
基于Spark平台ALS模型推荐算法的研究
2018-11-26 09:33吴青洋程旭邓程鹏丁浩轩张宏郑志伟
电脑知识与技术 2018年23期
吴青洋 程旭 邓程鹏 丁浩轩 张宏 郑志伟

摘要:针对推荐系统的可扩性问题,该文比较了基于Hadoop实现ALS模型推荐算法与基于Spark平台实现ALS模型推荐算法的性能,通过在GroupLens网站提供的MovieLens数据集上的实验结果表明,Spark平台的计算性能更强。针对推荐系统的数据稀疏性问题,该文采用了ALS模型推荐算法。最后在Spark平台上使用Scala编程语言,对不同参数下的ALS模型进行训练,并在校验集中验证,获取了最佳参数下的模型。
关键词:MapReduce;Spark:ALS模型推荐算法:矩阵分解:迭代最小二乘法
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2018)23-0033-04
1 概述
推荐系统是目前使用最广泛的机器学习技术[1]之一。由于它在个性化推荐方面效果显著,因此引起了越来越多学者的关注。随着互联网的快速发展,推荐系统正面临处理海量数据的问题。
推荐系统旨在给用户推荐他们可能感兴趣的物品。它主要通过分析用户的行为信息数据来预测用户对某些物品的喜好。个性化推荐技术主要分为三类:基于内容的推荐,基于协同过滤的推荐,基于混合的推荐[2]。
该文使用推荐效果较好的协同过滤算法。协同过滤算法的关键是计算用户的相似度(或物品的相似度)。随着用户和物品数量的线性增长,推荐系统的计算量增大,性能降低。此时需要额外的计算能力,即推荐系统的可扩展性问题,也是协同过滤算法面临的难题之一[3]。
文献[4-5]使用Hadoop并行化协同过滤算法致力于解决计算复杂度和可扩展性问题。然而,如果数据量剧增的时候,这种基于MapReduce方式缺乏良好的可扩展性和计算效率。
该文提出了基于Spark平台的解决方案。我们使用两个集群计算框架比较基于ALS模型推荐算法:基于Hadoop的MapReduce和基于Spark的内存计算RDD。基于Hadoop平台使用Mahout实现ALS模型推荐算法[6-7]。基于Spark平台使用Scala编程语言实现ALS模型推荐算法。
由于用户和项目数量不断增加,用户项目评分矩阵往往十分庞大,此外评分矩阵通常是稀疏的,因此可以考虑采用低维度矩阵拟合评分矩阵。矩阵分解法是利用两个低维度的矩阵来描述评分矩阵,从而达到降维的目的[8]。该文采用的是容易并行化的最小二乘法ALS(Alternating-Least-Squares)[9]。
2 MapReduce
MapReduce是分布式编程的一种模式,用于处理集群中的海量数据,其中的每台计算机被称为一个节点,该模式是由谷歌公司在2004年提出的[10],其主要特点是通过并行编程解决处理海量数据的问题。MapReduce主要思想是”Map(映射)"和"Reduce(归约)”,它们都是来自函数式编程语言和矢量编程语言。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
开发人员的任务是实现以下两个步骤(见图1 MapReduce的工作流程):
1)map函数将输入数据切分为(键,值)对组表示的片段,根据特定的记录,产生零个或多个中间对。MapReduce组织相关的所有中间值相同的中间键k。接下来,值转移到reduce()函数。
2)reduce函数处理中间键K和与K对应的一组值,然后将这组值进行合并。每次调用Reduce函数通常返回一个值,但它也可以返回零个或多个值。
MapReduce能够有效地分配集群的资源来执行任务,解决了并行化编程的复杂性问题,但它缺少编程的灵活性:一个程序只能由map的和reduce函数组成,计算的每个阶段仅当其前一功能的各实例的结束后才能开始。执行复杂的操作,唯一的办法就是执行若干个MapReduce,输出数据的记录在磁盘上,然后再传给下一个任务。
在已经实现MapReduce的若干个实施方案中,Apache Hadoop的技术是最成功的,尤其在商业用途方面[11-12]。
3 协同过滤
协同过滤算法在推荐系统中广泛使用[13-15]。协同过滤算法分为基于邻域的推荐算法和基于模型的推荐算法。该文采用的是基于ALS模型推荐算法,算法原理如下:假设用户-物品评分矩阵为R,由矩阵奇异值分解原理可知,矩阵R可以分解为几个矩阵相乘的形式,如公式(1):
4.1 Hadoop解决方案
基于Hadoop平台的Mahout[6]在机器学习领域实现了算法的并行化,Mahout包含聚类、分类、推荐过滤、频繁子项挖掘等算法的实现。
ALS模型推荐算法的并行化是通过执行连续的MapReduce任务来实现的,在程序的实现过程中,中间数据被不断地写入磁盘,然后再从磁盘读取相关数据,这种方式对系统的开销很大。
4.2 Apache Spark
