
基于转置卷积操作改进的单阶段多边框目标检测方法
2018-11-23 00:57郭川磊
计算机应用 2018年10期
郭川磊,何 嘉
(成都信息工程大学 计算机学院,成都 610225)(*通信作者电子邮箱hejia@cuit.edu.cn)
0 引言
在现实世界的应用中,以高精度分类和定位目标是服务质量的关键。例如,在高端的驾驶辅助系统中,精确地定位车辆和行人与实现安全的自动驾驶紧密相关。
近几年在目标检测领域取得的进展体现了深度卷积神经网络在自动驾驶技术发展中发挥的关键作用。目前基于卷积神经网络的不同方法可以大致被分为两类:第一类是类似基于区域卷积神经网络(Regions with Convolutional Neural Network, R-CNN)[1]的双阶段方法。该类方法的第一阶段产生高质量的候选区域,第二阶段对候选区域进行分类和定位结果优化。另外一类方法取消了生成候选区域阶段,构建了一个单阶段的端到端模型。单阶段模型通常更加容易训练,能够在生产环境中达到更高的计算效率[2]。然而,当单阶段模型需要以更高的交并比(Intersection over Union,IoU)来评估平均目标检测精度时,运算速度的优势通常会被较低的检测精度抵消,而双阶段的目标检测方法能够取得更高的检测精度。造成单阶段方法在高IoU条件下检测精度降低的主要原因是:在复杂的场景中,模型很难生成高质量的边界框。
通过实验可以看出,大部分低质量的边界框是由于定位小目标和重叠目标失败而产生的。在这种情况下,边界框的回归过程变得非常不可靠,因为边界框的正确生成必须依赖于图像的上下文信息(例如目标的尺寸信息或被遮挡目标周围的环境特征)。消除这类错误的关键在于使用能充分利用图像中上下文信息的优化过程。更快速的基于区域的卷积神经网络(Faster Regions with Convolutional Neural Network, Faster R-CNN)[3]的感兴趣区域池化(Region Of Interest Pooling,ROI Pooling)阶段可以被认为是一个简单利用上下文信息在特征图上重新采样的过程;但是 Faster R-CNN 在分类阶段仍然需要进行大量的运算来处理候选区域,这使得模型很难进行端到端的训练以提升整体性能。
本文为单阶段模型引入了利用图像上下文信息的优化方法。以转置卷积操作为基础,构建了循环特征聚合结构。利用循环特征聚合结构,上下文信息可以被逐渐地、有选择地被应用到对目标的分类和定位过程中。图像上下文信息的生成过程是完全由数据驱动的,并且可以进行端到端训练。实验使用KITTI数据集,在IoU为0.7的条件下评估了模型的平均检测精度(mean Average Precision, mAP)。本文实验中,循环特征聚合模型与对比模型均使用经过预训练的残差网络(Residual convolutional Network, ResNet)101作为特征提取网络,这证明了在使用相同特征图的情况下,循环特征聚合模型能够达到更高的平均检测精度。
1 相关工作
使用卷积神经网络在目标检测领域取得开创性进展的工作是R-CNN[1]。R-CNN使用选择性搜索算法[4]来生成目标候选区域,然后使用卷积神经网络提取特征并输出到分类器。空间金字塔形池化网络(Spatial Pyramid Pooling Network,SPP-NET)、Fast R-CNN和Faster R-CNN先后三次对R-CNN作出了改进。SPP-NET[5]在特征提取网络生成的特征图上运行选择性搜索算法来提升运算速度和候选区域的生成质量。Fast R-CNN[6]利用了ROI池化来为目标候选区域高效地生成特征编码。Faster R-CNN[3]使用卷积神经网络替换了选择性搜索算法来生成候选区域。后续的许多工作都采用了Faster R-CNN的模式,发表了一系列变种,它们能被运用在以高IoU评估平均检测精度的场景中。例如,基于区域的全连接卷积神经网络(Region-based Fully Convolutional neural Network, R-FCN)[7]利用全连接的卷积神经网络,降低了第二阶段的计算复杂度。然而,R-FCN的检测精度重度依赖于更大、更深的特征提取网络。多尺寸卷积神经网络(Multi-Scale Convolutional Neural Network,MS-CNN)[8]首先将转置卷积操作应用到了双阶段目标检测模型中,先利用转置卷积提升特征图的分辨率,然后再学习候选区域生成过程。
