
基于改进SSD的行人检测方法
2018-11-20 06:09:16邢浩强杜志岐
计算机工程 2018年11期
邢浩强,杜志岐,苏 波
(中国北方车辆研究所,北京 100072)
0 概述
行人检测作为计算机视觉领域的研究热点,在车辆高级驾驶辅助系统、视频监控、安全检查以及反恐防暴等方面有着重要应用。 在过去的几十年里,研究人员针对行人检测问题做了大量探索与研究并取得一系列成果。目前行人检测主要分为基于人工设计特征和基于神经网络特征的2种检测方法。
文献[1]建立了根模型和部件模型来表示物体,并将2种方法的匹配结果作为最终的行人检测结果。文献[2]使用包含归一化梯度幅值、梯度方向直方图特征等10个聚合通道特征,训练了由2 048个决策树状组成的强分类器以减少模型分类时间。文献[3]提出了基于感兴趣区域梯度直方图的行人检测方法,分别在头部及四肢等重点区域计算梯度方向直方图,减少了向量维数。文献[4]将人脸检测中级联检测框架引入到行人检测中,采用Gentle AdaBoost方法进行分类器训练,提高了检测效率。 以上基于人工设计特征的行人检测方法在诸多行人检测问题中都取得了良好的检测效果,但也有明显的不足。 这类方法的特征依赖对行人检测问题的理解与设计经验。 此外这些人工设计的特征也仅仅侧重于某类或某几类特点,很难全面兼顾多种工况下的检测任务。
深度学习是近年来兴起的技术,计算机视觉领域也在不断地探索将其应用于图像处理、目标检测与识别等问题中。文献[5]将支持向量机(Support Vector Machine,SVM)方法与LeNet神经网络融合,通过SVM提取特征并通过卷积神经网络(Convdutional Neura Network,CNN)剔除误检窗口,实现了较高的召回率和准确率。文献[6]提出了一种包含大量人体部件检测器的检测框架,能够通过较少量的监督数据来进行训练,对于遮挡情况下的行人检测问题有较好的检测效果。文献[7]提出一种基于CNN的隐式训练模型,通过结合多部件检测模块降低计算复杂度,在INRIA数据集上获得98%的检测准确率。 然而上述基于深度学习的方法在通过神经网络逐层提取行人特征时,认为该特征仅与前一层有关,忽略了其余特征层的作用。此外,该类方法在对行人目标进行预测时往往将特征层孤立开来,影响了检测结果的鲁棒性与准确性。
为解决上述问题,本文提出一种基于改进SSD(Single Shot Multibox Detector)的行人检测方法。该方法的网络结构以文献[8]中通用目标检测模型SSD为基础,结合行人检测任务特点进行优化与改进。