2012年4月加州大学伯克利分校的AMPLab 发表的文章中提出了弹性分布式数据集(简称RDD)的概念,Spark就是基于RDD实现的,Spark平台开发者的目的是消除MapReduce范式的局限性。Spark类似Hadoop的MapReduce范式,也是一个开源的分布式计算平台[11],而且Spark与HDFS是完全兼容的[16]。
RDD本質上是一个只读的分区记录集合,这意味着一个特定元素集合可以在集群节点间被共享。此外,RDD还具有以下特征:
1)只能由操作其RDD集或从文件系统读取数据时被创建;
2)为了有效地实现容错,RDD提供了一种高度受限的共享内存,即RDD是只读的;
3)中间结果的操作可以存储在内存中,计算迭代算法更快。
5 實验研究
1)对比spark与MapReduce 计算平台性能的差异
为了比较Spark与Hadoop MapReduce性能上差异,该文统计在MovieLens数据集为100万条记录数上,二者实现ALS模型推荐算法所消耗时间。为了减小实验误差,所有实验均进行三次,取三次结果的平均值作为最终结果。
2)基于Spark平台ALS模型推荐算法并行化实现指标统计
该文基于Spark平台ALS模型推荐算法并行化实现中,对推荐系统相关评测指标进行统计,统计基于ALS推荐算法在不同的属性个数、正则化参数、迭代次数下RMSE的大小。实验中训练集占数据量60%,校验集占数量20%,评测集占数据20%。所有实验均进行三次,取三次结果的平均值作为最终结果。
5.1 实验数据
该实验数据集是由GroupLe小组提供的MovieLens数据集,其主要包括3个种类的数据集,大小分别为100k, 1M, 10M,分别记录了10万条、100万条、1000万条用户评分记录。100万条记录里面主要有四个文件:movies.dat, ratings.dat, users.dat, README,其中users.dat记录所有用户相关信息;ratings.dat记录用户一电影的评分信息及时间戳;movies.dat记录电影相关信息,包括电影名、类型、年份等。该文主要采用100万条记录作为实验数据集,它包括了6060多名用户对4000多部电影评分的记录。
5.2 实验步骤
所有实验在包括一个MasterNode主节点和两个DataNodes(从节点)的集群上运行,每个节点都配备了Intel(R)Core(TM) i5-4590处理器(3.30 Ghz)和8GB的RAM。实验运行在版本为2.20的Hadoop(Mahout的版本为0.9),版本为2.10.04的Scala和版本为1.0的Spark。
5.3 实验结果
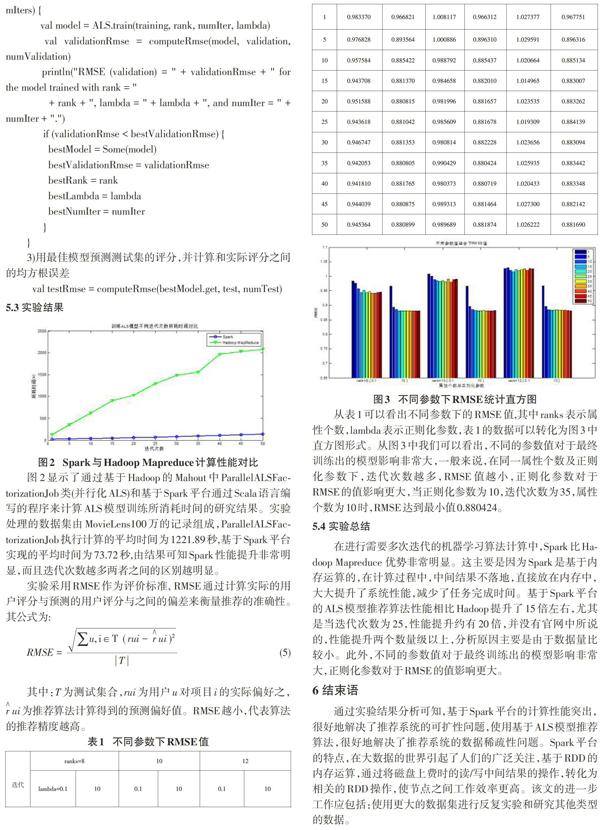
图2显示了通过基于Hadoop的Mahout中ParallelALSFactorizationJob类(并行化ALS)和基于Spark平台通过Scala语言编写的程序来计算ALS模型训练所消耗时间的研究结果。实验处理的数据集由MovieLens100万的记录组成,ParallelALSFactorizationJob执行计算的平均时间为1221.89秒,基于Spark平台实现的平均时间为73.72秒,由结果可知Spark性能提升非常明显,而且迭代次数越多两者之间的区别越明显。
从表1可以看出不同参数下的RMSE值,其中ranks表示属性个数,lambda表示正则化参数,表1的数据可以转化为图3中直方图形式。从图3中我们可以看出,不同的参数值对于最终训练出的模型影响非常大,一般来说,在同一属性个数及正则化参数下,迭代次数越多,RMSE值越小,正则化参数对于RMSE的值影响更大,当正则化参数为10,迭代次数为35,属性个数为10时,RMSE达到最小值0.880424。
5.4 实验总结
在进行需要多次迭代的机器学习算法计算中,Spark比Hadoop Mapreduce 优势非常明显。这主要是因为Spark是基于内存运算的,在计算过程中,中间结果不落地,直接放在内存中,大大提升了系统性能,减少了任务完成时间。基于Spark平台的ALS模型推荐算法性能相比Hadoop提升了15倍左右,尤其是当迭代次数为25,性能提升约有20倍,并没有官网中所说的,性能提升两个数量级以上,分析原因主要是由于数据量比较小。此外,不同的参数值对于最终训练出的模型影响非常大,正则化参数对于RMSE的值影响更大。
6 结束语
通过实验结果分析可知,基于Spark平台的计算性能突出,很好地解决了推荐系统的可扩性问题,使用基于ALS模型推荐算法,很好地解决了推荐系统的数据稀疏性问题。Spark平台的特点,在大数据的世界引起了人们的广泛关注,基于RDD的内存运算,通过将磁盘上费时的读/写中间结果的操作,转化为相关的RDD操作,使节点之间工作效率更高。该文的进一步工作应包括:使用更大的数据集进行反复实验和研究其他类型的数据。
