
面向姿态估计的组件感知自适应算法
2018-11-20 06:09:24陈耀东彭蝶飞
计算机工程 2018年11期
陈耀东,刘 琴,彭蝶飞
(1.长沙师范学院 a.信息与工程系; b.科研与学科建设处,长沙 410100; 2.湖南省教育科学研究院 职业教育与成人教育研究所,长沙 410005)
0 概述
姿态估计主要针对图像数据的人体组件定位问题,是当前图像识别领域的一个热门研究[1],具有广泛的应用前景。区别于图像分类,姿态估计模型一般考虑建立组件外观和组件空间关系,将组件定位转换为一个结构化分类问题[2]。估计模型的参数学习一般基于传统的监督学习方式[3-4],监督学习的一个前提假设是训练数据集(以下简称为源集)与测试数据集(以下简称为目标集)处于相同或趋近的特征分布,这在现实环境中通常难以满足。例如通过田径运动场景的运动员动作集训练而成的姿态估计模型去识别停车场监控视频中的行人姿态,由于2种数据集在人体姿态分布上具有较大差异,采用传统学习算法获取的估计模型其泛化性能难以保证。领域自适应(Domain Adaptation,DA)是近几年提出的一种新的机器学习方法,能有效地解决上述分布差异环境下的参数学习问题[5-7]。在DA中所谓的“领域”差异从狭义上说是源集和目标集的分布差异,而广义上还可指代为待学习模型的任务差异。DA目前在人工智能的各个领域都有相关的应用,例如自然语言处理的中文分词[8]、情感分析[9],计算机视觉的图像分类[10]、目标检测[11-12]等二值分类任务。另外,文献[13]提出了一种面向结构化输出的DA算法,该算法重新定义了结构化支持向量机(Structural SVM,S-SVM)[14]的损失函数。在优化目标参数的同时保持其与源参数的相似性,该算法成功应用于部件标注任务的跨领域学习。
在上述的DA方法中,多数是将目标参数作为一个整体来考虑与源参数的自适应程度,这对于图像分类[10]、目标检测[11]等基于全局特征的识别方法行之有效,但在基于局部特征的识别方法(例如基于部件的方法)中受到限制。因为对于此类算法的目标参数而言,不同局部特征指向的目标参数其自适应度(或者说迁移度)并不一致,典型的如姿态估计场景,头部、躯干无论在外观还是相对位置,变化程度均比手臂、脚部等更小,那么自适应度相对较高,反之亦然。可见,“细粒度”的自适应学习能够使得目标模型更具鲁棒性。为此,本文提出一种组件感知的自适应学习算法。该算法的训练过程将目标的整体学习更改为各组件独立学习自适应过程,即各组件能够自动感知“合适的”自适应权重。为使学习过程效率更高,本文引入基于主动学习的2种样本选取策略。通过选取对知识迁移有用的样本子集进行训练,从而加速参数学习的收敛过程。
1 姿态估计任务