1 原始SSD方法及其存在的问题
1.1 原始SSD方法模型结构
原始SSD模型主要由4部分组成:基础网络部分,附加特征提取层部分,原始包围框生成部分和卷积预测部分。其工作原理如下:首先将不同尺寸的图片变换为300×300像素的尺寸输入模型; 输入图像经过基础网络与附加特征提取部分后得到原始图像的大量卷积特征;选择部分特征层作为目标预测的依据,分别经过原始包围框生成部分和卷积预测部分得到大量多尺度原始包围框和各卷积层在每个位置处的包围框修正值与预测概率;根据原始包围框、预测结果与图片真值数据通过loss层计算损失函数,通过训练实现模型权值的更新。
1.1.1 基础网络部分
基础网络部分用于对输入图像进行浅层特征提取,得到的浅层特征一方面可直接用于目标检测与包围框回归,另一方面可用于提取目标的深层特征。 原始SSD模型直接将VGG-16[9]模型的卷积部分用作基础网络部分。这部分包含13个不同的卷积层,可对一张输入尺寸为300×300像素的三通道图像进行大量卷积运算,最终得到512张尺寸为19×19的特征图,作为附加特征提取层继续进行卷积运算的输入。
1.1.2 附加特征提取层部分
附加特征提取层部分仿照基础网络部分的结构,新增10层卷积层,对基础网络提取的特征进行进一步卷积运算。 VGG-16卷积层后为2个全连接层,在特征提取阶段宜采用计算量更小的卷积运算。文献[10]提出通过下采样和atrous方法将原VGG-16模型中的前2个全连接层修改为附加卷积层的前2层,即Fc6-Conv层和Fc7-Conv层,其余8层为普通创建的卷积层。
1.1.3 原始包围框生成部分
原始SSD模型选取部分卷积层来实现目标预测与包围框修正。为实现增量式包围框回归,需要在被选特征层的每个特征值位置上生成若干宽高比的原始包围框,并在此基础上回归修正值以获得最终包围框结果。
网络中不同层次的特征图具有不同的感受野(receptive field),即不同层次特征图上的特征值对应于原始图像不同尺寸的图像块。通过设计不同层的缩放因子来调整不同层内原始包围框的尺寸以适应不同大小的目标。假设共选m个特征层,则原始SSD方法对于第k层的缩放因子如下所示。
其中,smin=0.2,smax=0.9。设输入图像的高和宽分别为Hinput和Winput,则该层对应与宽高比为r的原始包围框宽和高如下所示。