参考文献:
[1] Sammut C, Webb G I. Encyclopedia of Machine Learning[J]. Springer, 2011.
[2] IBM what is big data? Bringing big data to the enterprise[EB/OL]. http://www.ibm.com/big-data/us/en/.
[3] Sarwar B,Karypis G, Konstan J, et al. Item-based collabo-rative filtering recommendation algorithms[C]//Proceedings of the 10th international conference on World Wide Web. ACM, 2001: 285-295.
[4] Zhao Z D, Shang M S. User-based collaborative-filtering recom-mendation algorithms on Hadoop[C]//Knowledge Discovery and Data Mining, 2010. WKDD10. Third International Conference on. IEEE, 2010: 478-481.
[5] Jiang J, Lu J, Zhang G, et al. Scaling-up item-based collaborative filtering recommendation algorithm based on Hadoop[C]// Services (SERVICES), 2011. IEEE World Congress on. IEEE, 2011: 490-497.
[6] Owen S, Anil R, Dunning T, et al. Mahout in action[M]. Manning Publications Co, Greenwich, CT, USA, 2011.
[7] Apache mahout documentation[EB/OL]. http://mahout.apache.org/.
[8] 樊哲. Mahout算法解析与案例实战[M]. 北京: 机械工业出版社, 2014(6).
[9] Zhou Y, Wilkinson D, Schreiber R. Large-scale parallel collaborative filtering for the netflix prize[M]// Algorithmic Aspects in Information and Management. Springer Berlin Heidelberg, 2008: 337-348.
[10] Dean J, Ghemawat S. Mapreduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
[11] Hadoop 1.1.2 documentation[EB/OL].http://hadoop.apache.org/docs/stable/.
[12] White T. Hadoop: The definitive guide[M]. OReilly Media, Inc, 2012.
[13] Resnick P, Varian H R. Recommender systems[J]. Communications of the ACM, 1997, 40(3): 56-58.
[14] Tan H, Ye H. A collaborative filtering recommendation algorithm based on item classification[C]//Circuits, Communications and Systems, 2009. PACCS09. Pacific-Asia Conference on. IEEE, 2009: 694-697.
[15] Gong S, Ye H, Tan H. Combining memory-based and model-based collaborative filtering in recommender system[C]//Circuits, Com-munications and Systems, 2009. PACCS09. Pacific-Asia Conference on. IEEE, 2009: 690-693.
[16] Spark documentation[EB/OL]. http://spark.apache.org/documentation.html.
【通聯编辑:谢媛媛】