单阶段模型取消了R-CNN的候选区域生成阶段,提升了检测速度。单阶段多边框目标检测(Single Shot multibox Detector, SSD)模型[2]是一个典型的单阶段模型,模型在前向传播过程中生成了不同分辨率和语义抽象层次的特征图,这些特征图被直接用来检测尺寸在一定范围内的目标。SSD节省了巨大的计算量,所以运行速度比Faster R-CNN快很多。SSD以IoU为0.5评估检测精度的任务中取得了接近Faster R-CNN的检测精度。然而,如本文实验中展示的,当IoU被提高时,模型的准确率会明显下降。YOLO(You Only Look Once)[9]是另一个快速的单阶段模型,但是它的检测精度低于SSD。DSSD(Deconvolutional SSD)[10]以转置卷积操作为基础,构建了编码-解码的对称结构,充分利用了图像的全局上下文信息,但是DSSD的训练难度较大,失去了端到端训练的优势。RetinaNet(Retina Convolutional Neural Network)[11]的特征聚合的方式和特征聚合模型类似,但是该方法中上下文信息的生成过程是不可学习的。
循环神经网络(Recurrent Neural Network,RNN)被广泛地应用到了自然语言处理领域,如图像描述生成,但是使用序列模型来提升目标检测精度的想法只被很少的文章讨论过。文献[12]中将检测问题作为了边界框的生成问题,并利用了长短期记忆网络(Long Short-Term Memory, LSTM)在深度的特征图上学习边界框的生成过程。然而,因为仅仅利用了特征提取网络的最后一层特征图,当第一个特征图中的目标存在模糊、遮盖等问题时,目标检测的难度就会提升,而这种情况在实际应用中非常常见。与文献[12]不同,本文提出的循环特征聚合结构能有效地检测任意目标,因为它充分利用了上下文信息,并且在以高IoU评估的场景中得到了精确的检测结果。
2 方法分析
2.1 已有方法分析
一个健壮的目标检测系统必须能够同时检测尺寸和分辨率变化很大的目标。在Faster R-CNN[3]中,特征提取网络的最后一个卷积层中的每个的卷积核都有很大的感受野,它们可以帮助模型检测不同尺寸的目标。因为使用了多个池化层,最后一层特征图的尺寸要远小于输入图片的尺寸。这可能使检测小尺寸目标变得困难,因为在低分辨率的特征图中,表示小目标的特征可能很难被利用。OverFeat(Over Feature neural network)[13]将模型在不同尺寸的输入图片上训练可以缓解这个问题,但是运算的效率较低。
在SSD[2]中,作者观察到在大多数用于目标检测的模型中,由于池化操作的存在,不同卷积层输出的特征图已经具有了不同的尺寸。所以,利用高分辨率、低语义抽象的特征图来检测尺寸相对较小的目标,而利用低分辨率、高语义抽象的特征图来检测尺寸相对较大的目标的方法是非常合理的。这种方法的优势在于,通过将目标的分类、边界框的回归过程转移到了具有高分率的特征图上,模型能够更精确地检测尺寸较小的目标;SSD作为一个单阶段模型,它的运算速度要比双阶段模型快很多倍。运算速度快的原因在于这种方法并行处理多种尺寸特征图,并且不会为特征提取网络增加额外的运算量。
但是,SSD的检测精度低于双阶段模型。当使用更高的IoU评估检测精度时,SSD与双阶段模型之间的精度差距会扩大[14]。SSD利用多尺寸特征图的运算过程可以写作:
Φn=fn(Φn)=fn(fn-1(…f1(I)))
(1)
D=E(τn(Φn),τn-1(Φn-1),…,τn-k(Φn-k));n>k
(2)
其中:Φn代表第n层特征图;fn(·)是作用在第n-1层特征图上的非线性运算,通常是卷积层、池化层、线性修正单元(Rectified Linear Unit, ReLU)层等的组合;f1(I)是将输入图像I转换为第一层特征图的非线性运算;τn(·)是根据第n层特征图运算得到目标检测结果的函数,该函数仅负责检测尺寸在一定范围内的目标;E集成所有中间检测结果并生成最终目标检测结果D。
