
联合HMM-UBM与RVM的声纹密码识别算法
2018-11-20 06:08:52胡志隆贺建飚
计算机工程 2018年11期
胡志隆,文 畅,谢 凯,贺建飚
(1.长江大学 a.电子信息学院; b.计算机科学学院,湖北 荆州 434023; 2.中南大学 信息科学与工程学院,长沙 410083)
0 概述
语音识别是一种生物识别技术,获取方法简单且成本低廉。相比于人脸识别、虹膜识别等技术,语音识别使用者的接受程度更高,因此,其被广泛应用于医疗、社保、金融及公共场所的安全认证等领域。而声纹密码识别作为文本相关的语音识别方法,用文本的上下文关系和话者声道信息保护说话人的信息安全,与文本无关的语音识别方法相比,具有较高的安全性[1]。
目前,语音识别系统常采用高斯混合模型-通用背景模型(Gaussian Mixture Model-Universal Background Model,GMM-UBM),该算法应用话者的声道信息并通过全局背景模型解决训练样本少的问题,在文本无关的语音识别中取得较好的识别效用。此外,随着人工神经网络(Artificial Neural Network,ANN)、支持向量机(Super Vector Machine,SVM)等机器学习方法的不断成熟,也出现类似GMM-SVM的融合算法[2-6]。然而,GMM模型仅单一反映话者的声道信息而忽略语音文本的上下文关系,因此不适用于声纹密码识别。同时,ANN是一个高度非线性的大型网络,需要大量的训练样本才能得到效果较好的模型,导致其难以应用于实际。
针对上述方法的不足,本文提出一种隐马尔科夫模型-通用背景模型(Hidden Markov Model-Universal Background Model,HMM-UBM)联合相关向量机(Relevance Vector Machine,RVM)的声纹密码识别算法,该算法采用HMM-UBM模型,利用语音的文本信息及其话者的声道信息进行时序建模。同时针对HMM模型分类决策能力较差的问题,本文融合相关向量机作为分类器,做最后的判决决策。
1 声纹密码识别算法流程