图1展示了姿态估计任务的基本过程。给定的某目标图像,通过一个已学习的估计模型(见图1(a))自动定位该目标预定的一个组件集(见图1(b))。当前的估计模型主要采用判别统计模型,下面给出具体的形式化描述。
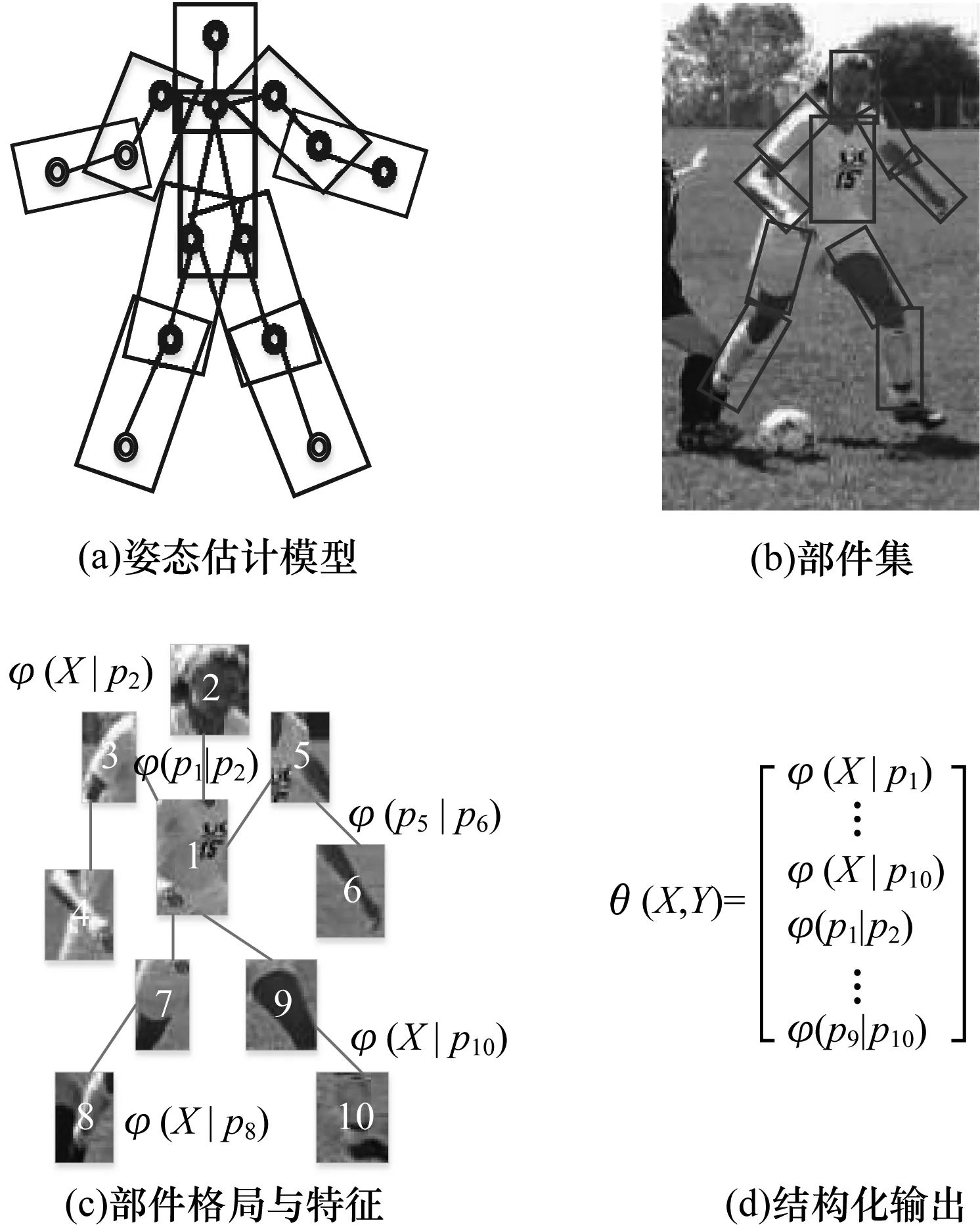
图1 姿态估计的主要任务
假设待估计目标由p个组件构成,每个组件由向量h=(x,y,l,θ)定位,其中,(x,y)表示该组件的坐标,(l,θ)分别代表尺度和方向。姿态估计的计算过程即是在给定的目标图像I中搜索所有可能的姿态H并且选择具有最高得分的姿态。候选姿态H的得分可用下式计算:
(1)
(2)
(3)

-(d1,d2,d3,d4,d5,d6,d7,d8)T·
(Δx,Δx2,Δy,Δy2,Δl,Δs2,Δθ,Δθ2)
(4)
Δx=(xi-xj),Δy=(yi-yj),…,Δθ=(θi-θj)
(5)
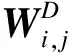

(6)
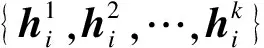
Score(H,I)=W·φ(H,I)
(7)
(8)
姿态估计的目标即是在给定的目标图像中找出最佳的姿态候选:
H*={(h0,t0),(h1,t1),…,(hp,tp)}
满足:
H*=argmaxScore(H,I)
其中,hi和ti分别代表第i个组件的位置向量和子类型。不同于目标检测[15],姿态估计输出具有树状结构的结果值H(见图1(d))。估计模型的参数学习一般采用传统的学习算法,如S-SVM[14],但此类算法只有假定源集与目标集处于相同的特征分布才能达到有效的学习,当现实环境不满足假设时将限制W的泛化性能。下一节将讨论基于DA的结构化学习算法,以解决源集与目标集处于不同分布场景的参数学习问题。
2 DA算法
本节首先阐述组件感知的DA算法,然后介绍基于主动学习的样本选取策略,最后对两者进行整合。
2.1 基于组件感知的DA算法
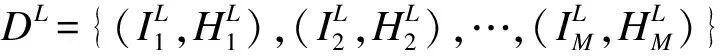
minWR(W)+C·L(W,DL)
(9)
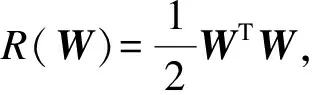
(10)
对比式(9)和式(10)可以看出,自适应学习不是直接优化目标参数W,而是希望从目标训练集DL中找到一个与源参数WS接近的目标参数W,同时满足该参数在DL中具有最小的分类损失值。由第1节可知,姿态估计的参数向量W即是所有组件权重向量的线性组合,若根据式(10)的优化,每个组件均以相同的权重控制对应参数集Wi的自适应过程。事实上,每个组件的分布差异程度是不同的,例如人的头部外观变化相比前肢变化要小,因而分布差异度也较小。基于此,本文重新定义正则算子,引入β=(β1,β2,…,βp)代表每个组件的自适应权重,即:
(11)