1.1.4 卷积预测部分
每个被选择的特征层输出的特征经过与之对应的卷积预测部分运算,输出结果分别为预测的目标包围框修正值与该包围框内物体是目标或背景的概率。每个包围框修正值包含4维数据:中心点横坐标修正值,中心点纵坐标修正值,包围框宽度修正值和包围框高度修正值。
1.2 原始SSD方法存在的问题
1.2.1 基础网络部分
原始SSD方法直接采用VGG-16网络的卷积层作为基础网络部分,用来提取目标的浅层特征。每层的卷积运算输入仅为与之相连的上一卷积层,并未考虑之前的卷积层,丧失了大量卷积运算得到的特征信息。此外,这种串联的卷积运算模式下,如果某层权值在更新过程中出现了较大偏差,则会导致该层后面的所有层都受到影响。
1.2.2 被选特征层结构
输入图像经过基础网络部分与附加特征提取部分运算,得到大量卷积特征图,选择部分特征图作为原始包围框与卷积预测的基础。原始SSD方法没有将浅层特征与深层特征融合起来综合考虑,而是孤立的选择若干卷积层作为被选特征层,在此基础上进行检测结果的预测。
1.2.3 被选特征层缩放因子
考虑到不同层次的特征图具有不同的感受野,需要为不同特征层设计缩放因子。目标的尺寸分布具有如下规律:目标尺寸很大与很小的可能性相对较小,而尺寸适中的可能性相对较大。原始SSD方法忽略了这一规律,认为目标尺寸大小概率相同,采用线性均分的方法为各个特征层分配缩放因子。
2 改进的SSD方法
改进的SSD方法用密集连接的卷积层[11]替换串联结构的基础网络部分,在得到大量目标特征图后通过特征融合部分将不同层次的特征图组合,得到融合特征图用作预测的依据,并修改了不同特征层的缩放因子,使得各特征层的原始包围框尺寸更好地满足待检目标的尺寸分布规律。改进SSD方法的模型整体结构如图1所示。

图1 改进SSD方法的模型整体结构
2.1 密集连接基础网络部分
密集连接的基础网络部为15个卷积层,平均分为5组,每组的3个卷积层构成一个Block。每个Block采用密集连接的方式进行卷积运算,每个卷积层都与当前Block内该层之前的所有卷积层连接(见图2)。第一卷积层的输入为前Block的输出,第二卷积层的输入为该Block的第一卷积层输出,第一、第二卷积层的输出组合后作为第三卷积层的输入,第一~第三卷积层的输出组合后作为该Block的卷积运算结果。
