
非参数化近似策略迭代并行强化学习算法
2018-11-20 06:09:36季挺,张华
计算机工程 2018年11期
季 挺,张 华
(南昌大学 江西省机器人与焊接自动化重点实验室,南昌 330031)
0 概述
近似策略迭代强化学习通过近似计算更新当前的值函数评估策略,并采用贪心方法来改进策略,其是解决传统强化学习“维数灾难”问题的主要方法之一。文献[1]证明近似策略迭代方法的收敛性,并提出LSPI算法,但该算法为离线算法,计算量较大、收敛速度较慢。文献[2]提出online LSPI算法,以解决LSPI的在线计算问题。文献[3]在online LSPI的基础上提出BLSPI算法,该算法进一步提高了样本利用率,并在一定程度上降低了计算量,但其依然未能彻底解决在线近似策略迭代强化学习收敛速度较慢的问题。此外,在以上算法中,强化学习的结构、参数均依赖先验知识或通过反复试凑来确定,使算法不具备自动构建的能力。
并行强化学习是解决经典强化学习算法收敛速度较慢问题的途径之一。本文将并行强化学习与近似策略迭代强化学习相结合,提出一种非参数化近似策略迭代并行强化学习算法NPAPI-P。将NPAPI-P 算法应用于一级倒立摆平衡控制问题,并通过仿真验证该算法的有效性和快速收敛能力。
1 并行强化学习
并行强化学习与多智能体强化学习对目标任务分而治之,通过强化学习单元(以下简称为学习单元)相互协作提升学习性能的思路不同,其学习单元之间互不影响、各自独立地在整个状态空间进行学习[4-5],通过对各单元经验地融合来加快学习的收敛速度。
文献[4]对并行强化学习进行了开创性的研究,其采用delta规则实现单个学习单元,采用经验加权法进行各单元的融合及融合信息的反馈,它的研究成果被用于解决多臂老虎机问题。文献[6]遵循文献[4]的研究思路,将并行强化学习用于解决海星机器人沿单轴前进的问题,所不同的是,其采用异步更新的方式实现各学习单元的融合以及融合信息反馈。文献[7]依旧采用文献[4]的思路,将并行强化学习用于解决网格寻径问题,所不同的是,其学习单元采用贝叶斯强化学习算法实现。文献[8]提出的并行强化学习方法采用Q学习算法实现单个学习单元,采用D-S证据理论对各单元进行融合,融合信息直接反馈成为各单元的策略,同时提出加速比和效率的概念作为评价并行强化学习方法性能的指标,其研究成果被用于解决网格寻径和机器人避障问题。文献[9]提出的并行强化学习方法采用Q学习算法实现单个学习单元,采用全局Q表融合各单元的信息,且融合信息不反馈至单个单元,该算法被用来解决交通控制问题并取得了较好的效果。文献[10-11]提出的并行强化学习方法采用近似SARSA(λ)算法实现单个学习单元,采用部分参数异步更新的方式实现各单元的融合以及融合信息的反馈,其研究成果用于解决网格寻径、Mountain Car和倒立摆控制问题。 文献[12]提出的并行强化学习方法采用BP神经网络实现单个Q学习单元,采用D-S证据理论对各单元进行融合,其研究成果被用于解决路径规划问题。