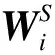
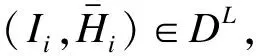
(12)


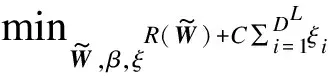
(13)
式(13)适于归入二次规划问题求解,其对偶形式为:
(14)
式(14)的计算与常规的S-SVM相仿,本文限于篇幅不做具体阐述,详见文献[14],参数优化过程与样本选取策略整合后的算法见2.2节。最终目标函数形式如下式所示。
ΔW′·φ(H,X)]
(15)
目标分类器由源分类函数与差值函数2部分组成,注意源分类函数是由带有适应权重的多个组件分类器组合而成。
2.2 样本选取
2.1节的组件感知DA算法仍是基于监督学习方式,即采用目标领域的标注训练样本集DL作为目标参数的训练依据。对监督学习方式而言,标注训练集的“质量”是影响算法分类性能的一个重要因素。若标注实例具有足够的代表性或者判别性,则通过式(12)得到的目标参数W具有更强的泛化能力。当目标集规模庞大,随机选取是唯一可行的方法,但如果目标集规模不大,主动学习显然更为有效。从样本添加方式上,目前主动学习研究有基于样本池和基于数据流的2种,简单而言,前者是逐个添加样本,后者是批量添加。主动学习的研究更多着重于选取策略,主要有基于不确定度的方法、基于样本空间缩减的方法、委员会方法、基于未来泛化误差率缩减的方法等[17],文献[18]基于SVM的学习过程提出了2种主动学习策略——基于最不确定的和基于最确定的样本选取,实验证明了2种方式都比未采用主动学习策略效果要强。
区别于上述方法,本文则是从自适应的角度看待样本选取,即趋向于选取对知识迁移有用的样本子集。本节将讨论2种样本选取策略——基于损失率与基于歧义性的方法,选取“高质量”的样本子集作为训练用的标注对象。从原理上看,基于损失率的方法即是考虑缩减目标函数的泛化误差率,基于歧义性的方法即是考虑选取最不确定性样本。
为方便说明,本节将式(1)的Score函数简记为F,由源集D0训练的分类函数记为F0,目标数据集仍记为D,DL⊆D表示从D当中选取的人工标注样本集。假设P(Y|X)为某个图像样本X∈D的条件概率,Y为对应的分类值,且有P(X)为该样本的边概率。若式(1)采用经典的结构化分类方法优化,则函数F的期望风险R(F)表示为:
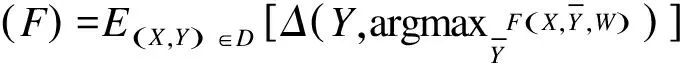
EXEY|X(ΔF(Y))
(16)
其中,ΔF(Y)度量函数F对于训练样本X的输出损失度,由式(12)计算。E(X,Y)、EX、EY|X分别表示(X,Y)的联合分布、X的边分布和Y的条件分布。因真实的联合分布无法获知,本文将期望风险用经验风险拟合:
(17)