指定文本的声纹密码识别系统主要流程包括语音信号的预处理、特征参数提取、特征建模和相似性度量等模块,其中特征参数的选取及相似性度量的方法决定系统的识别效率[7]。本文针对传统声纹密码识别系统中的相似性度量模块进行了改进,提出了基于HMM-UBM联合改进RVM的声纹密码识别算法,算法流程如图1所示。首先对注册语音、训练语音及待识别语音进行预处理,包括分帧、加窗、预加重等;其次采用梅尔倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)对处理过的语音提取特征参数;然后将其作为输入序列,训练得到HMM-UBM模型后计算每位注册说话人语音与训练语音的匹配得分,归一化后组合成一个特征向量,将每位注册说话人的特征向量提供给RVM训练,得到语音分类信息,即RVM分类器;最后对待识别语音采用同样的方法得到其对应的特征向量,输入训练好的RVM模型进行分类决策,并最终取得分类结果。
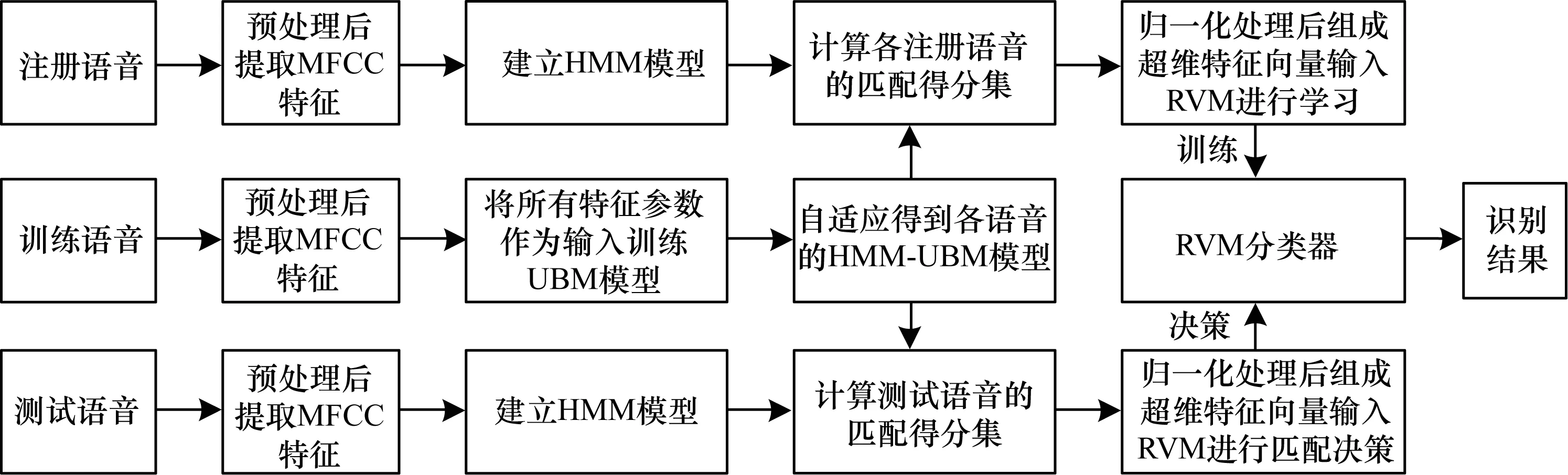
图1 声纹密码识别算法流程
2 HMM-UBM模型
说话人识别系统中常用的GMM-UBM模型虽然拟合了说话人的声音特性,但忽视了文本内容对识别效果的影响,不适用于特定文本的声纹密码识别[8-10]。因此,本文采用HMM来对相关性进行建模,同时采用全局高斯混合模型作为UBM来表达说话人声道特征在训练样本中的分布概率。模型构建流程如图2所示。
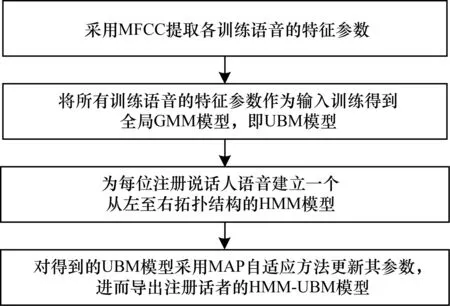
图2 HMM-UBM模型构建流程
与GMM-UBM模型相似,由于UBM的均值矢量利用率较高,因此自适应时仅更新该参数,更新过程如下:
1)设注册话者的输入特征矢量为{xi|i=1,2,…,t},计算其在所有训练样本中的概率分布,若话者对应第i个训练样本,则其概率分布为:
(1)
其中,pi(xt)为第i个训练样本的密度函数,ωi为第i个训练样本的权重系数,Pr(i|xt)为第i个训练样本的后验概率,表示在测试语音的特征矢量为xt的条件下,测试语音对应第i个训练语音的概率。
2)利用Pr(i|xt)和均值向量进行从分统计,统计式为:
(2)
3)通过所有训练数据产生新的均值统计量,更新UBM第i个混合分量的均值矢量得到第i个分量的HMM-UBM模型,如式3所示。
(3)
3 相关向量机