综上所述,近年来,对并行强化学习的研究较少,多数只用于解决小规模、离散状态和动作空间中的问题,且并行学习单元数量均需人工确定。
2 NPAPI-P算法结构及其学习步骤
NPAPI-P算法网络结构由状态输入层、学习单元层、票箱层和动作输出层构成,如图1所示。
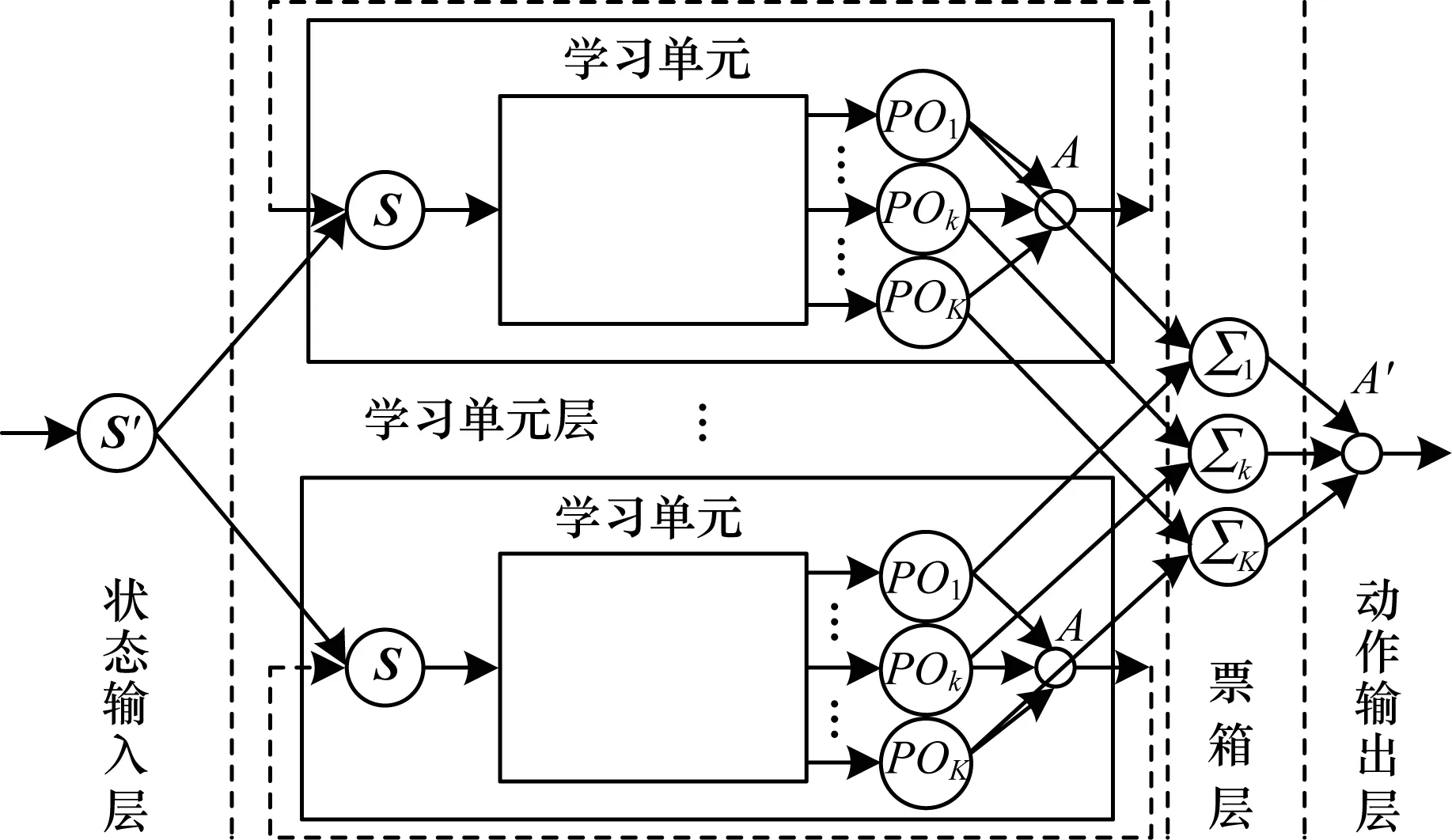
图1 NPAPI-P算法网络结构
Σk=ΣPOk
(1)
动作输出层输出当前状态S′下应执行的动作A′,A′采用贪心策略定义为:
(2)
NPAPI-P算法运行时,所有单元独立地在整个状态动作空间中进行学习,且各单元在每次尝试结束后进行一次联合尝试,以加快强化学习的收敛速度。NPAPI-P算法具体步骤如下:
步骤1设置强化学习的允许误差率ε。
步骤2通过学习单元构建样本采集过程,以确定单元数量,通过学习单元自动构建过程来生成所有学习单元。
步骤3各单元通过学习单元自主学习过程分别进行一次尝试,若有单元尝试成功,则该单元策略为算法整体策略,算法结束。否则执行步骤4。
步骤4所有单元进行一次联合尝试。联合尝试通过式(1)融合所有学习单元的策略,通过式(2)选择算法在当前状态S′下应执行的动作A′,但并不更新各学习单元的参数。若联合尝试成功,则各单元联合策略为算法整体策略,算法结束。否则执行步骤3。
3 学习单元数量确定
在并行算法中,并行单元数量决定了算法的加速比和效率,若并行单元数量较少会使得加速比较低,若数量过多则容易导致算法效率下降,因此,选择合适的学习单元数量是并行强化学习的关键。本文依据强化学习的允许误差率ε,通过学习单元构建样本采集过程以确定强化学习单元的数量。学习单元构建样本采集过程分为局部过程和总体过程2个方面。
3.1 局部过程
局部过程依据预先设置的ε为单个单元自动采集用于单元构建的状态样本,其步骤如下:
步骤1采用随机策略运行一次目标系统。设置采样次数tm=1,目标系统运行次数tr=1,采样缓存长度L=step,其中,step为目标系统本次运行持续的时间步数。将本次采样得到的样本集合记为samtm,通过式(3)和式(4)分别计算其均值meantm及其在各维分量上的平均绝对离差向量madtm。
(3)
(4)
其中,ns为samtm中样本的数量,abs()用于计算向量在各维分量上的绝对值。
步骤2开始单次采样。tm=tm+1,初始化单次采样,新增非重复样本数量ln=0,使temp=samtm-1。
步骤3采用随机策略运行一次目标系统。tr=tr+1,收集本次运行采集到的样本集合Tsam,同时更新step和rep的值,其中,rep为Tsam与temp中重复样本的数量。