Block内卷积层进行组合后经过Batch Normalization[12]运算以平滑不同特征图之间的偏差,经过Scale运算归一化。每个Block内3个卷积层组合后的特征图通道数是任意卷积层的3倍,通过1×1的卷积核进行变通道操作,将Block的输出通道数变换至与Block内任意卷积层相同,结果作为Block输出。基础网络部分5个Block的结构参数如表1所示。
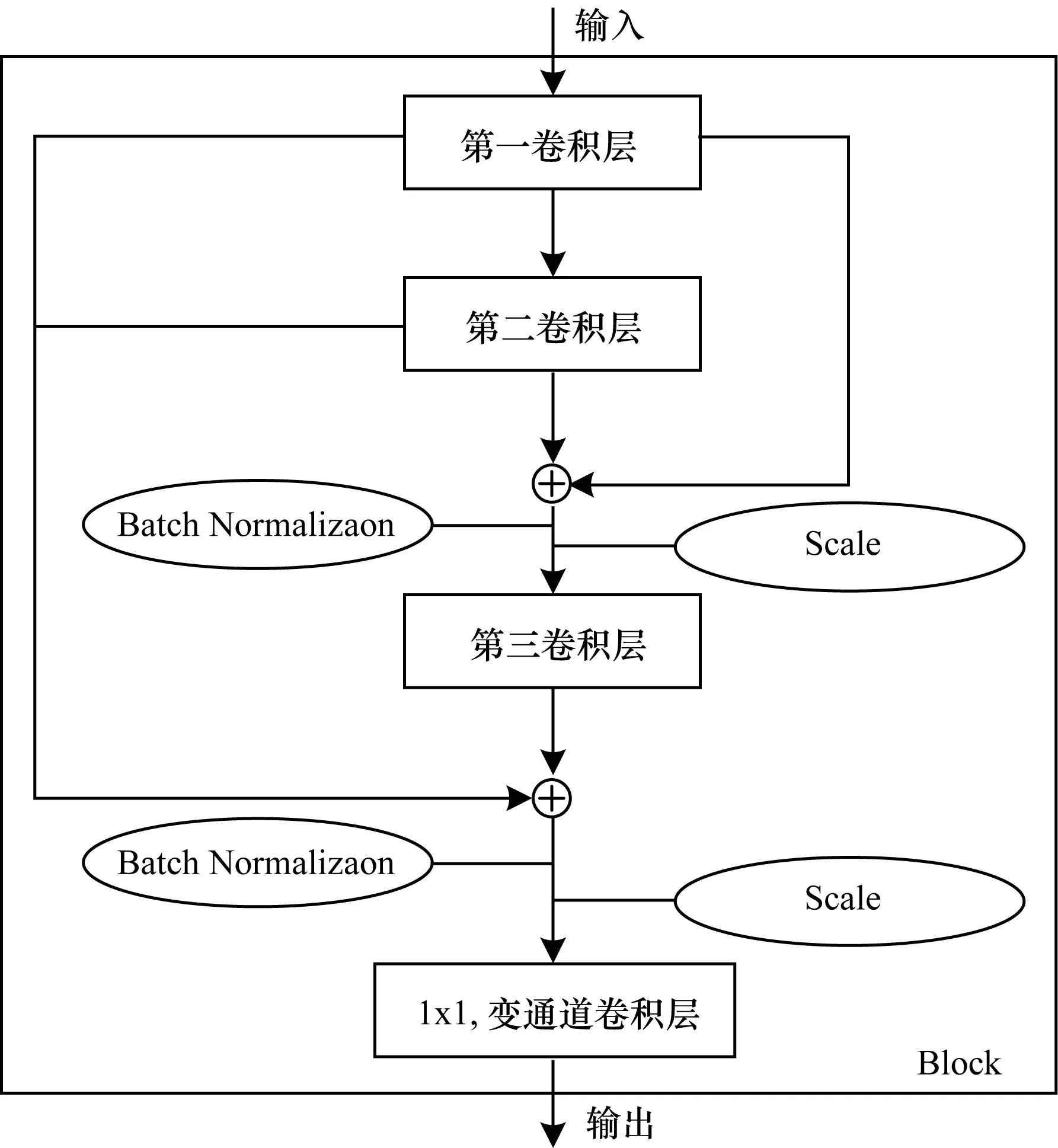
图2 密集连接Block结构示意图
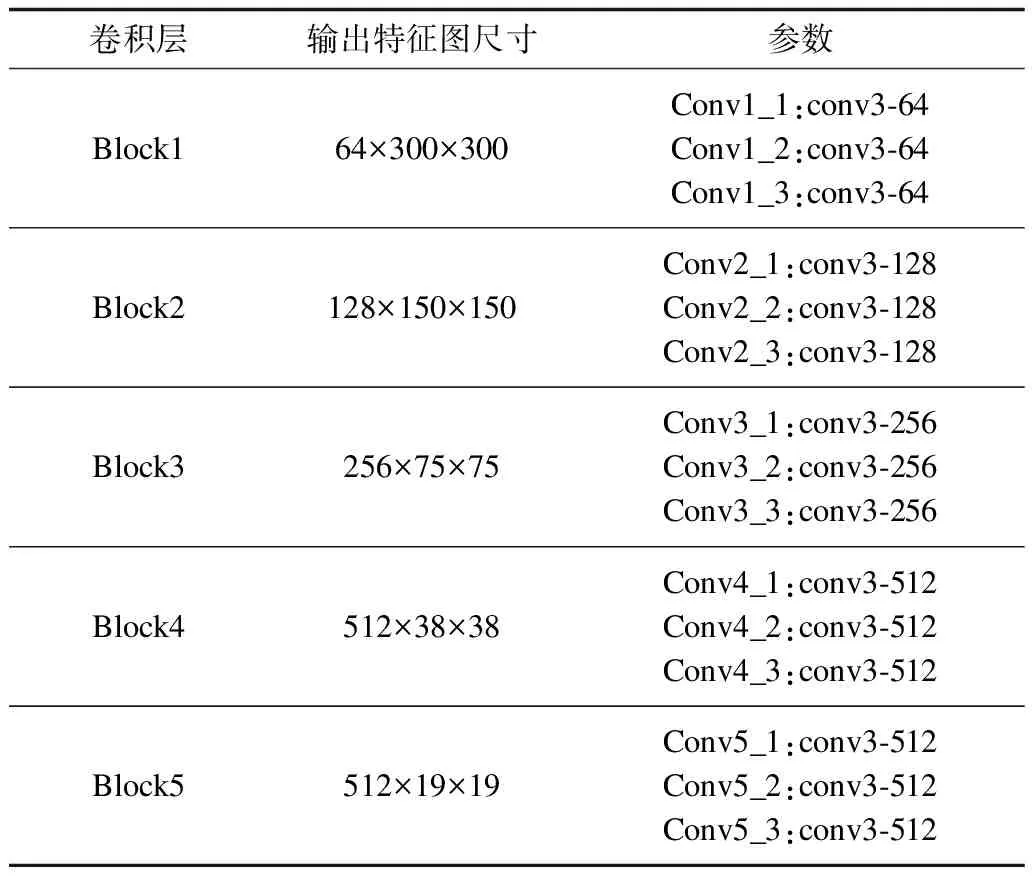
表1 基础网络部分结构参数
2.2 作为被选特征层的融合特征层
模型将浅层特征与深层特征融合形成融合特征,用作包围框回归与目标概率预测的原始特征图。浅层特征通过下采样以减小维度,深层特征通过上采样以增加维度。上采样方法为直接填充,即用原特征图上某点的值填充上采样后该点对应区域的所有值。随后将2种来源不同的特征图融合起来形成融合特征用于行人目标检测。 融合特征层的通道数中一半来自浅层特征图,另一半来自深层特征图,当通道数不符时可通过1×1的卷积核来改变通道数。为了避免相邻特征图相关性较大影响检测效果,本文中的特征融合均采用隔层融合。
以Combined_4融合层为例进行说明。该层维度为512×38×38。Block3的输出特征图维度为256×75×75,下采样得到变换后的Block3(Block3mod),其维度为256×38×38;Block5输出特征图维度为512×19×19,经过上采样和1×1卷积核的变换通道操作后得到变换后的Block5(Block5mod),其维度为256×38×38。Block3mod和Block5mod拼接为Combined_4融合层,其维度为512×38×38。特征融合后经过Batch Normalization和Scale运算处理,其余融合层的融合规则如表2所示。

表2 特征融合部分融合规则
2.3 适应目标尺寸分布的卷积层缩放因子
通过设计不同层的缩放因子来调整不同层内原始包围框的尺寸以适应不同大小的目标。假设共选m层特征层,考虑到目标的尺寸较大或较小的可能性较低,故缩放因子较小或较大时的分布应稀疏,而缩放因子位于中间值时分布应相对密集。 第k层包围框缩放系数计算方法可在线性分配的基础上加以修正,如下式所示。
其中,smin=0.2,smax=0.9,φ(k)是不同层修正系数函数。本文共选择6个融合特征层作为包围框修正值与目标概率预测的原始特征图,取φ(1)=φ(6)=0.8,φ(2)=φ(5)=1,φ(3)=φ(4)=1.2。