RVM是一种基于贝叶斯稀疏核的分类算法。与SVM相比,RVM可以计算出样本输出的后验概率分布,更适用于多分类问题,并且其核函数不需要限定为对称正定核,从而可以得到更加稀疏的解[11-15]。因此,本文选用其作为分类器,进行最后的决策,得到更加准确的识别结果。

ti=y(xi)+εn
(4)
其中,εn是均值为0、方差为σ2的噪声,y(x)为RVM的分类模型,其定义为:
(5)
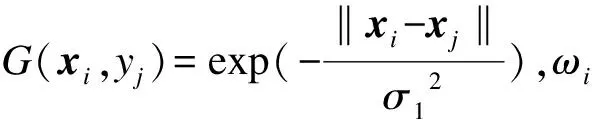
设目标{t|t=t1,t2,…,tN}独立同分布,则整个训练样本的似然函数可以表示为:
(6)
其中,t=(t1,t2,…,tN)T,ω=(ω0,ω1,…,ωN)T,φ为N×(N+1)矩阵,如式(7)所示。
(7)
假设式(6)中的ω和σ2采用最大似然估计求解,结果通常使权重参数ω中大部分元素不为0,从而导致过拟合。为了避免过学习的问题,RVM对每个权重参数加上先决条件:使其几率是分布在0周围的正态分布,如式(8)所示。
(8)
其中,α为N+1维超向量。
根据贝叶斯公式直接求得参数ω的后验分布:
p(ω|t,α,σ2)=(2π)-(N+1)/2|Σ|-1/N×
(9)
其中,μ=σ-2ΣφTt,Σ为协方差,Σ=(σ-2φTφ+A)-1,A=diag(α0,α1,…,αN),σ2(x)=(β)-1+φ(x)Σφ(x)。
对于一个给定的样本x,最终其输出的概率分布为:
(2π)-N/2·|σ2I+φA-1φT|-1/2
(10)
式(10)中的未知量为超参数α和β,则求解输出概率分布的问题转化为求解超参数α和β,本文通过最大化法来求解参数,如式(11)所示。
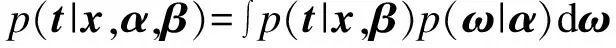
(11)
通过最大化式(11),来更新α和β的值:
(12)
(13)
经过多次学习,大部分超参数αi会趋于无穷,而对应的权重向量ωi=0,少部分权重向量不为0的训练样本xi即为相关向量,通过相关向量得到其分类模型并作为最优分类超平面,以对输入的测试样本进行识别。
4 HMM-UBM-RVM声纹密码识别算法
HMM算法具有较强的时序建模能力,处理连续动态信号时表现优异。但HMM是基于先验知识的统计学习方法,其分类决策能力较差。而RVM是基于贝叶斯稀疏核的回归分类算法,具有较强的分类效果和泛化能力。本文提出HMM-UBM-RVM声纹识别算法,将2种方法进行融合,具有较强的时序建模能力和分类效果。