步骤4使temp=temp∪Tsam,更新ln与L的值。
ln=ln+step-rep
(5)
(6)
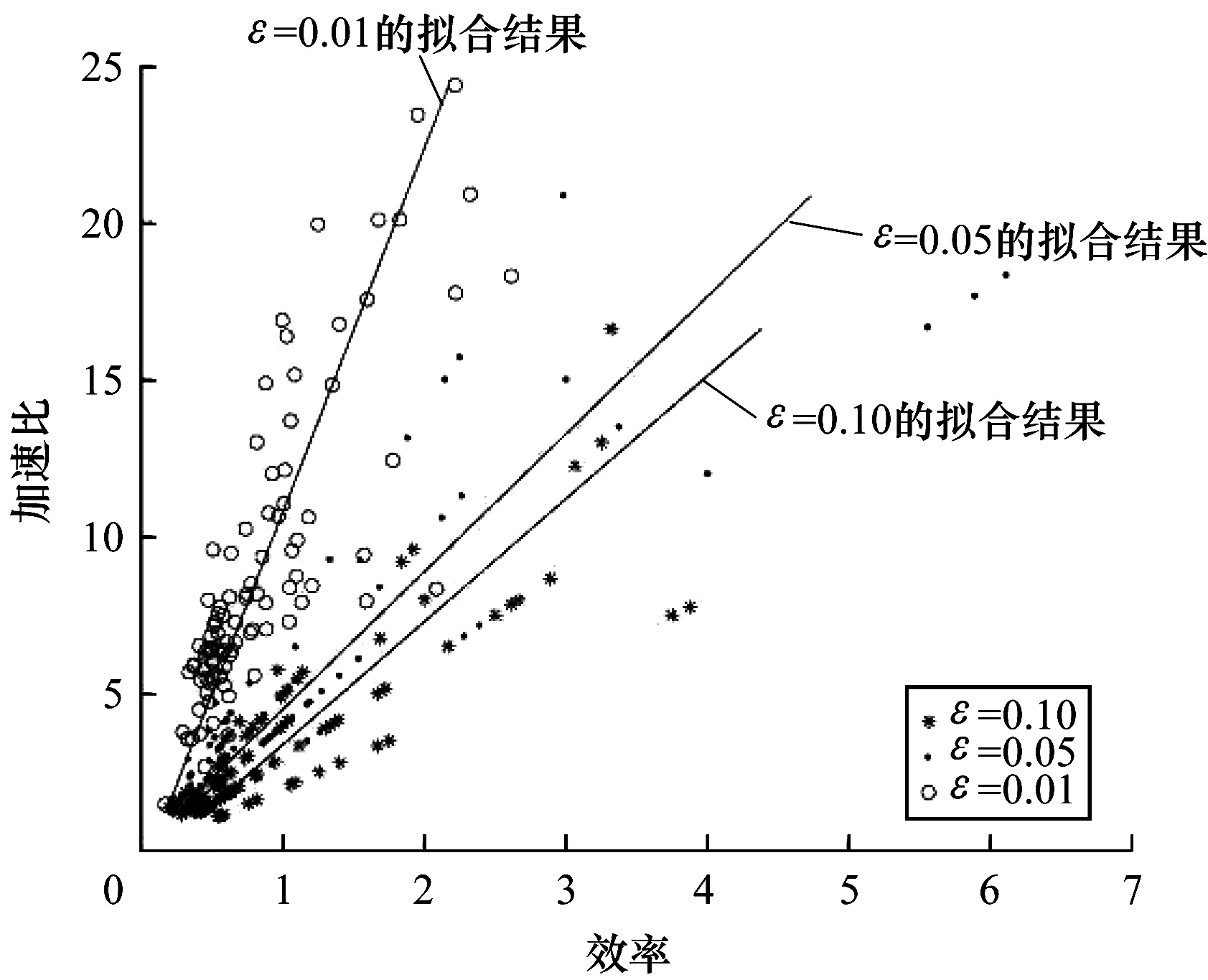
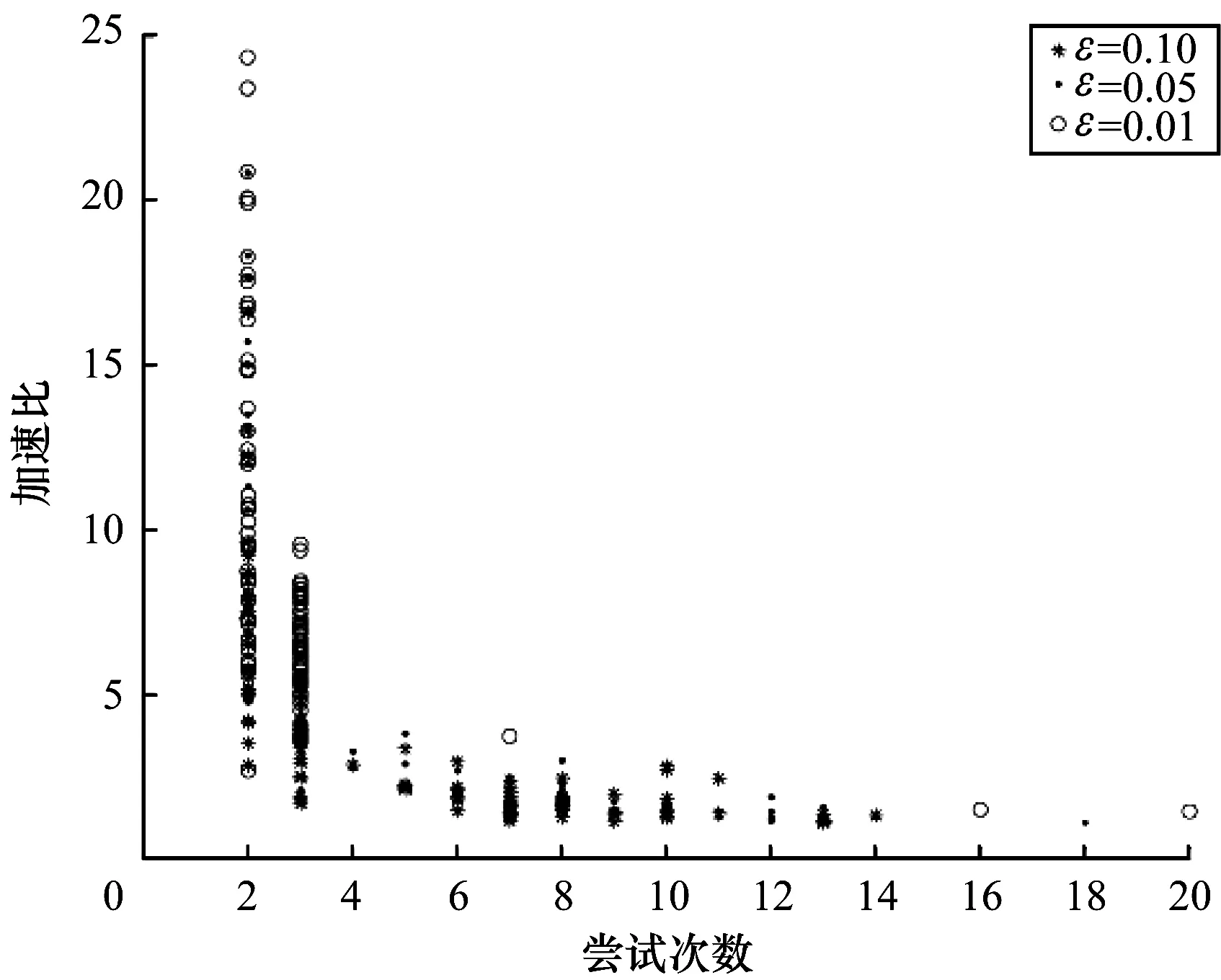
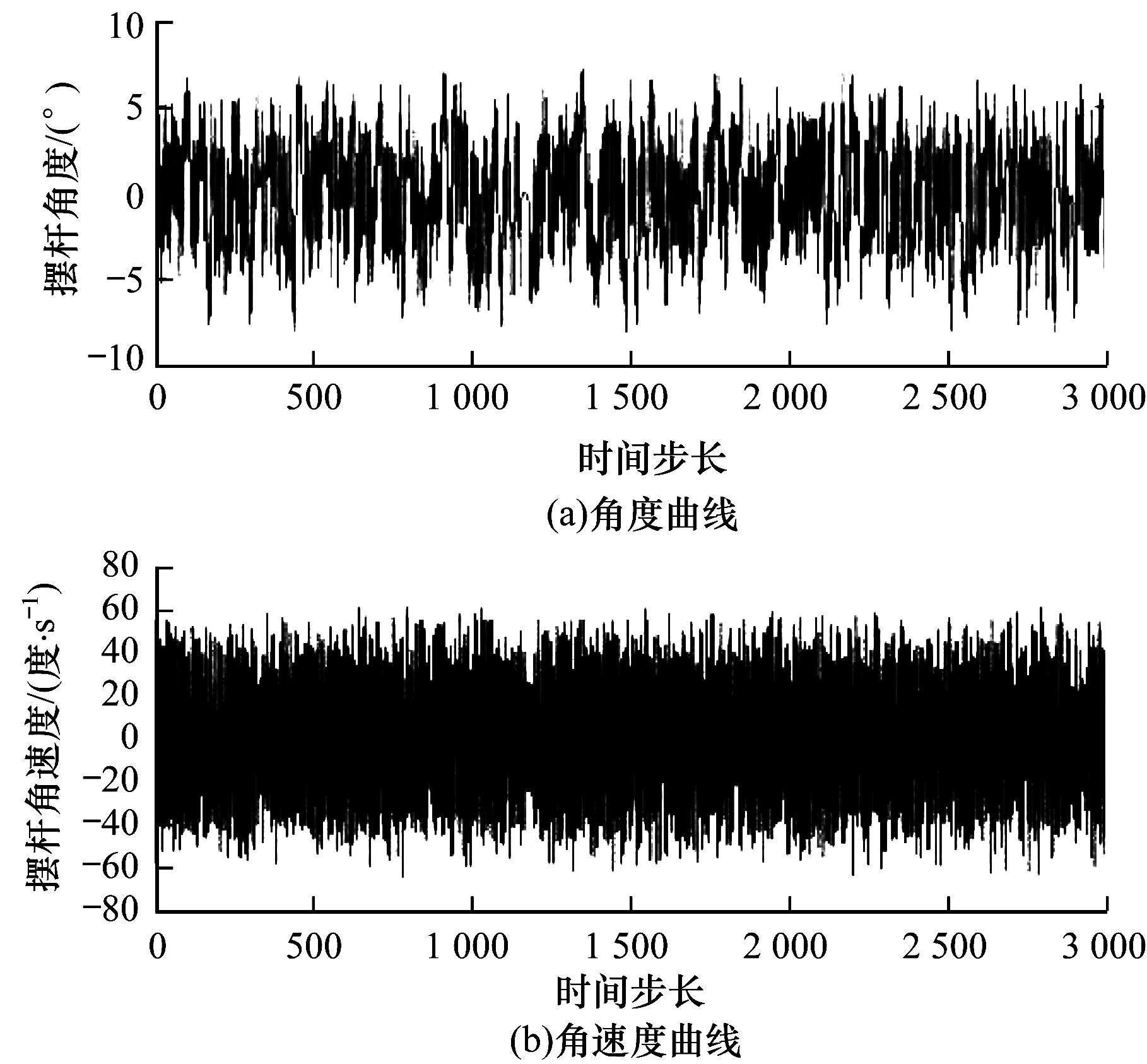
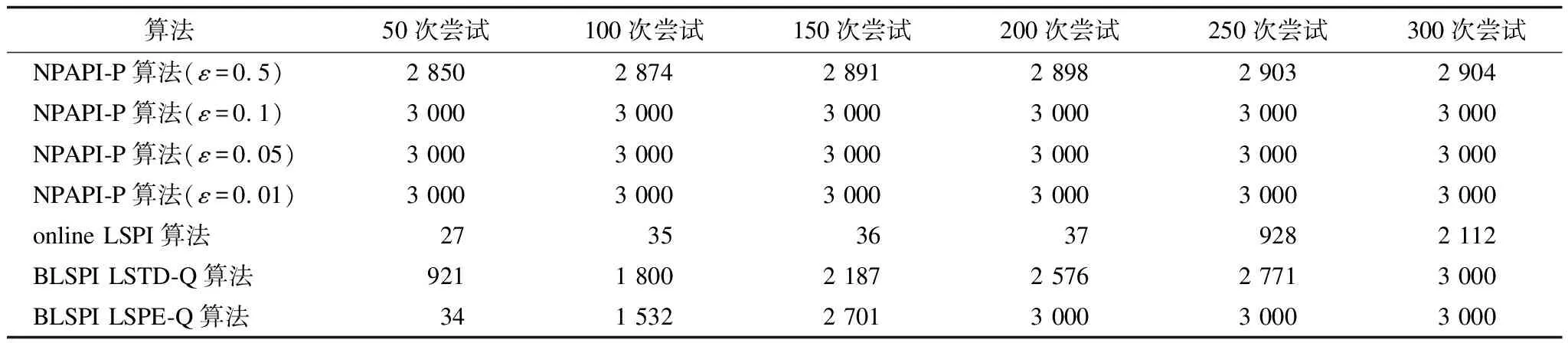
若ln 步骤5通过式(3)和式(4)计算meantm和madtm。 步骤6通过式(7)计算samtm相对samtm-1的变化率rate,rate随samtm对样本空间覆盖率的提升而逐渐减小。 rate=‖(rate1,rate2,…,ratei,…,raten)‖2 (7) fbcl={fci,bci,fli,bli} fc=meantm-madtm bc=meantm+madtm fl=meantm-1-madtm-1 bl=meantm-1+madtm-1 步骤7若rate<ε,获得一个单元的构建样本集sam=samtm,局部过程结束。否则,执行步骤2。 总体过程依据ε来确定学习单元数量,其步骤如下: 步骤1新增一个学习单元,使单元数NU=1。通过局部过程获取其构建样本集sam,并初始化总体样本集SAMNU=sam,通过式(3)和式(4)分别计算SAMNU的均值MEANNU及其在各维分量上的平均绝对离差向量MADNU。 步骤2新增一个学习单元,使单元数NU=NU+1。通过局部过程获取其构建样本集sam,使SAMNU=SAMNU-1∪sam。 步骤3通过式(3)和式(4)计算MEANNU和MADNU。 步骤4通过式(7)计算SAMNU相对SAMNU-1的变化率RATE,RATE随SAMNU对样本空间覆盖率的提升而逐渐减小。 步骤5若RATE<ε,学习单元不再增加,总体过程结束。否则,执行步骤2。 学习单元由在线近似策略迭代强化学习算法实现,其网络结构由状态输入层、Q值函数逼近器和动作选择器组成,如图2所示。 图2 学习单元网络结构 Q值函数逼近器由基于RBF(Radial Basis Function )的线性逼近结构实现,状态动作对(S,A)对应的近似Q值计算公式如式(8)所示。 Q(S,A)=ΦT(S)ω(A) (8) 其中,Φ(S)=(Φ1(S),Φ2(S),…,Φj(S),…,Φm(S))T为状态S在各基函数下的归一化隶属度向量,其元素定义为: (9) 其中,φ(S)=(φ1(S),φ2(S),…,φj(S),…,φm(S))T为逼近器的状态基函数向量,其值为状态S在各状态基函数下的隶属度,m为φ(S)的维数。