根据2.1节提出的自适应算法,本文希望求取一个子集DL,满足:
DL*= argmaxDL⊆D(R(F0)-R(F))≈
(18)
式(18)旨在找到一个合适的子集DL⊆D,能最大化的表示源函数损失度ΔF0(Y)与目标函数损失度ΔF(Y)的差异值。类似于文献[19],这里假设目标函数F的损失度归于0或者某个训练时设定的极小值ξ,得到
(19)
由于式(19)可能的标注子集数目非常大(共有2|D|),采用主动学习策略从目标集D当中逐个挑选样本加入DL是一种有效的解决方法,本文共提出了2种样本选取策略。为了描述直观,采用二值线性SVM示意相关理论,见图2。

图2 自适应学习原理与主动学习策略
1)期望损失最大的实例选取(Most Expected-Error Case Selection,MECS)。由于无法获取目标样本PX∈DL(Y|X)的条件概率分布,因此假设PX∈DL(Y|X)≈PX∈D0(Y|X)≈PX∈D0(Y)。定义PX∈D0(Y)为Y的每个具体组件类型在源集D0上的频率分布:
(20)
其中,freD0(pi)代表在组件pi在源集D0中的出现频率,根据式(20),MECS在目标集上选取对于源分类器F0具有最大损失率的样本(如图2(b)所示),即:
X*=argmaxX∈DDLPX∈DL(Y)ΔF0(Y)
(21)
Y=argmaxF(H,X)
对DA问题而言,此实例能最大的反映2个数据集的分布差异,对目标集而言具有显著的代表性。
2)歧义最大的实例选取(Most Ambiguous Case Selection,MACS)。从式(12)可知,DA算法本质上通过调整源分类超平面W0来构建新的超平面W,MACS假设2个超平面具有足够的相似性,那么F0总能正确的分类目标集样本。该策略选取最具歧义(即分类信任值最低)的样本作为标注对象。
X*=argminX∈DDL|F0(X,Y,W0)|
(22)
此策略认为那些在源分类器上小于分类间隔的目标样本对于确定目标分界面也具有重要的判别性(如图2(c)所示)。
将上述2种样本选取策略整合至DA算法,整体训练框架如下:

penalty C>0,threshold ε>0,源分类器WS.
2.DL←formula 20 or 21
3.S←Ø
4.repeat
6. for i=1,…,M do
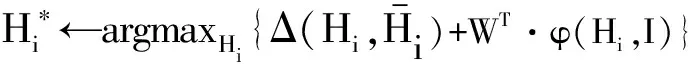
8. end for
10.until
11.return (W,β,ξ)