设训练样本中包含n位说话人,每位说话人包含10条语音,对于第i位说话人,其特征序列分别为{i-voice0,i-voice1,…,i-voice9}。其中i-voice0为其注册声纹密码,则该模型的实现流程如图3所示。
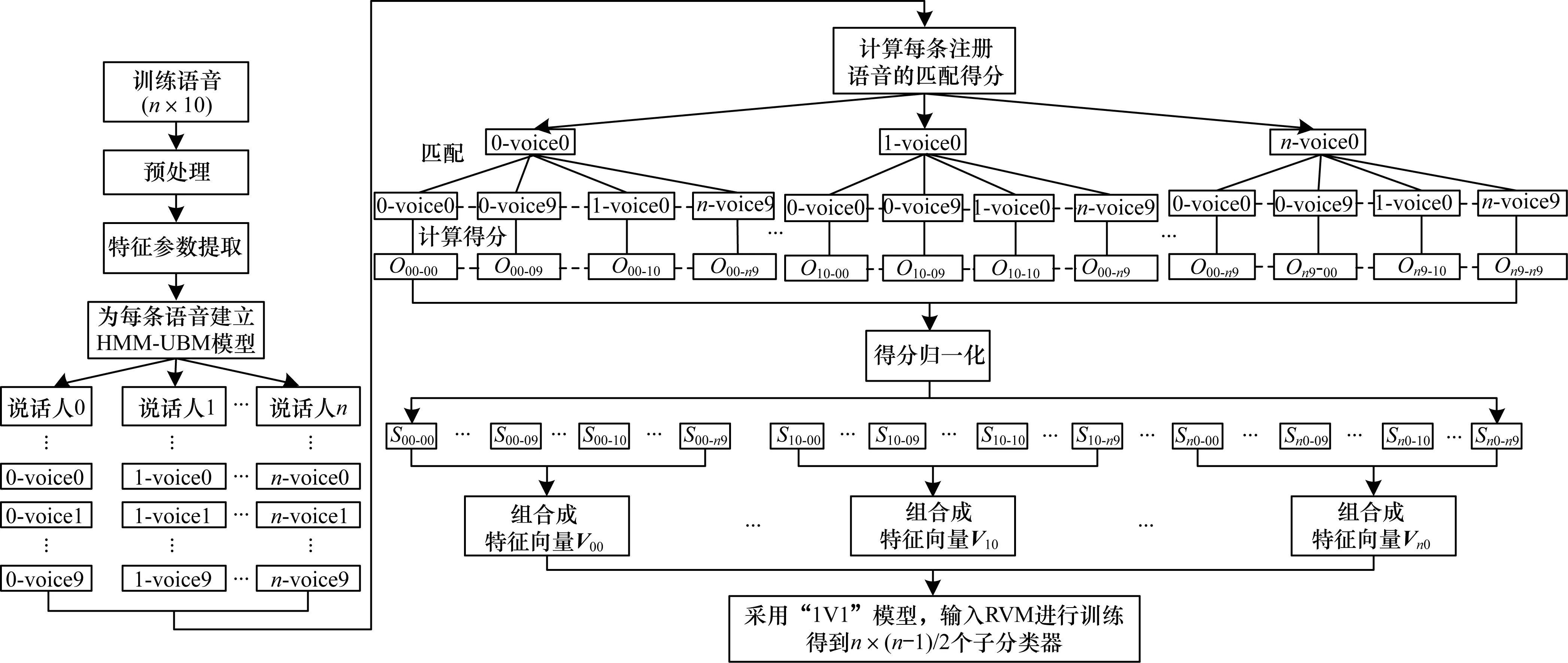
图3 HMM-UBM联合RVM实现流程
联合HMM-UBM与RVM算法实现流程如下:
1)录制语音信号。对语音信号进行预处理,消除干扰信息后提取其MFCC特征参数。
2)对每位说话人的语音建立HMM-UBM模型。
3)用式(14)计算训练样本中每条注册语音对其他语音的匹配得分:
Οt0-ik(Xt0)=logp(Xt0|λik)-logp(Xt0|λUBM)
(14)
其中,Xt0为训练样本中第t位说话人注册语音的HMM特征序列,λik为训练样本中第i位说话人第k条语音的HMM-UBM特征序列,λUBM为背景模型的特征序列。
4)对匹配得分进行归一化:
(15)
5)将每条注册语音归一化数据组成超维向量V。例如,对于第t位说话人,其注册语音的超维特征向量为Vt0={Scoret0-00,Scoret0-01,…,Scoret0-n9}。
6)将得分矢量输入到RVM进行学习,直到RVM迭代次数到预设次数为止(本文取最大迭代次数为300次)。至此完成RVM分类器的训练阶段,得到n×(n-1)/2个二分类的子RVM分类器。
7)对待识别的输入语音信号进行训练,得到HMM模型。用式(14)计算其得分,归一化后组成待识别语音的特征向量VVP,VVP={Scorevp1,Scorevp2,…,Scorevpn}。
8)将待识别语音的特征向量VVP输入到RVM,然后对该向量进行非线性映射。为提高识别精度,本文采用“1V1”模型进行多分类识别,如图4所示。
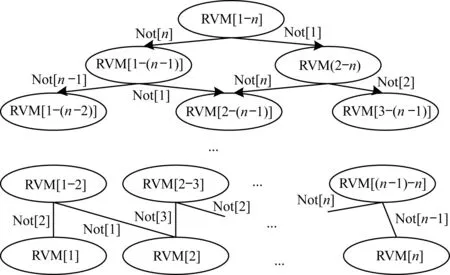
图4 RVM“1V1”分类模型
5 实验结果与分析
采用本文设计的声纹密码识别系统作为测试平台,系统运行界面如图5所示。
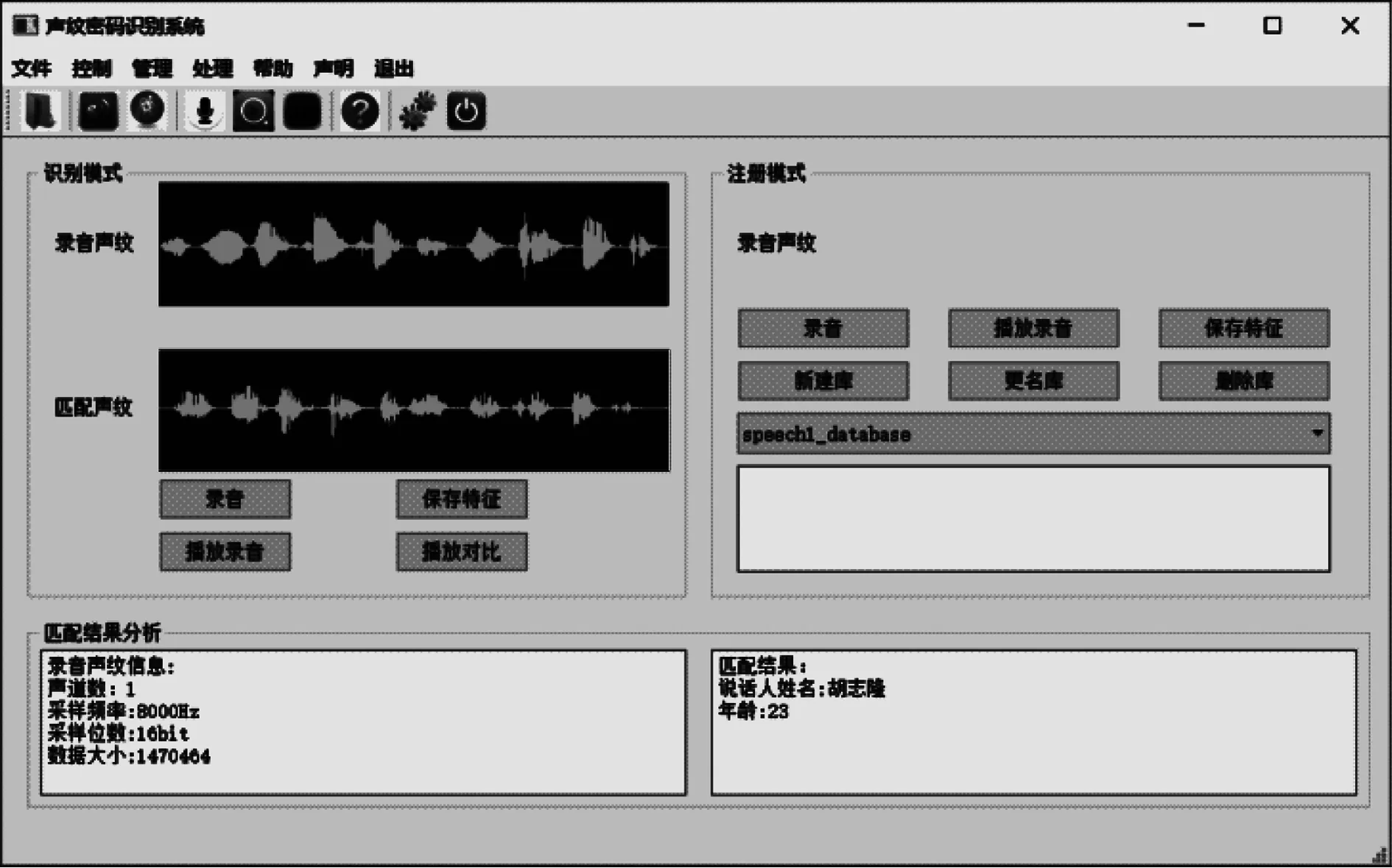
图5 系统运行界面
5.1 数据库及评测方法