φ(S)的元素使用RBF函数定义为: (10) 其中,μj=(μ1j,μ2j,…,μij,…,μnj)T和δj=(δ1j,δ2j,…,δij,…,δnj)T分别为基函数φj的中心和半径,μij和δij分别为φj在第i维状态分量上的中心和半径。 ω=(ω1,ω2,…,ωj,…,ωm)T为逼近器的插值参数向量,其意义为在各状态基函数中心执行所选动作A的Q值,ω的元素利用插值方法[13]定义为: (11) (12) 其中,η为Q值函数逼近器的平均学习率,由学习单元的初始状态基函数构建过程确定,Δ为TD误差,定义为: (13) 其中,rt为即时奖励,γ为折扣率。 状态基函数向量φ的参数和维数、插值参数向量ω的维数由Q值函数逼近器自动构建过程依据采样样本确定,并在学习过程中自适应调整。 动作选择器采用贪心策略定义为: (14) 其中,POk是学习单元对在当前状态S下执行动作ak的投票结果,其计算表达式为: (15) 学习单元自动构建过程的核心是构建Q值函数逼近器,其由核心状态聚类生成过程和初始状态基函数构建过程组成。 核心状态聚类生成过程基于相对准则和轮廓指标,采用K均值聚类算法实现,其目的是为构建初始状态基函数提供初值,具体步骤如下: (16) 步骤2遍历num,对当前遍历的聚类数numv运行K均值聚类算法,得到聚类结果clusv及其相应的聚类有效性valv,valv采用轮廓指标[15]计算,如下: (17) 步骤3若num遍历结束,则通过式(18)输出sam的最佳聚类结果CLU,并将CLU作为核心状态聚类,执行步骤4。否则,执行步骤2。 CLU=clusID (18) 步骤4计算CLU中每个聚类的中心和半径,并将其存入核心聚类中心矩阵cen和半径矩阵rad中。CLU中单个聚类C的中心Cc为C中所有元素的均值,通过式(19)计算;半径Cr为C中每个元素与其中心Cc在各维分量上的距离均值向量,通过式(20)计算。 (19) (20) 其中,Cz为聚类C中的一个元素,nc为聚类C中元素的数量。 状态基函数的形式如式(10)所示。为提升状态基函数对样本空间的覆盖率,使其尽可能完整地反映状态空间的分布,本文提出一种以样本空间完全覆盖为目标的模糊估计方法,以计算逼近器的状态基函数和平均学习率。具体步骤如下: 步骤1利用核心聚类中心矩阵cen和半径矩阵rad初始化基函数向量φ的中心和半径。 步骤2遍历构建样本集sam。通过欧氏距离获取与当前遍历样本Csam最邻近的基函数φnear。若Csam在各维上的分量均落在φnear内部,则继续执行步骤2;否则,结束本次遍历,执行步骤3。若sam中所有样本均在最邻近基函数内部,则表明状态基函数完成了对样本空间的完全覆盖,执行步骤5。 步骤3新增一个状态基函数,将其中心初始化为Csam,并加入φ中。 