3 实验与结果分析
为了验证改进SSD方法的有效性,通过Caltech Pedestrian数据集进行测试,并将测试结果与其他方法的结果进行对比与分析。
3.1 Caltech Pedestrian数据集
Caltech Pedestrian为加州理工大学构建的数据集,常用于行人检测算法的设计与测试。该数据集为时长约10 h的城市道路环境拍摄视频,共约106帧,图像原始分辨率为640×480像素。视频集分为Set00-Set10共11段,选择Set00-Set05作为训练集,Set06-Set10为测试集。其中“person”类代表图像中标记出的独立行人目标,“people”类代表图像中标记出的行人群,“person?”类代表图像中的目标无法清晰分辨是否为行人。本文仅考虑标记为“person”类的目标,忽略“people”类与“person?”类。
Caltech Pedestrian数据集按照视频中行人目标的尺寸与被遮挡情况,将测试集分为不同级别。本文选择All与Reasonable测试集测试算法的一般泛化能力,选择Far与Occ.heavy测试集测试算法的难例泛化能力。4个测试集的属性如表3所示。

表3 所选测试集属性
3.2 模型训练
训练数据经过左右翻转和随机采样实现数据增强,随机采样的最小jaccard overlap[13]值为0.5,训练数据与测试数据均等比例缩放至300×300。权值训练方法为随机梯度下降(Stochastic Gradient Descent,SGD),mini-batch尺寸为32,训练平台为英伟达TitanX GPU。
由于模型网络结构相对复杂权值参数较多,因此从头训练速度较慢,本文使用原SSD模型中与改进SSD模型相同的层来初始化改进SSD模型中的部分层,其余层采用文献[14]中的方法初始化。初始学习率为0.001,25 000次循环后学习率调整为0.000 1,40 000次循环后学习率调整为0.000 01,50 000次循环后终止训练。参数衰减值(weight decay)为0.000 5,动量因子(momentum)为0.9。
3.3 测试结果
3.3.1 检测准确性
