一个增量,把文件的全部记录分组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2 希尔排序算法的时间复杂度,由于涉及一些数学上未解决的难题,无法准确算出时间复杂度,时间复杂度经过大量研究为接近为[On32]。 3 实验方法 实验测试在以下条件下进行: 编程语言:Python语言 编译器:PyCharm 测试数据: 数据规模:1000~1000000 数据组数:5*4组,每种排序算法分别进行1000,10000,100000,1000000数据量测试,多次测试取平均值。[4] 数据获取方式:随机获取 实验环境 OS:Windows 10 处理器:Intel? Core? i5-6200U CPU 2.30GHz 2.40GHz RAM:4.00GB 系统类型:64位操作系统,基于x64处理器。 4 数据分析 实验采用随机产生数组,数据值取值区间为0~1000,数据容量分别为1000,10000,100000,1000000组数据值。即实验过程中分别将冒泡排序,插入排序,选择排序,快速排序,希尔排序分别记录其在1k,10k,100k,1000k数据量的进行排序所需要的时间,分别比较算法运行的时间,从而比较出算法的性能优劣。 有上述图表可知五种算法在数据容量为1k的情况下所需要的时间对比,冒泡排序和插入排序相差不大,时间集中于0.17s~0.15s之间,选择排序算法的时间约为冒泡排序和插入排序算法的一半,而希尔排序与快速排序明显优于其他排序算法,运行时间集中于0.02s~0.01s之间,由第二部分对算法的分析可知,冒泡排序,插入排序,选择排序的时间复杂度都为[O(n2)],其三个算法的同样较小数据量的时间较为接近,而希尔排序和快速排序在数据量较小时,时间较短无法准确的确定优劣。 当数据量增加到10k是可明显观察到冒泡排序,插入排序,选择排序存在明显的时间差,由于冒泡排序重复遍历数据的次数要多于插入排序和选择排序,所以消耗的时间较长,选择排序优于插入排序,插入排序优于冒泡排序,而希尔排序和快速排序时间较为接近,由于可能数据量还是较少的原因,时间集中于0.15s~0.10s,快速排序稍微优于希尔排序,但仍然无法得到较为优劣的算法。 在数据量为100k情况下,冒泡排序,插入排序,选择排序运行仍然呈阶梯状的,优劣明显,而希尔排序算法的运行的平均时间为4.845293s,快速排序算法的平均运行时间为1.940293s,实验数据表明希尔排序算法要优于快速排序算法,希尔排序算法的时间复杂度为[On32],快速排序的时间复杂度为[Onlog2n],当数据量级达到100k时可以观察出希尔排序算法和快速排序算法的优劣程度。 当数据量超过1000k时,冒泡排序,插入排序,选择排序,所需要的时间量过于庞大无法有效测出,当数据量大时希尔排序,和快速排序运行时间对比明显,快速排序明显优于希尔排序。[6-10] 5 总结 由上述实验数据可知,在Python语言编写的冒泡排序,插入排序,选择排序,希尔排序,快速排序的排序算法的性能差别。一个算法的优劣取决本身时间复杂度和空间复杂度,还有程序所运行的环境不同,算法的需求不同,优劣也会不同。[9] 根据以上的实验结果,当数据量小于1k时,冒泡排序,插入排序,选择排序的时间复杂度相同,所以时间消耗接近,随着数据量的逐渐增加,冒泡排序算法消耗的时间要高于两种算法。当数据量在1k~100k时,根据折线图9,可明显看出选择排序优于插入排序,插入排序优于冒泡排序,而希尔排序和快速排序明显优于上述三种排序算法。由于希尔排序算法的时间复杂度为[On32],快速排序的时间复杂度为[Onlog2n],所以在数据量较小的时候,无法明显得出两种算法的优劣程度,而在数据量超过100k时,快速排序算法所消耗的时间要远远短于希尔排序。[6-10] 本次實验仅仅是从数据量的大小来判断算法的优劣,而影响一个排序算法性能的影响因素多种多样,所以在接下的研究中会有更多的考虑方面,使算法可以更好地利用在合适的方面中。 参考文献: [1] 蒲天银.软件工程基础[M].镇江.江苏大学出版社,2013. [2] 严蔚敏.数据结构[M].北京.人民邮电出版社,2011. [3] 埃里克·马瑟斯(Eric Matthes).Python从入门到实践[M].北京:人民邮电出版社,2016. [4] 郑明秀.常用排序算法时间开销的实验统计分析[J].西南民族大学学报:自然科学版,2015,41(6). [5] 淦金,杨有.五种排序算法的性能分析[J].重庆文理学院学报:自然科学版,2010,29(3). [6] 淦艳,尚晋.五种排序算法的性能分析[J].重庆航天职业技术学院学报,2010(6). [7] 李长峰.关于排序算法复杂度的研究[J].零八一科技,2008(4). [8] 翟利红,侯枫.排序方法的分析与探讨[J].中国科教创新导刊,2008(1). [9] 杨洪波,田荣,张玉起.C语言常用三种排序方法总结与分析[J].今日科苑,2007(18). [10] 刘模群.排序算法时间复杂度研究[J].软件导刊,2012,11(6). 【通联编辑:王力】