步骤4通过式(21)和式(22)调整φ中所有基函数的中心和半径,执行步骤2。 (21) (22) 其中,behj为样本(sam)h到状态基φj的归一化隶属度。 步骤5通过式(23)计算学习单元的强化学习率η,初始状态基函数构建过程结束。 (23) 其中,X=(X1,X2,…,Xj,…,Xm)T为各基函数的构建样本数向量,其元素表示为: 学习单元自主学习过程的重点是实现逼近器状态基函数和参数的自适应调整。其中,参数的自适应调整如式(12)所示,状态基函数的自适应调整如下。 状态基函数的自适应调整步骤为: 步骤1若输入状态S属于状态基函数的构建样本集sam,则继续执行步骤1判定下一输入状态;否则,将S加入构建样本集sam,执行步骤2。 步骤2通过欧式距离获取与S最邻近的基函数φnear。 步骤3若φnear为初始状态基函数,TD误差率RΔ>ε(RΔ的计算如式(24)),且S的任意一维分量落在φnear外部,则新增状态基函数φnew,并初始化其中心μnew=S,半径δnew=δnear,执行步骤4;否则直接执行步骤4。 (24) 步骤4采用delta规则调整状态基函数的中心和半径,对φj有: μj=μj+ηRΔBEj(S-μj) (25) δj=δj+ηRΔBEj(abs(S-μj)-δj) (26) 本次调整结束后执行步骤1,开始下一次状态基函数调整过程。 步骤1学习单元开始一次尝试。初始化当前状态St=S0。若本次尝试未结束,循环执行下列步骤: 1)使用式(10)计算St在各状态基函数的隶属度向量φ(St)。使用式(9)计算St在各基函数下的归一化隶属度向量Φ(St)。 2)使用式(15)计算当前状态下执行动作ak的投票结果,使用式(14)选择当前状态下应采取的动作At,获取即时奖励r,且环境转移到下一状态St+1。 3)依据式(12)调整Q值函数逼近器参数向量进行策略改进,依据状态基函数的自适应调整过程更新构建样本集和状态基函数。设置当前状态St=St+1。 步骤2若本次尝试成功,则学习单元学习结束。否则,执行步骤1再次进行尝试。 从以上步骤可以看出,单个学习单元在学习阶段的计算复杂度主要由策略评估复杂度O(Km)、策略选择复杂度O(K)、策略改进复杂度O(K+Km+K2m)以及基函数调整复杂度O(m)组成,即总体复杂度为O(2K+(K2+2K+1)m),远小于其他近似策略迭代强化学习算法的时间复杂度O(m3)[3],说明该过程可以更好地满足在线计算的要求。 一级倒立摆平衡控制问题是强化学习的标准测试问题,本文通过对该问题的仿真实验来验证NPAPI-P算法在不同测试条件下的有效性。另外,由于本文提出的学习单元由近似策略迭代强化学习算法实现,因此采用文献[1]方法,如式(27)所示,建立倒立摆系统模型。 (27) 仿真时间步长设置为0.1 s,折扣率γ=0.95。