根据式(2),可以发现SSD模型实现高精度检测依赖于一个假设。为了使模型中每一层的特征图能实现对某个尺寸范围内目标的检测,网络中的每个特征图都需要具备足够的表示能力,能够支持精确的目标分类和定位。所以,特征图需要能够表示目标的细节;特征图应该有足够高的抽象程度,具备高层语义信息;特征图应该包含待检测目标的上下文信息,基于这些上下文信息,重叠、残缺、模糊或尺寸较小的目标也能够被可靠地检测和定位[2-3,12]。通过式(1)~(2)可看出:当k很大时,Φn的深度大于Φn-k,所以Φn-k的抽象程度可能不足以实现对目标的检测。这就使得用于将第n-k层的特征图转化为检测结果的函数τn-k(·)比τn(·)更难于训练。
Faster R-CNN没有这个深度问题,因为它的候选区域是利用特征提取网络的最后一层特征图得到的。但是特征提取网络的最后一层特征图的分辨率较低。所以,本文认为在单阶段目标检测模型中,输出函数应该被定义为:
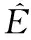

H={Φn,Φn-1,…,Φn-k},n>k>0
(3)
2.2 使用转置卷积操作实现特征聚合

(4)

2.2.1 循环特征聚合模型的细节
循环特征聚合模型的网络结构如图1所示。图1展示了一次特征聚合迭代过程。第一列的实线框代表由特征提取网络ResNet101的res3b3_relu、res5c_relu、res5c_relu/conv1_2、res5c_relu/conv2_2、res5c_relu/conv3_2卷积层输出的特征图。在第一阶段指向虚线框的箭头代表特征聚合过程,生成的特征图用虚线框表示。两个阶段之间的1×1卷积操作用于减少特征图的维度,使特征图可以被用于下次特征聚合。特征聚合与减少维度操作的权重在不同阶段之间共享。本文使用去除了分类器的ResNet101[15]作为特征提取网络,然后将特征聚合结构应用于ResNet101所提取的特征图。输入图像的尺寸为1 272×375,有3个颜色通道,所以ResNet101中卷积层res3b3_relu和res5c_relu输出的特征图的尺寸分别为 512×159×47和1 024×80×24,512和1 024是通道数。和原始SSD模型一样,本文为检测不同尺寸的目标而添加了卷积层res5c_relu/conv1_2、res5c_relu/conv2_2和res5c_relu/conv3_2。
本文使用一个转置卷积层来聚合深层的特征。例如,卷积层res5c_relu/conv1_2生成的特征图在经过一个ReLU运算和一个转置卷积运算后生成了新的特征图,与在卷积层res5c_relu特征图上使用3×3卷积生成新的特征图拼接。类似地,图中的每一组向右的1×1卷积和转置卷积都表示了同样的特征聚合操作。当第一次特征聚合结束后,在每层产生的特征图上分别做1×1卷积操作来将通道数减少到最初的设置。在减少通道数操作之后,第一个特征聚合过程就完成了。该减少通道数的操作保证了在两次特征聚合迭代之间,特征图的尺寸是一致的,这也使得循环特征聚合成为可能。训练时,不同迭代之间所有卷积和转置卷积操作所对应的卷积核的参数都是共享的。本文将该迭代的过程称为循环特征聚合。

图1 循环特征聚合网络结构Fig. 1 Architecture of recurrent feature aggregation network
文献[16]中提出的生成包含上下文信息的网络结构与本文相似,区别在于本文去掉了显式聚合前驱特征图的过程,因为模型的前向传输过程中的卷积操作生成的特征图已经包含了前驱特征图的相关信息;根据文献[5,11],本文对特征图进行了一次3×3卷积操作用于保证特征聚合的稳定性。
2.2.2 利用循环神经网络实现目标检测
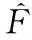
循环特征聚合是个循环的过程,该过程中的每次迭代提取并聚合生成目标检测所需的特征。如之前讨论,这些重新生成的特征包含了对于检测困难目标非常关键的上下文信息。在每次特征聚合迭代中,都有一组单独的损失函数来指导模型对参数的学习。这保证了相关的特征将在训练过程中被逐步引入,并不断取得进展。与文献[12]不同,因为循环特征聚合不会特别处理某种尺寸的边界框,所以上下文信息可以被利用来检测场景中的任意目标。