本文采用的数据库是TIMIT语音库,包含来自美国8个主要方言地区的630个人,每个人包含10段3 s~6 s的语音。其中,2段为方言句子,每个人的方言句子内容相同,其余语音内容不同。
方言句1内容为“She had your dark suit in greasy wash water all year”,方言句2内容为“Don’t ask me to carry an oily rag like that”。
本文采用错误接收概率(FA)和错误拒绝概率(FR)评判声纹密码识别系统的性能,其表达式如式(16)和式(17)所示。
(16)
(17)
其中,nNRVC表示测试语音为非注册语音时,识别为注册语音的概率,nNRVT表示采用非注册语音作为测试语音的实验次数,nRVW表示测试语音为注册语音时,识别错误的概率(当且仅当测试语音与识别出的注册语音内容和对应说话人均匹配时,才认为识别正确),nRVT表示采用注册语音作为测试语音的实验次数。
5.2 UBM混合数对HMM-UBM模型的影响
通用背景模型的高斯混合数越大,说话人声道特征分布概率越精确,但计算复杂度相应增加。因此,本文针对这些参数做以下实验。
采用数据库中不含噪的dr3部分语音,以其中每个人的方言句1作为注册语料,以该语音库全部6 300条语音作为训练集训练UBM模型。实验中HMM的状态数及高斯混合度均取为4,UBM模型的高斯混合数分别取:8,16,32,64,128,256,512,1 024。
在测试时,随机选取dr3部分的1条语音作为测试语音进行识别,重复实验,取FA、FR均值。实验结果如图6所示。
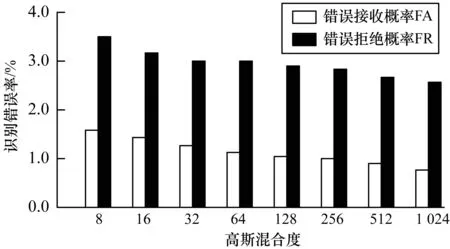
图6 UBM高斯混合度对识别率的影响结果
测试结果表明,随着通用背景模型的高斯混合度增高,错误接收概率及错误拒绝概率均有小幅度下降。当混合度超过512时,错误接收概率小于1%,尽管错误拒绝率仍有3%左右,但错误拒绝对用户信息安全影响较小。因此,取UBM模型的高斯混合度为512。
5.3 RVM采用不同核函数对模型识别率的影响
采用数据库中不含噪的dr3部分语音,以其中每个人的方言句1作为注册语料,以该语音库全部6 300条语音作为训练集训练UBM模型。在实验中,RVM分类器核函数分别选多项式核、sigmoid核和高斯核,分别选取dr3语料中15位、30位、45位、60位说话人的注册语音重复进行识别率测试。实验结果如表1所示。