在仿真中,若摆杆偏离垂直方向角度超过90°,则失败;若摆杆在上述约束条件下保持指定时间步长不倒,则成功。相应的即时奖励r计算表达式如式(28)所示。 (28) 加速比和效率是并行算法的重要评价指标,NPAPI-P算法每次运行时的加速比JSB和效率XL分别由式(29)和式(30)定义。 (29) (30) 其中,NLT为各学习单元平均收敛尝试次数,NPT为并行学习收敛尝试次数,NL为学习单元数量。由上述定义可知,若并行算法不具备加速效果,则JSB∈[0,1],XL∈[0,1/NL],其中,1/NL称为临界效率。 设置实验目标为倒立摆运行3 000时间步长不倒,实验最大尝试次数为300,当ε=0.1时,离散动作集合分别取2个离散值{-50 N,+50 N}、3个离散值{-50 N,0,+50 N}、4个离散值{-50 N,-25 N,+25 N,+50 N}、5个离散值{-50 N,-25 N,0,+25 N,+50 N}、6个离散值{-50 N,-33 N,-16 N,+16 N,+33 N,+50 N}、7个离散值{-50 N,-33 N,-16 N,0,+16 N,+33 N,+50 N}、8个离散值{-50 N,-37.5 N,-25 N,-12.5 N,+12.5 N,+25 N,+37.5 N,+50 N}、9个离散值{-50 N,-37.5 N,-25 N,-12.5 N,0,+12.5 N,+25 N,+37.5 N,+50 N}、10个离散值{-50 N,-40 N,-30 N,-20 N,-10 N,+10 N,+20 N,+30 N,+40 N,+50 N}、11个离散值{-50 N,-40 N,-30 N,-20 N,-10 N,0,+10 N,+20 N,+30 N,+40 N,+50 N}。在以上离散动作集合取值下分别进行100次独立仿真运算,实验结果如表1所示。 表1 在不同离散动作集合取值下的实验结果 从表1可以看出,不论离散动作集合如何取值,NPAPI-P算法均具有较快的收敛速度,能够在较短尝试次数内学习到一级倒立摆系统的平衡控制策略,并且在保持较高加速比(与1比较)的同时具有较高的效率(与平均临界效率比较),从而验证了NPAPI-P算法在离散动作集合不同取值下的有效性。 接下来,设置实验目标为倒立摆运行3 000时间步长不倒,实验最大尝试次数为300,当离散动作集合取3个离散值{-50 N,0,+50 N}、ε取0.5、0.1、0.05、0.01,分别进行100次独立仿真运算,实验结果如表2所示。 表2 在不同ε取值下的实验结果 从表2可以看出,当ε取0.5时算法失败,这是由于ε过大,导致学习单元构建样本集无法反映样本空间的主要分布特征。