算法首先使用源分类器WS执行样本选取策略,从目标集内获得一个标注子集DL。第4步~第10步基于cutting-plane对(W,ξ)迭代求解,关键思想是从训练集DL中搜索最具惩罚度的约束条件(即某一结构化输出)。其中第5步依据当前工作集求解目标参数W,注意这里采用式(10)的自适应优化,然后用学习到的W从每个训练样本中找到最具惩罚的输出,并加入工作集S。算法的结束条件为S不再变化,此时由S训练的参数为给定误差ε下的最优解。上述训练算法的实现是在开源代码SVM-Struct[20]上修改了迭代第一步,将常规的SVM优化函数替换为本文的式(10)。C和ε是调节SVM训练深度的2个经验性参数,SVM-Struct默认设定C=0.01,ε=0.1。根据文献[14]的理论推导,C值越大或者ε值越小,训练迭代次数越大,参数拟合度越高,本文经过多次交叉验证,权衡了训练效率和过拟合问题,经验性地保持C的默认值,ε取0.01。
3 实验与结果分析
式(1)采用判别算法估计姿态时受到了2种特征分布的影响,即各组件的外观特征分布(以下简称外观分布)以及组件间的位移特征分布(以下简称格局分布),本节根据这2种分布差异模拟了对应的测试场景。表1显示了目标集和评估模型的具体配置。DL表示从目标集当中按某一策略选取的标注样本子集。本文共选取了5种学习模型,Baseline代表常规的S-SVM[14],即假定源-目标数据集处于相同分布,Ada为面向结构化输出的DA算法[13],Ada_ca代表2.1节提出的组件感知的自适应算法,Ada_ca_MECS和Ada_ca_MACS代表Ada_ca分别整合MECS和MACS 2种样本选取策略后的自适应算法。为了客观对比,实验以随机方式从目标集合选取与Ada_ca_MECS和Ada_ca_MACS相同数量的样本,标注后作为Ada_ca的训练集。上述5种模型从目标集参数学习的角度来看均为监督学习模式。
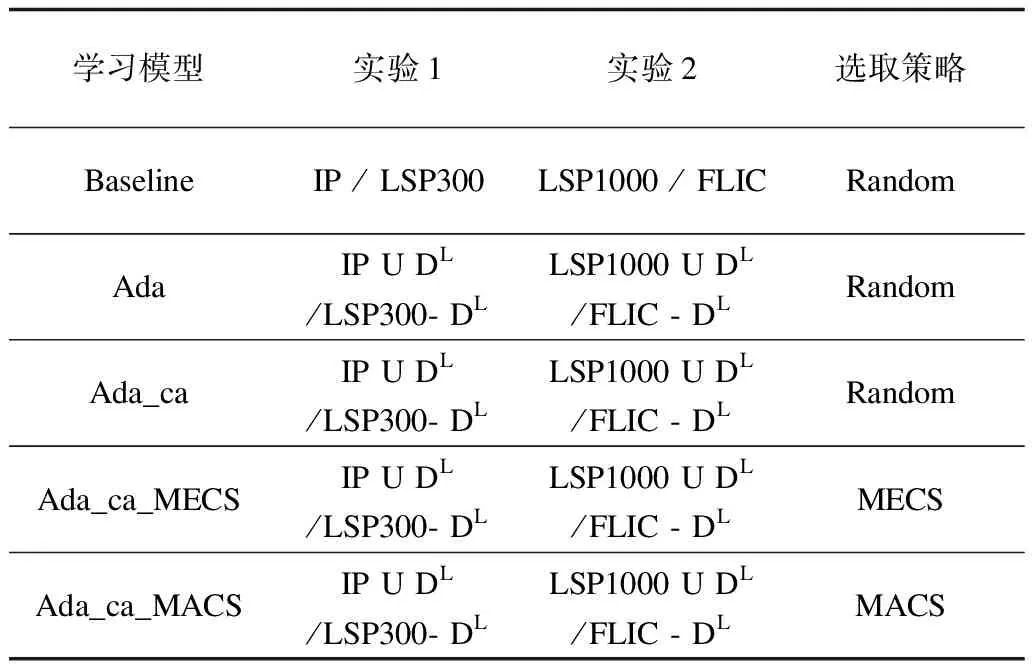
表1 实验用源/目标集配置
3.1 实验1格局分布差异下的学习性能
本节借助2个特定的人体Pose标注集模拟组件分布差异,实验的一个基本假设是来自不同场景的人体Pose具有不同的组件格局分布。训练集Iterator Image Parsing(IP)[21]取自田径运动场景,包含305张人体Pose,每个Pose由14个关键点标注;测试集Leeds Sport Pose(LSP)[22]未限定Pose场景,标注方式与IP相同。为了获得更好的实验效果,本文从LSP中随机选取同等规模(约300)但不包含田径场景的样本(记为LSP300)。


表2 格局分布差异下的自适应算法性能对比 %
表2数据显示Ada_ca、Ada_ca_MECS、Ada_ca_MACS分别采用Random、MECS和MACS 3种样本选取策略,结果表明MECS策略表现最佳,因此认为MECS选取对目标集而言最有代表性(或者说判别性)的样本,学习到的分类模型具有更强的泛化性能。MACS采用传统的主动学习策略,当源-目标集的特征分布不同时,此策略只能选取对源模型有判别性的目标样本(参见图2(b))。