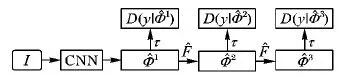
图2 循环特征聚合过程Fig. 2 Process of recurrent feature aggregation
在训练过程中,每次特征聚合迭代过程都有单独的损失函数。和SSD一样, Smooth L1损失被用来指导边界框回归。本文使用损失函数Focal Loss[11]指导目标分类。
实验中,网络中某一层输出的特征图,例如res3b3_relu负责实现对尺寸在某个特定区间的目标实现边界框回归。因为边界框回归在本质上是一个线性过程,所以如果这个尺寸区间过大或者特征图太过复杂,那么边界框回归过程的可靠性就会被严重地影响。因为循环特征聚合为特征图引入了更多的上下文信息,这不可避免地使特征图变得复杂,所以利用特征图对原来尺寸范围的目标进行边界框回归也就变得困难。为了使边界框的回归过程更加可靠,本文为所有特征图都加入了多个边界框回归函数,使边界框回归任务的尺寸区间离散化。这样,每个边界框回归函数需要处理的任务比原来更简单。
3 实验
本文使用了KITTI数据集[17]进行模型评估。该数据集中不仅包含检测难度较大的目标,例如小尺寸并且被严重遮挡的汽车和行人,而且在评估对车辆的检测效果时,要求检测结果与标注信息之间的IoU大于0.7。KITTI数据集包含7 481张图像用于模型的训练和验证,另外的7 518张图像用来测试。
本文进行了三个实验:第一个实验考察了每次特征聚合后,模型损失函数值的变化情况;第二个实验在一个较小的验证集上评估了模型的性能;最后一个实验对比了模型和其他已发表的单阶段与双阶段模型的性能。
三个实验使用了相同的设置来初始化模型。在网络结构方面,本文在训练过程进行了5次特征聚合迭代,为每一组特征图设置了5个边界框回归器,用于实现边界框回归。因为特征聚合由1×1的卷积以及转置卷积实现,所以实验得到的模型是非常高效的。在数据增广方面,除了使用SSD[2]中所提到的所有数据增广方法外,实验在色相—饱和度—曝光度(Hue-Saturation-Value, HSV)颜色空间中随机将部分图像的饱和度和曝光度扩大至1.3倍。随机调整了图像的曝光度和饱和度。模型还删除了SSD中的全局池化层。在训练过程中,本文使用了随机梯度下降法,动量设置为0.9,权重衰减设置为0.000 5,学习率为0.001。学习率在每15 epoch后缩小为当前值的1/10。为了使训练集与验证集的差别尽可能大,本文采用了归一化颜色直方图来衡量图像的相似度,并根据相似度来分割训练集和验证集。最终的验证集包含了2 741张图像。
3.1 每次特征聚合后的模型的损失值对比
因为循环特征聚合在测试中进行了5次特征聚合迭代,所以在实验中可以得到6组目标检测损失值,或者说模型连续做了6次检测。这次实验的目的是验证每次特征聚合后,模型的目标检测效果是否都有提升。
为了得到结果,在训练和验证集上分别运行了循环特征聚合模型,并分别计算了平均损失值。损失值见表1。
第1次迭代的损失值在未进行任何特征聚合时得到,第2次到第6次迭代的损失值由在前一次得到的特征图上进行特征聚合后得到。可以看到验证集的损失值要比训练集上的损失值大,这表示模型都一定程度地过拟合。出现这种情况的原因是,实验从训练集中抽取了很大一部分图像来作为验证集。从表1中可以归纳损失值基本的变化情况:第2次迭代的损失值,也就是进行一次特征聚合后,要比第1次迭代减小0.041。当进行四次特征聚合后,可以得到最小的损失值;然而,从第5次迭代特征聚合开始,损失函数不再减小。
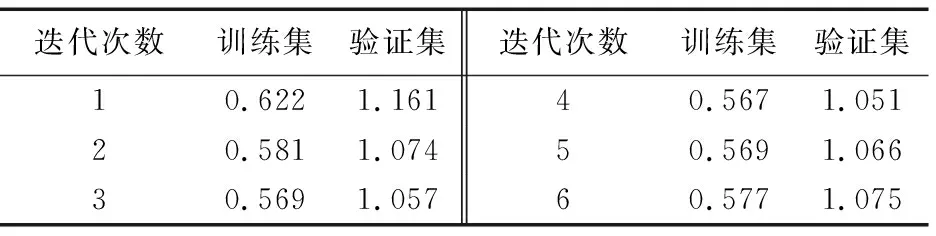
表1 不同特征聚合迭代后的平均损失Tab. 1 Average loss of different iterations of feature aggregation
表1中的数据显示循环特征聚合模型能够在几次连续的特征聚合迭代过程中持续提升检测效果,但是之后提升停止。这种现象可以从两个方面理解:一方面,循环特征聚合是有效的;另一方面,模型的模型效果最终下降的原因在于模型缺乏有效的记忆机制,记忆机制可提升对长序列的建模效果。尽管记忆机制对于提升模型的检测效果可能很有帮助,但是这会为模型引入额外的运算量和内存占用。这个实验结果指导了如何集成最终的目标检测结果。在之后两个实验中,本文通过在第3次、第4次和第5次迭代输出值上运行非极大值抑制算法来得到模型最终的检测结果。