当ε满足学习单元构建要求时,随着ε减小,NPAPI-P算法能够更快地学习到一级倒立摆系统的平衡控制策略,并且在保持较高加速比(与1比较)的同时具有较高的效率(与平均临界效率比较),从而验证了NPAPI-P算法在ε合理取值下的有效性。在不同ε取值下NPAPI-P算法加速比与效率的关系如图3所示。 图3 在不同ε取值下算法加速比与效率的关系 从图3可以看出,当ε确定后,NPAPI-P算法的学习单元数量(拟合直线的斜率)基本维持稳定,且随着ε减小,学习单元数量逐渐增加。其中,当ε=0.1时,平均单元数量为3.4个,当ε=0.05时,平均单元数量为4.5个,当ε=0.01时,平均单元数量为10.6个。结合表2中的相关数据可以看出,相较于已有文献将并行单元数量人为确定为10个~20个的方法,NPAPI-P算法能够依据实际情况更好地平衡加速比和效率间的关系。在不同ε取值下NPAPI-P算法的加速比与收敛速度的关系如图4所示。 图4 在不同ε取值下算法加速比与收敛速度的关系 从图4可以看出,当ε在合理范围内取值时,NPAPI-P算法都趋向于在较高加速比下快速收敛,且ε越小,这一趋势越明显,表明该算法具有良好地并行加速性能。 最后,设置实验目标为倒立摆运行3 000时间步长不倒,实验最大尝试次数为300,当离散动作集合取3个离散值{-50 N,0,+50 N}、ε取0.1时,进行100次独立仿真运算,得到算法的学习性能如图5所示。 图5 NPAPI-P算法学习性能 在图5中,算法学习成功的尝试次数最小为2次,最大为14次。选择倒立摆进行2次尝试即成功的典型学习过程,其学习成功的曲线如图6所示。从图6可以看出,摆杆的摆动角度基本稳定在[-5°,+5°],角速度基本稳定在[-60°/s,+60°/s]。以上数据验证了NPAPI-P算法在控制能力上的有效性。 图6 ε=0.1时3个离散动作的典型学习成功曲线 在线近似策略迭代强化学习算法的优劣一般通过不同参数条件下获得控制策略的速度进行评价,收敛速度越快,算法性能越好。将NPAPI-P算法在ε取0.5、0.1、0.05和0.01时进行100次独立仿真运算的结果,与典型在线近似策略迭代强化学习算法online LSPI、BLSPI的最优实验结果[3]进行比较,3种算法在不同尝试次数下的平均平衡时间步长如表3所示。其中,LSTD-Q和LSPE-Q是BLSPI算法采用2种不同策略的评估算法,后者与前者的主要区别在于处理每个样本数据后都要更新参数。 表3 3种算法在不同条件下的平均平衡时间步长对比 从表3可以看出,当ε≤0.1时,由于学习单元构建样本集能够反映一级倒立摆样本空间的主要分布特征,此时,NPAPI-P算法可在50次尝试内完全学习到一级倒立摆的平衡控制策略。针对相同的学习目标,BLSPI算法平均需要200次尝试才能完成,online LSPI算法平均需要300次尝试才能完成。