模型训练结束后通过测试集测试模型的检测结果,根据文献[15]中的评价方法计算测试结果的准确率与漏检率,绘制漏检率-每图误检数(FPPI)曲线,并将测试结果与其他顶尖方法进行对比。图3~图6分别为All、Reasonable、Far与Occ.heavy测试集下改进SSD方法与其他方法的测试对比,图中左下角边框内为各方法的对数平均漏检率(log-average miss rate)[15],该值越低,则对应方法的检测效果越好。 从测试结果来看,相比其他方法,改进SSD方法针对Caltech行人数据集具有更好的检测效果。图7为Caltech数据集部分检测结果。
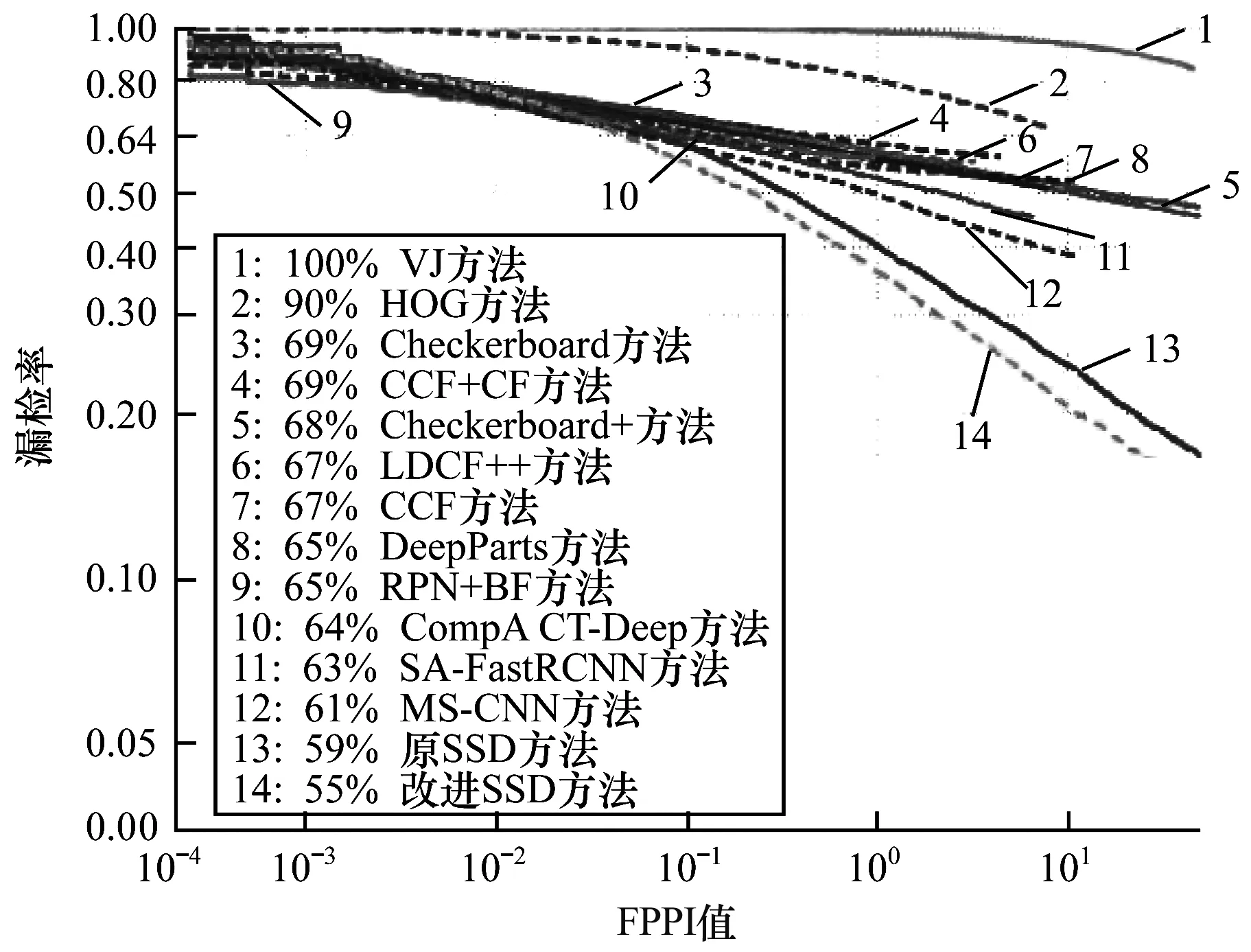
图3 All测试集下不同方法测试结果对比

图4 Reasonable测试集下不同方法测试结果对比
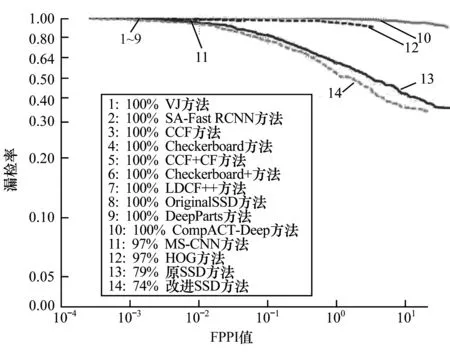
图5 Far测试集下不同方法测试结果对比
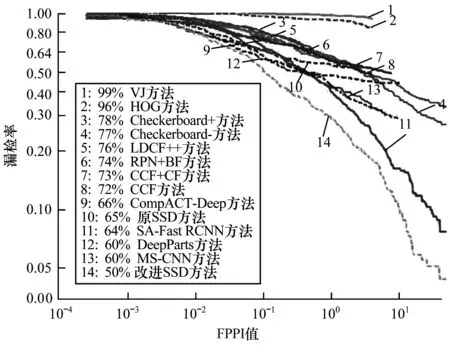
图6 Occ.heavy测试集下不同方法测试结果对比

图7 Caltech数据集部分检测结果
3.3.2 检测速度
为测试改进SSD方法的检测速度,本文选取目前检测精度较高的4种方法:SA Fast RCNN[16],MS-CNN[17],RPN+BF[18]与CompACT-Deep[19],用来做对比实验。考虑到不同方法使用的GPU计算能力不同,本文计算各方法在单位tflops(每秒万亿次单精度浮点计算)计算能力下的检测速度,结果如表4所示。由表4可知,改进SSD方法的检测速度可达20 frame/s,明显快于其他方法,满足行人检测的实时性要求。
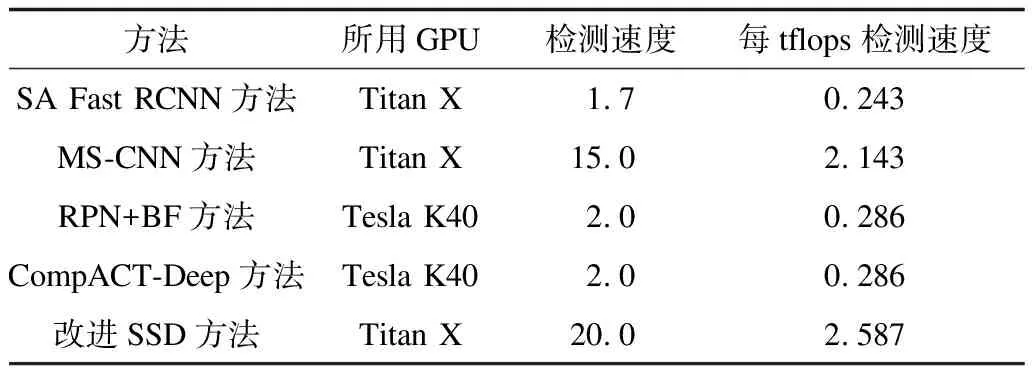
表4 不同检测方法的检测速度 (frame·s-1)
3.4 测试结果分析
3.4.1 检测准确性结果分析
测试结果表明,相比于原始SSD等其他方法,改进SSD方法对Caltech Pedestrian数据集具有更低的平均漏检率。密集连接的基础网络能够综合考虑大量浅层行人特征,提高模型的一般泛化能力,改进SSD方法在All与Reasonable测试集上的平均漏检率较其他方法有3%~5%的提升。融合特征能够兼顾行人的浅层特征和深层特征,提高目标预测阶段的稳定性与鲁棒性,使得改进SSD方法对于小尺寸目标与严重遮挡目标具有更好的检测效果。改进SSD在Far与Occ.heavy测试集上的平均漏检率较其他方法有10%~20%的提升,这对于解决行人检测中低照度、模糊目标、遮挡目标等痛点问题具有重要意义。
3.4.2 检测速度结果分析