图3进一步评估了3种样本策略在限定样本数目下的性能变化。2种样本选取策略MECS和MACS均明显优于Random选取,其中MECS除了在样本数40时略低于MACS,其他情形下表明更佳。
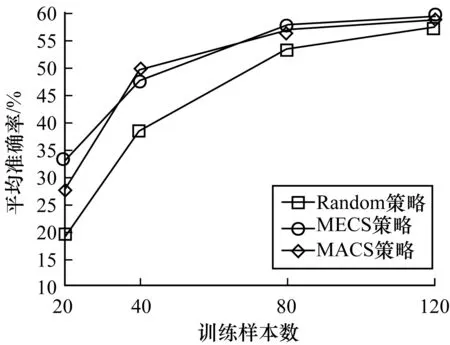
图3 不同样本选取策略的性能对比
3.2 实验2外观分布差异下的学习性能
本节基于2个采样来源不同的数据集进行自适应评估。实验假设不同的采样来源其组件外观的特征分布亦不同,即以不同数据集来假设组件外观的分布差异。实验从LSP训练集当中随机选取1 000个样本(记为LSP1000),测试集基于当前主流的FLIC[23],该数据集包括5 003张从各类电影中截取的图片,通过人工方式标注上半身10个关节点,从FLIC中随机选取2 000个样本。图4显示了5个模型在PASCAL上姿态估计的平均准确率。类似于实验1的测试结果,4种自适应算法均优于传统的监督学习方法(Baseline),相比一般的自适应方法(Ada),本文的组件感知自适应方法(Ada_ca)有3.1%的性能提升,而且整合主动学习策略的自适应算法同样能进一步提升估计性能1%~2%。Ada与监督算法Ada_ca在此实验中的差距(约3.1%)小于在实验1当中的差距(4.1%)主要原因是实验1的源-目标集分布差异体现在组件的相对位置(即姿态的变化);实验2的2个数据集的分布差异主要体现在组件的外观形式。这表明格局分布特征(即组件的相对位置)相比外观特征对姿态估计的性能影响更大。
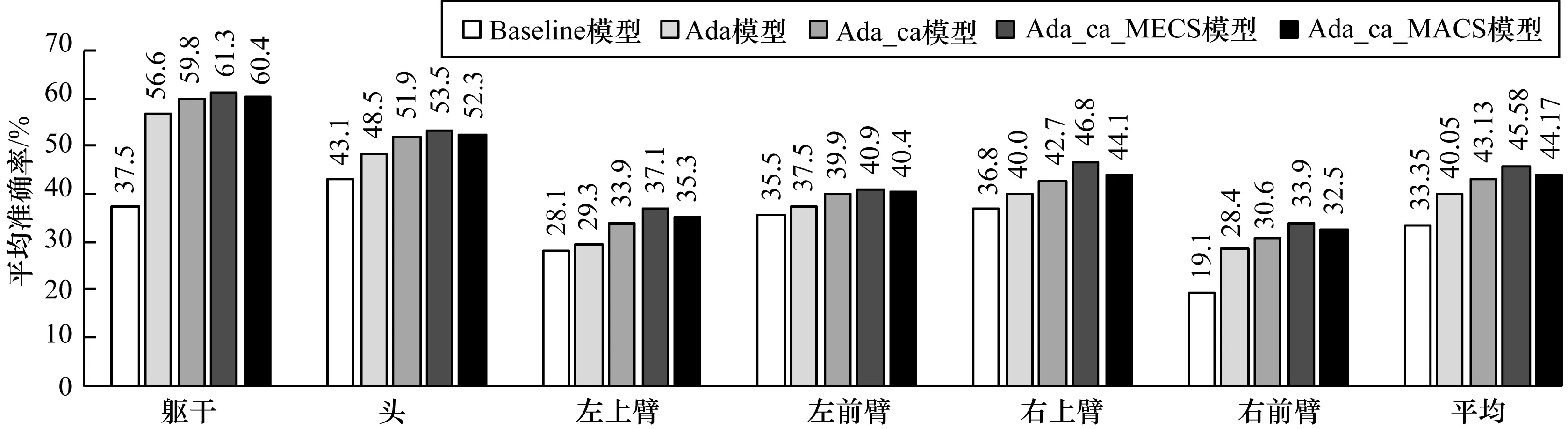
图4 外观分布差异下自适应算法的性能对比
4 结束语
本文提出一种DA与主动学习相结合的训练算法,并应用于姿态估计问题。本文算法基于最简单的正规子扩展原理,相比近几年提出的更先进的自适应模型(例如子空间[10]、Laplarian SVM[11]、Distribution Adaptation[12]等),仍有广阔的研究空间。本文提出的主动学习策略是获取“高质量”子集的一种有效途径,但如果目标数据集的规模非常大,则此方法因无法实现全局搜索而失效。下一步将考虑更为复杂的自适应场景,对本文算法进行研究与改进。
猜你喜欢
能源工程(2022年2期)2022-05-23 13:51:50
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
学生天地(2020年3期)2020-08-25 09:04:16
重型机械(2020年2期)2020-07-24 08:16:16
装备制造技术(2019年12期)2019-12-25 03:07:36
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