由此可以得出,NPAPI-P算法的学习速度明显快于online LSPI算法和BLSPI算法。 3种算法的参数数量情况如表4所示,从表4可以看出,NPAPI-P算法只需指定强化学习允许误差率ε即可实现算法的自主构建和学习,而BLSPI算法需要手工确定4+m个参数,online-LSPI算法需要手工确定5+m个参数,其中,m为状态基的数量。由此可见,NPAPI-P算法完全实现了强化学习算法的非参数化,其易用性和自学习能力均超过online LSPI算法和BLSPI算法。 表4 3种算法的参数数量对比 本文提出一种非参数化近似策略迭代并行强化学习算法NPAPI-P。该算法只需指定强化学习的允许误差率,就能完全自主地构建、调整学习单元,进而快速学习到解决目标问题的控制策略。一级倒立摆平衡控制实验比较收敛速度、加速比、效率和控制精度等指标,结果表明,相对online-LSPI算法和BLSPI算法,本文算法在不同离散动作和强化学习允许误差率下均具有有效性,且收敛速度更快。针对NPAPI-P算法收敛性的理论证明,将是今后的研究重点。3.2 总体过程
4 学习单元结构
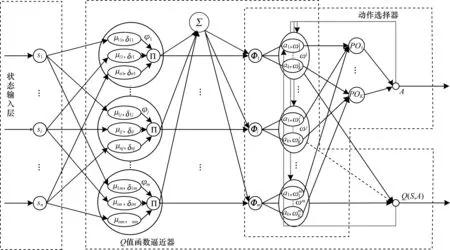
4.1 状态输入层

4.2 Q值函数逼近器

4.3 动作选择器

5 学习单元自动构建过程
5.1 核心状态聚类生成
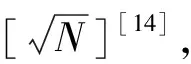


5.2 初始状态基函数构建
6 学习单元自主学习过程
6.1 状态基函数的自适应调整
6.2 学习单元的学习步骤

7 一级倒立摆平衡控制实验
7.1 实验描述

7.2 评价指标
7.3 实验结果

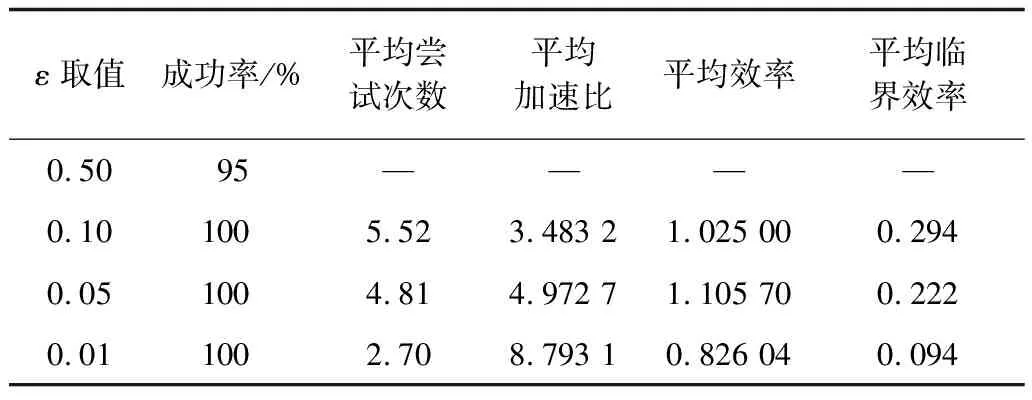

7.4 与典型在线近似策略迭代强化学习算法对比

8 结束语
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
阅读与作文(英语高中版)(2019年11期)2019-09-10 07:22:44
学生天地(2019年29期)2019-08-25 08:52:26
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
小主人报(2018年11期)2018-06-26 08:52:18
北极光(2018年12期)2018-03-07 01:01:58
电子测试(2017年15期)2017-12-18 07:19:27
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
智能系统学报(2015年4期)2015-12-27 09:38:39