表1 RVM采用不同核函数对模型识别率的影响
从表1可以看出,随着测试人数的增加,高斯核的测试精度明显高于多项式核和sigmoid核。因此,RVM均采用高斯核作为核函数进行分类决策。
5.4 系统识别率测试
本文所提出的声纹密码识别方法与常用于语音识别的GMM-UBM、GMM-SVM及HMM-UBM算法进行对比,实验采用TIMIT语音库中所有说话人的方言句1作为注册语音,为对应话者建立模型,采用全部6 300条语音作为训练集训练UBM模型,抽取每位话者的注册语音及随机两条其他语音进行识别,共测试630×3=1 890次,取识别正确率、FA及FR均值,实验结果如表2所示。
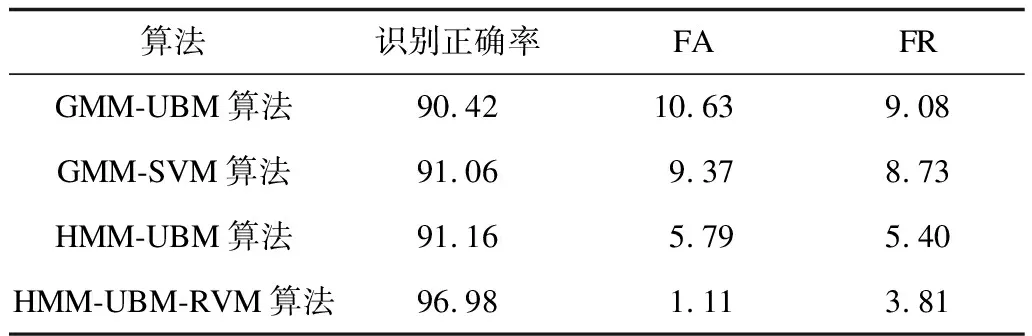
表2 不同算法的识别率比较 %
从表2可以看出,本文方法与GMM-UBM和GMM-SVM识别算法相比,大幅降低了识别算法的错误接收概率和错误拒绝概率。可以看出,针对文本相关的声纹密码识别,采用更具有时序建模能力的隐马尔科夫模型-通用背景模型,该模型可反映声纹的文本信息及话者的声道信息。相比之下,GMM模型的GMM-UBM算法和GMM-SVM算法都忽视了文本信息,会将说话人的其他语音识别为其注册语音,从而导致错误接收概率较大,影响用户信息安全。同时,本文方法在HMM-UBM模型基础上采用RVM作为分类器,回避了该模型分类决策能力弱的问题。
5.5 系统抗噪性能测试
对测试语音进行高斯白噪声加噪处理,信噪比分别为0 dB、5 dB、10 dB、15 dB、20 dB、25 dB、30 dB。系统抗噪性能测试结果如图7所示。
由图7可以看出,本文算法在各信噪比环境下,识别率均优于基于GMM-SVM和GMM-UBM识别算法。尤其在低信噪比环境下,其优越性更加明显。一方面是因为该方法采用HMM-UBM模型,兼顾语音的文本信息及话者的声道信息,更适用于文本相关的声纹密码识别;另一方面,由于HMM是基于先验知识的统计学习方法,并不具备良好的分类能力,将其与相关向量机相融合,发挥HMM的时序建模能力和RVM的分类决策能力,能够提高其抗噪性能识别精度。