改进SSD方法的速度高于SA Fast RCNN、MS-CNN、RPN+BF与CompACT-Deep等方法的原因主要有2点。1)改进SSD方法的目标包围框是被动生成的,即在特征图的每个位置产生若干固定宽高比的默认包围框,默认包围框产生阶段不需考虑图片的具体像素值。而SA Fast RCNN与MS-CNN等方法的默认包围框需要根据不同图片的像素值主动生成,这一阶段需要消耗大量时间。2)改进SSD方法可以实现端到端的训练与检测,模型的输入为待检图片,输出即为检测结果,训练与检测流程在同一CNN内进行。而RPN+BF与CompACT-Deep等方法的训练与检测均需要分段进行,特征的提取与基于特征的与检测通过不同的神经网络或传统机器学习模型实现,其中数据的转移和处理消耗了额外时间。
4 结束语
为提高行人检测的准确性与稳定性,本文提出一种基于改进SSD的行人检测方法。该方法以SSD为基础网络结构,结合行人检测任务特点进行优化与改进。 将串联式的基础网络部分修改为密集连接式结构,目标预测阶段选择融合特征作为预测依据,并根据目标尺寸分布规律优化各特征层的缩放因子。模型在Caltech Pedestrian数据集上训练与测试,获得了较低的平均漏检率,验证了本文方法的有效性。对于行人目标尺寸较小与严重遮挡等难点问题,相比于原始SSD、VJ-1、HOG等方法,本文方法的检测结果具有明显提升。此外本文方法的检测速度也较有明显优势。
虽然基于高计算能力GPU的改进SSD方法针对行人检测具有较快的速度,但这类方法在计算能力稍差的嵌入式系统中的检测速度仍然很慢。下一步将精简和压缩模型结构,在不明显影响检测精度的基础上提升模型前向传播速度,增强其嵌入式系统部署能力。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
意林(2021年5期)2021-04-18 12:21:17
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
电子制作(2019年11期)2019-07-04 00:34:38
当代陕西(2019年10期)2019-06-03 10:12:04
扬子江(2019年1期)2019-03-08 02:52:34
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
电视技术(2014年19期)2014-03-11 15:38:20