3.2 在验证集上模型性能评估
本实验测量了循环特征聚合模型在目标检测任务中带来的提升。实验在从数据集中抽取的包含汽车的图像上完成。
在评估过程中,平均检测精度(mAP)在不同的IoU条件下分别计算得到。实验训练了一个用于检测汽车的SSD模型来作为实验精度的基准线。然后,本文使用同样的初始化方法和模型配置训练了的循环特征聚合(Recurrent Feature Aggregation, RFA)模型。循环特征聚合模型的检测结果在第3到5组输出值上运行非极大值抑制算法而得到。通过表2可以看到,循环特征聚合模型的检测精度比原本的SSD更高。因为SSD和循环特征聚合模型都使用ResNet101作为特征提取网络,所以检测结果的提升是由于添加了循环特征聚合结构。
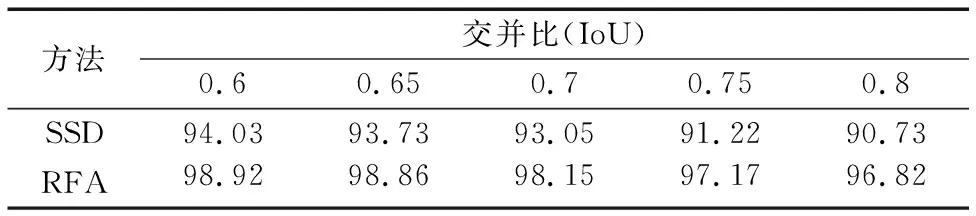
表2 在验证集上使用不同的IoU评估检测精度 %Tab. 2 mAP results on validation set for different IoU thresholds %
观察到在不同IoU条件下,特征聚合模型的精度总是要比SSD高。这可以进一步确认本文在实验一中得到的结论。当将评估模型的IoU提升到0.8时,循环特征聚合模型的检测精度要比原始的SSD高6.09个百分点。这个结果说明循环特征聚合结构可以有效地生成高质量的边界框。事实上,实验中指出的SSD生成边界框质量差的问题普遍存在于单阶段模型中,这也是限制单阶段模型达到更好检测精度的瓶颈。循环特征聚合模型在一定程度上解决了这个问题。
3.3 对比训练过程中模型检测精度及运算速度对比
本实验使用循环特征聚合模型与目前目标检测领域内典型的单阶段和双阶段目标检测模型的检测精度及运算速度作了对比,包括目前检测精度最高的双阶段模型Faster R-CNN[3]与R-FCN[7],以及单阶段模型YOLOv2[18]与SSD[2],循环目标检测模型则用RFA表示。对比模型的源代码从相应引用文献中获取,利用KITTI数据集重新训练,并记录了模型在每轮全样本训练后的检测精度。模型的检测精度使用IoU为0.7进行了评估。
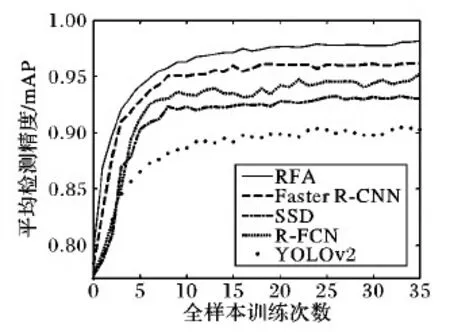
图3 不同模型检测精度在训练过程中的变化对比Fig. 3 mAP comparison of multiple detectors during training process

表3 模型运算速度对比Tab. 3 Processing speed comparison of multiple detectors
由对比结果图3可以看出,循环特征聚合模型的精度不仅比原始的SSD模型高5.1个百分点,并且比代表着最高检测精度的Faster R-CNN高2个百分点。从表3可以看出,由于循环特征聚合模型RFA在原始的SSD模型上添加了额外的特征聚合过程,所以造成了一定的性能下降,但是运算速度依然明显高于单阶段模型 Faster R-CNN 和 R-FCN。实验的结果确认了循环特征聚合结构的有效性,也对未来设计更精确的单阶段目标检测模型具有指导意义。
4 结语
本文提出了一种基于SSD模型,利用转置卷积操作改进的循环特征聚合结构,该结构可以有效地提升单阶段目标检测方法的检测精度。循环特征聚合能够持续地聚合特征图中的相关上下文信息,从而生成精确的检测结果。循环特征聚合结构在利用KITTI数据集的评估中达到了比双阶段目标检测模型更高的检测精度。
在未来的工作中,将研究将记忆机制引入循环特征聚合结构中,并且量化记忆机制对目标检测性能的影响。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
一重技术(2021年5期)2022-01-18
China’s foreign Trade(2021年6期)2021-12-26
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
汽车与新动力(2017年3期)2017-06-29
华人时刊(2016年16期)2016-04-05
中华奇石(2015年7期)2015-07-09