5.6 应用测试
本文方法用于模拟门禁系统,实现声纹密码开锁。实验采用实验室中20位说话人(12男,8女),每位说话人50条语音,语音内容为8位0~9的随机数,取每位话者其中一条语音作为声纹密码,注册其模型,以全部1 000条语音作为训练集,训练UBM模型。对每位说话人进行测试,测试语音采用说话人现场说出5条对应的注册语音及5条对应的非注册语音,记录正确开锁率(说话人与密码相匹配并开锁成功及说话人与密码不匹配并开锁失败2种情况视为正确开锁)。以基于GMM-UBM、GMM-SVM和HMM-UBM算法的模拟门禁系统作为对比,采用同样的方法进行测试,对比结果如表3所示。
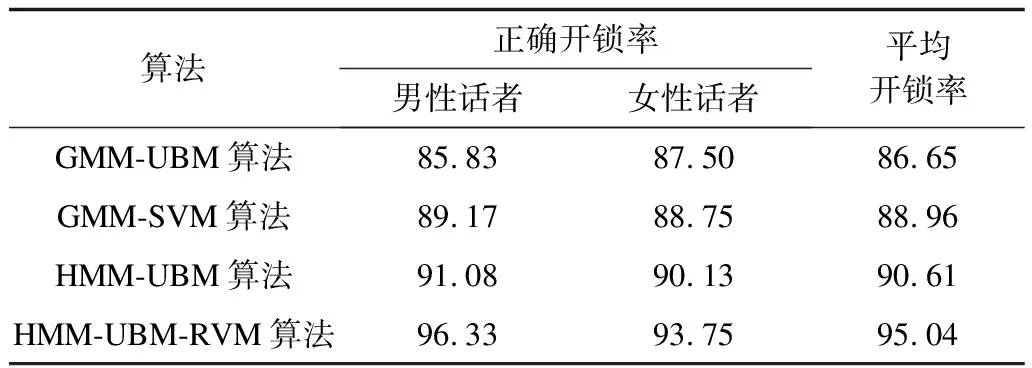
表3 算法应用结果对比 %
6 结束语
声纹密码识别广泛应用于各种场所的安全认证,而常用语音识别系统大多采用传统的GMM-UBM模型及改进算法。GMM模型虽能较好反映说话人的声道信息,但忽视语音内容对识别正确率的影响,不适用于固定文本的声纹密码识别。本文提出HMM-UBM联合RVM的声纹密码识别算法,利用隐马尔科夫模型的时序建模能力得到语音的文本信息,采用UBM模型解决训练样本不足的问题,并通过相关向量机对测试语音进行分类决策。实验结果表明,该算法在进行文本相关的说话人识别时,识别效果优于GMM-UBM算法和GMM-SVM算法,具有较好的应用价值。
猜你喜欢
保健医苑(2022年4期)2022-05-05 06:11:30
英语文摘(2020年3期)2020-08-13 07:27:02
科技创新与应用(2020年6期)2020-02-29 10:39:27
通信产业报(2018年32期)2018-11-24 10:37:58
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
语文世界(小学版)(2016年9期)2016-09-14 20:02:22
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
微型小说选刊(2015年5期)2015-06-05 09:15:29
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:11
